TiKVの概要
TiKVは、 ACID準拠のトランザクションAPIを提供する分散型トランザクションキーバリューデータベースです。RocksDBに保存されるRaftコンセンサスアルゴリズムとコンセンサスステートの実装により、TiKVは複数のレプリカ間のデータ一貫性と高可用性を保証します。TiDB分散データベースのストレージレイヤーとして、TiKVは読み取りおよび書き込みサービスを提供し、アプリケーションから書き込まれたデータを永続化します。また、TiDBクラスターの統計データも保存します。
アーキテクチャの概要
TiKV は、Google Spanner の設計に基づいて、マルチ raft グループ レプリカ メカニズムを実装しています。リージョンはキーと値のデータの移動の基本単位で、ストア内のデータ範囲を参照します。各リージョンは複数のノードに複製されます。これらの複数のレプリカがRaftグループを形成します。リージョンのレプリカはピアと呼ばれます。通常、リージョンには 3 つのピアがあります。そのうちの 1 つがリーダーで、読み取りおよび書き込みサービスを提供します。PDコンポーネントは、すべてのリージョンのバランスを自動的に調整して、TiKV クラスター内のすべてのノード間で読み取りおよび書き込みのスループットが均等になるようにします。PD と慎重に設計されたRaftグループにより、TiKV は水平方向のスケーラビリティに優れ、100 TB を超えるデータを簡単に保存できます。
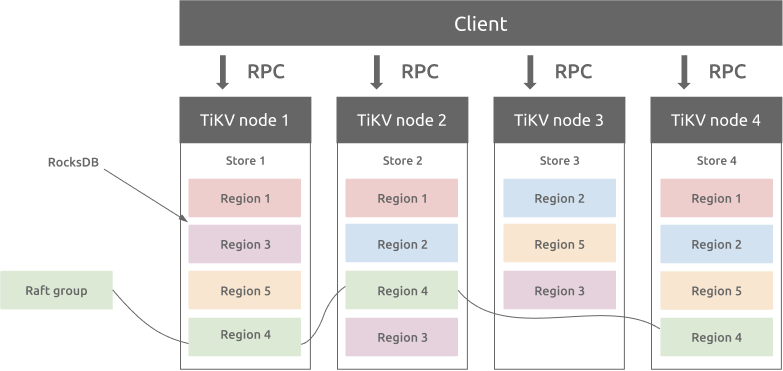
リージョンとRocksDB
各ストアにはRocksDBデータベースがあり、データはローカルディスクに保存されます。リージョンデータはすべて、各ストア内の同じRocksDBインスタンスに保存されます。Raftコンセンサスアルゴリズムに使用されるログはすべて、各ストア内の別のRocksDBインスタンスに保存されます。これは、シーケンシャルI/Oの方がランダムI/ Raftよりもパフォーマンスが優れているためです。Raftログとリージョンデータを異なるRocksDBインスタンスに保存することで、TiKVはRaftログとTiKVリージョンへのすべての書き込み操作を1つのI/O操作に統合し、パフォーマンスを向上させます。
リージョンとRaftコンセンサスアルゴリズム
リージョン内のレプリカ間のデータ整合性は、 Raftコンセンサスアルゴリズムによって保証されます。リージョンのリーダーのみが書き込みサービスを提供でき、リージョン内のレプリカの過半数にデータが書き込まれた場合にのみ、書き込み操作は成功します。
TiKVは、クラスター内の各リージョンの適切なサイズを維持しようとします。リージョンのサイズは現在、デフォルトで256MiBです。このメカニズムは、PDコンポーネントがTiKVクラスター内のノード間でリージョンのバランスをとるのに役立ちます。リージョンのサイズがしきい値(デフォルトでは384MiB)を超えると、TiKVはそれを2つ以上のリージョンに分割します。リージョンのサイズがしきい値(デフォルトでは54MiB)より小さい場合、TiKVは隣接する2つの小さなリージョンを1つのリージョンに結合します。
PD がレプリカをある TiKV ノードから別の TiKV ノードに移動する場合、まずターゲット ノードにLearnerレプリカを追加し、 LearnerレプリカのデータがLeaderレプリカのデータとほぼ同じになったら、PD はそれをFollowerレプリカに変更し、ソース ノードのFollowerレプリカを削除します。
Leaderレプリカをあるノードから別のノードに移動させる場合も同様のメカニズムが採用されます。違いは、LearnerレプリカがFollowerレプリカになった後、「Leader移行」処理が実行され、Followerレプリカが自らをLeaderに選出するための選挙を積極的に提案することです。最終的に、新しいLeaderはソースノードから古いLeaderレプリカを削除します。
分散トランザクション
TiKVは分散トランザクションをサポートします。ユーザー(またはTiDB)は、同じリージョンに属しているかどうかを気にすることなく、複数のキーと値のペアを書き込むことができます。TiKVは2フェーズコミットを使用してACID制約を実現します。詳細はTiDB 楽観的トランザクションモデルを参照してください。
TiKVコプロセッサー
TiDBは一部のデータ計算ロジックをTiKVコプロセッサーにプッシュします。TiKVコプロセッサーは各リージョンの計算を処理します。TiKVコプロセッサーに送信される各リクエストは、1つのリージョンのデータのみを対象とします。