TiDB スケジューリング
Placement Driver(PD)はTiDBクラスタのマネージャとして機能し、クラスタ内のリージョンのスケジュールも行います。この記事では、PDスケジューリングコンポーネントの設計とコアコンセプトを紹介します。
スケジュール状況
TiKVは、TiDBが使用する分散キーバリューストレージエンジンです。TiKVでは、データはリージョンとして編成され、複数のストアに複製されます。すべてのレプリカにおいて、リーダーが読み取りと書き込みを担当し、フォロワーはリーダーからのRaftログの複製を担当します。
ここで、次のような状況について考えてみましょう。
- ストレージスペースを効率的に利用するには、同じリージョンの複数のレプリカを、リージョンのサイズに応じて異なるノードに適切に分散する必要があります。
- 複数のデータセンター トポロジの場合、1 つのデータセンターに障害が発生すると、すべてのリージョンの 1 つのレプリカのみが失敗します。
- 新しい TiKV ストアが追加されると、そのストアにデータを再バランスさせることができます。
- TiKV ストアに障害が発生した場合、PD は次のことを考慮する必要があります。
- 障害が発生したストアの回復時間。
- 短い場合(たとえば、サービスが再起動された場合)、スケジュールが必要かどうか。
- 長時間かかる場合(例えばディスク障害が発生してデータが失われる場合)、どのようにスケジュールを立てるか。
- すべてのリージョンのレプリカ。
- 一部のリージョンでレプリカの数が足りない場合、PD はそれらを完了する必要があります。
- レプリカの数が予想より多い場合 (たとえば、障害が発生したストアがリカバリ後にクラスターに再参加する場合)、PD はそれらを削除する必要があります。
- 障害が発生したストアの回復時間。
- 読み取り/書き込み操作はリーダー上で実行されますが、少数の個別のストアにのみ分散することはできません。
- すべてのリージョンがホットなわけではないので、すべての TiKV ストアの負荷をバランスさせる必要があります。
- リージョンのバランスが取れている場合、データ転送に多くのネットワーク/ディスク トラフィックと CPU 時間が必要となり、オンライン サービスに影響する可能性があります。
これらの状況は同時に発生する可能性があり、解決が困難になります。また、システム全体が動的に変化するため、クラスタに関するすべての情報を収集し、クラスタを調整するスケジューラが必要です。そこで、TiDBクラスタにPDが導入されました。
スケジュール要件
上記の状況は、次の 2 つのタイプに分類できます。
分散型で可用性の高いストレージシステムは、次の要件を満たす必要があります。
- 適切な数のレプリカ。
- レプリカは、さまざまなトポロジに応じて異なるマシンに分散する必要があります。
- クラスターは、TiKV ピアの障害からの自動災害復旧を実行できます。
優れた分散システムには、次のような最適化が必要です。
- すべてのリージョンリーダーはストアに均等に分散されます。
- すべての TiKV ピアのストレージ容量がバランスされています。
- ホットスポットはバランスが取れています。
- オンライン サービスの安定性を確保するには、リージョンの負荷分散の速度を制限する必要があります。
- メンテナーはピアを手動でオンライン/オフラインにすることができます。
最初のタイプの要件が満たされると、システムは障害を許容できるようになります。2番目のタイプの要件が満たされると、リソースはより効率的に利用され、システムのスケーラビリティが向上します。
目標を達成するために、PDはまず、ピアの状態、 Raftグループに関する情報、ピアへのアクセス統計などの情報を収集する必要があります。次に、PDがこれらの情報と戦略に基づいてスケジューリングプランを作成できるように、PDにいくつかの戦略を指定する必要があります。最後に、PDはTiKVピアにいくつかのオペレータを配布し、スケジューリングプランを完成させます。
基本的なスケジュール演算子
すべてのスケジュール プランには、次の 3 つの基本演算子が含まれています。
- 新しいレプリカを追加する
- レプリカを削除する
- Raftグループ内のレプリカ間でリージョンリーダーを転送する
これらはRemoveReplica RaftコマンドAddReplica 、およびTransferLeaderによって実装されます。
情報収集
スケジューリングは情報収集に基づいています。つまり、PDスケジューリングコンポーネントは、すべてのTiKVピアとすべてのリージョンの状態を把握する必要があります。TiKVピアはPDに以下の情報を報告します。
各 TiKV ピアによって報告される状態情報:
各 TiKV ピアは定期的に PD にハートビートを送信します。PD はストアが生きているかどうかを確認するだけでなく、ハートビートメッセージで
StoreStateも収集します。3 にはStoreStateが含まれます。- ディスク容量合計
- 使用可能なディスク容量
- リージョンの数
- データの読み取り/書き込み速度
- 送受信されるスナップショットの数(データはスナップショットを通じてレプリカ間で複製される可能性があります)
- ストアが混雑しているかどうか
- ラベル( トポロジーの認識参照)
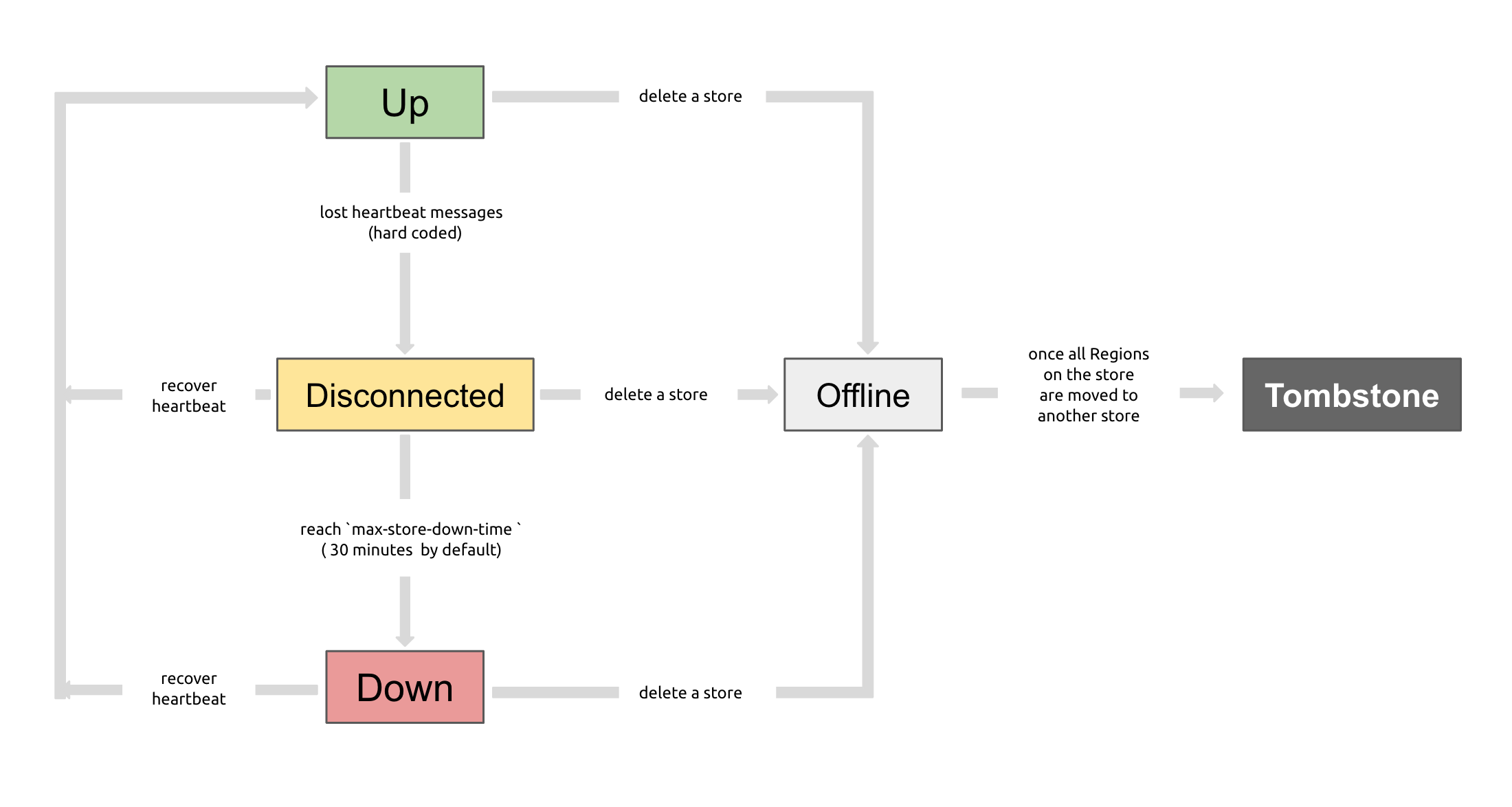
PD制御を使用して、TiKVストアのステータス(稼働中、切断、オフライン、ダウン、または廃棄)を確認できます。以下は、すべてのステータスとその関係についての説明です。
- Up : TiKVストアが稼働中です。
- 切断:PDとTiKVストア間のハートビートメッセージが20秒以上失われます。失われた期間が
max-store-down-timeで指定された時間を超えると、「切断」ステータスが「ダウン」に変わります。 - ダウン:PDとTiKVストア間のハートビートメッセージが
max-store-down-time(デフォルトでは30分)以上途絶えています。この状態になると、TiKVストアは各リージョンのレプリカを残存ストアに補充し始めます。 - オフライン: TiKV ストアは、 PD Controlによって手動でオフラインになっています。これは、ストアがオフラインになるまでの中間ステータスです。このステータスのストアは、すべてのリージョンを、再配置条件を満たす他の「稼働中」ストアに移動します。
leader_countとregion_count( PD Controlから取得) の両方が0示している場合、ストアのステータスは「オフライン」から「廃棄」に変わります。「オフライン」ステータスでは、ストア サービスまたはストアが配置されている物理サーバーを無効にしないでください。ストアがオフラインになるプロセス中に、クラスターにリージョンを再配置するターゲット ストアがない場合 (クラスター内にレプリカを保持するのに十分なストアがない場合など)、ストアは常に「オフライン」ステータスになります。 - tombstone:TiKVストアは完全にオフラインです。この状態では、
remove-tombstoneインターフェースを使用してTiKVを安全にクリーンアップできます。v6.5.0以降、手動で処理しない限り、ノードがtombstoneに変換されてから1か月後にPDは内部的に保存されたtombstoneレコードを自動的に削除します。
リージョンリーダーから報告された情報:
各リージョンリーダーは、定期的に PD にハートビートを送信して、
RegionStateの情報を報告します。1- リーダー自身の立場
- 他のレプリカの位置
- オフラインレプリカの数
- データの読み取り/書き込み速度
PD は 2 種類のハートビートによってクラスター情報を収集し、それに基づいて決定を下します。
さらに、PDは拡張インターフェースからより多くの情報を取得し、より正確な判断を下すことができます。例えば、ストアのハートビートが途切れた場合、PDはピアが一時的にダウンしているのか、それとも永久にダウンしているのかを判断できません。PDはしばらく(デフォルトでは30分)待機し、それでもハートビートが受信されない場合はストアをオフラインと見なします。その後、PDはストア上のすべてのリージョンを他のストアに分散させます。
ただし、ストアがメンテナーによって手動でオフラインに設定される場合もあります。その場合、メンテナーはPD制御インターフェースを通じてPDにその旨を通知できます。これにより、PDはすべてのリージョンを即座にバランス調整できます。
スケジュール戦略
情報を収集した後、PD はスケジュール計画を立てるためのいくつかの戦略を必要とします。
戦略1:リージョンのレプリカの数は正しい必要があります
PDは、リージョンリーダーのハートビートから、リージョンのレプリカ数が誤っていることを検知できます。このような状況が発生した場合、PDはレプリカを追加または削除することでレプリカ数を調整できます。レプリカ数が誤っている原因としては、以下のことが考えられます。
- ストア障害のため、一部のリージョンのレプリカ数が予想より少なくなっています。
- 障害後のストアのリカバリのため、一部のリージョンのレプリカ数が予想より多くなる場合があります。
max-replicasが変更されます。
戦略2:リージョンのレプリカは異なる位置に配置する必要あり
ここでの「位置」は「マシン」とは異なることに注意してください。通常、PDは、ピアの障害によって複数のレプリカが失われるのを防ぐため、リージョンのレプリカが同じピアに存在しないようにすることしかできません。ただし、本番では、次のような要件がある場合があります。
- 複数の TiKV ピアが 1 台のマシンに存在します。
- TiKV ピアは複数のラックに配置されており、ラックに障害が発生してもシステムは利用可能であると予想されます。
- TiKV ピアは複数のデータセンターにあり、データセンターに障害が発生した場合でもシステムは利用可能であると予想されます。
これらの要件の鍵となるのは、ピアが同じ「ポジション」を持つことができることです。これは、障害耐性の最小単位です。リージョンのレプリカは、同じユニットに存在してはなりません。そこで、TiKVピアにラベル設定し、PDに場所ラベル設定することで、ポジションのマーキングに使用するラベルを指定できます。
戦略3: レプリカはストア間でバランスをとる必要がある
リージョンレプリカのサイズ制限は固定されているため、ストア間でレプリカのバランスを保つことは、データ サイズのバランスを保つのに役立ちます。
戦略4:ストア間でリーダーのバランスをとる必要がある
読み取りおよび書き込み操作はRaftプロトコルに従ってリーダー上で実行されるため、PD はリーダーを複数のピアではなくクラスター全体に分散する必要があります。
戦略5:ストア間でホットスポットのバランスをとる必要がある
PD は、ストア ハートビートとリージョンハートビートからホット スポットを検出し、ホット スポットを分散することができます。
戦略6: 保管サイズはストア間でバランスをとる必要がある
起動時に、TiKV ストアはストレージのcapacity報告します。これは、ストアのスペース制限を示します。PD は、スケジュール設定時にこれを考慮します。
戦略7: スケジュール速度を調整してオンラインサービスを安定させる
スケジューリングはCPU、メモリ、ネットワーク、I/Oトラフィックを消費します。リソースを過度に使用すると、オンラインサービスに影響を及ぼします。そのため、PDは同時スケジューリングタスクの数を制限する必要があります。デフォルトではこの戦略は保守的ですが、より迅速なスケジューリングが必要な場合は変更できます。
スケジュールの実装
PDはストアハートビートとリージョンハートビートからクラスタ情報を収集し、それらの情報と戦略に基づいてスケジューリングプランを作成します。スケジューリングプランは、一連の基本オペレータから構成されます。PDはリージョンリーダーからリージョンハートビートを受信するたびに、そのリージョンに保留中のオペレータが存在するかどうかを確認します。PDがリージョンに新しいオペレータをディスパッチする必要がある場合、そのオペレータをハートビート応答に割り当て、後続のリージョンハートビートをチェックすることでオペレータを監視します。
ここでの「オペレータ」は、リージョンリーダーへの提案に過ぎず、リージョンによってスキップされる可能性があることに注意してください。リージョンLeaderは、スケジューリングオペレータの現在のステータスに基づいて、そのオペレータをスキップするかどうかを決定できます。