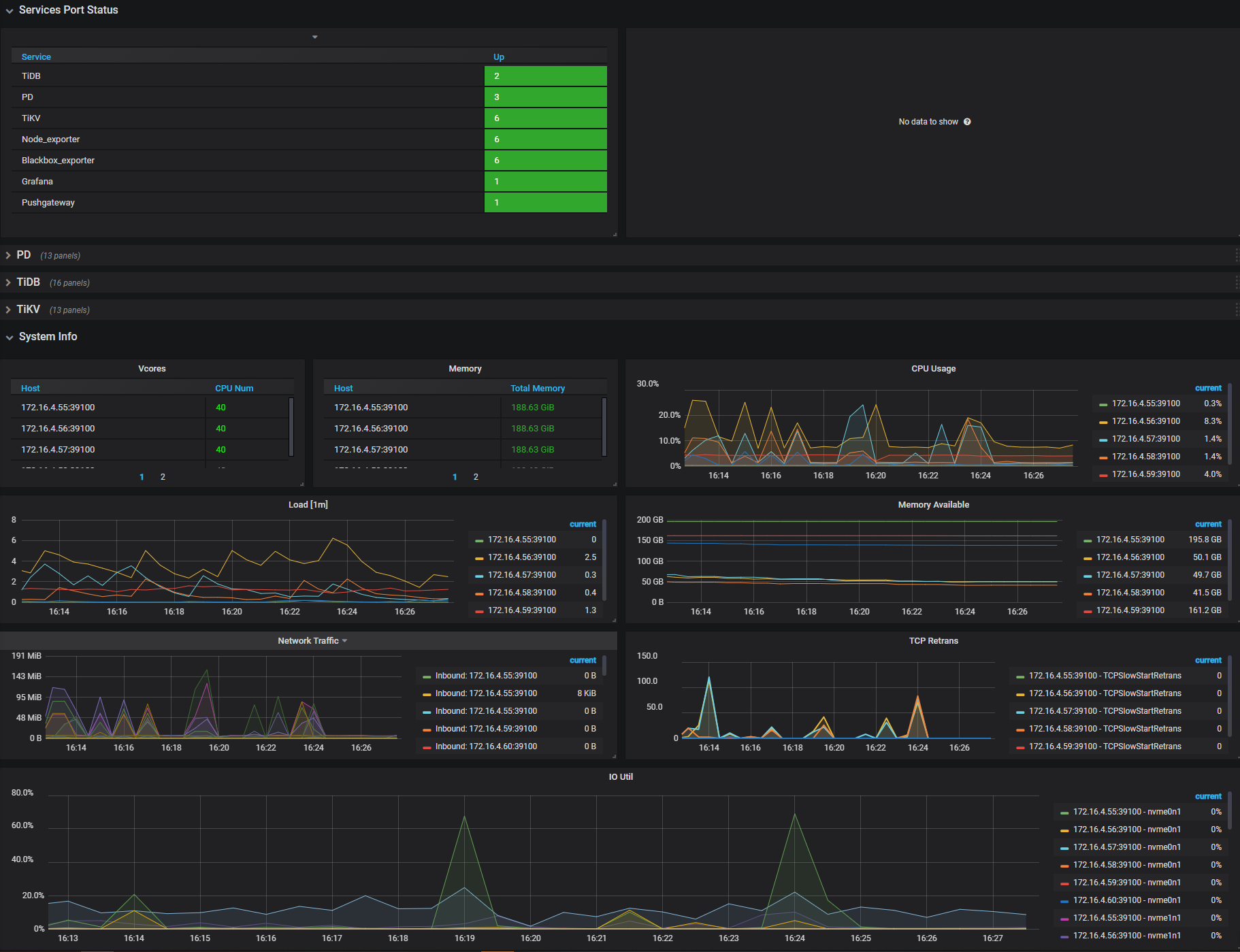
主要な指標
TiUPを使用してTiDBクラスターをデプロイする場合、監視システム(PrometheusとGrafana)も同時にデプロイされます。詳細については、 TiDB 監視フレームワークの概要参照してください。
Grafanaダッシュボードは、Overview、PD、TiDB、TiKV、Node_exporter、Disk Performance、Performance_overviewといった一連のサブダッシュボードに分かれています。診断に役立つ多くの指標が用意されています。
日常的な運用では、主要なメトリクスが表示される「概要」ダッシュボードから、コンポーネント(PD、TiDB、TiKV)のステータスとクラスタ全体の概要を確認できます。このドキュメントでは、これらの主要なメトリクスについて詳しく説明します。
主要な指標の説明
概要ダッシュボードに表示される主要な指標を理解するには、次の表を確認してください。
| サービス | パネル名 | 説明 | 正常範囲 |
|---|---|---|---|
| サービスポートのステータス | サービスアップ | 各サービスのオンライン ノード数。 | |
| PD | PDの役割 | 現在のPDの役割。 | |
| PD | ストレージ容量 | TiDB クラスターの合計storage容量。 | |
| PD | 現在のstorageサイズ | TiKV レプリカによって占有されるスペースを含む、TiDB クラスターの占有storage容量。 | |
| PD | 通常の店舗 | 正常状態にあるノードの数。 | |
| PD | 異常な店舗 | 異常状態にあるノードの数。 | 0 |
| PD | 地域数 | 現在のクラスター内のリージョンの合計数。リージョンの数はレプリカの数とは関係ありません。 | |
| PD | 99% 完了コマンド実行時間秒数 | pd-server 要求を完了するまでの 99 パーセンタイル期間。 | 5ミリ秒未満 |
| PD | 処理リクエストの所要時間(秒) | PD 要求のネットワーク期間。 | |
| PD | リージョンの健康 | 各リージョンの状態。 | 通常、保留中のピアの数は 100 未満であり、不足しているピアの数は必ずしも0を超えるとは限りません。 |
| PD | ホットライトリージョンのリーダー分布 | 各 TiKV インスタンスの書き込みホットスポットであるリーダーの合計数。 | |
| PD | ホットリード地域のリーダー分布 | 各 TiKV インスタンス上の読み取りホットスポットであるリーダーの合計数。 | |
| PD | リージョンのハートビートレポート | インスタンスごとに PD に報告されたハートビートの数。 | |
| PD | 99%リージョンハートビートレイテンシー | TiKV インスタンスごとのハートビートレイテンシー(P99)。 | |
| TiDB | ステートメントOPS | 1 秒あたりに実行される異なるタイプの SQL ステートメントの数。1 、 SELECT 、 UPDATEなどINSERTステートメントのタイプに応じてカウントされます。 | |
| TiDB | 間隔 | 実行時間。 1. クライアントのネットワーク要求がTiDBに送信されてから、TiDBが要求を実行した後にクライアントに返されるまでの時間。通常、クライアント要求はSQL文の形式で送信されますが、この時間には COM_PING 、 COM_SLEEP 、 COM_STMT_FETCH 、 COM_SEND_LONG_DATAなどのコマンドの実行時間も含まれる場合があります。2. TiDBはマルチクエリをサポートしているため、 select 1; select 1; select 1;ように複数のSQL文を一度に送信できます。この場合、このクエリの合計実行時間には、すべてのSQL文の実行時間が含まれます。 | |
| TiDB | インスタンスごとのCPS | インスタンス別 CPS: コマンド実行結果の成功または失敗に応じて分類された、各 TiDB インスタンスのコマンド統計。 | |
| TiDB | クエリ OPM の失敗 | 各TiDBインスタンスにおける1秒あたりのSQL文実行時に発生したエラー数に基づく、エラーの種類(構文エラーや主キーの競合など)の統計情報。エラーが発生したモジュールとエラーコードが含まれます。 | |
| TiDB | 接続数 | 各 TiDB インスタンスの接続数。 | |
| TiDB | メモリ使用量 | 各 TiDB インスタンスのメモリ使用量統計。プロセスによって占有されるメモリと、ヒープ上でGolangによって適用されたメモリに分割されます。 | |
| TiDB | トランザクションOPS | 1 秒あたりに実行されるトランザクションの数。 | |
| TiDB | トランザクション期間 | トランザクションの実行時間 | |
| TiDB | KVコマンドオペレーション | 実行された KV コマンドの数。 | |
| TiDB | KVコマンド持続時間99 | KV コマンドの実行時間。 | |
| TiDB | PD TSOオペレーション | TiDB が PD に送信する 1 秒あたりの gRPC 要求の数 (cmd) と TSO 要求の数 (request)。各 gRPC 要求には、TSO 要求のバッチが含まれます。 | |
| TiDB | PD TSO 待機時間 | TiDB が PD から TSO が返されるのを待機する期間。 | |
| TiDB | TiClientリージョンエラー OPS | TiKV によって返されたリージョン関連エラーの数。 | |
| TiDB | ロック解決OPS | ロックを解決したTiDB操作の数。TiDBの読み取りまたは書き込み要求がロックに遭遇すると、TiDBはロックを解決しようとします。 | |
| TiDB | KV バックオフ OPS | TiKV によって返されたエラーの数。 | |
| TiKV | リーダー | 各 TiKV ノード上のリーダーの数。 | |
| TiKV | 地域 | 各 TiKV ノード上のリージョンの数。 | |
| TiKV | CPU | 各 TiKV ノード上の CPU 使用率。 | |
| TiKV | メモリ | 各 TiKV ノードのメモリ使用量。 | |
| TiKV | 店舗規模 | 各 TiKV インスタンスによって使用されるstorageスペースのサイズ。 | |
| TiKV | cfサイズ | 各カラムファミリー(略して CF) のサイズ。 | |
| TiKV | チャンネルがいっぱい | 各 TiKV インスタンスでの「チャネルがいっぱい」エラーの数。 | 0 |
| TiKV | サーバーレポートの失敗 | 各 TiKV インスタンスによって報告されたエラー メッセージの数。 | 0 |
| TiKV | スケジューラ保留コマンド | 各 TiKV インスタンス上の保留中のコマンドの数。 | |
| TiKV | コプロセッサ実行者数 | TiKVが1秒あたりに受信したコプロセッサ操作の数。コプロセッサの種類ごとに個別にカウントされます。 | |
| TiKV | コプロセッサ要求期間 | コプロセッサの読み取り要求を処理するのに費やされた時間。 | |
| TiKV | いかだストアCPU | raftstoreスレッドのCPU使用率 | デフォルトのスレッド数は2( raftstore.store-pool-sizeで設定)です。1つのスレッドの値が80%を超える場合、CPU使用率が非常に高いことを示します。 |
| TiKV | コプロセッサーCPU | コプロセッサ スレッドの CPU 使用率。 | |
| システム情報 | Vコア | CPU コアの数。 | |
| システム情報 | メモリ | 合計メモリ。 | |
| システム情報 | CPU使用率 | CPU使用率、最大100%。 | |
| システム情報 | 荷重 [1m] | 1分以内に過負荷になります。 | |
| システム情報 | 使用可能なメモリ | 使用可能なメモリのサイズ。 | |
| システム情報 | ネットワークトラフィック | ネットワーク トラフィックの統計。 | |
| システム情報 | TCP再送信 | TOC 再送信の頻度。 | |
| システム情報 | IO使用率 | ディスク使用率は最大でも 100% ですが、一般的には使用率が 80% ~ 90% までになると新しいノードの追加を検討する必要があります。 |
概要ダッシュボードのインターフェース