TiFlashパイプライン実行モデル
このドキュメントでは、 TiFlashパイプライン実行モデルについて説明します。
バージョン7.2.0以降、 TiFlashは新しい実行モデルであるパイプライン実行モデルをサポートしています。
- v7.2.0 および v7.3.0 の場合: パイプライン実行モデルは実験的であり、
tidb_enable_tiflash_pipeline_modelによって制御されます。 - v7.4.0 以降のバージョンの場合: パイプライン実行モデルが一般提供されます。これはTiFlashの内部機能であり、 TiFlashリソース制御と緊密に統合されています。 TiFlashリソース制御を有効にすると、パイプライン実行モデルが自動的に有効になります。 TiFlashリソース制御の使用方法の詳細については、 リソース制御を使用して、リソースグループの制限とフロー制御を実現します参照してください。さらに、v7.4.0 以降、システム変数
tidb_enable_tiflash_pipeline_modelは非推奨になりました。
論文モルセル駆動型並列処理:マルチコア時代に向けたNUMA対応クエリ評価フレームワークからインスピレーションを得た、 TiFlashパイプライン実行モデルは、従来のスレッド スケジューリング モデルとは異なる、きめの細かいタスク スケジューリング モデルを提供します。これにより、オペレーティング システムのスレッド アプリケーションとスケジューリングのオーバーヘッドが削減され、きめ細かいスケジューリング メカニズムが提供されます。
設計と実装
TiFlashのオリジナルのストリームモデルは、スレッドスケジューリングによる実行モデルです。各クエリは独立して複数のスレッドに適用され、それらのスレッドが連携して実行されます。
スレッドスケジューリングモデルには、以下の2つの欠陥がある。
- 高並行処理シナリオでは、スレッド数が多すぎるとコンテキストスイッチが大量に発生し、結果としてスレッドスケジューリングのコストが高くなります。
- スレッドスケジューリングモデルでは、クエリのリソース使用量を正確に測定したり、きめ細かなリソース制御を行うことはできません。
新しいパイプライン実行モデルでは、以下の最適化が行われます。
- クエリは複数のパイプラインに分割され、順次実行されます。各パイプラインでは、データブロックを可能な限りキャッシュに保持することで、時間的な局所性を向上させ、実行プロセス全体の効率を高めます。
- オペレーティングシステムのネイティブなスレッドスケジューリングモデルを排除し、よりきめ細かなスケジューリングメカニズムを実装するために、各パイプラインは複数のタスクにインスタンス化され、タスクスケジューリングモデルが使用されます。同時に、オペレーティングシステムのスレッドスケジューリングのオーバーヘッドを削減するために、固定スレッドプールが使用されます。
パイプライン実行モデルのアーキテクチャは以下のとおりです。
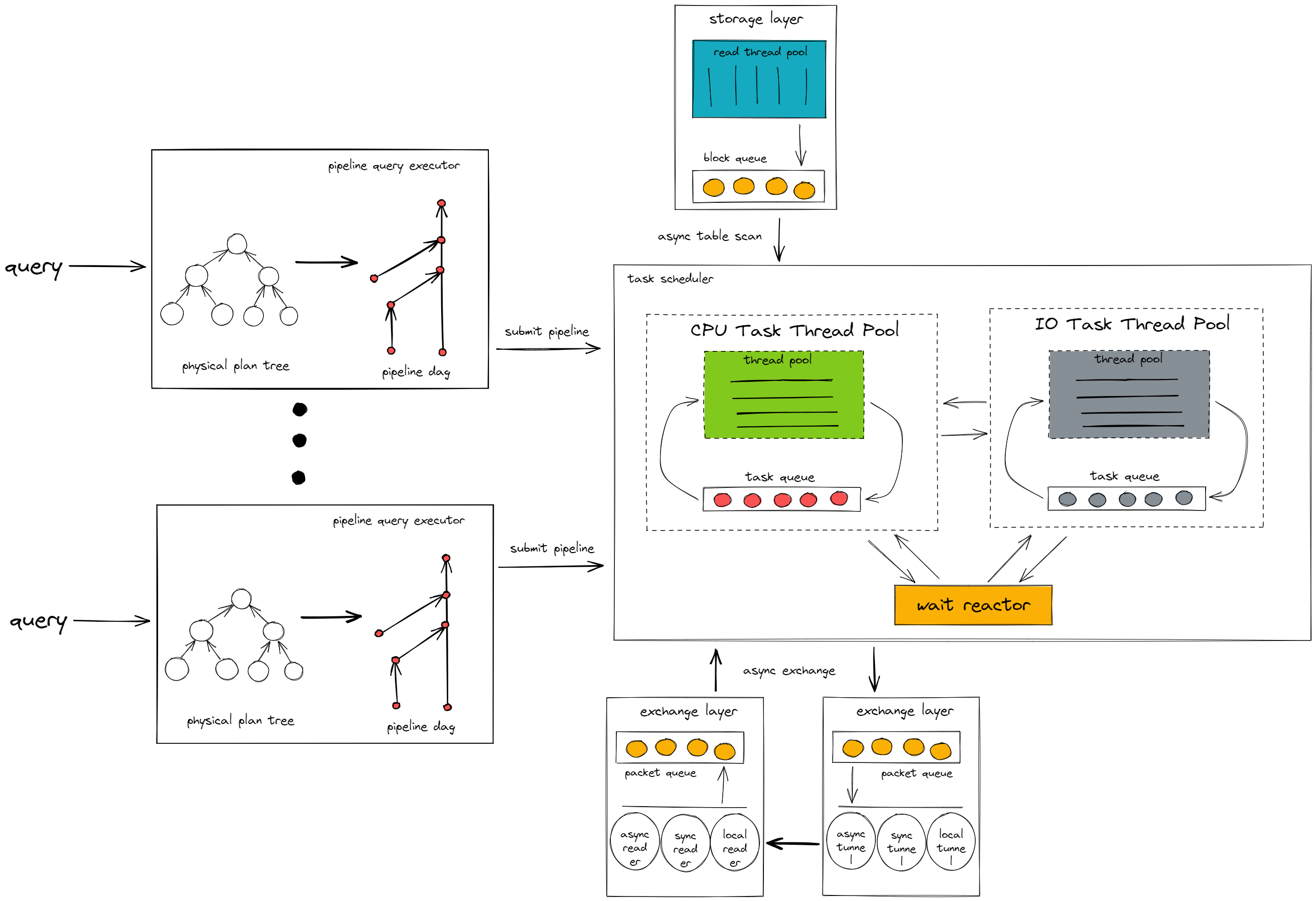
前述の図に示すように、パイプライン実行モデルは、パイプラインクエリ実行部とタスクスケジューラという2つの主要な構成要素から成り立っています。
パイプラインクエリ実行ツール
パイプラインクエリ実行エンジンは、TiDBノードから送信されたクエリ要求をパイプライン有向非巡回グラフ(DAG)に変換します。
クエリ内のパイプラインブレーカー演算子を検出し、それらの演算子に基づいてクエリを複数のパイプラインに分割します。次に、パイプライン間の依存関係に基づいて、それらのパイプラインをDAG(有向非巡回グラフ)に組み立てます。
パイプラインブレーカーとは、一時停止/ブロッキングロジックを持つ演算子です。このタイプの演算子は、上流の演算子からデータブロックを継続的に受信し、すべてのデータブロックを受信すると、処理結果を下流の演算子に返します。このタイプの演算子はデータ処理パイプラインを中断するため、パイプラインブレーカーと呼ばれます。パイプラインブレーカーの1つに集計演算子があり、これは上流の演算子からのすべてのデータをハッシュテーブルに書き込み、ハッシュテーブル内のデータを計算してから、結果を下流の演算子に返します。
クエリがパイプラインDAGに変換された後、パイプラインクエリ実行エンジンは、依存関係に従って各パイプラインを順番に実行します。パイプラインは、クエリの同時実行性に応じて複数のタスクにインスタンス化され、実行のためにタスクスケジューラに送信されます。
タスクスケジューラ
タスクスケジューラは、パイプラインクエリ実行エンジンによって送信されたタスクを実行します。タスクは、実行ロジックに応じて、タスクスケジューラ内のさまざまなコンポーネント間で動的に切り替えられます。
CPUタスクスレッドプール
タスク内のCPU負荷の高い計算ロジック(データフィルタリングや関数計算など)を実行します。
IOタスクスレッドプール
タスク内のI/O負荷の高い計算ロジックを実行します。例えば、中間結果をディスクに書き込むなどです。
原子炉を待つ
タスク内の待機ロジックを実行します。たとえば、ネットワークレイヤーがデータパケットを計算レイヤーに転送するのを待機します。