統計入門
TiDBは、統計情報をオプティマイザへの入力として使用し、SQL文の各プランステップで処理される行数を推定します。オプティマイザは、利用可能な各プランのコスト( インデックスアクセスとテーブル結合の順序を含む)を推定し、利用可能な各プランのコストを生成します。そして、全体的なコストが最も低い実行プランを選択します。
統計を収集する
このセクションでは、統計を収集する 2 つの方法 (自動更新と手動収集) について説明します。
自動更新
INSERT 、 DELETE 、またはUPDATEステートメントの場合、TiDB は統計内の行数と変更された行数を自動的に更新します。
TiDBは更新情報を定期的に保持し、更新サイクルは20 * stats-leaseです。デフォルト値はstats-leaseですが、 3sです。値を0に指定すると、TiDBは統計情報の更新を自動的に停止します。
テーブルへの変更回数に基づいて、TiDBは自動的にそのテーブルの統計情報を収集するANALYZEを設定します。これは以下のシステム変数によって制御されます。
| システム変数 | デフォルト値 | 説明 |
|---|---|---|
tidb_auto_analyze_concurrency | 1 | TiDB クラスター内の自動分析操作の同時実行性。 |
tidb_auto_analyze_end_time | 23:59 +0000 | TiDB が自動更新を実行できる 1 日の終了時刻。 |
tidb_auto_analyze_partition_batch_size | 8192 | パーティションテーブルを分析するときに TiDB が自動的に分析するパーティションの数 (つまり、パーティションテーブルの統計を自動的に更新するときに)。 |
tidb_auto_analyze_ratio | 0.5 | 自動更新のしきい値。 |
tidb_auto_analyze_start_time | 00:00 +0000 | TiDB が自動更新を実行できる 1 日の開始時刻。 |
tidb_enable_auto_analyze | ON | TiDB がANALYZE自動的に実行するかどうかを制御します。 |
tidb_enable_auto_analyze_priority_queue | ON | 優先キューを有効にして、統計情報の自動収集タスクをスケジュールするかどうかを制御します。この変数を有効にすると、TiDBは、新しく作成されたインデックスやパーティションが変更されたパーティションテーブルなど、収集する価値の高いテーブルの統計情報を優先的に収集します。さらに、TiDBはヘルススコアが低いテーブルを優先し、キューの先頭に配置します。 |
tidb_enable_stats_owner | ON | 対応する TiDB インスタンスが自動統計更新タスクを実行できるかどうかを制御します。 |
tidb_max_auto_analyze_time | 43200 (12時間) | 自動タスクANALYZEの最大実行時間。単位は秒です。 |
テーブル内の変更された行数とtblの行の合計数の比率がtidb_auto_analyze_ratioより大きく、現在の時刻がtidb_auto_analyze_start_timeからtidb_auto_analyze_end_time間である場合、TiDB はバックグラウンドでANALYZE TABLE tblステートメントを実行し、このテーブルの統計を自動的に更新します。
小さなテーブルのデータ変更が頻繁に自動更新をトリガーする状況を回避するため、テーブルの行数が1000行未満の場合は、TiDBでは変更によって自動更新がトリガーされません。テーブルの行数を確認するには、 SHOW STATS_METAステートメントを使用します。
注記:
現在、自動更新では、手動
ANALYZEで入力された設定項目は記録されません。そのため、WITH構文を使用してANALYZEの収集動作を制御する場合は、統計情報を収集するためのスケジュールタスクを手動で設定する必要があります。
手動収集
現在、TiDBは完全なコレクションとして統計を収集します。統計を収集するには、 ANALYZE TABLEステートメントを実行できます。
次の構文を使用して完全なコレクションを実行できます。
TableNameList内のすべてのテーブルの統計を収集するには:ANALYZE TABLE TableNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];WITH NUM BUCKETS、生成されたヒストグラム内のバケットの最大数を指定します。WITH NUM TOPN生成されるTOPNの最大数を指定します。WITH NUM CMSKETCH DEPTHCM スケッチの深さを指定します。WITH NUM CMSKETCH WIDTHCM スケッチの幅を指定します。WITH NUM SAMPLESサンプル数を指定します。WITH FLOAT_NUM SAMPLERATEサンプリング レートを指定します。
WITH NUM SAMPLESとWITH FLOAT_NUM SAMPLERATE 、サンプルを収集する 2 つの異なるアルゴリズムに対応します。
詳細な説明についてはSAMPLERATE ヒストグラム (カウント・ミニマムスケッチ) トップN参照してください。7/ SAMPLESについては、 収集パフォーマンスの向上 CMSketchしてください。
オプションを永続化して再利用しやすくする方法については、 ANALYZE構成を保持する参照してください。
統計の種類
このセクションでは、ヒストグラム、Count-Min Sketch、Top-N の 3 種類の統計について説明します。
ヒストグラム
ヒストグラム統計は、間隔述語または範囲述語の選択性を推定するためにオプティマイザーによって使用されます。また、統計バージョン 2 の等号/IN 述語の推定のために、列内の個別値の数を決定するために使用される場合もあります ( 統計のバージョンを参照)。
ヒストグラムは、データの分布を大まかに表すものです。値の範囲全体を一連のバケットに分割し、各バケットに含まれる値の数などの単純なデータを使用して各バケットを説明します。TiDBでは、各テーブルの特定の列に対して等深度ヒストグラムが作成されます。等深度ヒストグラムは、間隔クエリの推定に使用できます。
ここで「等深度」とは、各バケットに含まれる値の数が可能な限り均等になることを意味します。例えば、{1.6, 1.9, 1.9, 2.0, 2.4, 2.6, 2.7, 2.7, 2.8, 2.9, 3.4, 3.5}という集合に対して、4つのバケットを生成するとします。等深度ヒストグラムは以下のようになります。[1.6, 1.9]、[2.0, 2.6]、[2.7, 2.8]、[2.9, 3.5]という4つのバケットが含まれています。バケットの深度は3です。
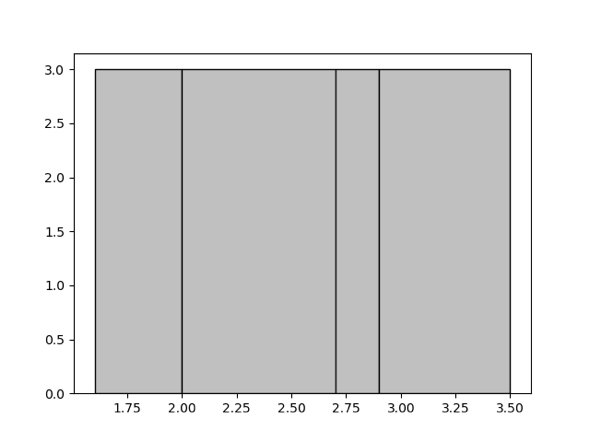
ヒストグラムのバケット数の上限を決定するパラメータの詳細については、 手動収集を参照してください。バケット数が多いほどヒストグラムの精度は向上しますが、精度向上にはメモリリソースの消費量の増加が伴います。実際のシナリオに応じて、この数値を適切に調整してください。
カウントミニマムスケッチ
注記:
Count-Minスケッチは、統計バージョン1ではequal/IN述語選択性推定にのみ使用されます。バージョン2では、後述するようにCount-Minスケッチの衝突回避のための管理が困難であるため、代わりにヒストグラム統計が使用されます。
Count-Min Sketchはハッシュ構造です。1 a = 1ような同値クエリやINようなクエリ(例えばa IN (1, 2, 3) )を処理する際、TiDBはこのデータ構造を用いて推定を行います。
Count-Min Sketchはハッシュ構造であるため、ハッシュ衝突が発生する可能性があります。1 EXPLAINのステートメントにおいて、同等のクエリの推定値が実際の値と大きく異なる場合、大きい値と小さい値が一緒にハッシュ化されていると考えられます。この場合、ハッシュ衝突を回避するために、以下のいずれかの方法を実行できます。
- パラメータ
WITH NUM TOPNを変更します。TiDB は、高頻度データ(上位 x 値)を別々に保存し、その他のデータは Count-Min Sketch に保存します。そのため、大きな値と小さな値が一緒にハッシュ化されるのを防ぐには、パラメータWITH NUM TOPNの値を増やすことができます。TiDB では、デフォルト値は 20 です。最大値は 1024 です。このパラメータの詳細については、パラメータ手動収集参照してください。 - 2つのパラメータ
WITH NUM CMSKETCH DEPTHとWITH NUM CMSKETCH WIDTHを変更します。どちらもハッシュバケットの数と衝突確率に影響します。実際のシナリオに応じて、2つのパラメータの値を適切に増やすことでハッシュ衝突の確率を下げることができますが、統計情報のメモリ使用量が増加します。TiDBでは、デフォルト値WITH NUM CMSKETCH DEPTHは5、デフォルト値WITH NUM CMSKETCH WIDTHは2048です。2つのパラメータの詳細については、 手動収集参照してください。
トップN
上位N値とは、列またはインデックス内で出現頻度が上位N個の値を指します。上位N統計は、頻度統計またはデータスキューとも呼ばれます。
TiDBは、上位N値の値と出現回数を記録します。ここでNパラメータWITH NUM TOPNによって制御されます。デフォルト値は20で、これは最も頻度の高い上位20個の値が収集されることを意味します。最大値は1024です。パラメータの詳細については、 手動収集参照してください。
選択的統計収集
このセクションでは、統計を選択的に収集する方法について説明します。
インデックスの統計を収集する
IndexNameList in TableNameのすべてのインデックスの統計を収集するには、次の構文を使用します。
ANALYZE TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
IndexNameListが空の場合、この構文はTableName内のすべてのインデックスの統計を収集します。
注記:
収集前後の統計情報の一貫性を確保するために、
tidb_analyze_versionが2場合、この構文はインデックス付き列とすべてのインデックスの統計を収集します。
いくつかの列の統計を収集する
TiDBがSQL文を実行する際、オプティマイザはほとんどの場合、列のサブセットのみの統計情報を使用します。例えば、 WHERE 、 JOIN 、 ORDER BY 、 GROUP BY節に現れる列などです。これらの列は述語列と呼ばれます。
テーブルに多数の列がある場合、すべての列の統計情報を収集すると大きなオーバーヘッドが発生する可能性があります。オーバーヘッドを軽減するには、特定の列(選択した列)のみの統計を収集するか、オプティマイザで使用する列PREDICATE COLUMNS収集することができます。列のサブセットの列リストを永続化して将来再利用できるようにするには、 列構成を保持する参照してください。
注記:
- 述語列の統計の収集は
tidb_analyze_version = 2にのみ適用されます。- TiDB v7.2.0以降、TiDBは
tidb_analyze_skip_column_typesシステム変数も導入しました。これは、統計情報を収集するANALYZEコマンドを実行する際に、統計収集からどのタイプの列をスキップするかを示します。このシステム変数はtidb_analyze_version = 2にのみ適用されます。
特定の列の統計を収集するには、次の構文を使用します。
ANALYZE TABLE TableName COLUMNS ColumnNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];この構文では、
ColumnNameList対象列の名前リストを指定します。複数の列を指定する必要がある場合は、列名をカンマ,で区切ります。例:ANALYZE table t columns a, b。この構文は、特定のテーブルの特定の列の統計情報を収集するだけでなく、インデックスが付けられた列とそのテーブル内のすべてのインデックスの統計も同時に収集します。PREDICATE COLUMNSの統計を収集するには、次の構文を使用します。ANALYZE TABLE TableName PREDICATE COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];TiDB は常に 100 *
stats-leaseごとにPREDICATE COLUMNS情報をmysql.column_stats_usageシステム テーブルに書き込みます。この構文では、特定のテーブル内の
PREDICATE COLUMNSに関する統計を収集するだけでなく、インデックスが付けられた列とそのテーブル内のすべてのインデックスに関する統計も同時に収集します。注記:
mysql.column_stats_usageシステム テーブルにそのテーブルに対して記録されたPREDICATE COLUMNS含まれていない場合、上記の構文は、そのテーブル内のインデックス付き列とすべてのインデックスに関する統計を収集します。- 手動で列をリストするか、
PREDICATE COLUMNS使用することで収集から除外された列の統計情報は上書きされません。新しいタイプのSQLクエリを実行する際、オプティマイザは、そのような列に古い統計情報が存在する場合はそれを使用し、統計情報が収集されていない列の場合は擬似列統計情報を使用します。次にPREDICATE COLUMNS使用したANALYZEを実行すると、それらの列の統計情報が収集されます。
すべての列とインデックスの統計を収集するには、次の構文を使用します。
ANALYZE TABLE TableName ALL COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
パーティションの統計を収集する
PartitionNameListinTableNameのすべてのパーティションの統計を収集するには、次の構文を使用します。ANALYZE TABLE TableName PARTITION PartitionNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];PartitionNameListinTableNameのすべてのパーティションのインデックス統計を収集するには、次の構文を使用します。ANALYZE TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];テーブル内の一部のパーティションのいくつかの列の統計を収集するだけが必要な場合は、次の構文を使用します。
ANALYZE TABLE TableName PARTITION PartitionNameList [COLUMNS ColumnNameList|PREDICATE COLUMNS|ALL COLUMNS] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
動的プルーニングモードでパーティションテーブルの統計を収集する
動的プルーニングモード (v6.3.0以降のデフォルト)でパーティションテーブルにアクセスする場合、TiDBはテーブルレベルの統計、つまりパーティションテーブルのグローバル統計を収集します。現在、グローバル統計はすべてのパーティションの統計から集約されています。動的プルーニングモードでは、テーブルのいずれかのパーティションの統計が更新されると、そのテーブルのグローバル統計も更新される可能性があります。
一部のパーティションの統計が空の場合、または一部のパーティションの一部の列の統計が欠落している場合、コレクションの動作はtidb_skip_missing_partition_stats変数によって制御されます。
グローバル統計の更新がトリガーされ、
tidb_skip_missing_partition_statsがOFF場合:一部のパーティションに統計がない場合 (分析されたことのない新しいパーティションなど)、グローバル統計の生成が中断され、パーティションに統計がないことを示す警告メッセージが表示されます。
特定のパーティションに一部の列の統計が存在しない場合 (これらのパーティションでは分析用に異なる列が指定されている)、これらの列の統計を集計するときにグローバル統計の生成が中断され、特定のパーティションに一部の列の統計が存在しないことを示す警告メッセージが表示されます。
グローバル統計の更新がトリガーされ、
tidb_skip_missing_partition_statsがON場合:- 一部のパーティションのすべての列または一部の列の統計が欠落している場合、TiDB はグローバル統計を生成するときにこれらの欠落しているパーティション統計をスキップするため、グローバル統計の生成には影響しません。
動的プルーニングモードでは、パーティションとテーブルのANALYZE構成は同じである必要があります。したがって、 ANALYZE TABLE TableName PARTITION PartitionNameList文の後にCOLUMNS構成を指定した場合、またはWITHの後にOPTIONS構成を指定した場合、TiDB はそれらを無視し、警告を返します。
収集パフォーマンスの向上
注記:
- TiDBにおける
ANALYZE TABLE実行時間は、MySQLやInnoDBよりも長くなる可能性があります。InnoDBでは少数のページのみがサンプリングされますが、TiDBではデフォルトで包括的な統計セットが完全に再構築されます。
TiDB は、統計収集のパフォーマンスを向上させる 2 つのオプションを提供します。
- 列のサブセットに関する統計情報を収集しています。1 いくつかの列の統計情報を収集する参照してください。
- サンプリング。
統計サンプリング
サンプリングはANALYZEステートメントの 2 つの別個のオプションを介して実行できます。それぞれが異なる収集アルゴリズムに対応しています。
WITH NUM SAMPLES、TiDB のリザーバサンプリング方式で実装されているサンプリングセットのサイズを指定します。テーブルが大きい場合、この方式を使用して統計情報を収集することは推奨されません。リザーバサンプリングの中間結果セットには冗長な結果が含まれるため、メモリなどのリソースにさらなる負荷がかかります。WITH FLOAT_NUM SAMPLERATEはバージョン5.3.0で導入されたサンプリング方式です。値の範囲は(0, 1]で、このパラメータはサンプリングレートを指定します。これはTiDBのベルヌーイサンプリング方式で実装されており、大規模なテーブルのサンプリングに適しており、収集効率とリソース使用率が向上します。
v5.3.0より前のTiDBでは、統計収集にリザーバサンプリング法が使用されていました。v5.3.0以降、TiDBバージョン2の統計では、デフォルトでベルヌーイサンプリング法が統計収集に使用されます。リザーバサンプリング法を再利用するには、 WITH NUM SAMPLES文を使用します。
現在のサンプリングレートは、適応アルゴリズムに基づいて計算されます。表の行数をSHOW STATS_METAで観測できる場合は、その行数を使用して100,000行に対応するサンプリングレートを計算できます。この行数を観測できない場合は、表のSHOW TABLE REGIONSの結果のAPPROXIMATE_KEYS列目のすべての値の合計を別の基準として使用して、サンプリングレートを計算できます。
注記:
通常、
STATS_METAAPPROXIMATE_KEYSよりも信頼性が高いです。ただし、STATS_METAの結果がAPPROXIMATE_KEYS結果よりもはるかに小さい場合は、APPROXIMATE_KEYS使用してサンプリングレートを計算することをお勧めします。
統計情報を収集するためのメモリクォータ
TiDB v6.1.0 以降では、システム変数tidb_mem_quota_analyze使用して、TiDB で統計を収集するためのメモリクォータを制御できます。
適切な値tidb_mem_quota_analyzeを設定するには、クラスターのデータサイズを考慮してください。デフォルトのサンプリングレートを使用する場合、主な考慮事項は列数、列値のサイズ、およびTiDBのメモリ構成です。最大値と最小値を設定する際には、以下の推奨事項を考慮してください。
注記:
以下の提案は参考用です。実際のシナリオに基づいて値を設定する必要があります。
- 最小値: TiDBが最も多くの列を持つテーブルから統計情報を収集する場合の最大メモリ使用量よりも大きい値にする必要があります。おおよその目安: TiDBがデフォルト設定で20列のテーブルから統計情報を収集する場合、最大メモリ使用量は約800 MiBです。一方、TiDBがデフォルト設定で160列のテーブルから統計情報を収集する場合、最大メモリ使用量は約5 GiBです。
- 最大値: TiDB が統計を収集していない場合は、使用可能なメモリよりも小さくする必要があります。
ANALYZE構成を保持する
v5.4.0以降、TiDBはいくつANALYZEの設定の永続化をサポートしています。この機能により、既存の設定を将来の統計収集に簡単に再利用できます。
永続性をサポートするANALYZE構成は次のとおりです。
| 構成 | 対応するANALYZE構文 |
|---|---|
| ヒストグラムバケットの数 | WITH NUM BUCKETS |
| トップNの数 | WITH NUM TOPN |
| サンプル数 | WITH NUM SAMPLES |
| サンプリングレート | WITH FLOATNUM SAMPLERATE |
ANALYZE列タイプ | AnalyzeColumnOption ::= ( 'すべての列' |
ANALYZE列目 | 列名リスト ::= 識別子 ( ',' 識別子 )* |
ANALYZE構成の永続性を有効にする
ANALYZE構成の永続性機能はデフォルトで有効になっています (システム変数tidb_analyze_versionは2でtidb_persist_analyze_optionsデフォルトでONです)。
この機能を使用すると、 ANALYZEのステートメントを手動で実行する際に、そのステートメントで指定された永続性設定を記録できます。一度記録すると、次回 TiDB が統計を自動的に更新するとき、またはこれらの設定を指定せずに手動で統計を収集するときに、TiDB は記録された設定に従って統計を収集します。
auto analyze操作に使用される特定のテーブルに保存されている構成を照会するには、次の SQL ステートメントを使用できます。
SELECT sample_num, sample_rate, buckets, topn, column_choice, column_ids FROM mysql.analyze_options opt JOIN information_schema.tables tbl ON opt.table_id = tbl.tidb_table_id WHERE tbl.table_schema = '{db_name}' AND tbl.table_name = '{table_name}';
TiDBは、最新のANALYZEステートメントで指定された新しい設定を使用して、以前に記録された永続的な設定を上書きします。例えば、 ANALYZE TABLE t WITH 200 TOPN;のステートメントを実行すると、 ANALYZEステートメントの上位200個の値が設定されます。その後、 ANALYZE TABLE t WITH 0.1 SAMPLERATE;ステートメントを実行すると、上位200個の値と、 ANALYZE TABLE t WITH 200 TOPN, 0.1 SAMPLERATE;のステートメントと同様に、auto ANALYZEステートメントのサンプリングレート0.1が設定されます。
ANALYZE構成の永続性を無効にする
ANALYZE設定永続性機能を無効にするには、 tidb_persist_analyze_optionsシステム変数をOFFに設定します。 ANALYZE設定永続性機能はtidb_analyze_version = 1には適用されないため、 tidb_analyze_version = 1設定することでもこの機能を無効にすることができます。
ANALYZE設定永続化機能を無効にした後、TiDB は永続化された設定レコードをクリアしません。そのため、この機能を再度有効にすると、TiDB は以前に記録された永続設定を使用して統計情報を収集し続けます。
注記:
ANALYZE構成の永続性機能を再度有効にするときに、以前に記録された永続性構成が最新のデータに適用されなくなった場合は、ANALYZEステートメントを手動で実行し、新しい永続性構成を指定する必要があります。
列構成を保持する
ANALYZE文( COLUMNS ColumnNameList 、 PREDICATE COLUMNS 、 ALL COLUMNSを含む)の列設定を永続化したい場合は、システム変数tidb_persist_analyze_optionsの値をONに設定して、 構成の永続性を分析する機能を有効にします。ANALYZE 設定永続化機能を有効にした後、以下の操作を行います。
- TiDB が自動的に統計を収集する場合、または列構成を指定せずに
ANALYZEステートメントを実行して手動で統計を収集する場合、TiDB は統計収集のために以前に保持された構成を引き続き使用します。 - 列構成を指定して
ANALYZEステートメントを手動で複数回実行すると、TiDB は最新のANALYZEステートメントで指定された新しい構成を使用して、以前に記録された永続的な構成を上書きします。
統計が収集されたPREDICATE COLUMNSと列を見つけるには、 SHOW COLUMN_STATS_USAGEステートメントを使用します。
次の例では、 ANALYZE TABLE t PREDICATE COLUMNS;実行した後、 TiDB は列b 、 c 、およびdの統計を収集します。ここで、列b PREDICATE COLUMNであり、列cとdインデックス列です。
CREATE TABLE t (a INT, b INT, c INT, d INT, INDEX idx_c_d(c, d));
Query OK, 0 rows affected (0.00 sec)
-- The optimizer uses the statistics on column b in this query.
SELECT * FROM t WHERE b > 1;
Empty set (0.00 sec)
-- After waiting for a period of time (100 * stats-lease), TiDB writes the collected `PREDICATE COLUMNS` to mysql.column_stats_usage.
-- Specify `last_used_at IS NOT NULL` to show the `PREDICATE COLUMNS` collected by TiDB.
SHOW COLUMN_STATS_USAGE
WHERE db_name = 'test' AND table_name = 't' AND last_used_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+------------------+
| test | t | | b | 2022-01-05 17:21:33 | NULL |
+---------+------------+----------------+-------------+---------------------+------------------+
1 row in set (0.00 sec)
ANALYZE TABLE t PREDICATE COLUMNS;
Query OK, 0 rows affected, 1 warning (0.03 sec)
-- Specify `last_analyzed_at IS NOT NULL` to show the columns for which statistics have been collected.
SHOW COLUMN_STATS_USAGE
WHERE db_name = 'test' AND table_name = 't' AND last_analyzed_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+---------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+---------------------+
| test | t | | b | 2022-01-05 17:21:33 | 2022-01-05 17:23:06 |
| test | t | | c | NULL | 2022-01-05 17:23:06 |
| test | t | | d | NULL | 2022-01-05 17:23:06 |
+---------+------------+----------------+-------------+---------------------+---------------------+
3 rows in set (0.00 sec)
統計のバージョン
変数tidb_analyze_versionは、TiDB によって収集される統計情報を制御します。現在、統計情報のバージョンはtidb_analyze_version = 1とtidb_analyze_version = 2 2 つがサポートされています。
- TiDB Self-Managed の場合、この変数のデフォルト値は、v5.3.0 以降、
1から2に変更されます。 - TiDB Cloudの場合、この変数のデフォルト値は、v6.5.0 以降、
1から2に変更されます。 - クラスターが以前のバージョンからアップグレードされた場合、アップグレード後もデフォルト値
tidb_analyze_versionは変更されません。
バージョン2が推奨されており、今後も機能強化が続けられ、最終的にはバージョン1を完全に置き換える予定です。バージョン1と比較して、バージョン2では、より大規模なデータ量に対して収集される多くの統計情報の精度が向上しています。また、述語選択性推定のためのCount-Minスケッチ統計情報の収集が不要になり、選択された列のみの自動収集もサポートされるため、収集パフォーマンスも向上しています( いくつかの列の統計情報を収集する参照)。
次の表は、オプティマイザーの推定に使用するために各バージョンで収集される情報を示しています。
| 情報 | バージョン1 | バージョン2 |
|---|---|---|
| 表の行の総数 | ⎷ | ⎷ |
| 等号/IN述語推定 | ⎷ (カラム/ インデックス トップN & カウント最小スケッチ) | ⎷ (カラム/ インデックストップN & ヒストグラム) |
| 範囲述語推定 | ⎷ (カラム/ インデックストップN & ヒストグラム) | ⎷ (カラム/ インデックストップN & ヒストグラム) |
NULL述語推定 | ⎷ | ⎷ |
| 列の平均長さ | ⎷ | ⎷ |
| インデックスの平均長 | ⎷ | ⎷ |
統計バージョンを切り替える
すべてのテーブル/インデックス(およびパーティション)で、同じバージョンの統計情報収集を使用することをお勧めします。バージョン2の使用が推奨されますが、使用中のバージョンで問題が発生したなどの正当な理由がない限り、バージョン間の切り替えは推奨されません。バージョン間の切り替えでは、すべてのテーブルが新しいバージョンで分析されるまで、統計情報が利用できない状態が続く場合があります。統計情報が利用できない場合、オプティマイザのプラン選択に悪影響を与える可能性があります。
切り替えの正当な理由としては、バージョン1では、Count-Minスケッチ統計の収集時にハッシュ衝突が発生するため、equal/IN述語の推定に不正確な点が生じる可能性があることが挙げられます。解決策はカウントミニマムスケッチセクションに記載されています。あるいは、 tidb_analyze_version = 2設定してすべてのオブジェクトでANALYZEを再実行することも解決策の一つです。バージョン2の初期リリースでは、 ANALYZE後にメモリオーバーフローが発生するリスクがありました。この問題は解決されていますが、当初はtidb_analyze_version = 1設定してすべてのオブジェクトでANALYZE再実行するという解決策もありました。
バージョン間の切り替えを準備するにはANALYZE
ANALYZEステートメントを手動で実行する場合は、分析対象のすべてのテーブルを手動で分析します。SELECT DISTINCT(CONCAT('ANALYZE TABLE ', table_schema, '.', table_name, ';')) FROM information_schema.tables JOIN mysql.stats_histograms ON table_id = tidb_table_id WHERE stats_ver = 2;自動分析が有効になっているため、TiDB が
ANALYZEステートメントを自動的に実行する場合は、DROP STATSステートメントを生成する次のステートメントを実行します。SELECT DISTINCT(CONCAT('DROP STATS ', table_schema, '.', table_name, ';')) FROM information_schema.tables JOIN mysql.stats_histograms ON table_id = tidb_table_id WHERE stats_ver = 2;前のステートメントの結果が長すぎてコピーして貼り付けることができない場合は、結果を一時テキスト ファイルにエクスポートし、次のようにファイルから実行することができます。
SELECT DISTINCT ... INTO OUTFILE '/tmp/sql.txt'; mysql -h ${TiDB_IP} -u user -P ${TIDB_PORT} ... < '/tmp/sql.txt'
統計情報をビュー
次のステートメントを使用して、 ANALYZEステータスと統計情報を表示できます。
ANALYZE状態
ANALYZEステートメントを実行するときに、 SHOW ANALYZE STATUSを使用してANALYZEの現在の状態を表示できます。
TiDB v6.1.0以降、 SHOW ANALYZE STATUSステートメントはクラスターレベルのタスクの表示をサポートします。TiDBの再起動後でも、このステートメントを使用して再起動前のタスクレコードを表示できます。TiDB v6.1.0より前では、 SHOW ANALYZE STATUSステートメントはインスタンスレベルのタスクのみを表示でき、タスクレコードはTiDBの再起動後に消去されます。
SHOW ANALYZE STATUS最新のタスク記録のみを表示します。TiDB v6.1.0以降では、システムテーブルmysql.analyze_jobsを通じて過去7日間のタスク履歴を表示できます。
tidb_mem_quota_analyzeが設定され、TiDB のバックグラウンドで実行されている自動タスクANALYZEがこのしきい値を超えるメモリを使用すると、タスクは再試行されます。失敗したタスクと再試行されたタスクは、 SHOW ANALYZE STATUSステートメントの出力で確認できます。
tidb_max_auto_analyze_timeが 0 より大きく、TiDB バックグラウンドで実行されている自動ANALYZEタスクにこのしきい値を超える時間がかかる場合、タスクは終了します。
mysql> SHOW ANALYZE STATUS [ShowLikeOrWhere];
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| Table_schema | Table_name | Partition_name | Job_info | Processed_rows | Start_time | End_time | State | Fail_reason |
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| test | sbtest1 | | retry auto analyze table all columns with 100 topn, 0.055 samplerate | 2000000 | 2022-05-07 16:41:09 | 2022-05-07 16:41:20 | finished | NULL |
| test | sbtest1 | | auto analyze table all columns with 100 topn, 0.5 samplerate | 0 | 2022-05-07 16:40:50 | 2022-05-07 16:41:09 | failed | analyze panic due to memory quota exceeds, please try with smaller samplerate |
テーブルのメタデータ
SHOW STATS_METAステートメントを使用すると、行の合計数と更新された行の数を表示できます。
テーブルのヘルス状態
SHOW STATS_HEALTHYステートメントを使用すると、テーブルのヘルス状態を確認し、統計情報の精度を大まかに推定できます。3 >= row_count modify_count場合、ヘルス状態は 0 です。7 < row_countの場合、ヘルス状態は ( modify_count - modify_count / row_count ) * 100 です。
列のメタデータ
SHOW STATS_HISTOGRAMSステートメントを使用すると、すべての列の異なる値の数とNULLの数を表示できます。
ヒストグラムのバケット
SHOW STATS_BUCKETSステートメントを使用して、ヒストグラムの各バケットを表示できます。
トップN情報
SHOW STATS_TOPNステートメントを使用すると、現在 TiDB によって収集されている Top-N 情報を表示できます。
統計情報を削除
統計を削除するには、 DROP STATSステートメントを実行します。
負荷統計
注記:
ロード統計はクラスターTiDB CloudスターターおよびTiDB Cloudエッセンシャルでは利用できません。
デフォルトでは、列統計のサイズに応じて、TiDB は次のように異なる方法で統計をロードします。
- メモリ消費量が少ない統計 (count、distinctCount、nullCount など) の場合、列データが更新されている限り、TiDB は対応する統計を SQL 最適化ステージで使用するためにメモリに自動的にロードします。
- 大量のメモリを消費する統計(ヒストグラム、TopN、Count-Min Sketchなど)については、SQL実行のパフォーマンスを確保するため、TiDBはオンデマンドで統計を非同期的に読み込みます。ヒストグラムを例に挙げると、TiDBはオプティマイザーがその列のヒストグラム統計を使用する場合にのみ、その列のヒストグラム統計をメモリに読み込みます。オンデマンドの非同期統計読み込みはSQL実行のパフォーマンスには影響しませんが、SQL最適化に不完全な統計を提供する可能性があります。
v5.4.0以降、TiDBは統計情報の同期ロード機能を導入しました。この機能により、SQL文の実行時に、ヒストグラム、TopN、Count-Min Sketch統計などの大規模な統計情報をメモリに同期ロードできるようになり、SQL最適化における統計情報の完全性が向上します。
この機能を有効にするには、システム変数tidb_stats_load_sync_waitの値を、SQL最適化が完全な列統計情報を同期的にロードするまでの最大待機時間(ミリ秒)に設定します。この変数のデフォルト値は100で、この機能が有効であることを示します。
統計の同期読み込み機能を有効にした後、次のように機能をさらに構成できます。
- SQL最適化の待機時間がタイムアウトに達した際のTiDBの動作を制御するには、システム変数
tidb_stats_load_pseudo_timeoutの値を変更します。この変数のデフォルト値はONで、タイムアウト後、SQL最適化プロセスはどの列に対してもヒストグラム、TopN、CMSketch統計を使用しません。この変数をOFFに設定すると、タイムアウト後にSQL実行が失敗します。 - 同期ロード統計機能で同時に処理できる列の最大数を指定するには、TiDB設定ファイルの
stats-load-concurrencyオプションの値を変更します。v8.2.0以降、このオプションのデフォルト値は0で、TiDBはサーバー設定に基づいて同時実行性を自動的に調整します。 - 同期ロード統計機能がキャッシュできる列リクエストの最大数を指定するには、TiDB設定ファイルの
stats-load-queue-sizeオプションの値を変更します。デフォルト値は1000です。
TiDBの起動時、初期統計情報が完全にロードされる前に実行されるSQL文は、最適ではない実行プランを持つ可能性があり、パフォーマンスの問題を引き起こす可能性があります。このような問題を回避するために、TiDB v7.1.0では設定パラメータforce-init-statsが導入されました。このオプションを使用すると、起動時に統計情報の初期化が完了した後にのみTiDBがサービスを提供するかどうかを制御できます。v7.2.0以降では、このパラメータはデフォルトで有効になっています。
v7.1.0 以降、TiDB では軽量統計の初期化にlite-init-stats導入されています。
lite-init-statsの値がtrue場合、統計の初期化では、インデックスまたは列のヒストグラム、TopN、または Count-Min Sketch はメモリにロードされません。lite-init-statsの値がfalse場合、統計の初期化では、インデックスと主キーのヒストグラム、TopN、Count-Min Sketch がメモリにロードされますが、主キー以外の列のヒストグラム、TopN、Count-Min Sketch はメモリにロードされません。オプティマイザーが特定のインデックスまたは列のヒストグラム、TopN、Count-Min Sketch を必要とする場合、必要な統計は同期的または非同期的にメモリにロードされます。
デフォルト値はlite-init-stats true 、これは軽量な統計情報の初期化を有効にすることを意味します。5 からlite-init-stats true設定すると、統計情報の初期化が高速化され、不要な統計情報の読み込みが回避されるため、TiDB のメモリ使用量が削減されます。
輸出入統計
このセクションでは、統計をエクスポートおよびインポートする方法について説明します。
輸出統計
統計をエクスポートするためのインターフェースは次のとおりです。
${db_name}データベース内の${table_name}テーブルの JSON 形式の統計を取得するには:http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}例えば:
curl -s http://127.0.0.1:10080/stats/dump/test/t1 -o /tmp/t1.json特定の時間における
${db_name}データベース内の${table_name}のテーブルの JSON 形式の統計を取得するには:http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyyMMddHHmmss}
輸入統計
注記:
MySQL クライアントを起動するときは、
--local-infile=1オプションを使用します。
通常、インポートされた統計は、エクスポート インターフェイスを使用して取得された JSON ファイルを参照します。
統計のロードはLOAD STATSステートメントで実行できます。
例えば:
LOAD STATS 'file_name';
file_nameはインポートする統計のファイル名です。
ロック統計
v6.5.0以降、TiDBは統計情報のロックをサポートしています。テーブルまたはパーティションの統計情報がロックされると、そのテーブルの統計情報を変更できなくなり、そのテーブルに対してANALYZE文を実行することもできなくなります。例えば:
テーブルtを作成し、そこにデータを挿入します。テーブルtの統計情報がロックされていない場合、 ANALYZEステートメントは正常に実行できます。
mysql> CREATE TABLE t(a INT, b INT);
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO t VALUES (1,2), (3,4), (5,6), (7,8);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "Row count in stats_meta is much smaller compared with the row count got by PD, use min(1, 15000/4) as the sample-rate=1" |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
テーブルtの統計情報をロックし、 ANALYZE実行します。警告メッセージには、 ANALYZEステートメントがテーブルtスキップしたことが示されています。
mysql> LOCK STATS t;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATS_LOCKED;
+---------+------------+----------------+--------+
| Db_name | Table_name | Partition_name | Status |
+---------+------------+----------------+--------+
| test | t | | locked |
+---------+------------+----------------+--------+
1 row in set (0.01 sec)
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> SHOW WARNINGS;
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "use min(1, 110000/8) as the sample-rate=1" |
| Warning | 1105 | skip analyze locked table: test.t |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
表tおよびANALYZE統計のロックを解除すると、再度正常に実行できるようになります。
mysql> UNLOCK STATS t;
Query OK, 0 rows affected (0.01 sec)
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "use min(1, 110000/8) as the sample-rate=1" |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
さらに、 LOCK STATS使用してパーティションの統計情報をロックすることもできます。例:
パーティションテーブルtを作成し、そこにデータを挿入します。パーティションp1の統計情報がロックされていない場合、 ANALYZEステートメントは正常に実行できます。
mysql> CREATE TABLE t(a INT, b INT) PARTITION BY RANGE (a) (PARTITION p0 VALUES LESS THAN (10), PARTITION p1 VALUES LESS THAN (20), PARTITION p2 VALUES LESS THAN (30));
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO t VALUES (1,2), (3,4), (5,6), (7,8);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 6 warning (0.02 sec)
mysql> SHOW WARNINGS;
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p0, reason to use this rate is "Row count in stats_meta is much smaller compared with the row count got by PD, use min(1, 15000/4) as the sample-rate=1" |
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p2, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
6 rows in set (0.01 sec)
パーティションp1の統計情報をロックし、 ANALYZE実行します。警告メッセージには、 ANALYZEステートメントがパーティションp1スキップしたことが示されています。
mysql> LOCK STATS t PARTITION p1;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATS_LOCKED;
+---------+------------+----------------+--------+
| Db_name | Table_name | Partition_name | Status |
+---------+------------+----------------+--------+
| test | t | p1 | locked |
+---------+------------+----------------+--------+
1 row in set (0.00 sec)
mysql> ANALYZE TABLE t PARTITION p1;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> SHOW WARNINGS;
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
| Warning | 1105 | skip analyze locked table: test.t partition (p1) |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
パーティションp1とANALYZE統計のロック解除を再度正常に実行できます。
mysql> UNLOCK STATS t PARTITION p1;
Query OK, 0 rows affected (0.00 sec)
mysql> ANALYZE TABLE t PARTITION p1;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> SHOW WARNINGS;
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
統計情報のロックの動作
- パーティションテーブルの統計をロックすると、パーティションテーブルのすべてのパーティションの統計がロックされます。
- テーブルまたはパーティションを切り捨てると、テーブルまたはパーティションの統計ロックが解除されます。
次の表は、統計のロックの動作を示しています。
| テーブル全体を削除する | テーブル全体を切り捨てる | パーティションを切り捨てる | 新しいパーティションを作成する | パーティションを削除する | パーティションを再編成する | パーティションを交換する | |
|---|---|---|---|---|---|---|---|
| パーティションテーブルがロックされている | ロックが無効です | TiDBは古いテーブルを削除するためロックは無効であり、ロック情報も削除される。 | / | / | / | / | / |
| パーティションテーブルとテーブル全体がロックされている | ロックが無効です | TiDBは古いテーブルを削除するためロックは無効であり、ロック情報も削除される。 | 古いパーティションのロック情報は無効であり、新しいパーティションは自動的にロックされます | 新しいパーティションは自動的にロックされます | 削除されたパーティションのロック情報はクリアされ、テーブル全体のロックは引き続き有効になります。 | 削除されたパーティションのロック情報はクリアされ、新しいパーティションは自動的にロックされます。 | ロック情報は交換されたテーブルに転送され、新しいパーティションは自動的にロックされます。 |
| パーティションテーブルで、一部のパーティションのみがロックされている | ロックが無効です | TiDBは古いテーブルを削除するためロックは無効であり、ロック情報も削除される。 | TiDBは古いテーブルを削除するためロックは無効であり、ロック情報も削除される。 | / | 削除されたパーティションのロック情報はクリアされます | 削除されたパーティションのロック情報はクリアされます | ロック情報は交換テーブルに転送される |
ANALYZEタスクと同時実行を管理する
このセクションでは、バックグラウンドANALYZEタスクを終了し、 ANALYZE同時実行を制御する方法について説明します。
バックグラウンドのANALYZEタスクを終了する
TiDB v6.0以降、TiDBはKILLのステートメントを使用して、バックグラウンドで実行されているANALYZEタスクを終了できるようになりました。バックグラウンドで実行されているANALYZEタスクが大量のリソースを消費し、アプリケーションに影響を与える場合は、次の手順でANALYZEタスクを終了できます。
次の SQL ステートメントを実行します。
SHOW ANALYZE STATUS結果の
instance列目とprocess_id列目を確認すると、TiDB インスタンスのアドレスと、バックグラウンドANALYZEタスクのタスクID取得できます。バックグラウンドで実行されている
ANALYZEタスクを終了します。enable-global-killがtrue(デフォルトではtrue) の場合、KILL TIDB ${id};ステートメントを直接実行できます。ここで、${id}前の手順で取得されたバックグラウンドANALYZEタスクのIDです。enable-global-killがfalse場合、クライアントを使用してバックエンドANALYZEタスクを実行している TiDB インスタンスに接続し、KILL TIDB ${id};文を実行する必要があります。クライアントを使用して別の TiDB インスタンスに接続している場合、またはクライアントと TiDB クラスタの間にプロキシがある場合、KILL文ではバックグラウンドANALYZEタスクを終了できません。
KILLステートメントの詳細については、 KILL参照してください。
ANALYZE同時実行を制御する
ANALYZEステートメントを実行すると、システム変数を使用して同時実行性を調整し、システムへの影響を制御できます。
関連するシステム変数の関係を以下に示します。

上図に示すように、 tidb_build_stats_concurrency 、 tidb_build_sampling_stats_concurrency 、 tidb_analyze_partition_concurrency上流と下流の関係にあります。実際の合計同時実行数はtidb_build_stats_concurrency * ( tidb_build_sampling_stats_concurrency + tidb_analyze_partition_concurrency ) です。これらの変数を変更する際には、それぞれの値も同時に考慮する必要があります。 tidb_analyze_partition_concurrency 、 tidb_build_sampling_stats_concurrency 、 tidb_build_stats_concurrencyの順に1つずつ調整し、システムへの影響を確認することをお勧めします。これらの3つの変数の値が大きいほど、システムへのリソースオーバーヘッドが大きくなります。
tidb_build_stats_concurrency
ANALYZEステートメントを実行すると、タスクは複数の小さなタスクに分割されます。各タスクは、1つの列またはインデックスの統計情報のみを処理します。3 変数tidb_build_stats_concurrency使用して、同時に実行する小さなタスクの数を制御できます。デフォルト値は2です。v7.4.0 以前のバージョンでは、デフォルト値は4です。
tidb_build_sampling_stats_concurrency
通常の列を分析する場合、サンプリングタスクの同時実行を制御するためにtidb_build_sampling_stats_concurrency指定できます。デフォルト値は2です。
tidb_analyze_partition_concurrency
ANALYZEステートメントを実行する際に、パーティションテーブルの統計情報の読み取りと書き込みの同時実行を制御するためにtidb_analyze_partition_concurrency使用できます。デフォルト値は2です。v7.4.0 以前のバージョンでは、デフォルト値は1です。
tidb_distsql_scan_concurrency
通常の列を分析する場合、変数tidb_distsql_scan_concurrencyを使って一度に読み取るリージョンの数を制御できます。デフォルト値は15です。値を変更するとクエリのパフォーマンスに影響することに注意してください。値は慎重に調整してください。
tidb_index_serial_scan_concurrency
インデックス列を分析する際に、変数tidb_index_serial_scan_concurrencyを使って一度に読み取るリージョンの数を制御できます。デフォルト値は1です。この値を変更するとクエリのパフォーマンスに影響することに注意してください。値は慎重に調整してください。