統計入門
TiDB は、統計情報をオプティマイザへの入力として使用し、SQL ステートメントの各プラン ステップで処理される行数を推定します。オプティマイザは、利用可能な各プランのコストを推定し、インデックスアクセスやテーブル結合の順序などを含め、利用可能な各プランのコストを算出します。その後、オプティマイザは、全体のコストが最も低い実行プランを選択します。
統計情報を収集する
このセクションでは、統計情報を収集する2つの方法、すなわち自動更新と手動収集について説明します。
自動更新
INSERT 、 DELETE 、またはUPDATE文の場合、TiDBは統計情報内の行数と変更された行数を自動的に更新します。
TiDB は更新情報を定期的に保持し、更新サイクルは 20 * stats-leaseです。 stats-leaseのデフォルト値は3sです。値を0と指定すると、TiDB は統計情報の自動更新を停止します。
TiDBは、テーブルへの変更回数に基づいて、自動的にANALYZEを実行して該当テーブルの統計情報を収集します。これは、以下のシステム変数によって制御されます。
テーブル内のtblの変更された行数と総行数の比率がtidb_auto_analyze_ratioより大きく、かつ現在時刻がtidb_auto_analyze_start_timeとtidb_auto_analyze_end_timeの間である場合、TiDB はバックグラウンドでANALYZE TABLE tblステートメントを実行して、このテーブルの統計情報を自動的に更新します。
小さなテーブルのデータを変更すると、自動更新が頻繁にトリガーされる状況を避けるため、TiDB では、テーブルの行数が 1000 行未満の場合、変更によって自動更新がトリガーされません。テーブルの行数を確認するには、 SHOW STATS_METAステートメントを使用できます。
手動収集
現在、TiDB は統計情報を完全なコレクションとして収集します。統計情報を収集するには、 ANALYZE TABLEステートメントを実行してください。
以下の構文を使用すると、完全なデータ収集を実行できます。
TableNameList内のすべてのテーブルの統計情報を収集するには:ANALYZE TABLE TableNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];WITH NUM BUCKETS生成されるヒストグラムのバケットの最大数を指定します。WITH NUM TOPN生成されるTOPNの最大数を指定します。WITH NUM CMSKETCH DEPTHCM スケッチの深さを指定します。WITH NUM CMSKETCH WIDTHCM スケッチの幅を指定します。WITH NUM SAMPLESサンプル数を指定します。WITH FLOAT_NUM SAMPLERATEはサンプリングレートを指定します。
WITH NUM SAMPLESとWITH FLOAT_NUM SAMPLERATEは、サンプルを収集する2つの異なるアルゴリズムに対応しています。
詳細な説明については、ヒストグラム、トップN 、 CMSketch (Count-Min Sketch) を参照してください。 SAMPLES / SAMPLERATEについては、収集パフォーマンスを向上させるください。
再利用を容易にするためにオプションを永続化する方法については、 ANALYZE構成を永続化するを参照してください。
統計の種類
このセクションでは、ヒストグラム、カウントミニスケッチ、トップNという3種類の統計について説明します。
ヒストグラム
ヒストグラム統計は、オプティマイザが区間または範囲述語の選択性を推定するために使用され、また、統計のバージョン 2 で等号/IN 述語を推定するために列内の異なる値の数を決定するためにも使用される場合があります (統計統計のバージョンを参照)。
ヒストグラムは、データの分布を近似的に表現したものです。値の全範囲を複数のバケットに分割し、各バケットに含まれる値の数など、単純なデータを用いて各バケットを記述します。TiDBでは、各テーブルの特定の列に対して等深ヒストグラムが作成されます。この等深ヒストグラムは、区間クエリの推定に利用できます。
ここで「等深」とは、各バケットに入る値の数が可能な限り均等になることを意味します。たとえば、与えられたセット {1.6, 1.9, 1.9, 2.0, 2.4, 2.6, 2.7, 2.7, 2.8, 2.9, 3.4, 3.5} に対して、4 つのバケットを生成したいとします。等深ヒストグラムは次のようになります。これには [1.6, 1.9]、[2.0, 2.6]、[2.7, 2.8]、[2.9, 3.5] の 4 つのバケットが含まれます。バケットの深さは 3 です。
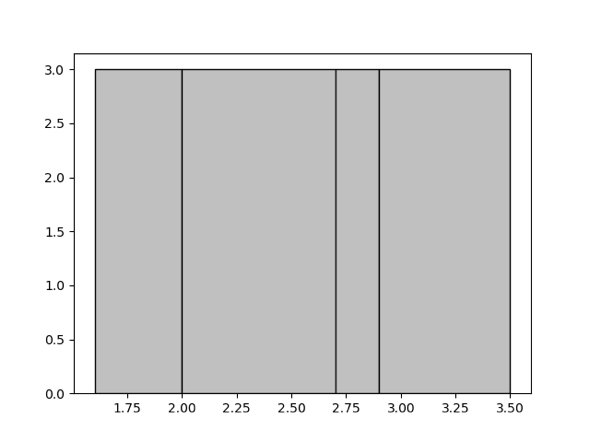
ヒストグラムのバケット数の上限を決定するパラメータの詳細については手動収集を参照してください。 バケット数が多いほどヒストグラムの精度は高くなりますが、精度が高いほどメモリリソースの使用量が増加します。実際の状況に応じて、この数値を適切に調整してください。
カウントミニスケッチ
Count-Min Sketch はハッシュ構造です。 a = 1やINクエリ (例えばa IN (1, 2, 3) ) のような等価性クエリを処理する際、TiDB はこのデータ構造を使用して推定を行います。
Count-Min Sketch はハッシュ構造であるため、ハッシュ衝突が発生する可能性があります。EXPLAIN EXPLAINにおいて、同等のクエリの推定値が実際の値から大きく乖離する場合、より大きな値とより小さな値がハッシュ化されているとみなすことができます。この場合、ハッシュ衝突を回避するために、以下のいずれかの方法を取ることができます。
WITH NUM TOPNパラメータを変更します。TiDB は、高頻度 (上位 x) のデータを別々に格納し、その他のデータは Count-Min Sketch に格納します。そのため、より大きな値とより小さな値が一緒にハッシュ化されるのを防ぐには、WITH NUM TOPNの値を増やすことができます。TiDB では、デフォルト値は 20 です。最大値は 1024 です。このパラメータの詳細については、 を参照手動収集てください。WITH NUM CMSKETCH DEPTHとWITH NUM CMSKETCH WIDTHの 2 つのパラメータを変更します。どちらもハッシュ バケットの数と衝突確率に影響します。実際のシナリオに応じて 2 つのパラメータの値を適切に増やすことでハッシュ衝突の確率を減らすことができますが、統計情報のメモリ使用量が増加します。TiDB では、WITH NUM CMSKETCH DEPTHのデフォルト値は 5、WITH NUM CMSKETCH WIDTHのデフォルト値は 2048 です。2 つのパラメータの詳細については、 を参照手動収集てください。
トップN
トップN値とは、列またはインデックス内で出現頻度が最も高いN個の値のことです。トップN統計は、頻度統計またはデータスキューと呼ばれることもあります。
TiDB は上位 N 個の値とその出現回数を記録します。ここではNはWITH NUM TOPNパラメータによって制御されます。デフォルト値は 20 で、これは最も頻繁に出現する上位 20 個の値が収集されることを意味します。最大値は 1024 です。パラメータの詳細については、 を参照手動収集てください。
選択的統計収集
このセクションでは、統計データを選択的に収集する方法について説明します。
指標に関する統計情報を収集する
IndexNameList TableName内のすべてのインデックスに関する統計情報を収集するには、次の構文を使用します。
ANALYZE TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
IndexNameListが空の場合、この構文はTableName内のすべてのインデックスに関する統計情報を収集します。
いくつかの列の統計情報を収集する
TiDB が SQL ステートメントを実行する際、オプティマイザはほとんどの場合、一部の列のみの統計情報を使用します。たとえば、 WHERE 、 JOIN 、 ORDER BY 、およびGROUP BY句に現れる列などです。これらの列は述語列と呼ばれます。
テーブルに多数の列がある場合、すべての列の統計情報を収集すると、大きなオーバーヘッドが発生する可能性があります。オーバーヘッドを削減するには、オプティマイザで使用する特定の列(選択した列)またはPREDICATE COLUMNSのみの統計情報を収集できます。列のサブセットの列リストを将来再利用するために保持するには、列構成を保持する参照してください。
特定の列に関する統計情報を収集するには、次の構文を使用します。
ANALYZE TABLE TableName COLUMNS ColumnNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];構文では、
ColumnNameList対象列の名前リストを指定します。複数の列を指定する必要がある場合は、列名をカンマ,で区切ります。たとえば、ANALYZE table t columns a, bのように指定します。この構文では、特定のテーブルの特定の列に関する統計情報を収集するだけでなく、そのテーブルのインデックス付き列とすべてのインデックスに関する統計情報も同時に収集します。PREDICATE COLUMNSに関する統計情報を収集するには、次の構文を使用します。ANALYZE TABLE TableName PREDICATE COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];TiDB は常に
PREDICATE COLUMNS情報を 100 *stats-leaseごとにmysql.column_stats_usageシステム テーブルに書き込みます。この構文は、特定のテーブル内の
PREDICATE COLUMNSに関する統計情報を収集するだけでなく、そのテーブル内のインデックス付き列とすべてのインデックスに関する統計情報も同時に収集します。すべての列とインデックスに関する統計情報を収集するには、次の構文を使用します。
ANALYZE TABLE TableName ALL COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
パーティションに関する統計情報を収集する
PartitionNameList内のTableName内のすべてのパーティションに関する統計情報を収集するには、次の構文を使用します。ANALYZE TABLE TableName PARTITION PartitionNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];PartitionNameListTableNameのすべてのパーティションのインデックス統計情報を収集するには、次の構文を使用します。ANALYZE TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];テーブル内のいくつかのパーティションのいくつかの列の統計情報を収集する必要がある場合は、次の構文を使用します。
ANALYZE TABLE TableName PARTITION PartitionNameList [COLUMNS ColumnNameList|PREDICATE COLUMNS|ALL COLUMNS] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
動的プルーニングモードでパーティションテーブルの統計情報を収集する
TiDB は、パーティション分割されたテーブルに、パーティション 動的剪定モード(v6.3.0 以降はデフォルト) でアクセスする場合、テーブルレベルの統計情報、つまりパーティション分割されたテーブルのグローバル統計情報を収集します。現在、グローバル統計情報は、すべてのパーティションの統計情報を集計したものです。動的プルーニングモードでは、テーブルのいずれかのパーティションの統計情報が更新されると、そのテーブルのグローバル統計情報も更新される可能性があります。
一部のパーティションの統計情報が空の場合、または一部のパーティションで一部の列の統計情報が欠落している場合、収集動作はtidb_skip_missing_partition_stats変数によって制御されます。
グローバル統計の更新がトリガーされ、
tidb_skip_missing_partition_statsがOFFの場合:一部のパーティションに統計情報がない場合(例えば、これまで分析されたことのない新しいパーティションなど)、グローバル統計情報の生成は中断され、パーティションに統計情報が存在しないことを示す警告メッセージが表示されます。
特定のパーティションで一部の列の統計情報が存在しない場合(これらのパーティションでは、分析対象として異なる列が指定されています)、これらの列の統計情報が集計される際にグローバル統計情報の生成が中断され、特定のパーティションで一部の列の統計情報が存在しないことを示す警告メッセージが表示されます。
グローバル統計の更新がトリガーされ、
tidb_skip_missing_partition_statsがONの場合:- 一部のパーティションで、すべての列または一部の列の統計情報が欠落している場合、TiDB はグローバル統計情報の生成時にこれらの欠落したパーティション統計情報をスキップするため、グローバル統計情報の生成には影響しません。
動的プルーニングモードでは、パーティションとテーブルのANALYZE構成は同じである必要があります。したがって、 COLUMNSステートメントの後にANALYZE TABLE TableName PARTITION PartitionNameList }構成を指定した場合、またはOPTIONSの後にWITH }構成を指定した場合、TiDBはそれらを無視して警告を返します。
収集パフォーマンスを向上させる
TiDBは、統計情報の収集パフォーマンスを向上させるための2つのオプションを提供します。
- 列のサブセットに関する統計を収集します。いくつかの列に関する統計情報を収集するご覧ください。
- サンプリング。
統計サンプリング
サンプリングはANALYZEステートメントの 2 つのオプションで利用可能であり、それぞれ異なる収集アルゴリズムに対応しています。
WITH NUM SAMPLESTiDB のリザーバーサンプリング方式で実装されているサンプリングセットのサイズを指定します。テーブルが大きい場合、この方式を使用して統計情報を収集することは推奨されません。リザーバーサンプリングの中間結果セットには冗長な結果が含まれるため、メモリなどのリソースに余分な負荷がかかります。WITH FLOAT_NUM SAMPLERATEは、v5.3.0 で導入されたサンプリング方法です。値の範囲(0, 1]を指定することで、サンプリングレートを設定できます。TiDB ではベルヌーイサンプリング方式で実装されており、大規模なテーブルのサンプリングに適しており、収集効率とリソース使用量の面で優れたパフォーマンスを発揮します。
バージョン5.3.0より前は、TiDBはリザーバーサンプリング方式を使用して統計情報を収集していました。バージョン5.3.0以降、TiDBバージョン2の統計情報は、デフォルトでベルヌーイサンプリング方式を使用して統計情報を収集します。リザーバーサンプリング方式を再利用するには、 WITH NUM SAMPLESステートメントを使用できます。
現在のサンプリングレートは、適応アルゴリズムに基づいて計算されます。SHOW STATS_METAを使用してテーブルの行数を確認できる場合は、その行数を使用して 100,000 行に対応するサンプリングレートを計算できます。この行数を確認できない場合は、テーブルのSHOW TABLE REGIONSの結果にあるAPPROXIMATE_KEYS列のすべての値の合計を、サンプリングレートを計算するための別の参照値として使用できます。
統計情報を収集するためのメモリ割り当て
TiDB v6.1.0以降では、システム変数tidb_mem_quota_analyzeを使用して、TiDBで統計情報を収集するためのメモリ割り当てを制御できます。
tidb_mem_quota_analyzeの適切な値を設定するには、クラスタのデータサイズを考慮してください。デフォルトのサンプリングレートを使用する場合、主な考慮事項は、列数、列値のサイズ、および TiDB のメモリ構成です。最大値と最小値を設定する際には、次の提案を参考にしてください。
- 最小値:TiDBが列数が最も多いテーブルから統計情報を収集する際の最大メモリ使用量よりも大きくする必要があります。目安として、デフォルト設定で20列のテーブルから統計情報を収集する場合、最大メモリ使用量は約800 MiBです。また、デフォルト設定で160列のテーブルから統計情報を収集する場合、最大メモリ使用量は約5 GiBです。
- 最大値:TiDBが統計情報を収集していないときは、利用可能なメモリよりも小さくする必要があります。
ANALYZE構成を永続化する
バージョン5.4.0以降、TiDBは一部のANALYZE設定の永続化をサポートしています。この機能により、既存の設定を今後の統計情報収集に簡単に再利用できます。
永続性をサポートするANALYZE構成は以下のとおりです。
ANALYZE構成の永続性を有効にする
ANALYZE構成永続化機能はデフォルトで有効になっています (システム変数tidb_analyze_versionはデフォルトで2であり、 tidb_persist_analyze_optionsはデフォルトでONです)。
この機能を使用すると、 ANALYZEステートメントを手動で実行する際に、そのステートメントで指定された永続化構成を記録できます。一度記録すると、次回 TiDB が統計情報を自動的に更新する場合、またはこれらの構成を指定せずに手動で統計情報を収集する場合、TiDB は記録された構成に従って統計情報を収集します。
auto analyze操作に使用される特定のテーブルに保持されている構成を照会するには、次の SQL ステートメントを使用できます。
SELECT sample_num, sample_rate, buckets, topn, column_choice, column_ids FROM mysql.analyze_options opt JOIN information_schema.tables tbl ON opt.table_id = tbl.tidb_table_id WHERE tbl.table_schema = '{db_name}' AND tbl.table_name = '{table_name}';
TiDB は、最新のANALYZEステートメントで指定された新しい構成を使用して、以前に記録された永続構成を上書きします。たとえば、 ANALYZE TABLE t WITH 200 TOPN;を実行すると、 ANALYZEステートメントの上位 200 個の値が設定されます。その後、 ANALYZE TABLE t WITH 0.1 SAMPLERATE;を実行すると、 ANALYZEと同様に、自動ANALYZE TABLE t WITH 200 TOPN, 0.1 SAMPLERATE; 。
ANALYZE構成の永続化を無効にする
ANALYZE構成永続化機能を無効にするには、 tidb_persist_analyze_optionsシステム変数をOFFに設定します。 ANALYZE構成永続化機能はtidb_analyze_version = 1には適用されないため、 tidb_analyze_version = 1を設定することでもこの機能を無効にできます。
ANALYZE構成永続化機能を無効にした後も、TiDBは永続化された構成レコードをクリアしません。そのため、この機能を再度有効にすると、TiDBは以前に記録された永続化構成を使用して統計情報の収集を継続します。
列構成を保持する
ANALYZEステートメント ( COLUMNS ColumnNameList 、{{B-PLACEHOLDER-2-PLACEHOLDER- PREDICATE COLUMNSを含む) の列構成を永続化する場合は、 tidb_persist_analyze_options ALL COLUMNS変数の値をONに設定して構成の永続性を分析する機能を有効にします。 ANALYZE 構成永続化機能を有効にした後:
- TiDB が統計情報を自動的に収集する場合、または列構成を指定せずに
ANALYZEステートメントを実行して手動で統計情報を収集する場合、TiDB は統計情報の収集に以前に保持された構成を引き続き使用します。 - 列構成を指定して
ANALYZEステートメントを手動で複数回実行すると、TiDB は最新のANALYZEステートメントで指定された新しい構成を使用して、以前に記録された永続構成を上書きします。
PREDICATE COLUMNSおよび統計情報が収集された列を特定するには、 SHOW COLUMN_STATS_USAGEステートメントを使用します。
次の例では、 ANALYZE TABLE t PREDICATE COLUMNS;を実行した後、TiDB は列b 、 c 、およびdの統計情報を収集します。ここで、列bはPREDICATE COLUMNであり、列cおよびdはインデックス列です。
CREATE TABLE t (a INT, b INT, c INT, d INT, INDEX idx_c_d(c, d));
Query OK, 0 rows affected (0.00 sec)
-- The optimizer uses the statistics on column b in this query.
SELECT * FROM t WHERE b > 1;
Empty set (0.00 sec)
-- After waiting for a period of time (100 * stats-lease), TiDB writes the collected `PREDICATE COLUMNS` to mysql.column_stats_usage.
-- Specify `last_used_at IS NOT NULL` to show the `PREDICATE COLUMNS` collected by TiDB.
SHOW COLUMN_STATS_USAGE
WHERE db_name = 'test' AND table_name = 't' AND last_used_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+------------------+
| test | t | | b | 2022-01-05 17:21:33 | NULL |
+---------+------------+----------------+-------------+---------------------+------------------+
1 row in set (0.00 sec)
ANALYZE TABLE t PREDICATE COLUMNS;
Query OK, 0 rows affected, 1 warning (0.03 sec)
-- Specify `last_analyzed_at IS NOT NULL` to show the columns for which statistics have been collected.
SHOW COLUMN_STATS_USAGE
WHERE db_name = 'test' AND table_name = 't' AND last_analyzed_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+---------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+---------------------+
| test | t | | b | 2022-01-05 17:21:33 | 2022-01-05 17:23:06 |
| test | t | | c | NULL | 2022-01-05 17:23:06 |
| test | t | | d | NULL | 2022-01-05 17:23:06 |
+---------+------------+----------------+-------------+---------------------+---------------------+
3 rows in set (0.00 sec)
統計のバージョン
tidb_analyze_version変数は、TiDB によって収集される統計情報を制御します。現在、TiDB はtidb_analyze_version = 1とtidb_analyze_version = 2 2 つの統計バージョンをサポートしています。
- TiDB Self-Managedの場合、v5.3.0以降、この変数のデフォルト値が
1から2に変更されます。 - TiDB Cloudの場合、v6.5.0 以降、この変数のデフォルト値が
1から2に変更されます。 - クラスターを以前のバージョンからアップグレードした場合、
tidb_analyze_versionのデフォルト値はアップグレード後も変更されません。
バージョン2は推奨される統計バージョンです。バージョン1と比較して、バージョン2ではデータ量が多い場合の多くの統計情報の精度が向上しています。また、バージョン2ではCount-Minスケッチ統計情報を収集する必要がなくなったため、収集パフォーマンスも向上しています。
以下の表は、最適化推定に使用するために各バージョンで収集された情報の一覧です。
統計バージョンの切り替え
すべてのテーブル、インデックス、パーティションで同じ統計バージョンを使用することをお勧めします。クラスタでまだ統計バージョン1を使用している場合は、できるだけ早く統計バージョン2に移行してください。テーブル、インデックス、パーティションなどのオブジェクトに対してバージョン2の統計が収集されるまで、TiDBはそのオブジェクトに対して既存のバージョン1の統計を引き続き使用します。
移行の主な理由の1つは、Count-Min Sketchでハッシュ衝突が発生する可能性があるため、バージョン1ではequal/IN述語の推定値が不正確になる可能性があることです。詳細については、カウントミニスケッチ参照してください。この問題を回避するには、 tidb_analyze_version = 2を設定し、すべてのオブジェクトでANALYZEを再実行してください。
統計バージョン1から統計バージョン2への移行準備として、 ANALYZEを準備します。
ANALYZEステートメントを手動で実行する場合は、分析対象のすべてのテーブルを手動で分析します。SELECT DISTINCT(CONCAT('ANALYZE TABLE ', table_schema, '.', table_name, ';')) FROM information_schema.tables JOIN mysql.stats_histograms ON table_id = tidb_table_id WHERE stats_ver = 1;自動分析が有効になっているため、TiDB が
ANALYZEステートメントを自動的に実行する場合、tidb_analyze_version = 2を設定すると、TiDB は後続の自動分析を通じて統計情報をバージョン 2 に徐々に更新します。オブジェクトに対してバージョン 2 の統計情報が収集されるまでは、TiDB は既存のバージョン 1 の統計情報を引き続き使用できます。重要なオブジェクトの移行を高速化するには、それらのオブジェクトに対してANALYZEを手動で実行してください。前述のステートメントの結果が長すぎてコピー&ペーストできない場合は、結果を一時的なテキストファイルにエクスポートし、そのファイルから次のように実行できます。
SELECT DISTINCT ... INTO OUTFILE '/tmp/sql.txt'; mysql -h ${TiDB_IP} -u user -P ${TIDB_PORT} ... < '/tmp/sql.txt'
統計情報を表示する
ANALYZEの状態と統計情報は、以下のステートメントを使用して表示できます。
状態ANALYZE
ANALYZEステートメントを実行すると、 SHOW ANALYZE STATUSを使用してANALYZEの現在の状態を表示できます。
TiDB v6.1.0 以降では、 SHOW ANALYZE STATUSステートメントでクラスタレベルのタスクを表示できるようになりました。TiDB を再起動した後でも、このステートメントを使用すれば再起動前のタスクレコードを表示できます。TiDB v6.1.0 より前では、 SHOW ANALYZE STATUSステートメントではインスタンスレベルのタスクしか表示できず、TiDB の再起動後にタスクレコードはクリアされていました。
SHOW ANALYZE STATUSには、最新のタスク記録のみが表示されます。TiDB v6.1.0 以降では、システムテーブルmysql.analyze_jobsを通じて、過去 7 日間の履歴タスクを表示できます。
tidb_mem_quota_analyzeが設定されていて、TiDB のバックグラウンドで実行されている自動タスクANALYZEこのしきい値を超えるメモリを使用している場合、タスクは再試行されます。失敗したタスクと再試行されたタスクはSHOW ANALYZE STATUSステートメントの出力で確認できます。
tidb_max_auto_analyze_timeが 0 より大きく、TiDB のバックグラウンドで実行されている自動ANALYZEタスクがこのしきい値を超える時間がかかった場合、タスクは終了します。
mysql> SHOW ANALYZE STATUS [ShowLikeOrWhere];
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| Table_schema | Table_name | Partition_name | Job_info | Processed_rows | Start_time | End_time | State | Fail_reason |
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| test | sbtest1 | | retry auto analyze table all columns with 100 topn, 0.055 samplerate | 2000000 | 2022-05-07 16:41:09 | 2022-05-07 16:41:20 | finished | NULL |
| test | sbtest1 | | auto analyze table all columns with 100 topn, 0.5 samplerate | 0 | 2022-05-07 16:40:50 | 2022-05-07 16:41:09 | failed | analyze panic due to memory quota exceeds, please try with smaller samplerate |
テーブルのメタデータ
SHOW STATS_METAステートメントを使用すると、行の総数と更新された行の数を表示できます。
テーブルの健康状態
SHOW STATS_HEALTHYステートメントを使用すると、テーブルの健全性状態を確認し、統計情報の精度を概算できます。 modify_count >= row_countの場合、健全性状態は 0 です。 modify_count < row_countの場合、健全性状態は (1 - modify_count / row_count ) * 100 です。
列のメタデータ
SHOW STATS_HISTOGRAMSステートメントを使用すると、すべての列における異なる値の数とNULLの数を表示できます。
ヒストグラムのバケット
SHOW STATS_BUCKETSステートメントを使用すると、ヒストグラムの各バケットを表示できます。
トップN情報
SHOW STATS_TOPNステートメントを使用すると、TiDB が現在収集しているトップ N 情報を表示できます。
統計情報を削除する
統計情報を削除するには、DROP STATSステートメントを実行します。
負荷統計
デフォルトでは、列統計のサイズに応じて、TiDB は次のように異なる方法で統計情報をロードします。
- メモリ使用量が少ない統計情報(count、distinctCount、nullCountなど)については、列データが更新される限り、TiDBは対応する統計情報を自動的にメモリにロードし、SQL最適化段階で使用します。
- メモリを大量に消費する統計情報(ヒストグラム、TopN、Count-Min Sketchなど)については、SQL実行のパフォーマンスを確保するため、TiDBは必要に応じて非同期で統計情報をロードします。ヒストグラムを例にとると、TiDBはオプティマイザがその列のヒストグラム統計情報を使用する場合にのみ、その列のヒストグラム統計情報をメモリにロードします。オンデマンドの非同期統計情報ロードはSQL実行のパフォーマンスには影響しませんが、SQL最適化に必要な統計情報が不完全になる可能性があります。
TiDBはバージョン5.4.0以降、統計情報の同期読み込み機能を導入しました。この機能により、SQL文の実行時に、ヒストグラム、TopN、Count-Min Sketch統計情報などの大規模な統計情報をメモリに同期的に読み込むことが可能になり、SQL最適化のための統計情報の網羅性が向上します。
この機能を有効にするには、 tidb_stats_load_sync_waitシステム変数の値を、SQL 最適化が完全な列統計情報を同期的にロードするために待機できる最大時間 (ミリ秒単位) に設定します。この変数のデフォルト値は100で、この機能が有効になっていることを示します。
同期的に統計情報を読み込む機能を有効にした後、以下のようにさらに設定を行うことができます。
- SQL最適化の待機時間がタイムアウトに達したときのTiDBの動作を制御するには、
tidb_stats_load_pseudo_timeoutシステム変数の値を変更します。この変数のデフォルト値はONで、タイムアウト後、SQL最適化プロセスではどの列に対してもヒストグラム、TopN、またはCMSketch統計情報を使用しないことを示します。この変数をOFFに設定すると、タイムアウト後にSQLの実行が失敗します。 - 同期的に統計情報をロードする機能が同時に処理できる列の最大数を指定するには、TiDB 設定ファイルの
stats-load-concurrencyオプションの値を変更します。v8.2.0 以降、このオプションのデフォルト値は0であり、これは TiDB がサーバー構成に基づいて同時実行数を自動的に調整することを示しています。 - 同期的に統計情報をロードする機能がキャッシュできる列リクエストの最大数を指定するには、TiDB 設定ファイルの
stats-load-queue-sizeオプションの値を変更します。デフォルト値は1000です。
TiDBの起動時、初期統計情報が完全にロードされる前に実行されるSQL文は、最適とは言えない実行プランとなり、パフォーマンスの問題を引き起こす可能性があります。このような問題を回避するため、TiDB v7.1.0では設定パラメータforce-init-statsが導入されました。このオプションを使用すると、起動時に統計情報の初期化が完了した後にのみTiDBがサービスを提供するかどうかを制御できます。v7.2.0以降、このパラメータはデフォルトで有効になっています。
バージョン7.1.0以降、TiDBは軽量な統計情報初期化のためのlite-init-statsを導入しました。
lite-init-statsの値がtrueの場合、統計初期化では、インデックスまたは列のヒストグラム、TopN、または Count-Min Sketch はメモリにロードされません。lite-init-statsの値がfalseの場合、統計情報の初期化では、インデックスと主キーのヒストグラム、TopN、および Count-Min Sketch がメモリにロードされますが、主キー以外の列のヒストグラム、TopN、または Count-Min Sketch はメモリにロードされません。オプティマイザが特定のインデックスまたは列のヒストグラム、TopN、および Count-Min Sketch を必要とする場合、必要な統計情報が同期または非同期でメモリにロードされます。
lite-init-statsのデフォルト値はtrueで、これは軽量統計初期化を有効にすることを意味します。 lite-init-statsをtrueに設定すると、不要な統計の読み込みを回避することで、統計初期化が高速化され、TiDB のメモリ使用量が削減されます。
輸出入統計
このセクションでは、統計情報のエクスポートとインポートの方法について説明します。
輸出統計
統計情報をエクスポートするためのインターフェースは以下のとおりです。
${table_name}データベース内の${db_name}テーブルの JSON 形式の統計情報を取得するには:http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}例えば:
curl -s http://127.0.0.1:10080/stats/dump/test/t1 -o /tmp/t1.json${table_name}${db_name}テーブルの特定の時刻における JSON 形式の統計情報を取得するには:http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyyMMddHHmmss}
統計のインポート
一般的に、インポートされる統計情報は、エクスポートインターフェースを使用して取得したJSONファイルを指します。
統計情報の読み込みはLOAD STATSステートメントを使用して行うことができます。
例えば:
LOAD STATS 'file_name';
file_nameは、インポートする統計データのファイル名です。
ロック統計
TiDBはv6.5.0以降、統計情報のロックをサポートしています。テーブルまたはパーティションの統計情報がロックされると、テーブルの統計情報を変更したり、 ANALYZEステートメントをテーブル上で実行したりすることはできません。例:
テーブルtを作成し、データを挿入します。テーブルtの統計情報がロックされていない場合、 ANALYZEステートメントを正常に実行できます。
mysql> CREATE TABLE t(a INT, b INT);
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO t VALUES (1,2), (3,4), (5,6), (7,8);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "Row count in stats_meta is much smaller compared with the row count got by PD, use min(1, 15000/4) as the sample-rate=1" |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
テーブルtの統計情報をロックし、 ANALYZEを実行します。警告メッセージには、 ANALYZEステートメントがテーブルtをスキップしたことが示されています。
mysql> LOCK STATS t;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATS_LOCKED;
+---------+------------+----------------+--------+
| Db_name | Table_name | Partition_name | Status |
+---------+------------+----------------+--------+
| test | t | | locked |
+---------+------------+----------------+--------+
1 row in set (0.01 sec)
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> SHOW WARNINGS;
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "use min(1, 110000/8) as the sample-rate=1" |
| Warning | 1105 | skip analyze locked table: test.t |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
テーブルtとANALYZEの統計情報をロック解除して、再度実行できます。
mysql> UNLOCK STATS t;
Query OK, 0 rows affected (0.01 sec)
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "use min(1, 110000/8) as the sample-rate=1" |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
さらに、LOCK STATSを使用してパーティションの統計情報をロックすることもできます。例:
パーティションテーブルtを作成し、そこにデータを挿入します。パーティションp1の統計情報がロックされていない場合、 ANALYZEステートメントを正常に実行できます。
mysql> CREATE TABLE t(a INT, b INT) PARTITION BY RANGE (a) (PARTITION p0 VALUES LESS THAN (10), PARTITION p1 VALUES LESS THAN (20), PARTITION p2 VALUES LESS THAN (30));
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO t VALUES (1,2), (3,4), (5,6), (7,8);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 6 warning (0.02 sec)
mysql> SHOW WARNINGS;
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p0, reason to use this rate is "Row count in stats_meta is much smaller compared with the row count got by PD, use min(1, 15000/4) as the sample-rate=1" |
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p2, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
6 rows in set (0.01 sec)
パーティションp1の統計情報をロックし、 ANALYZEを実行します。警告メッセージには、 ANALYZEステートメントがパーティションp1をスキップしたことが示されています。
mysql> LOCK STATS t PARTITION p1;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATS_LOCKED;
+---------+------------+----------------+--------+
| Db_name | Table_name | Partition_name | Status |
+---------+------------+----------------+--------+
| test | t | p1 | locked |
+---------+------------+----------------+--------+
1 row in set (0.00 sec)
mysql> ANALYZE TABLE t PARTITION p1;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> SHOW WARNINGS;
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
| Warning | 1105 | skip analyze locked table: test.t partition (p1) |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
パーティションp1とANALYZEの統計情報のロック解除を再度正常に実行できます。
mysql> UNLOCK STATS t PARTITION p1;
Query OK, 0 rows affected (0.00 sec)
mysql> ANALYZE TABLE t PARTITION p1;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> SHOW WARNINGS;
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
ロック統計の挙動
- パーティションテーブルの統計情報をロックすると、そのパーティションテーブル上のすべてのパーティションの統計情報がロックされます。
- テーブルまたはパーティションを切り捨てると、そのテーブルまたはパーティションにかかっていた統計ロックが解除されます。
以下の表は、ロック統計の動作について説明しています。
ANALYZEタスクと並行処理を管理する
このセクションでは、バックグラウンドANALYZEタスクを終了し、 ANALYZEの同時実行を制御する方法について説明します。
バックグラウンドのANALYZEタスクを終了します
TiDB v6.0以降、TiDBはKILLステートメントを使用して、バックグラウンドで実行中のANALYZEタスクを終了することをサポートしています。バックグラウンドで実行中のANALYZEタスクが多くのリソースを消費し、アプリケーションに影響を与えている場合は、次の手順でANALYZEタスクを終了できます。
以下のSQL文を実行してください。
SHOW ANALYZE STATUS結果の
instance列とprocess_id列を確認することで、TiDB インスタンス アドレスと、バックグラウンドIDタスクのタスクANALYZEを取得できます。バックグラウンドで実行されている
ANALYZEタスクを終了します。enable-global-killがtrue(デフォルトではtrue) の場合、KILL TIDB ${id};ステートメントを直接実行できます。ここで、${id}は、前の手順で取得したバックグラウンドIDタスクのANALYZEです。enable-global-killがfalseの場合、クライアントを使用してバックエンドのANALYZEタスクを実行している TiDB インスタンスに接続し、KILL TIDB ${id};ステートメントを実行する必要があります。クライアントを使用して別の TiDB インスタンスに接続する場合、またはクライアントと TiDB クラスタの間にプロキシがある場合、KILLステートメントではバックグラウンドANALYZEタスクを終了できません。
KILLステートメントの詳細については、KILL参照してください。
制御ANALYZE並行性
ANALYZEステートメントを実行すると、システム変数を使用して同時実行性を調整し、システムへの影響を制御できます。
関連するシステム変数間の関係を以下に示します。

tidb_build_stats_concurrency 、 tidb_build_sampling_stats_concurrency 、およびtidb_analyze_partition_concurrencyは、前述の図に示すように、上流-下流の関係にあります。実際の合計同時実行数は、 tidb_build_stats_concurrency * ( tidb_build_sampling_stats_concurrency + tidb_analyze_partition_concurrency ) です。これらの変数を変更する場合は、それぞれの値を同時に考慮する必要があります。 tidb_analyze_partition_concurrency 、 tidb_build_sampling_stats_concurrency 、 tidb_build_stats_concurrencyの順に1つずつ調整し、システムへの影響を確認することをお勧めします。これら3つの変数の値が大きいほど、システムのリソースオーバーヘッドが大きくなります。
tidb_build_stats_concurrency
この変数は、手動 ANALYZE 中に統計情報を構築する際の同時実行性を制御します。たとえば、同時に処理できるテーブルまたはパーティションの分析タスク数です。デフォルト値は2です。v7.4.0 以前のバージョンでは、デフォルト値は4です。
tidb_build_sampling_stats_concurrency
この変数は、ANALYZE の同時実行性に関する以下の項目を制御します。
- 異なるリージョンから収集されたサンプルをマージする際の同時実行性。
- 特殊なインデックス(仮想生成カラム上のインデックスなど)の統計情報を収集する際の同時実行性。たとえば、TiDB が同時に統計情報を収集できるインデックス数です。
デフォルト値は2です。
tidb_analyze_partition_concurrency
この変数は、ANALYZE の結果を保存する際の同時実行性(TopN とヒストグラムをシステムテーブルに書き込むこと)を制御します。デフォルト値は2です。v7.4.0 以前のバージョンでは、デフォルト値は1です。
tidb_analyze_distsql_scan_concurrency
この変数は、ANALYZE の同時実行性に関する以下の項目を制御します。
- TiKV リージョンをスキャンする際の同時実行性。
- 特殊なインデックス(仮想カラムから生成されたインデックス)のためにリージョンをスキャンする際の同時実行性。
デフォルト値は4です。