パフォーマンスの分析とチューニングの概要
このドキュメントでは、TiDB Cloudで SQL パフォーマンスを分析および調整するのに役立つ手順について説明します。
ユーザー応答時間
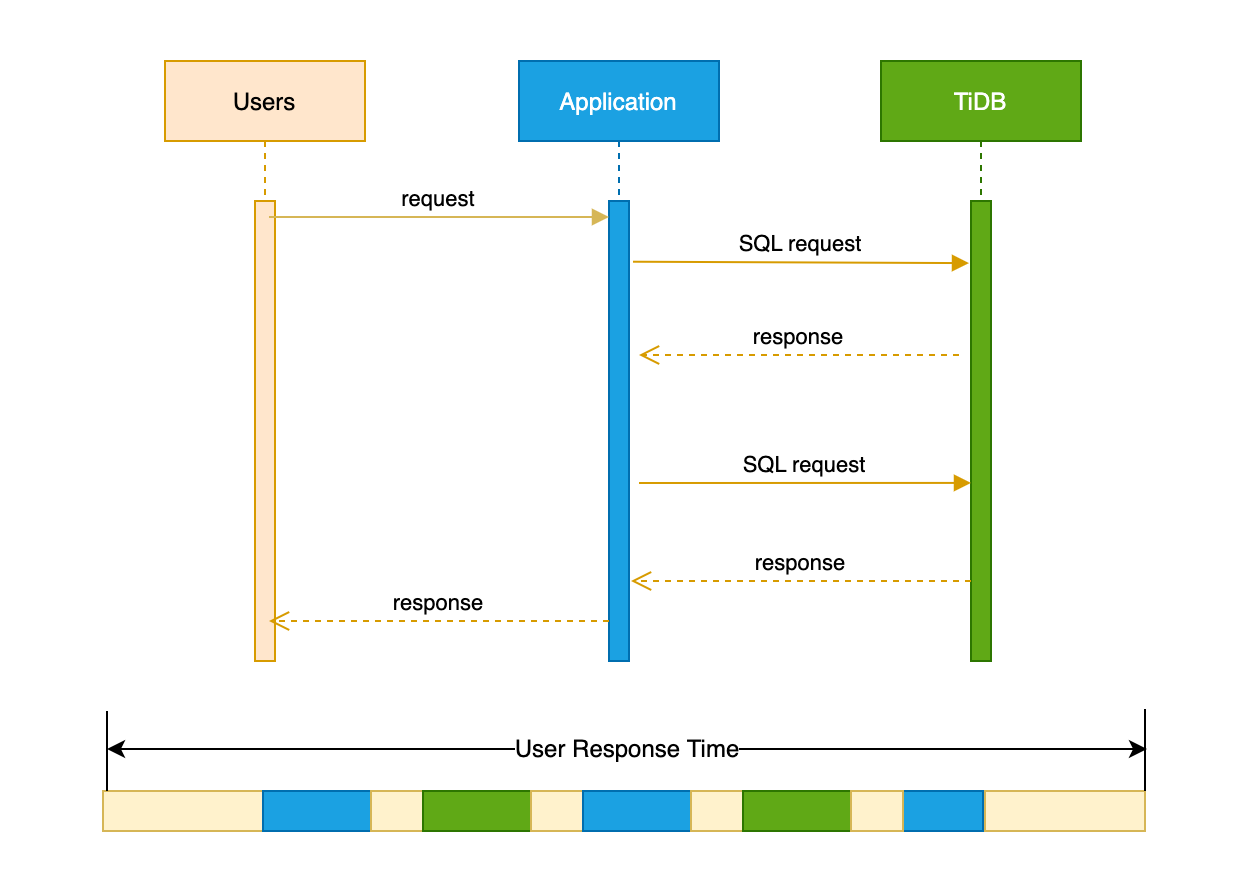
ユーザー応答時間とは、アプリケーションがリクエストの結果をユーザーに返すまでにかかる時間を指します。以下のシーケンシャルタイミング図からわかるように、典型的なユーザーリクエストの時間には、以下の要素が含まれます。
- ユーザーとアプリケーション間のネットワークレイテンシー
- 申請の処理時間
- アプリケーションとデータベース間のやり取り中のネットワークレイテンシー
- データベースのサービス時間
ユーザー応答時間は、ネットワークのレイテンシーや帯域幅、同時ユーザーの数やリクエストの種類、サーバーのCPUやI/Oリソースの使用率など、リクエストチェーン上の様々なサブシステムの影響を受けます。システム全体を効果的に最適化するには、まずユーザー応答時間のボトルネックを特定する必要があります。
指定された時間範囲( ΔT )内のユーザー応答時間の合計を取得するには、次の数式を使用します。
ΔTでの合計ユーザー応答時間 = 平均 TPS (1 秒あたりのトランザクション数) x 平均ユーザー応答時間 x ΔT 。
ユーザー応答時間とシステムスループットの関係
ユーザー応答時間は、サービス時間、キュー時間、およびユーザー要求を完了するための同時待機時間で構成されます。
User Response time = Service time + Queuing delay + Coherency delay
- サービス時間: リクエストを処理するときにシステムが特定のリソースに消費する時間。たとえば、データベースが SQL リクエストを完了するために消費する CPU 時間など。
- キューイング遅延: システムが要求を処理するときに、特定のリソースのサービスをキューで待機する時間。
- 一貫性遅延: システムがリクエストを処理するときに共有リソースにアクセスできるように、他の同時タスクと通信して連携する時間。
システムスループットとは、システムが1秒間に処理できるリクエストの数を指します。ユーザー応答時間とスループットは通常、反比例関係にあります。スループットが増加すると、システムリソースの使用率と、要求されたサービスのキューイングレイテンシーもそれに応じて増加します。リソース使用率が一定の変曲点を超えると、キューイングレイテンシーは劇的に増加します。
例えば、OLTP負荷を実行しているデータベースシステムでは、CPU使用率が65%を超えると、CPUキューイングとスケジューリングのレイテンシーが大幅に増加します。これは、システムの同時リクエストが完全に独立していないため、これらのリクエストが連携して共有リソースを奪い合う可能性があるためです。例えば、異なるユーザーからのリクエストが、同じデータに対して相互に排他的なロック操作を実行する場合があります。リソース使用率が増加すると、キューイングとスケジューリングのレイテンシーも増加し、共有リソースが時間内に解放されず、他のタスクによる共有リソースの待機時間が長くなります。
ユーザー応答時間のボトルネックをトラブルシューティングする
TiDB Cloudコンソールには、ユーザー応答時間のトラブルシューティングに役立つページがいくつかあります。
診断 :
- SQL文を使用すると、ページ上のSQL実行を直接観察し、システムテーブルをクエリすることなくパフォーマンスの問題を簡単に特定できます。SQL文をクリックすると、クエリの実行プランをさらに詳しく表示して、トラブルシューティングや分析を行うことができます。SQLパフォーマンスチューニングの詳細については、 SQLチューニングの概要参照してください。
- Key Visualizer を使用すると、TiDB のデータ アクセス パターンとデータ ホットスポットを観察できます。
メトリクス : このページでは、リクエスト単位、使用済みストレージサイズ、1 秒あたりのクエリ数、平均クエリ実行時間などのメトリックを表示できます。
追加のメトリックをリクエストするには、 TiDB Cloudサポートお問い合わせください。
レイテンシーやパフォーマンスの問題が発生した場合は、分析とトラブルシューティングについては次のセクションの手順を参照してください。
TiDB クラスタ外部のボトルネック
「概要」タブでレイテンシ(P80)を確認します。この値がユーザー応答時間のP80値よりも大幅に低い場合、主なボトルネックはTiDBクラスター外にある可能性があると判断できます。この場合、以下の手順に従ってボトルネックをトラブルシューティングできます。
概要タブの左側にある TiDB のバージョンを確認してください。v6.0.0 以前のバージョンの場合は、 PingCAPサポートチームに問い合わせて、Prepared plan cache、Raft エンジン、TiKV AsyncIO 機能を有効にできるかどうかを確認することをお勧めします。これらの機能を有効にし、アプリケーション側のチューニングを行うことで、スループット性能を大幅に向上させ、レイテンシーとリソース使用率を削減できます。
必要に応じて、TiDB トークンの制限を増やしてスループットを向上させることができます。
プリペアドプランキャッシュ機能が有効になっていて、ユーザー側で JDBC を使用する場合は、次の構成を使用することをお勧めします。
useServerPrepStmts=true&cachePrepStmts=true& prepStmtCacheSize=1000&prepStmtCacheSqlLimit=20480&useConfigs=maxPerformanceJDBC を使用せず、現在の TiDB クラスターのプリペアドプランキャッシュ機能を最大限に活用したい場合は、クライアント側でプリペアドステートメントオブジェクトをキャッシュする必要があります。StmtPrepare および StmtClose の呼び出しをリセットする必要はありません。クエリごとに呼び出されるコマンドの数を 3 から 1 に減らします。パフォーマンス要件とクライアント側の変更の量によっては、ある程度の開発作業が必要になります。PingCAPサポートチームに問い合わせてください。
TiDBクラスタのボトルネック
パフォーマンスのボトルネックが TiDB クラスター内にあると判断した場合は、次の操作を実行することをお勧めします。
- 遅い SQL クエリを最適化します。
- ホットスポットの問題を解決します。
- 容量を拡張するには、クラスターをスケールアウトします。
遅いSQLクエリを最適化する
SQL パフォーマンス チューニングの詳細については、 SQLチューニングの概要参照してください。
ホットスポットの問題を解決する
ホットスポットの問題はKey Visualizerタブで確認できます。以下のスクリーンショットはヒートマップのサンプルです。マップの横軸は時間、縦軸はテーブルとインデックスです。明るい色はトラフィックが多いことを示します。ツールバーで読み取りトラフィックと書き込みトラフィックの表示を切り替えることができます。
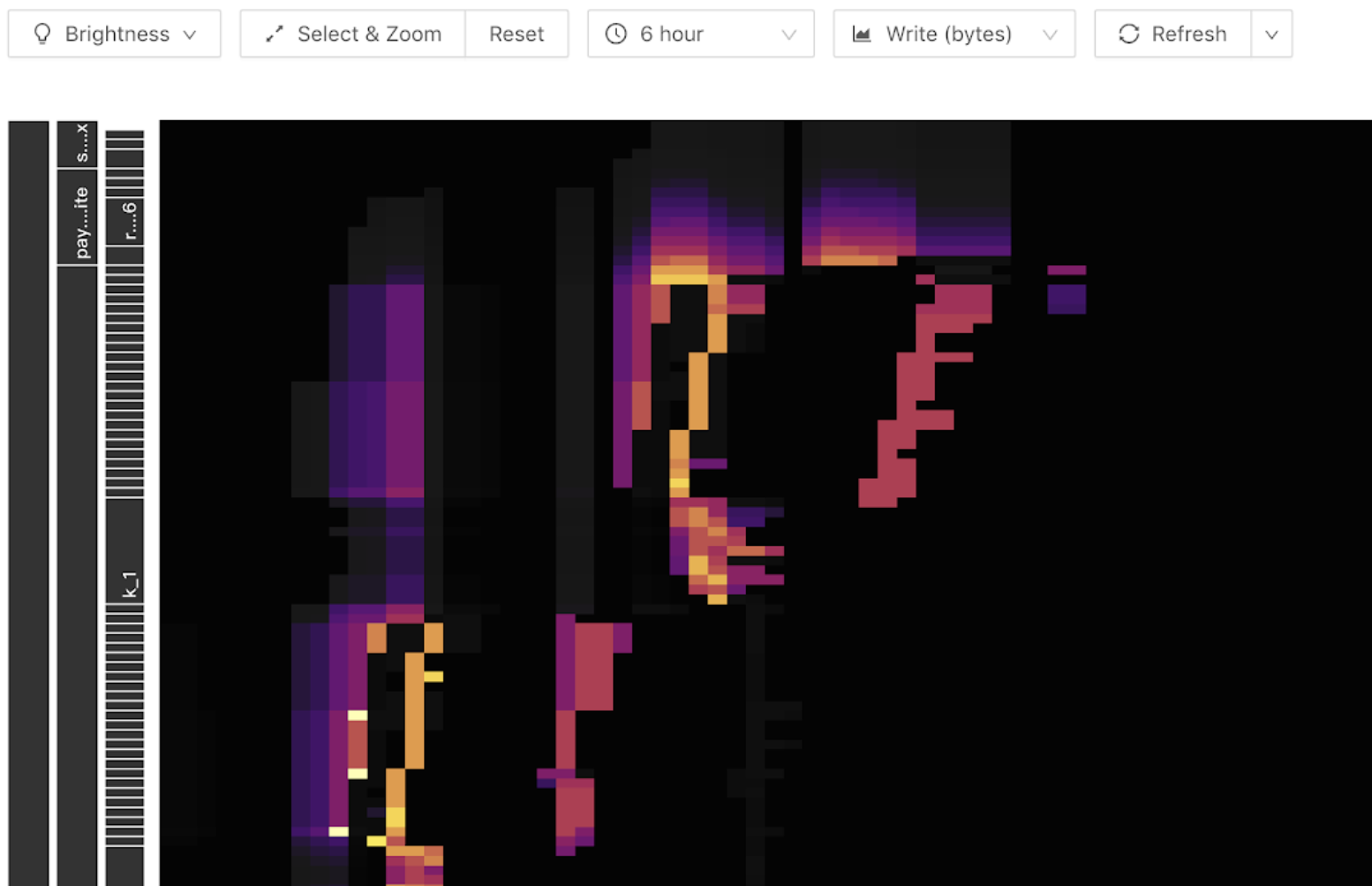
次のスクリーンショットは、書き込みホットスポットの例を示しています。書き込みフローグラフに明るい斜めの線(斜め上または斜め下)が表示され、書き込みトラフィックは線の終端にのみ現れます。テーブル「Regions」の数が増えるにつれて、このパターンは階段状に変化します。これは、テーブルに書き込みホットスポットが発生していることを示しています。書き込みホットスポットが発生した場合は、自己増分型の主キーを使用しているか、主キーを使用していないか、あるいは時間依存の挿入文またはインデックスを使用しているかを確認する必要があります。

読み取りホットスポットは通常、次のスクリーンショットに示すように、明るい水平線でヒートマップに表され、通常は多数のクエリを含む小さなテーブルとして表示されます。

次のスクリーンショットに示すように、強調表示されたブロックにマウスを移動すると、トラフィック量が多いテーブルまたはインデックスが表示されます。
スケールアウト
クラスター概要ページで、ストレージ容量、CPU使用率、TiKV IOレートのメトリクスを確認してください。いずれかのメトリクスが長期間上限に達している場合は、現在のクラスターサイズではビジネス要件を満たせない可能性があります。クラスターPingCAPサポートチームご連絡いただき、スケールアウトが必要かどうか確認することをお勧めします。
その他の問題
上記の方法でパフォーマンスの問題を解決できない場合は、 PingCAPサポートチームにお問い合わせください。トラブルシューティングを迅速に進めるために、以下の情報をご提供いただくことをお勧めします。
- クラスターID
- 発行間隔と同等の通常間隔
- 問題現象と期待される動作
- 読み取りまたは書き込み比率や主な動作などのビジネスワークロード特性
まとめ
一般に、パフォーマンスの問題を分析および解決するには、次の最適化方法を使用できます。
今後、 TiDB Cloud はより多くの観測可能なメトリクスと自己診断サービスを導入する予定です。これにより、パフォーマンスメトリクスに関するより包括的な理解と運用アドバイスが提供され、ユーザーエクスペリエンスが向上します。