TiDB Xアーキテクチャ
TiDB Xは、クラウドネイティブなオブジェクトストレージをTiDBの基盤とする新しい分散SQLアーキテクチャです。現在、 TiDB Cloud Starter、 Essential、Premiumで利用可能なこのアーキテクチャは、AI時代のワークロード向けに、柔軟なスケーラビリティ、予測可能なパフォーマンス、および最適化された総所有コスト(TCO)を実現します。
TiDB X はクラシックTiDBの共有なしアーキテクチャからクラウドネイティブな共有ストレージアーキテクチャへの根本的な進化を表しています。共有永続ストレージレイヤーとしてオブジェクトストレージを活用することで、TiDB X はコンピューティングワークロードの分離を実現し、オンライントランザクションワークロードをリソース集約型のバックグラウンドタスクから分離します。
このドキュメントでは、TiDB Xアーキテクチャを紹介し、TiDB Xの開発動機を説明し、従来のTiDBアーキテクチャと比較した主な革新点について説明します。
従来のTiDBの限界
このセクションでは、従来のTiDBのアーキテクチャと、TiDB Xの開発を促すその限界について分析します。
従来のTiDBの強み
従来のTiDBの共有なしアーキテクチャは、従来のモノリシックデータベースの限界を克服します。コンピューティングとストレージを分離し、 Raftコンセンサスアルゴリズムを利用することで、分散SQLワークロードに必要な耐障害性と拡張性を提供します。
従来のTiDBアーキテクチャは、以下の基本的な機能を提供します。
- 水平スケーラビリティ:読み取りと書き込みの両方のパフォーマンスにおいて、線形スケーリングをサポートします。クラスターは、毎秒数百万のクエリ(QPS)を処理し、数千万のテーブルにわたる1 PiBを超えるデータを管理できるように拡張できます。
- ハイブリッドトランザクションおよび分析処理(HTAP) :トランザクションワークロードと分析ワークロードを統合します。集約処理や結合処理といった負荷の高い処理をTiFlash (カラム型ストレージエンジン)にプッシュダウンすることで、複雑なETLパイプラインを必要とせずに、最新のトランザクションデータに対して予測可能なリアルタイム分析を実現します。
- 非ブロッキング型スキーマ変更:完全オンラインのDDL実装を採用しています。スキーマ変更によって読み取りや書き込みがブロックされないため、アプリケーションのレイテンシーや可用性への影響を最小限に抑えながらデータモデルを進化させることができます。
- 高可用性:シームレスなクラスタのアップグレードとスケーリング操作をサポートします。これにより、メンテナンスやリソース調整中も重要なサービスへのアクセスが維持されます。
- マルチクラウド対応: をサポートするオープンソースソリューションとして動作します。これによりAmazon Web Services (AWS)、Google Cloud、Microsoft Azureベンダーロックインのないクラウド中立性が実現します。
従来のTiDBの課題
従来のTiDBの共有なしアーキテクチャは高い耐障害性を提供する一方で、ローカルノード上のストレージとコンピューティングの密結合は、極めて大規模な環境では制約をもたらします。データ量の増加とクラウドネイティブ要件の進化に伴い、いくつかの構造的な課題が生じています。
拡張性の制限
データ移動のオーバーヘッド:従来のTiDBでは、スケールアウト(ノードの追加)またはスケールイン(ノードの削除)操作を行う際に、ノード間でSSTファイルを物理的に移動させる必要がありました。大規模なデータセットの場合、この処理は時間がかかり、データ移動中のCPUとI/Oの消費量が多いため、オンラインのトラフィックパフォーマンスが低下する可能性があります。
ストレージエンジンのボトルネック:従来のTiDBの基盤となるRocksDBストレージエンジンは、グローバルミューテックスで保護された単一のLSMツリーを使用しています。この設計により、システムが大規模なデータセット(例えば、TiKVノードあたり6TiBを超えるデータ、または30万を超えるSSTファイル)を処理する際に限界が生じ、ハードウェア容量を十分に活用できなくなります。
安定性とパフォーマンスの干渉
リソース競合:書き込みトラフィックが増加すると、SST ファイルをマージするための大規模なローカル圧縮ジョブが実行されます。従来の TiDB では、これらの圧縮ジョブはオンライン トラフィックを処理する同じ TiKV ノードで実行されるため、同じ CPU および I/O リソースを競合し、オンライン アプリケーションに影響を与える可能性があります。
物理的な分離の欠如:論理リージョンと物理的なSSTファイルの間には物理的な分離がありません。リージョンの移動(バランス調整)などの操作は、圧縮オーバーヘッドを発生させ、それがユーザーのクエリと直接競合するため、パフォーマンスの不安定性につながる可能性があります。
書き込みスロットリング:書き込み負荷が高い場合、バックグラウンドの圧縮処理がフォアグラウンドの書き込みトラフィックに追いつかないと、従来のTiDBはストレージエンジンを保護するためにフロー制御メカニズムを作動させます。その結果、アプリケーションの書き込みスループットが制限され、レイテンシーが急上昇します。
資源利用とコスト
過剰プロビジョニング:ピーク時のトラフィックやバックグラウンドメンテナンス時に安定性を維持し、パフォーマンスを確保するために、ユーザーは「ハイウォーターマーク」要件に基づいてハードウェアを過剰にプロビジョニングすることがよくあります。
柔軟性に欠けるスケーリング:コンピューティングとストレージは密接に結びついているため、CPU使用率が低い場合でも、ストレージ容量を増やすためだけに、高価でコンピューティング負荷の高いノードを追加せざるを得ない場合があります。
TiDB X の動機
TiDB Xへの移行は、データと物理的なコンピューティングリソースを分離する必要性から推進されています。共有ストレージを持たないアーキテクチャから共有ストレージアーキテクチャに移行することで、TiDB Xは結合ノードの物理的な制約に対処し、以下の技術的目標を達成します。
- スケーリングの高速化:物理的なデータ移行の必要性を排除することで、スケーリング性能を最大10倍向上させます。
- タスクの分離:バックグラウンドのメンテナンス タスク(圧縮など)とオンラインのトランザクション トラフィックとの間で干渉が一切発生しないようにします。
- リソースの柔軟性:コンピューティングリソースがストレージ容量とは独立して拡張できる、真の「従量課金制」モデルを実装します。
このアーキテクチャの開発に関する追加のコンテキストについては、ブログ投稿TiDB Xの誕生秘話:起源、アーキテクチャ、そして今後の展望を参照してください。
TiDB Xアーキテクチャの概要
TiDB Xは、従来のTiDB分散設計をクラウドネイティブに進化させたものです。従来のTiDBから以下のアーキテクチャ上の強みを受け継いでいます。
- ステートレスなSQLレイヤー:SQLレイヤー(TiDBサーバー)はステートレスであり、永続的なデータを保存することなく、クエリの解析、最適化、および実行を担当します。
- ゲートウェイと接続管理:TiProxy(またはロードバランサー)は、クライアントとの永続的な接続を維持し、SQLトラフィックをシームレスにルーティングします。元々はオンラインアップグレードをサポートするために設計されたTiProxyは、現在では自然なゲートウェイコンポーネントとして機能します。
- リージョンによる動的シャーディング:TiKVは、リージョン(デフォルトでは256MiB)と呼ばれる範囲ベースのシャーディング単位を使用します。データは数百万のリージョンに分割され、システムはリージョンの配置、移動、およびノード間の負荷分散を自動的に管理します。
TiDB X は、ローカルのシェアードストレージをクラウドネイティブの共有ストレージ オブジェクトストレージバックボーンに置き換えることにより、これらの基盤を進化させます。この移行により、「コンピューティングコンピューティングとコンピューティングの分離」モデルが可能になり、リソースを大量に消費するタスクをエラスティック プールにオフロードして、即時のスケーラビリティと予測可能なパフォーマンスを確保します。
TiDB Xのアーキテクチャは以下のとおりです。
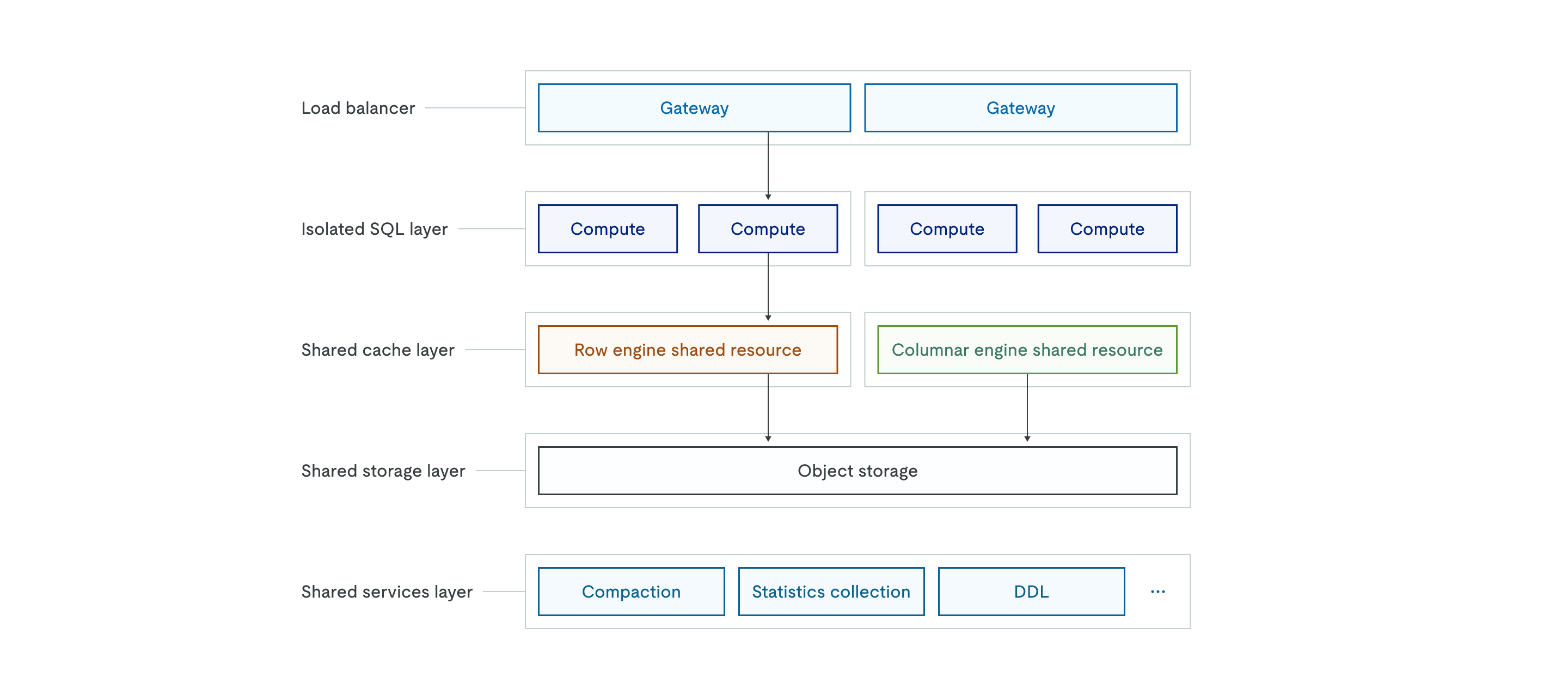
オブジェクトストレージのサポート
TiDB X は、Amazon S3 などのオブジェクトストレージを、すべてのデータの唯一の信頼できる情報源として使用します。データがローカルディスクに保存される従来のアーキテクチャとは異なり、TiDB X ではすべてのデータの永続的なコピーが共有オブジェクトストレージレイヤーに保存されます。上位の共有キャッシュレイヤー(行エンジンと列エンジン)は、低レイテンシーを確保するための高性能キャッシュとして機能します。
信頼できるデータは既にオブジェクトストレージに保存されているため、バックアップはS3に保存されたRaftの増分ログとメタデータのみに依存し、データ総量に関わらずバックアップ操作は数秒で完了します。スケールアウト操作中、新しいTiKVノードは既存のノードから大量のデータをコピーする必要はありません。代わりに、オブジェクトストレージに接続して必要なデータをオンデマンドでロードするため、スケールアウト操作が大幅に高速化されます。
自動スケーリング機構
TiDB Xアーキテクチャは、ロードバランサーとステートレスな分離型SQLレイヤーによって実現される、弾力的なスケーリングを前提として設計されています。共有キャッシュレイヤーは、CPU使用率またはディスク容量に基づいてスケーリングできます。システムは、リアルタイムのワークロード要求に対応するため、コンピューティングポッドを数秒以内に自動的に追加または削除します。
この技術的な柔軟性により、使用量に応じた従量課金制の料金モデルが実現します。ユーザーはピーク時の負荷に備えてリソースを事前に確保する必要がなくなります。代わりに、システムはトラフィックが急増した際には自動的にスケールアウトし、アイドル状態の時にはスケールインすることでコストを最小限に抑えます。
マイクロサービスとワークロードの分離
TiDB Xは、多様なワークロードが互いに干渉しないように、高度な職務分掌を実装しています。分離されたSQLレイヤーは、独立したコンピューティングノードのグループで構成されており、ワークロードの分離や、異なるアプリケーションが同じ基盤データを共有しながら専用のコンピューティングリソースを使用できるマルチテナントシナリオを実現します。
共有サービスレイヤーは、データベースの負荷の高い操作を、圧縮、統計情報の収集、DDL実行などの独立したマイクロサービスに分解します。インデックス作成や大規模データインポートといったリソース集約型のバックグラウンド操作をこのレイヤーにオフロードすることで、TiDB Xはこれらの操作がオンラインユーザーのトラフィックを処理する計算ノードとCPUやメモリのリソースを競合しないようにします。この設計により、重要なアプリケーションのパフォーマンスがより予測可能になり、ゲートウェイ、SQL計算、キャッシュ、バックグラウンドサービスといった各コンポーネントが、それぞれのリソース需要に基づいて独立してスケーリングできるようになります。
TiDB Xの主な革新点
以下の図は、従来のTiDBとTiDB Xのアーキテクチャを並べて比較したものです。共有ストレージを持たない設計から共有ストレージ設計への移行と、計算ワークロードの分離の導入が強調されています。
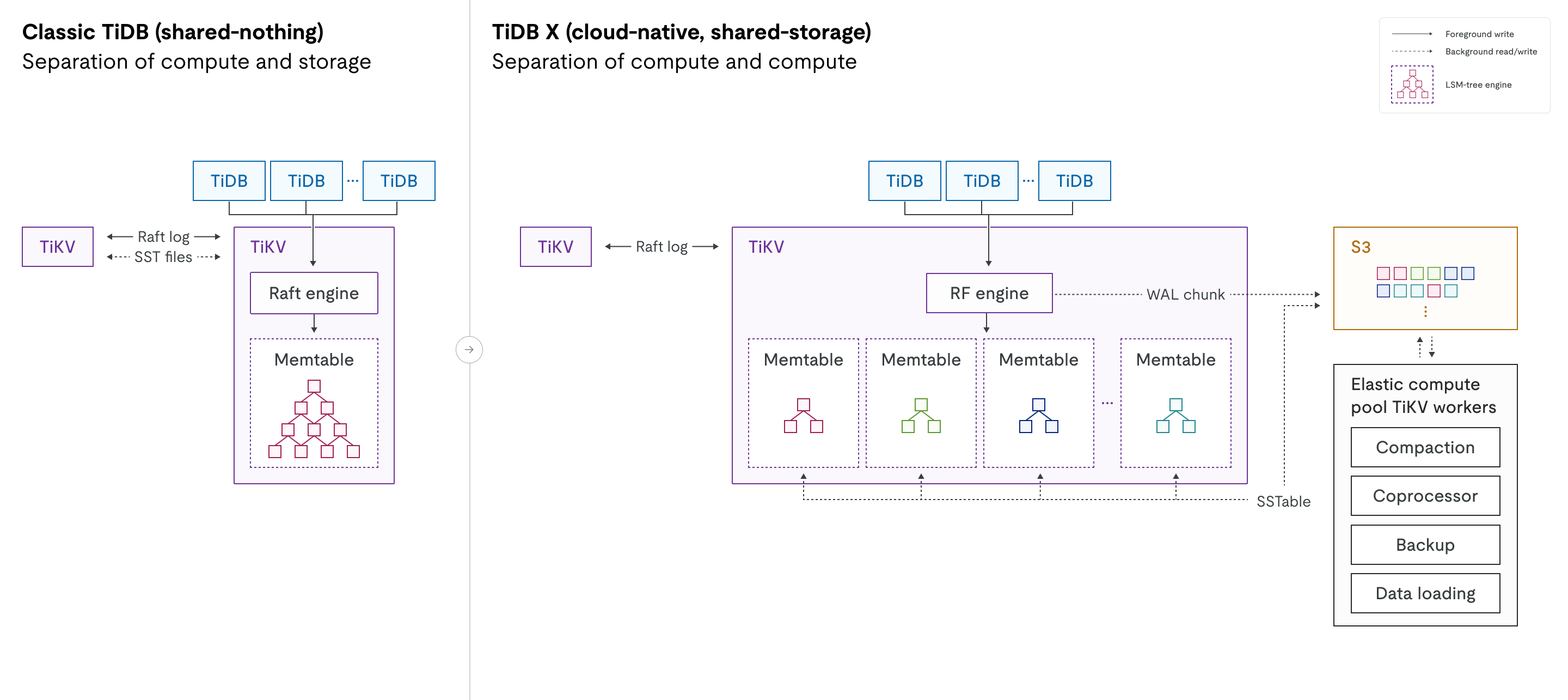
エンジンの進化:従来のTiDBでは、 RaftエンジンがMulti-Raftログを管理し、RocksDBがローカルディスク上の物理データストレージを処理していました。TiDB Xでは、これらのコンポーネントは新しいRFエンジン(Raftエンジン)と再設計されたKVエンジンに置き換えられています。KVエンジンは、RocksDBに代わるLSMツリーストレージエンジンです。どちらの新しいエンジンも、高性能とオブジェクトストレージとのシームレスな統合に特化して最適化されています。
コンピューティングワークロードの分離:図中の点線は、オブジェクトストレージレイヤーへのバックグラウンドでの読み書き操作を表しています。TiDB Xでは、RF/KVエンジンとオブジェクトストレージ間のこれらの相互作用はフォアグラウンドプロセスから分離されているため、バックグラウンド操作がオンライントラフィックのレイテンシーに影響を与えません。
計算と計算の分離
従来のTiDBは既に計算処理(SQLレイヤー)とstorage(TiKV)を分離していますが、TiDB XではSQL層とストレージ層の両方において、さらに分離レイヤーが追加されています。この設計により、オンラインのトランザクション処理ワークロード向けの軽量な計算処理と、リソース集約型のバックグラウンドタスク向けの高負荷な計算処理が区別されます。
軽量コンピューティング:ユーザークエリなどのOLTPワークロードDedicatedのリソース。
軽量なOLTPワークロードの場合、負荷の高い計算タスクはエラスティックコンピューティングプールにオフロードされるため、ユーザートラフィックを処理するTiKVサーバーはオンラインクエリ専用に確保されます。その結果、TiDB Xはより少ないリソースで、より安定した予測可能なパフォーマンスを実現します。この分離により、バックグラウンドタスクがオンライントランザクション処理に干渉することがなくなります。
ヘビーコンピューティング:圧縮、バックアップ、統計情報の収集、データロード、スロークエリ処理などのバックグラウンドタスク専用の、独立した弾力性のあるコンピューティングプール。
DDL操作や大規模データインポートなどの負荷の高い計算タスクの場合、TiDB Xは、オンライントラフィックへの影響を最小限に抑えながら、これらのワークロードをフルスピードで実行するための柔軟な計算リソースを自動的にプロビジョニングできます。たとえば、インデックスを追加すると、データ量に応じてTiDBワーカー、コプロセッサーワーカー、およびTiKVワーカーが動的にプロビジョニングされます。これらのプロビジョニングされた柔軟な計算リソースは、オンライントラフィックを処理するTiDBおよびTiKVサーバーから分離されているため、リソースを大量に消費する操作が重要なOLTPクエリと競合することはありません。実際のシナリオでは、インデックス作成は従来のTiDBよりも最大5倍高速になり、オンラインサービスに影響を与えることもありません。
共有なし環境から共有ストレージへの移行
TiDB Xは、従来の共有なしアーキテクチャ(TiKVノード間でデータを物理的にコピーする必要があった)から、共有ストレージアーキテクチャへと移行しました。TiDB Xでは、ローカルディスクではなく、オブジェクトストレージ(Amazon S3など)がすべての永続データの唯一の信頼できる情報源として機能します。これにより、スケーリング操作中に大量のデータをコピーする必要がなくなり、迅速な拡張性を実現できます。
オブジェクトストレージへの移行は、フォアグラウンドでの読み書きパフォーマンスを低下させません。
- 読み取り操作:軽量なリクエストはローカルキャッシュとディスクから処理されます。負荷の高い読み取りワークロードのみが、リモートの柔軟なコプロセッサワーカーにオフロードされます。
- 書き込み操作:オブジェクトストレージとのやり取りは非同期で行われます。まず、 Raftログがローカルディスクに永続化され、 Raft WAL(ライトアヘッドログ)のチャンクがバックグラウンドでオブジェクトストレージにアップロードされます。
- 圧縮: MemTable内のデータが満杯になり、ローカルディスクに書き込まれると、リージョンリーダーは SST ファイルをオブジェクトストレージにアップロードします。エラスティック圧縮ワーカーでリモート圧縮が完了すると、TiKV ノードに通知され、圧縮された SST ファイルをオブジェクトストレージからロードします。
柔軟な総所有コスト(従量課金制)
従来のTiDBでは、ピーク時のトラフィックとバックグラウンドタスクを同時に処理するために、クラスタが過剰にプロビジョニングされることがよくありました。TiDB Xはオートスケーリングに対応しており、ユーザーは消費したリソースに対してのみ料金を支払うことができます(従量課金制)。負荷の高いタスク用のバックグラウンドリソースは必要に応じてプロビジョニングされ、不要になった時点で解放されるため、無駄なコストを削減できます。
TiDB X は、 要求容量単位(RCU) を使用してプロビジョニングされたコンピューティング容量を測定します。1 RCU は、一定数の SQL リクエストを処理できる固定量のコンピューティング リソースを提供します。プロビジョニングする RCU の数によって、TiDB X インスタンスのベースラインのパフォーマンスとスループット容量が決まります。上限を設定することで、弾力的なスケーリングのメリットを享受しながらコストを管理できます。
LSMツリーからLSMフォレストへ
従来の TiDB では、各 TiKV ノードで単一の RocksDB インスタンスが実行され、すべてのリージョンのデータが 1 つの大きな LSM ツリーに格納されます。数千のリージョンのデータが混在するため、リージョンの移動、スケールアウト、スケールインなどの操作によって大規模な圧縮がトリガーされる可能性があります。これにより、CPU および I/O リソースが大幅に消費され、オンライン トラフィックに影響が出る可能性があります。単一の LSM ツリーはグローバル ミューテックスによって保護されています。データ サイズが大きくなると、大規模 (たとえば、TiKV ノードあたり 6 TiB を超えるデータ、または 300,000 を超える SST ファイル) では、グローバル ミューテックス ロックの競合が増加し、読み取りと書き込みの両方のパフォーマンスに影響が出る可能性があります。
TiDB X は、単一の LSM ツリーからLSM フォレストへと移行することで、ストレージエンジンを再設計しました。論理的なリージョン抽象化は維持しつつ、TiDB X は各リージョンに独自の独立した LSM ツリーを割り当てます。この物理的な分離により、スケーリング、リージョンの移動、データ ロードなどの操作中にリージョン間圧縮のオーバーヘッドが解消されます。1 つのリージョンに対する操作は、そのリージョンのツリー内に限定され、グローバルなミューテックスの競合は発生しません。
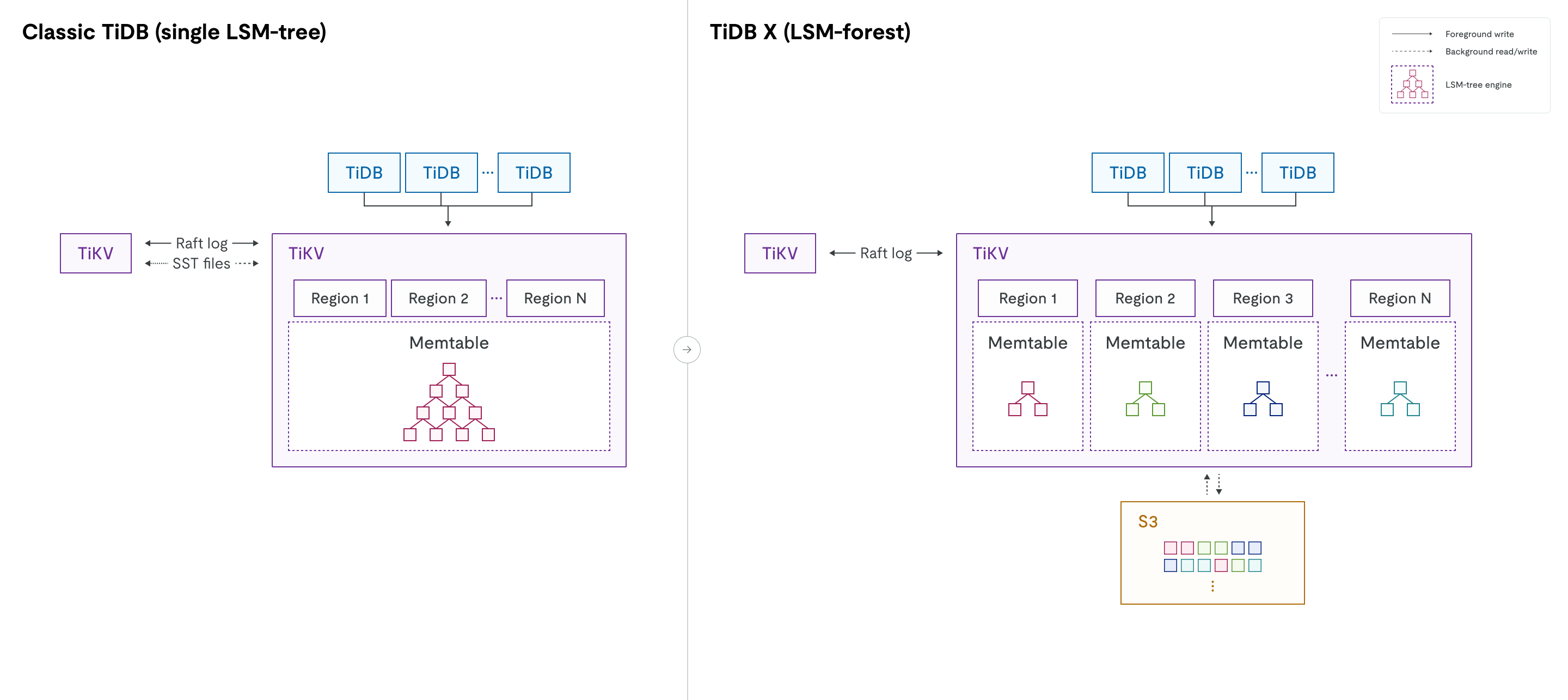
迅速かつ柔軟な拡張性
TiDB Xは、共有オブジェクトストレージにデータを保存し、各リージョンを独立したLSMツリーで管理することで、TiKVノードの追加または削除時に物理的なデータ移行や大規模なデータ圧縮を行う必要がなくなります。その結果、スケーリング操作は従来のTiDBに比べて5~10倍高速化され、オンラインワークロードのレイテンシーも安定的に維持されます。
アーキテクチャ比較の概要
以下の表は、従来のTiDBからTiDB Xへのアーキテクチャ上の移行をまとめたものであり、TiDB Xがスケーラビリティ、パフォーマンス分離、およびコスト効率をどのように向上させるかを説明しています。


