選択する
SELECTステートメントは、TiDB からデータを読み取るために使用されます。
あらすじ
選択Stmt:

デュアルから:

StmtOpts を選択:

選択StmtFieldList:
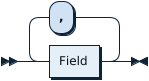
TableRefsClause:
- TableRefsClause
- AsOfClause
TableRefsClause ::=
TableRef AsOfClause? ( ',' TableRef AsOfClause? )*
AsOfClause ::=
'AS' 'OF' 'TIMESTAMP' Expression
WhereClauseオプション:

選択StmtGroup:
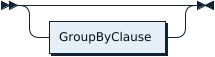
所有条項:
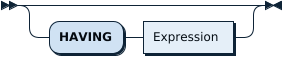
OrderByオプション:
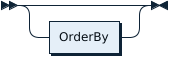
選択StmtLimit:
最初または次:

FetchFirstOpt:
行または行:
ロックオプションを選択:
- SelectLockOpt
- TableList
SelectLockOpt ::=
( ( 'FOR' 'UPDATE' ( 'OF' TableList )? 'NOWAIT'? )
| ( 'LOCK' 'IN' 'SHARE' 'MODE' ) )?
TableList ::=
TableName ( ',' TableName )*
WindowClauseオプション
テーブルサンプルオプション
- TableSampleOpt
TableSampleOpt ::=
'TABLESAMPLE' 'REGIONS()'
構文要素の説明
例
選択する
mysql> CREATE TABLE t1 (id INT NOT NULL PRIMARY KEY AUTO_INCREMENT, c1 INT NOT NULL);
Query OK, 0 rows affected (0.11 sec)
mysql> INSERT INTO t1 (c1) VALUES (1),(2),(3),(4),(5);
Query OK, 5 rows affected (0.03 sec)
Records: 5 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM t1;
+----+----+
| id | c1 |
+----+----+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
+----+----+
5 rows in set (0.00 sec)
mysql> SELECT AVG(s_quantity), COUNT(s_quantity) FROM stock TABLESAMPLE REGIONS();
+-----------------+-------------------+
| AVG(s_quantity) | COUNT(s_quantity) |
+-----------------+-------------------+
| 59.5000 | 4 |
+-----------------+-------------------+
1 row in set (0.00 sec)
mysql> SELECT AVG(s_quantity), COUNT(s_quantity) FROM stock;
+-----------------+-------------------+
| AVG(s_quantity) | COUNT(s_quantity) |
+-----------------+-------------------+
| 54.9729 | 1000000 |
+-----------------+-------------------+
1 row in set (0.52 sec)
上の例では、 tiup bench tpcc prepareで生成されたデータを使用しています。最初のクエリはTABLESAMPLEの使用を示しています。
...をOUTFILEに選択してください
SELECT ... INTO OUTFILEステートメントは、クエリの結果をファイルに書き込むために使用されます。
注記:
- このステートメントは TiDB セルフホスト型にのみ適用され、 TiDB Cloudでは使用できません。
- このステートメントは、Amazon S3 や GCS などへの外部ストレージ結果の書き込みをサポートしていません。
ステートメントでは、次の句を使用して出力ファイルの形式を指定できます。
FIELDS TERMINATED BY: ファイル内のフィールド区切り文字を指定します。たとえば、カンマ区切り値 (CSV) を出力する場合は','と指定し、タブ区切り値 (TSV) を出力する場合は'\t'と指定できます。FIELDS ENCLOSED BY: ファイル内の各フィールドを囲む囲み文字を指定します。LINES TERMINATED BY: 特定の文字で行を終了する場合は、ファイル内の行終端文字を指定します。
次のような 3 つの列を持つテーブルtがあるとします。
mysql> CREATE TABLE t (a INT, b VARCHAR(10), c DECIMAL(10,2));
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO t VALUES (1, 'a', 1.1), (2, 'b', 2.2), (3, 'c', 3.3);
Query OK, 3 rows affected (0.01 sec)
次の例は、 SELECT ... INTO OUTFILEステートメントを使用してクエリ結果をファイルに書き込む方法を示しています。
例 1:
mysql> SELECT * FROM t INTO OUTFILE '/tmp/tmp_file1';
Query OK, 3 rows affected (0.00 sec)
この例では、次のように/tmp/tmp_file1でクエリ結果を見つけることができます。
1 a 1.10
2 b 2.20
3 c 3.30
例 2:
mysql> SELECT * FROM t INTO OUTFILE '/tmp/tmp_file2' FIELDS TERMINATED BY ',' ENCLOSED BY '"';
Query OK, 3 rows affected (0.00 sec)
この例では、次のように/tmp/tmp_file2でクエリ結果を見つけることができます。
"1","a","1.10"
"2","b","2.20"
"3","c","3.30"
例 3:
mysql> SELECT * FROM t INTO OUTFILE '/tmp/tmp_file3'
-> FIELDS TERMINATED BY ',' ENCLOSED BY '\'' LINES TERMINATED BY '<<<\n';
Query OK, 3 rows affected (0.00 sec)
この例では、次のように/tmp/tmp_file3でクエリ結果を見つけることができます。
'1','a','1.10'<<<
'2','b','2.20'<<<
'3','c','3.30'<<<
MySQLの互換性
- 構文
SELECT ... INTO @variableはサポートされていません。 - 構文
SELECT ... GROUP BY ... WITH ROLLUPはサポートされていません。 - 構文
SELECT ... INTO DUMPFILEはサポートされていません。 - MySQL 5.7のように、構文
SELECT .. GROUP BY exprGROUP BY expr ORDER BY exprを意味しません。 TiDB は MySQL 8.0 の動作に一致し、デフォルトの順序を意味しません。 - 構文
SELECT ... TABLESAMPLE ...は、他のデータベース システムおよびISO/IEC 9075-2標準との互換性を目的として設計された TiDB 拡張機能ですが、現在 MySQL ではサポートされていません。