TiFlash Pipeline Execution Model
This document introduces the TiFlash pipeline execution model.
Starting from v7.2.0, TiFlash supports a new execution model, the pipeline execution model.
- For v7.2.0 and v7.3.0: The pipeline execution model is experimental and is controlled by
tidb_enable_tiflash_pipeline_model. - For v7.4.0 and later versions: The pipeline execution model becomes generally available. It is an internal feature of TiFlash and is tightly integrated with TiFlash resource control. When you enable TiFlash resource control, the pipeline execution model is automatically enabled. For more information about how to use TiFlash resource control, refer to Use Resource Control to Achieve Resource Group Limitation and Flow Control. Additionally, starting from v7.4.0, the system variable
tidb_enable_tiflash_pipeline_modelis deprecated.
Inspired by the paper Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age, the TiFlash pipeline execution model provides a fine-grained task scheduling model, which is different from the traditional thread scheduling model. It reduces the overhead of operating system thread application and scheduling and provides a fine-grained scheduling mechanism.
Design and implementation
The original TiFlash stream model is a thread scheduling execution model. Each query independently applies for several threads to execute in coordination.
The thread scheduling model has the following two defects:
- In high-concurrency scenarios, too many threads cause a large number of context switches, resulting in high thread scheduling costs.
- The thread scheduling model cannot accurately measure the resource usage of queries or do fine-grained resource control.
The new pipeline execution model makes the following optimizations:
- The queries are divided into multiple pipelines and executed in sequence. In each pipeline, the data blocks are kept in the cache as much as possible to achieve better temporal locality and improve the efficiency of the entire execution process.
- To get rid of the native thread scheduling model of the operating system and implement a more fine-grained scheduling mechanism, each pipeline is instantiated into several tasks and uses the task scheduling model. At the same time, a fixed thread pool is used to reduce the overhead of operating system thread scheduling.
The architecture of the pipeline execution model is as follows:
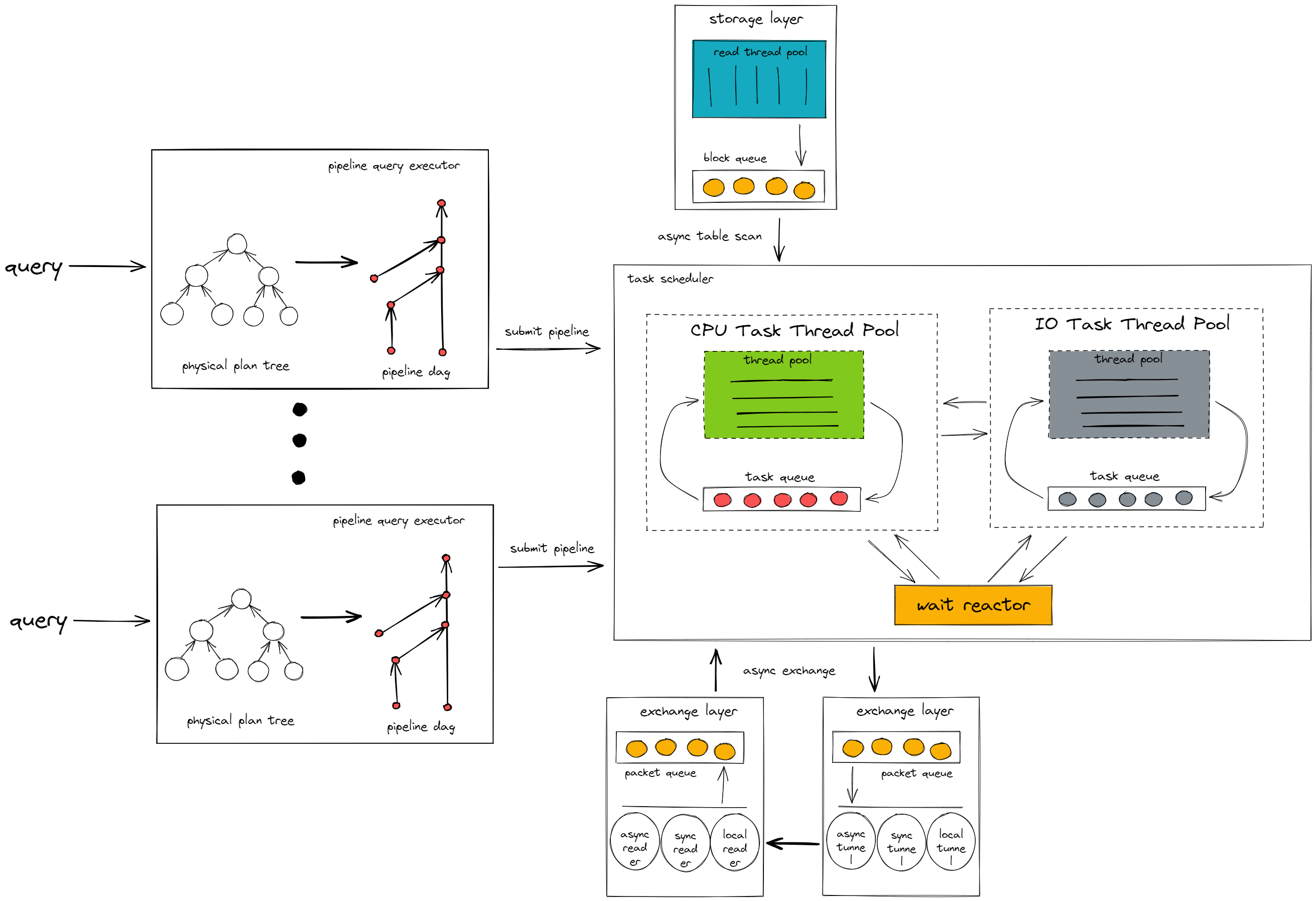
As shown in the preceding figure, the pipeline execution model consists of two main components: the pipeline query executor and the task scheduler.
The pipeline query executor
The pipeline query executor converts the query request sent from the TiDB node into a pipeline directed acyclic graph (DAG).
It will find the pipeline breaker operators in the query and split the query into several pipelines according to the pipeline breakers. Then, it assembles the pipelines into a DAG according to the dependency relationship between the pipelines.
A pipeline breaker is an operator that has a pause/blocking logic. This type of operator continuously receives data blocks from the upstream operator until all data blocks are received, and then return the processing result to the downstream operator. This type of operator breaks the data processing pipeline, so it is called a pipeline breaker. One of the pipeline breakers is the Aggregation operator, which writes all the data of the upstream operator into a hash table before calculating the data in the hash table and returning the result to the downstream operator.
After the query is converted into a pipeline DAG, the pipeline query executor executes each pipeline in sequence according to the dependency relationship. The pipeline is instantiated into several tasks according to the query concurrency and submitted to the task scheduler for execution.
Task scheduler
The task scheduler executes the tasks submitted by the pipeline query executor. The tasks are dynamically switched between different components in the task scheduler according to the different execution logic.
CPU task thread pool
Executes the CPU-intensive calculation logic in the task, such as data filtering and function calculation.
IO task thread pool
Executes the IO-intensive calculation logic in the task, such as writing intermediate results to disk.
Wait reactor
Executes the wait logic in the task, such as waiting for the network layer to transfer the data packet to the calculation layer.