TiFlashパイプライン実行モデル
このドキュメントでは、 TiFlashパイプライン実行モデルについて説明します。
v7.2.0 以降、 TiFlash は新しい実行モデルであるパイプライン実行モデルをサポートします。
- v7.2.0 および v7.3.0 の場合: パイプライン実行モデルは実験的もので、
tidb_enable_tiflash_pipeline_modelによって制御されます。 - v7.4.0以降のバージョン:パイプライン実行モデルが一般提供されました。これはTiFlashの内部機能であり、 TiFlashリソース制御と緊密に統合されています。TiFlashTiFlash制御を有効にすると、パイプライン実行モデルも自動的に有効になります。TiFlashTiFlash制御の使用方法の詳細については、 リソース制御を使用してリソースグループの制限とフロー制御を実現するを参照してください。また、v7.4.0以降、システム変数
tidb_enable_tiflash_pipeline_model非推奨となりました。
論文Morsel駆動型並列処理: メニーコア時代に向けたNUMA対応クエリ評価フレームワークに着想を得たTiFlashパイプライン実行モデルは、従来のスレッドスケジューリングモデルとは異なる、きめ細かなタスクスケジューリングモデルを提供します。これにより、オペレーティングシステムのスレッド適用とスケジューリングのオーバーヘッドが削減され、きめ細かなスケジューリングメカニズムが実現されます。
設計と実装
オリジナルのTiFlashストリームモデルは、スレッドスケジューリング実行モデルです。各クエリは独立して複数のスレッドに適用され、協調して実行されます。
スレッド スケジューリング モデルには、次の 2 つの欠陥があります。
- 同時実行性の高いシナリオでは、スレッドが多すぎるとコンテキストスイッチの数が多くなり、スレッドのスケジューリングコストが高くなります。
- スレッド スケジューリング モデルでは、クエリのリソース使用量を正確に測定したり、きめ細かいリソース制御を行うことはできません。
新しいパイプライン実行モデルでは、次の最適化が行われます。
- クエリは複数のパイプラインに分割され、順番に実行されます。各パイプラインでは、データブロックが可能な限りキャッシュに保持されるため、時間的な局所性が向上し、実行プロセス全体の効率が向上します。
- オペレーティングシステムのネイティブスレッドスケジューリングモデルを排除し、よりきめ細かなスケジューリングメカニズムを実装するために、各パイプラインは複数のタスクにインスタンス化され、タスクスケジューリングモデルを使用します。同時に、固定スレッドプールを使用することで、オペレーティングシステムのスレッドスケジューリングのオーバーヘッドを削減します。
パイプライン実行モデルのアーキテクチャは次のとおりです。
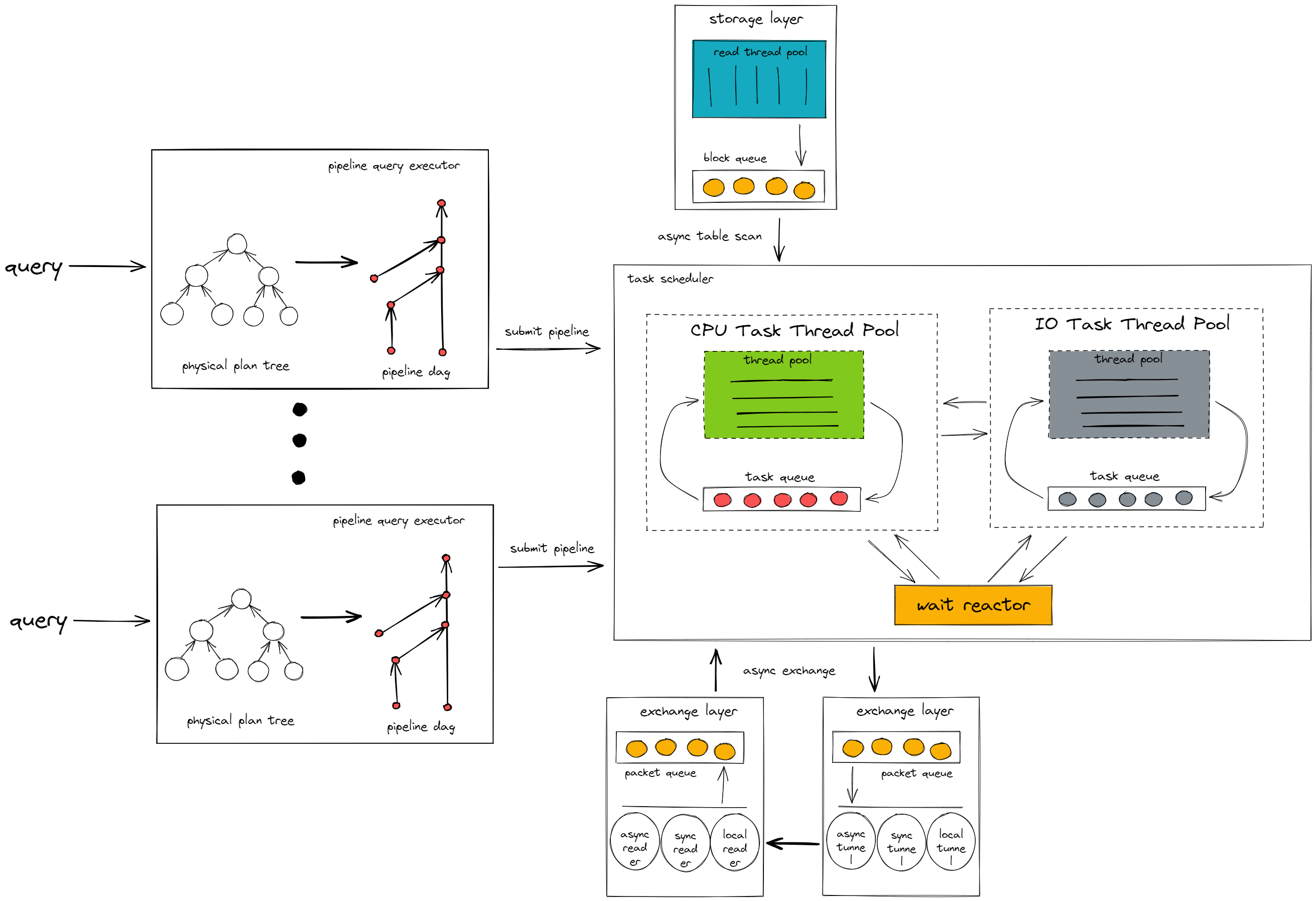
上の図に示すように、パイプライン実行モデルは、パイプライン クエリ エグゼキュータとタスク スケジューラという 2 つの主要コンポーネントで構成されます。
パイプラインクエリエグゼキュータ
パイプライン クエリ エグゼキュータは、TiDB ノードから送信されたクエリ要求をパイプライン有向非巡回グラフ (DAG) に変換します。
クエリ内のパイプラインブレーカー演算子を検出し、パイプラインブレーカーに基づいてクエリを複数のパイプラインに分割します。その後、パイプライン間の依存関係に基づいて、パイプラインをDAGに組み立てます。
パイプラインブレーカーは、一時停止/ブロッキングロジックを持つ演算子です。このタイプの演算子は、上流演算子からすべてのデータブロックを受信するまで継続的にデータブロックを受信し、その後、処理結果を下流演算子に返します。このタイプの演算子はデータ処理パイプラインを中断するため、パイプラインブレーカーと呼ばれます。パイプラインブレーカーの1つに集計演算子があります。これは、上流演算子のすべてのデータをハッシュテーブルに書き込み、ハッシュテーブル内のデータを計算し、結果を下流演算子に返します。
クエリがパイプラインDAGに変換された後、パイプラインクエリエグゼキュータは依存関係に従って各パイプラインを順番に実行します。パイプラインはクエリの同時実行性に応じて複数のタスクにインスタンス化され、タスクスケジューラに実行のために送信されます。
タスクスケジューラ
タスクスケジューラは、パイプラインクエリエグゼキュータによって送信されたタスクを実行します。タスクは、異なる実行ロジックに応じて、タスクスケジューラ内の異なるコンポーネント間で動的に切り替えられます。
CPUタスクスレッドプール
データのフィルタリングや関数の計算など、タスク内で CPU を集中的に使用する計算ロジックを実行します。
IOタスクスレッドプール
中間結果をディスクに書き込むなど、タスク内で IO 集約型の計算ロジックを実行します。
待機リアクター
ネットワークレイヤーがデータパケットを計算レイヤーに転送するのを待つなど、タスク内の待機ロジックを実行します。