SQLチューニングの概要
このドキュメントでは、TiDB Cloudで SQL のパフォーマンスをチューニングする方法について説明します。最高の SQL パフォーマンスを得るには、次の操作を実行できます。
- SQLのパフォーマンスを最適化しましょう。SQLのパフォーマンスを最適化する方法は数多くあり、クエリ文の分析、実行プランの最適化、フルテーブルスキャンの最適化などが挙げられます。
- スキーマ設計を最適化してください。業務ワークロードの種類によっては、トランザクションの競合やホットスポットを回避するために、スキーマを最適化する必要がある場合があります。
SQLパフォーマンスのチューニング
SQL文のパフォーマンスを向上させるには、以下の原則を考慮してください。
- スキャン対象データの範囲を最小限に抑えましょう。常に、必要最小限のデータのみをスキャンし、すべてのデータをスキャンすることは避けるのが最善策です。
- 適切なインデックスを使用してください。SQL文の
WHERE句の各列には、対応するインデックスが存在することを確認してください。そうでない場合、WHERE句はテーブル全体をスキャンするため、パフォーマンスが低下します。 - 適切な結合タイプを使用してください。クエリ内の各テーブルのサイズと相関関係に応じて、適切な結合タイプを選択することが非常に重要です。一般に、TiDB のコストベースのオプティマイザーは、最適な結合タイプを自動的に選択します。ただし、場合によっては、結合タイプを手動で指定する必要がある場合があります。詳細については、テーブル結合を使用するステートメントについて説明します参照してください。
- 適切なストレージエンジンを使用してください。ハイブリッドトランザクションおよび分析処理(HTAP)ワークロードには、 TiFlashストレージエンジンを使用することをお勧めします。HTAP HTAPクエリを参照してください。
TiDB Cloudには、スロークエリを分析するのに役立つツールがいくつか用意されています。以下のセクションでは、スロークエリを最適化するためのいくつかの方法について説明します。
診断ページの「使用説明書」を参照してください。
TiDB Cloudコンソールには、 診断上にSQLステートメントタブが用意されています。このタブでは、TiDB Cloudリソース上のすべてのデータベースの SQL ステートメントの実行統計情報を収集します。これを使用して、合計または単一の実行に長い時間を要する SQL ステートメントを特定し、分析することができます。
このページでは、構造が同じ SQL クエリ (クエリ パラメータが一致しない場合でも) は、同じ SQL ステートメントにグループ化されることに注意してください。たとえば、 SELECT * FROM employee WHERE id IN (1, 2, 3)とselect * from EMPLOYEE where ID in (4, 5)は、どちらも同じ SQL ステートメントselect * from employee where id in (...)の一部です。
SQLステートメントでいくつかの重要な情報を確認できます。
SQLテンプレート:SQLダイジェスト、SQLテンプレートID、現在表示されている時間範囲、実行プランの数、および実行が行われるデータベースが含まれます。
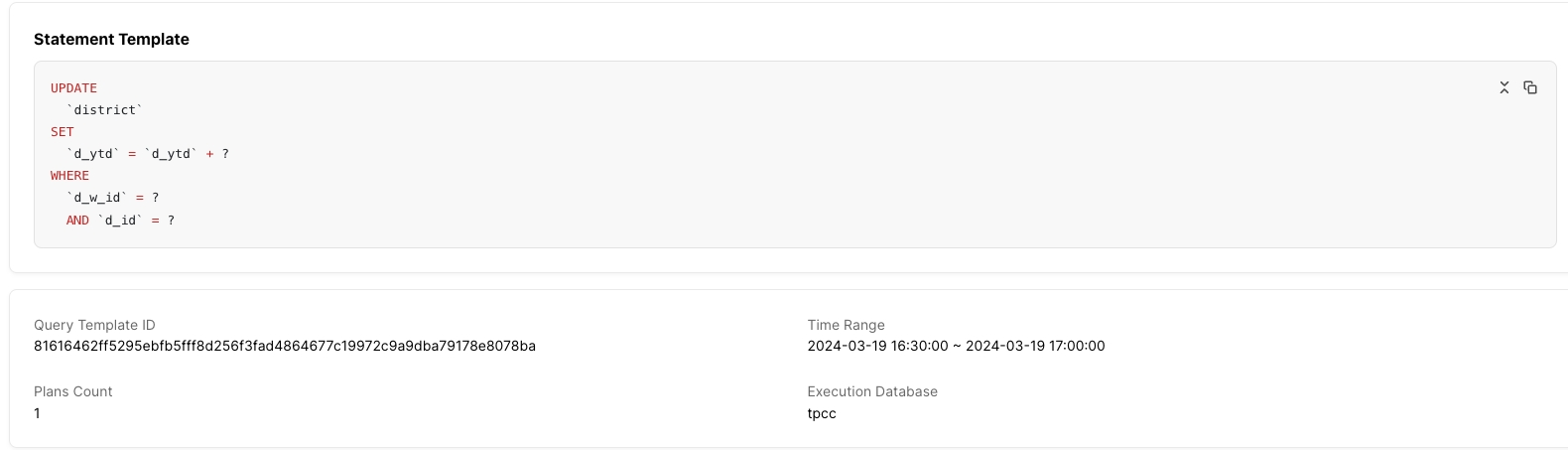
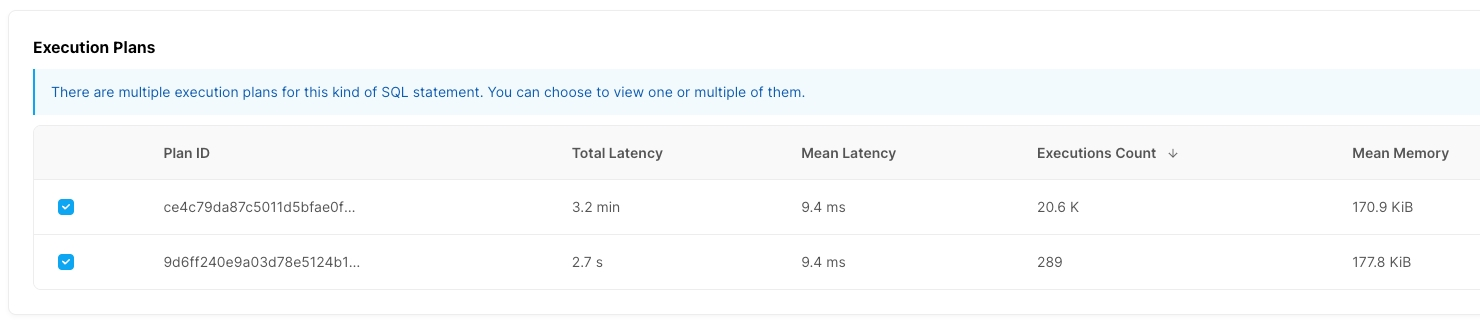
実行プラン一覧:SQL文に複数の実行プランがある場合、一覧が表示されます。複数の実行プランを選択すると、選択した実行プランの詳細が一覧の下部に表示されます。実行プランが1つしかない場合は、一覧は表示されません。
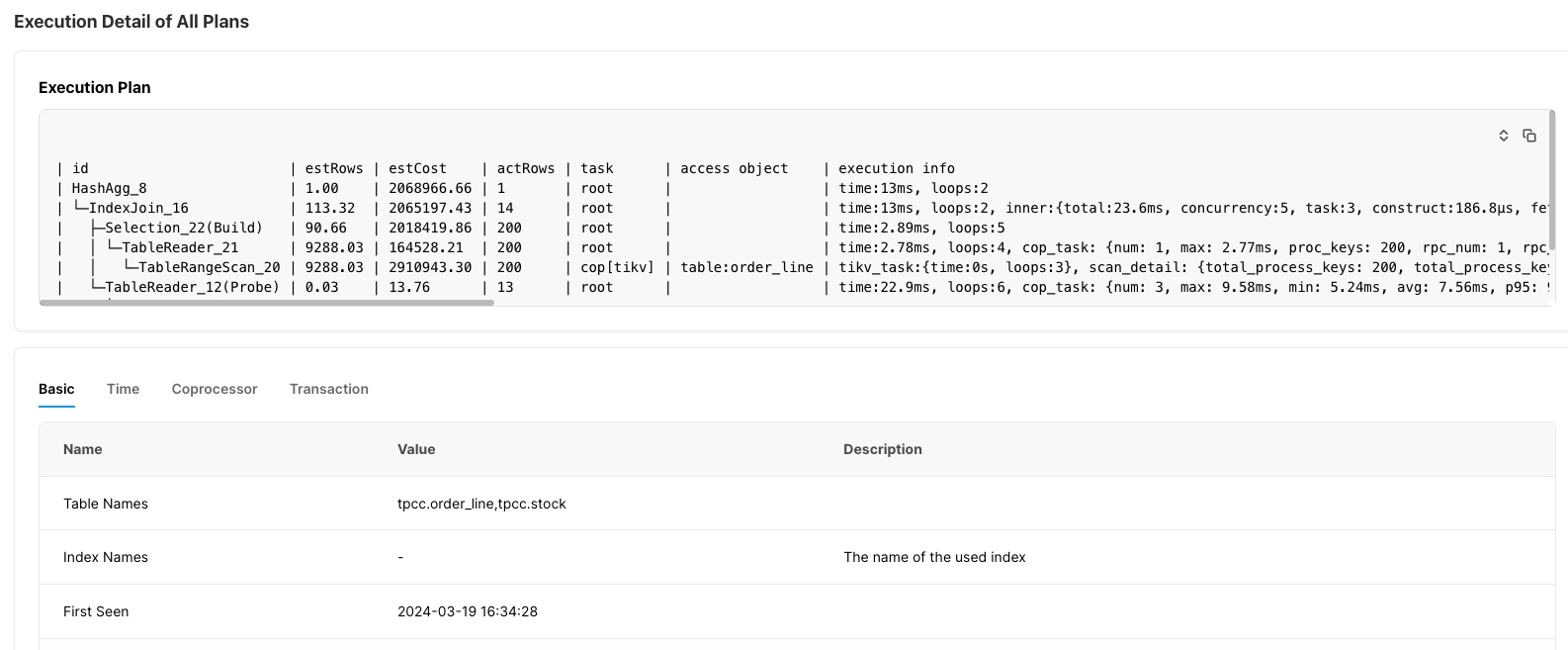
実行プランの詳細:選択した実行プランの詳細を表示します。各SQLタイプの実行プランと、複数の視点からの対応する実行時間を収集し、より多くの情報を取得するのに役立ちます。 実行計画参照してください。
関連するスロークエリ
ステートメントダッシュボードの情報に加えて、 TiDB CloudにはSQLのベストプラクティスもいくつかあり、以下のセクションで説明します。
実行計画を確認する
EXPLAIN使用すると、コンパイル時にTiDBが計算したステートメントの実行プランを確認できます。つまり、TiDBは数百または数千もの実行プランを推定し、リソース消費が最も少なく、実行速度が最も速い最適な実行プランを選択します。
TiDBによって選択された実行プランが最適でない場合は、 EXPLAINまたはEXPLAIN ANALYZE使用して診断できます。
実行計画を最適化する
parserによる元のクエリテキストの解析と基本的な妥当性検証の後、TiDB はまずクエリに対して論理的に同等の変更を行います。詳細については、 SQL論理最適化参照してください。 .
これらの等価性の変更により、クエリは論理実行プランで扱いやすくなります。等価性の変更後、TiDB は元のクエリと等価なクエリ プラン構造を取得し、データ分布と演算子の特定の実行オーバーヘッドに基づいて最終的な実行プランを取得します。詳細については、 SQLの物理的最適化参照してください。
また、プリペアドプランキャッシュで紹介したように、TiDB は、 PREPAREステートメントの実行時に実行プランの作成オーバーヘッドを削減するために、プリペアドプランキャッシュを提供しています。
フルテーブルスキャンを最適化
SQLクエリが遅くなる最も一般的な原因は、 SELECTステートメントがフルテーブルスキャンを実行するか、不適切なインデックスを使用していることです。EXPLAINまたはEXPLAIN ANALYZEを使用してクエリの実行プランを表示し、実行が遅くなる原因を特定できます。最適化に使用できる3つの方法あります。
- セカンダリインデックスを使用する
- カバーインデックスを使用する
- プライマリーインデックスを使用する
DMLのベストプラクティス
DMLのベストプラクティスを参照してください。
主キーを選択する際のDDLのベストプラクティス
主キーを選択する際に従うべきガイドライン参照してください。
インデックスのベストプラクティス
インデックス インデックス作成のベストプラクティスベストプラクティスには、インデックスの作成とインデックスの使用に関するベスト プラクティスが含まれています。
インデックスの作成速度はデフォルトでは控えめですが、シナリオによっては変数の変更によってインデックス作成プロセスを高速化できます。
スキーマ設計を最適化する
SQLパフォーマンスチューニングを行ってもパフォーマンスが改善されない場合は、トランザクションの競合やホットスポットを回避するために、スキーマ設計とデータ読み取りモデルを見直す必要があるかもしれません。
トランザクションの競合
トランザクションの競合を特定して解決する方法の詳細については、 ロックの競合をトラブルシューティングする参照してください。
ホットスポットの問題
Key Visualizerを使用してホットスポットの問題を分析できます。
Key Visualizerを使用すると、 TiDB Cloud Dedicatedクラスタの使用パターンを分析し、トラフィックのホットスポットをトラブルシューティングできます。このページでは、TiDB Cloud Dedicatedクラスタのトラフィックの推移を視覚的に表示します。
Key Visualizerでは、以下の情報を確認できます。まず、いくつかの基本概念を理解しておく必要があるかもしれません。
- 時間の経過に伴う全体の交通量を示す大きなヒートマップ
- ヒートマップの座標に関する詳細情報
- 左側に表示される表や索引などの識別情報
Key Visualizerには4つの一般的なヒートマップ結果があります。
- 均等に分散されたワークロード:望ましい結果
- X軸(時間)に沿って明るさと暗さが交互に変化する:ピーク時のリソースを確認する必要がある
- Y軸に沿って明暗が交互に変化する:生成されたホットスポットの集積度をチェックする必要がある
- 明るい斜線:ビジネスモデルを見直す必要がある
X軸とY軸が交互に明暗を繰り返す場合、どちらのケースでも読み書き時の筆圧に対処する必要があります。
SQLのパフォーマンスSQL最適化を参照してください。