TiFlash分散ストレージおよびコンピューティングアーキテクチャと S3 サポート
デフォルトでは、 TiFlashはstorageとコンピューティングを組み合わせたアーキテクチャを使用してデプロイされ、各TiFlashノードはstorageとコンピューティングノードの両方として機能します。TiDB v7.0.0以降、 TiFlashは分散型storageとコンピューティングアーキテクチャをサポートし、Amazon S3またはS3互換オブジェクトstorage(MinIOなど)にデータを保存できるようになりました。
アーキテクチャの概要
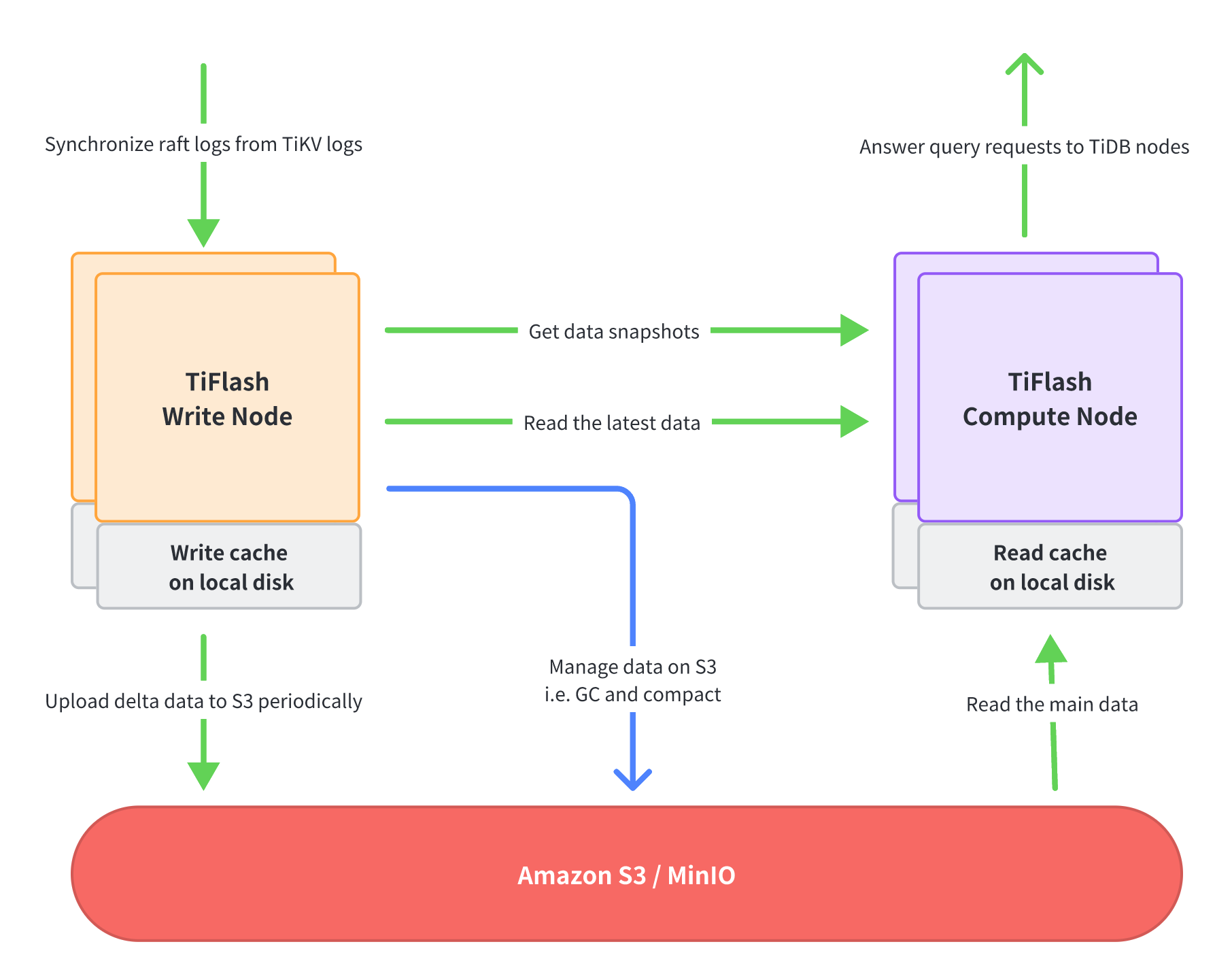
分散型storageおよびコンピューティングアーキテクチャでは、 TiFlashプロセスの異なる機能が分割され、書き込みノードとコンピューティングノードという2種類のノードに割り当てられます。これらの2種類のノードは個別に導入および拡張できるため、必要に応じて導入する書き込みノードとコンピューティングノードの数を決定できます。
TiFlash書き込みノード
書き込みノードは、TiKVからRaftログデータを受け取り、列指向形式に変換し、一定期間内に更新されたすべてのデータを定期的にパッケージ化してS3にアップロードします。さらに、書き込みノードは、クエリパフォーマンスを向上させるための継続的なデータ整理や不要なデータの削除など、S3上のデータを管理します。
書き込みノードは、メモリの過剰な使用を避けるために、ローカル ディスク (通常は NVMe SSD) を使用して最新の書き込みデータをキャッシュします。
TiFlashコンピューティングノード
コンピューティングノードは、TiDBノードから送信されたクエリリクエストを実行します。まず、書き込みノードにアクセスしてデータのスナップショットを取得し、次に書き込みノードから最新のデータ(つまり、まだS3にアップロードされていないデータ)を読み取り、残りのデータの大部分をS3から読み取ります。
コンピューティング ノードは、ローカル ディスク (通常は NVMe SSD) をデータ ファイルのキャッシュとして使用し、リモートの場所 (書き込みノードまたは S3) から同じデータを繰り返し読み取ることを回避して、クエリ パフォーマンスを向上させます。
コンピューティングノードはステートレスであり、スケーリング速度は2段階レベルです。この機能を利用することで、以下のようにコストを削減できます。
- クエリのワークロードが低い場合は、コンピューティングノードの数を減らしてコストを削減します。クエリがない場合、すべてのコンピューティングノードを停止することもできます。
- クエリのワークロードが増加した場合は、コンピューティング ノードの数を迅速に増やして、クエリのパフォーマンスを確保します。
シナリオ
TiFlashの分散型storageおよびコンピューティングアーキテクチャは、コスト効率の高いデータ分析サービスに最適です。このアーキテクチャでは、storageとコンピューティングリソースを必要に応じて個別に拡張できるため、以下のシナリオで大きなメリットが得られます。
データ量は膨大ですが、頻繁にクエリされるデータはごくわずかです。データの大部分はコールドデータであり、クエリ頻度は低いです。このため、頻繁にクエリされるデータは通常、コンピュートノードのローカルSSDにキャッシュされ、高速なクエリパフォーマンスを提供します。一方、その他のコールドデータの大部分は、storageコストを節約するために、低コストのS3などのオブジェクトstorageに保存されます。
コンピューティングリソースの需要には明らかなピークと谷があります。例えば、集中的なリコンシリエーションクエリは通常夜間に実行され、多くのコンピューティングリソースを必要とします。このような場合、夜間に一時的にコンピューティングノードを追加することを検討できます。一方、他の時間帯には、通常のクエリタスクを実行するために必要なコンピューティングノードの数は少なくて済みます。
前提条件
TiFlashデータを保存するための Amazon S3 バケットを準備します。
既存のバケットを使用することもできますが、TiDBクラスターごとに専用のキープレフィックスを予約する必要があります。S3バケットの詳細については、 AWSドキュメントご覧ください。
ミニオなどの他の S3 互換オブジェクトstorageを使用することもできます。
TiFlash はデータにアクセスするために以下の S3 API を使用する必要があります。TiDB クラスター内のTiFlashノードにこれらの API に対する必要な権限が付与されていることを確認してください。
- オブジェクトを配置する
- GetObject
- オブジェクトのコピー
- オブジェクトの削除
- リストオブジェクトV2
- オブジェクトタグ付けの取得
- PutBucketライフサイクル
TiDBクラスターに、storageとコンピューティングを組み合わせたアーキテクチャを使用してデプロイされたTiFlashノードがないことを確認してください。もしある場合は、すべてのテーブルのTiFlashレプリカ数を
0に設定し、すべてのTiFlashノードを削除してください。例:SELECT * FROM INFORMATION_SCHEMA.TIFLASH_REPLICA; # Query all tables with TiFlash replicas ALTER TABLE table_name SET TIFLASH REPLICA 0; # Set the TiFlash replica count of all tables to `0`tiup cluster scale-in mycluster -N 'node0,node1...' # Remove all TiFlash nodes tiup cluster display mycluster # Wait for all TiFlash nodes to enter the Tombstone state tiup cluster prune mycluster # Remove all TiFlash nodes in the Tombstone state
使用法
デフォルトでは、 TiUPはTiFlash を結合storageおよびコンピューティングアーキテクチャにデプロイします。分離storageおよびコンピューティングアーキテクチャにTiFlashをデプロイする必要がある場合は、以下の手順に従って手動で設定してください。
次の構成を持つ、
scale-out.topo.yamlなどのTiFlashトポロジ構成ファイルを準備します。tiflash_servers: # In the TiFlash topology configuration file, the `storage.s3` configuration indicates that the disaggregated storage and compute architecture is used for deployment. # If `flash.disaggregated_mode: tiflash_compute` is configured for a node, it is a Compute Node. # If `flash.disaggregated_mode: tiflash_write` is configured for a node, it is a Write Node. # 172.31.8.1~2 are TiFlash Write Nodes - host: 172.31.8.1 config: flash.disaggregated_mode: tiflash_write # This is a Write Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 endpoint address storage.s3.bucket: mybucket # TiFlash stores all data in this bucket storage.s3.root: /cluster1_data # Root directory where data is stored in the S3 bucket storage.s3.access_key_id: {ACCESS_KEY_ID} # Access S3 with ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # Access S3 with SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Local data directory of the Write Node. Configure it in the same way as the directory configuration of the coupled storage and compute architecture - host: 172.31.8.2 config: flash.disaggregated_mode: tiflash_write # This is a Write Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 endpoint address storage.s3.bucket: mybucket # TiFlash stores all data in this bucket storage.s3.root: /cluster1_data # Root directory where data is stored in the S3 bucket storage.s3.access_key_id: {ACCESS_KEY_ID} # Access S3 with ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # Access S3 with SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Local data directory of the Write Node. Configure it in the same way as the directory configuration of the coupled storage and compute architecture # 172.31.9.1~2 are TiFlash Compute Nodes - host: 172.31.9.1 config: flash.disaggregated_mode: tiflash_compute # This is a Compute Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 endpoint address storage.s3.bucket: mybucket # TiFlash stores all data in this bucket storage.s3.root: /cluster1_data # Root directory where data is stored in the S3 bucket storage.s3.access_key_id: {ACCESS_KEY_ID} # Access S3 with ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # Access S3 with SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Local data directory of the Compute Node. Configure it in the same way as the directory configuration of the coupled storage and compute architecture storage.remote.cache.dir: /data1/tiflash/cache # Local data cache directory of the Compute Node storage.remote.cache.capacity: 858993459200 # 800 GiB - host: 172.31.9.2 config: flash.disaggregated_mode: tiflash_compute # This is a Compute Node storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 endpoint address storage.s3.bucket: mybucket # TiFlash stores all data in this bucket storage.s3.root: /cluster1_data # Root directory where data is stored in the S3 bucket storage.s3.access_key_id: {ACCESS_KEY_ID} # Access S3 with ACCESS_KEY_ID storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # Access S3 with SECRET_ACCESS_KEY storage.main.dir: ["/data1/tiflash/data"] # Local data directory of the Compute Node. Configure it in the same way as the directory configuration of the coupled storage and compute architecture storage.remote.cache.dir: /data1/tiflash/cache # Local data cache directory of the Compute Node storage.remote.cache.capacity: 858993459200 # 800 GiB上記の
ACCESS_KEY_IDとSECRET_ACCESS_KEY設定ファイルに直接記述されていることに注意してください。環境変数を使用して個別に設定することもできます。両方の方法で設定した場合、環境変数が優先されます。環境変数を使用して
ACCESS_KEY_IDとSECRET_ACCESS_KEY構成するには、 TiFlashTiFlashを開始するユーザー環境 (通常はtidb) に切り替え、~/.bash_profile変更して次の構成を追加します。export S3_ACCESS_KEY_ID={ACCESS_KEY_ID} export S3_SECRET_ACCESS_KEY={SECRET_ACCESS_KEY}storage.s3.endpointhttpまたはhttpsモードを使用した S3 接続をサポートしており、URL を直接変更することでモードを設定できます。例:https://s3.{region}.amazonaws.com。
TiFlashノードを追加し、 TiFlashレプリカの数をリセットします。
tiup cluster scale-out mycluster ./scale-out.topo.yamlALTER TABLE table_name SET TIFLASH REPLICA 1;分散storageおよびコンピューティングアーキテクチャを使用してTiFlash をクエリするように TiDB 構成を変更します。
TiDB 構成ファイルを編集モードで開きます。
tiup cluster edit-config myclusterTiDB 構成ファイルに次の構成項目を追加します。
server_configs: tidb: disaggregated-tiflash: true # Query TiFlash using the disaggregated storage and compute architectureTiDBを再起動します。
tiup cluster reload mycluster -R tidb
制限
- TiFlash は、分離storageおよびコンピューティングアーキテクチャと**結合storageおよびコンピューティングアーキテクチャ**間のインプレース切り替えをサポートしていません。分離アーキテクチャに切り替える前に、結合アーキテクチャを使用してデプロイされている既存のTiFlashノードをすべて削除する必要があります。
- あるアーキテクチャから別のアーキテクチャに移行した後、すべてのTiFlashデータを再度複製する必要があります。
- 同じTiDBクラスター内では、同じアーキテクチャのTiFlashノードのみが許可されます。1つのクラスター内で2つのアーキテクチャを共存させることはできません。
- 分散型storageおよびコンピューティングアーキテクチャはS3 API を使用したオブジェクトstorageのみをサポートしますが、結合型storageおよびコンピューティングアーキテクチャはローカルstorageのみをサポートします。
- S3storageを使用する場合、 TiFlashノードは自身のノード上にないファイルのキーを取得できないため、 保存時の暗号化機能は使用できません。