TiDBストレージ
このドキュメントでは、 TiKVの設計アイデアと主要な概念をいくつか紹介します。
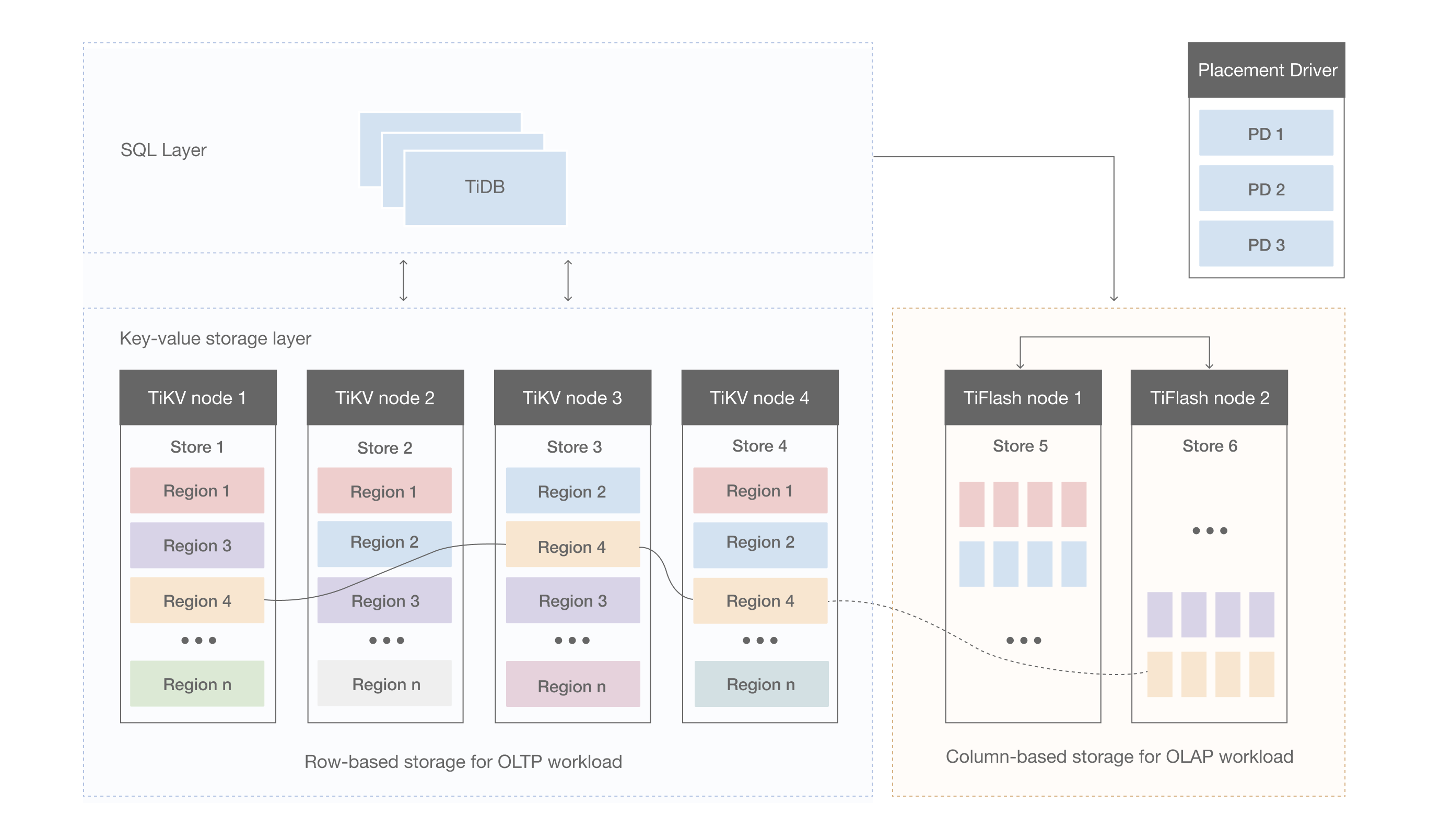
キーと値のペア
データストレージシステムで最初に決定すべきことは、データストレージモデル、つまりデータをどのような形式で保存するかです。TiKVはキーバリューモデルを採用しており、順序付けされたトラバーサル手法を提供します。TiKVデータストレージモデルには、以下の2つの重要なポイントがあります。
- これは、キーと値のペアを格納する巨大なマップ (C++ の
std::Mapに似ています) です。 - マップ内のキーと値のペアは、キーのバイナリ順序に従って順序付けられます。つまり、特定のキーの位置を Seek し、次に Next メソッドを呼び出して、このキーよりも大きいキーと値のペアを増分順に取得できます。
なお、本ドキュメントで説明するTiKVのKVstorageモデルは、SQLテーブルとは一切関係ありません。本ドキュメントではSQL関連の概念については説明せず、TiKVのような高性能で信頼性の高い分散型キーバリューストレージの実装方法のみに焦点を当てています。
ローカルストレージ(RocksDB)
あらゆる永続ストレージエンジンでは、データは最終的にディスクに保存されます。TiKVも例外ではありません。TiKVはデータをディスクに直接書き込むのではなく、データストレージを担うRocksDBにデータを保存します。その理由は、スタンドアロンストレージエンジン、特に綿密な最適化を必要とする高性能スタンドアロンエンジンの開発には多大なコストがかかるためです。
RocksDBは、Facebookがオープンソース化した優れたスタンドアロンストレージエンジンです。このエンジンは、単一のエンジンでTiKVの様々な要件を満たすことができます。ここでは、RocksDBを単一の永続的なキーバリューマップと見なすことができます。
Raftプロトコル
さらに、TiKV の実装では、1 台のマシンに障害が発生した場合でもデータの安全性を確保するという、より困難な問題に直面します。
簡単な方法は、データを複数のマシンに複製することです。こうすることで、1台のマシンに障害が発生しても、他のマシンのレプリカが引き続き利用可能になります。つまり、信頼性が高く、効率的で、レプリカに障害が発生した場合でも対処できるデータ複製スキームが必要です。これらはすべて、 Raftアルゴリズムによって可能になります。
Raftはコンセンサスアルゴリズムです。このドキュメントではRaftについて簡単に説明します。詳細については理解しやすいコンセンサスアルゴリズムを求めてご覧ください。Raftにはいくつかの重要な機能があります。
- Leader選挙
- メンバーシップの変更(レプリカの追加、レプリカの削除、リーダーの譲渡など)
- ログレプリケーション
TiKVはRaftを使用してデータレプリケーションを実行します。各データ変更はRaftログとして記録されます。Raftログレプリケーションにより、データはRaftグループ内の複数のノードに安全かつ確実に複製されます。ただし、 Raftプロトコルでは、書き込みが成功するには、データが過半数のノードに複製されている必要があります。
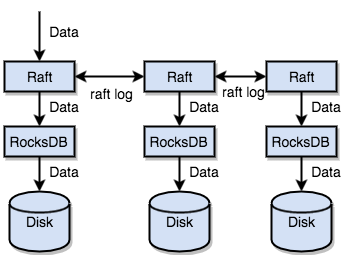
要約すると、TiKVはスタンドアロンマシンRocksDBを介してデータをディスクに迅速に保存し、マシン障害時にはRaftを介して複数のマシンにデータを複製できます。データはRocksDBではなくRaftインターフェースを介して書き込まれます。Raftの実装により、TiKVは分散型キーバリューストレージになります。たとえ少数のマシン障害が発生しても、TiKVはネイティブRaftプロトコルによって自動的に複製を完了できるため、アプリケーションには影響しません。
リージョン
理解を容易にするために、すべてのデータにレプリカが1つしかないと仮定しましょう。前述のように、TiKVは大規模で整然としたKVマップと見なすことができ、水平方向のスケーラビリティを実現するために、データは複数のマシンに分散されます。KVシステムでは、複数のマシンにデータを分散させる一般的なソリューションが2つあります。
- ハッシュ: キーによってハッシュを作成し、ハッシュ値に応じて対応するストレージノードを選択します。
- 範囲: 範囲をキーで分割します。シリアル キーのセグメントがノードに保存されます。
TiKVは、キーと値の空間全体を連続するキーセグメントに分割する2番目のソリューションを選択します。各セグメントはリージョンと呼ばれます。各リージョンは、左閉区間と右開区間の[StartKey, EndKey)で表されます。各リージョンのデフォルトのサイズ制限は256MiBですが、サイズは設定可能です。
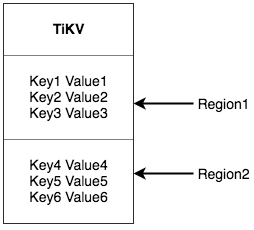
ここでのリージョンはSQLのテーブルとは何の関係もありません。このドキュメントでは、SQLについては一旦忘れてKVに焦点を当てます。データをリージョンに分割した後、TiKVは次の2つの重要なタスクを実行します。
- クラスター内のすべてのノードにデータを分散し、リージョンを基本単位として使用します。各ノードのリージョン数がほぼ同じになるようにしてください。
- リージョン内でRaftレプリケーションとメンバーシップ管理を実行します。
これら 2 つのタスクは非常に重要なので、1 つずつ紹介します。
まず、データはキーに基づいて複数のリージョンに分割され、各リージョンのデータは1つのノードにのみ保存されます(複数のレプリカは無視されます)。TiDBシステムには、クラスター内のすべてのノードにリージョンを可能な限り均等に分散させるPDコンポーネントがあります。これにより、ストレージ容量が水平方向に拡張され(他のノードのリージョンは新しく追加されたノードに自動的にスケジュールされます)、負荷分散が実現されます(あるノードに大量のデータがある一方で、他のノードにはほとんどデータがないという状況は発生しません)。
同時に、上位クライアントが必要なデータにアクセスできるようにするため、システムにはノード上の領域の分布、つまりキーの正確なリージョンと任意のキーを通じて配置されたそのリージョンのノードを記録するコンポーネント(PD) があります。
2つ目のタスクでは、TiKVはリージョン内でデータを複製します。つまり、1つのリージョン内のデータには「レプリカ」という名前のレプリカが複数存在することになります。リージョン内の複数のレプリカは異なるノードに保存され、 Raftグループを形成します。RaftグループはRaftアルゴリズムによって一貫性が維持されます。
レプリカの1つはグループのLeaderとして機能し、もう1つはFollowerとして機能します。デフォルトでは、すべての読み取りと書き込みはLeaderを介して処理され、リーダーで読み取りが行われ、書き込みはフォロワーに複製されます。次の図は、リージョンとRaftグループの全体像を示しています。
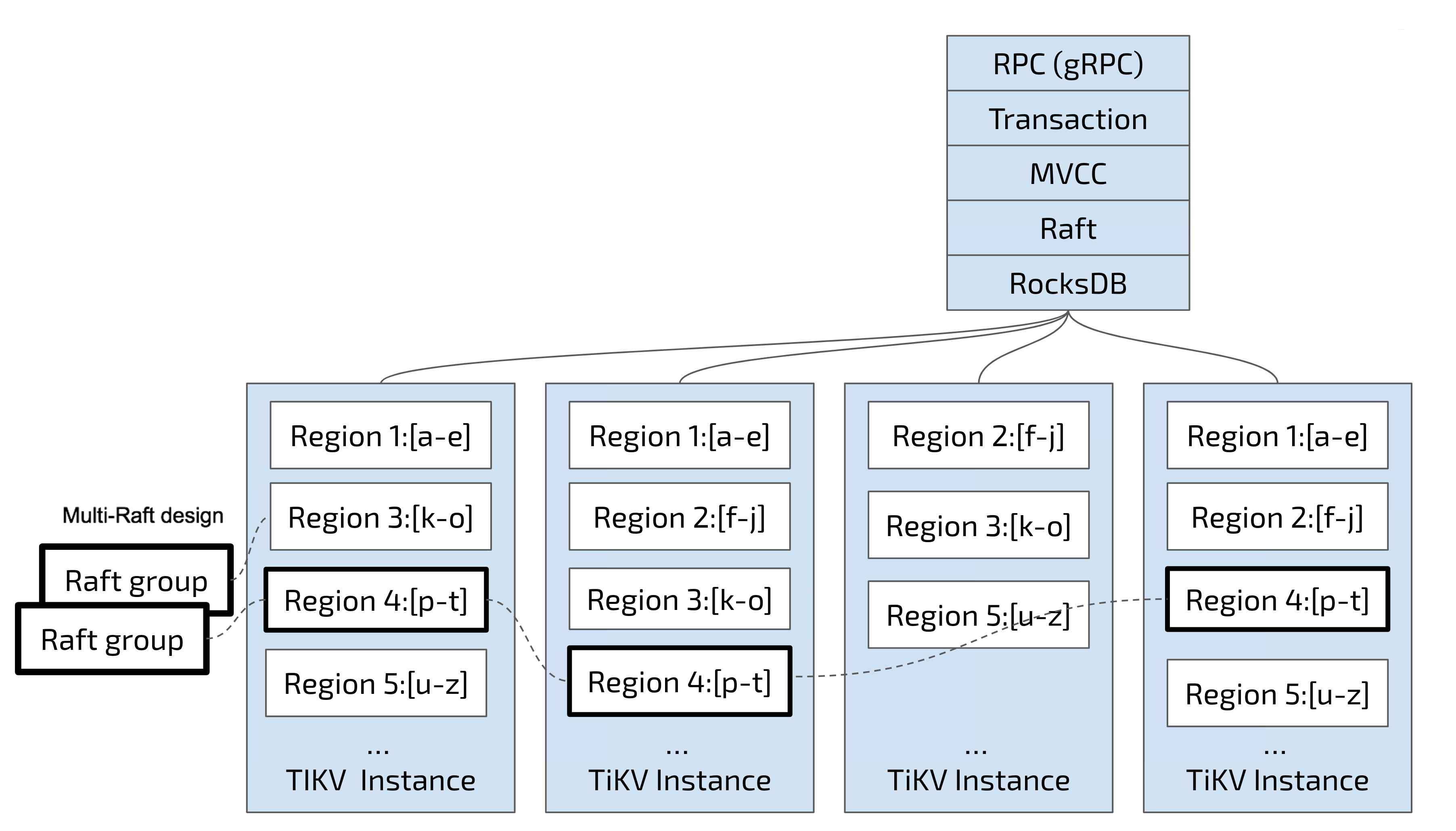
リージョン間でデータを分散・複製することで、分散型キーバリューシステムを構築し、ある程度の災害復旧能力を備えています。容量不足やディスク障害、データ損失を心配する必要はもうありません。
MVCC
TiKVは、マルチバージョン同時実行制御(MVCC)をサポートしています。クライアントAがキーへの書き込みと、クライアントBが同じキーの読み取りを同時に行うシナリオを考えてみましょう。MVCCメカニズムがなければ、これらの読み取り操作と書き込み操作は相互に排他的になり、分散シナリオではパフォーマンスの問題やデッドロックが発生します。しかし、MVCCがあれば、クライアントBがクライアントAの書き込み操作よりも論理的に早い時間に読み取り操作を実行する限り、クライアントBはクライアントAが書き込み操作を実行すると同時に元の値を正しく読み取ることができます。キーが複数の書き込み操作によって複数回変更された場合でも、クライアントBは論理的に正しい時刻に基づいて古い値を読み取ることができます。
TiKV MVCCは、キーにバージョン番号を付加することで実装されます。MVCCがない場合、TiKVのキーと値のペアは次のようになります。
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
MVCC では、TiKV のキーと値のペアは次のようになります。
Key1_Version3 -> Value
Key1_Version2 -> Value
Key1_Version1 -> Value
……
Key2_Version4 -> Value
Key2_Version3 -> Value
Key2_Version2 -> Value
Key2_Version1 -> Value
……
KeyN_Version2 -> Value
KeyN_Version1 -> Value
……
同じキーに複数のバージョンがある場合、番号の大きいバージョンが先頭に配置されます(キーの順序についてはキーバリューセクションを参照)。そのため、Key + VersionでValueを取得すると、MVCCのKeyはKeyとVersionで構築でき、 Key_Versionになります。その後、RocksDBのSeekPrefix(Key_Version) APIを使用して、このKey_Version以上の最初の位置を直接見つけることができます。
分散ACIDトランザクション
TiKVのトランザクションは、GoogleがBigTableで使用しているPercolatorモデルを採用しています。TiKVの実装はこの論文に着想を得ており、多くの最適化が行われています。詳細はトランザクションの概要をご覧ください。