TiDBスナップショットバックアップおよびリストアアーキテクチャ
このドキュメントでは、バックアップ&リストア( BR )ツールを例として、TiDBスナップショットのバックアップとリストアのアーキテクチャとプロセスについて説明します。
アーキテクチャ
TiDBのスナップショットバックアップおよびリストアのアーキテクチャは以下のとおりです。
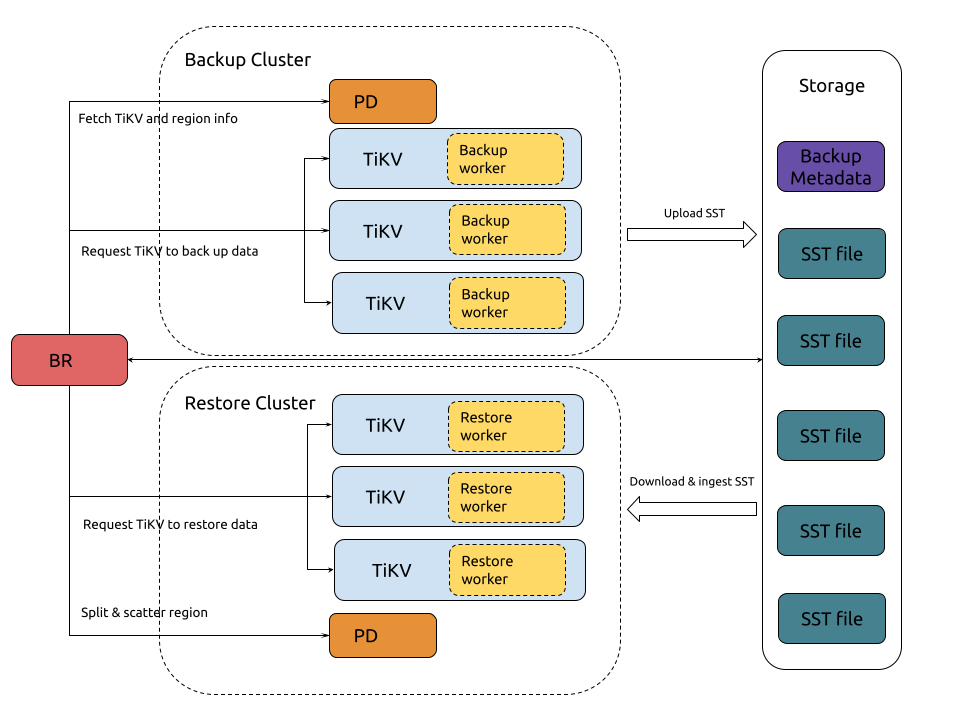
バックアップのプロセス
クラスタスナップショットバックアップの手順は以下のとおりです。
バックアップの全手順は以下のとおりです。
BR は
br backup fullコマンドを受け取ります。- バックアップの日時とストレージパスを取得します。
BRはバックアップデータのスケジュールを設定します。
- GCの一時停止: BRは、TiDB TiDB GCメカニズムによってバックアップデータがクリーンアップされないように、TiDB GCの時間を設定します。
- TiKV とリージョン情報の取得: BR はPD にアクセスして、すべての TiKV ノードのアドレスとデータのリージョン分布を取得します。
- TiKVにデータバックアップを依頼する: BRはバックアップ依頼を作成し、すべてのTiKVノードに送信します。バックアップ依頼には、バックアップのタイミング、バックアップ対象のリージョン、およびストレージパスが含まれます。
TiKVはバックアップ要求を受け入れ、バックアップワーカーを起動します。
TiKVはデータをバックアップします。
- KVのスキャン:バックアップワーカーは、リーダーが存在するリージョンから、バックアップ時点に対応するデータを読み取ります。
- SST の生成: バックアップ ワーカーはデータを SST ファイルに保存し、メモリに保存します。
- SSTファイルのアップロード:バックアップワーカーがSSTファイルをストレージパスにアップロードします。
BRは各TiKVノードからバックアップ結果を受け取ります。
- リージョン変更(例えば、TiKVノードがダウンした場合)により一部のデータのバックアップが失敗した場合、 BRはバックアップを再試行します。
- バックアップに失敗したデータがあり、再試行もできない場合、バックアップタスクは失敗します。
- すべてのデータのバックアップが完了した後、 BRはメタデータのバックアップを行います。
BRはメタデータをバックアップします。
- スキーマのバックアップ: BRはテーブルスキーマをバックアップし、テーブルデータのチェックサムを計算します。
- メタデータのアップロード: BRはバックアップメタデータを生成し、ストレージパスにアップロードします。バックアップメタデータには、バックアップタイムスタンプ、テーブルと対応するバックアップファイル、データチェックサム、およびファイルチェックサムが含まれます。
復元プロセス
クラスタスナップショットの復元プロセスは以下のとおりです。
完全な復元手順は以下のとおりです。
BR は
br restoreコマンドを受け取ります。- 復元するデータストレージパスとデータベースまたはテーブルを取得します。
- 復元対象のテーブルが存在するか、また復元要件を満たしているかを確認します。
BRは復元データのスケジュールを設定します。
- リージョンスケジュールの一時停止: BRは、復元中に自動リージョンスケジューリングを一時停止するようPDに要求します。
- スキーマの復元: BRはバックアップデータのスキーマ、および復元対象のデータベースとテーブルを取得します。新しく作成されたテーブルのIDは、バックアップデータのIDと異なる場合があることに注意してください。
- リージョンの分割と分散: BRはPDにバックアップデータに基づいてリージョンを分割(Split)するよう要求し、ストレージノードに均等に分散(Scatter)されるようにリージョンをスケジュールします。各リージョンには、指定されたデータ範囲
[start key, end key)があります。 - TiKVにデータ復元を依頼する: BRは復元依頼を作成し、リージョン分割の結果に応じて対応するTiKVノードに送信します。復元依頼には、復元するデータと書き換えルールが含まれます。
TiKVは復元要求を受け入れ、復元ワーカーを起動します。
- リストアワーカーは、リストアのために読み込む必要のあるバックアップデータを計算します。
TiKVはデータを復元します。
- SSTファイルのダウンロード:復元ワーカーは、ストレージパスから対応するSSTファイルをローカルディレクトリにダウンロードします。
- KVの書き換え:復元ワーカーは、新しいテーブルIDに基づいてKVデータを書き換えます。つまり、 キー値内の元のテーブルIDを新しいテーブルIDに置き換えます。復元ワーカーは、インデックスIDも同様に書き換えます。
- SSTの取り込み: リストアワーカーは、処理済みの SST ファイルを RocksDB に取り込みます。
- 復元結果の報告: 復元ワーカーは復元結果をBRに報告します。
BRは各TiKVノードから復元結果を受け取ります。
- 例えば TiKV ノードがダウンしている場合など、
RegionNotFoundまたはEpochNotMatchが原因でデータの復元に失敗した場合、 BR は復元を再試行します。 - 復元に失敗し、再試行もできない場合、復元タスクは失敗します。
- すべてのデータが復元されると、復元タスクは成功します。
- 例えば TiKV ノードがダウンしている場合など、
バックアップファイル
バックアップファイルの種類
スナップショットバックアップでは、以下の種類のファイルが生成されます。
SSTファイル: TiKV ノードがバックアップするデータを格納します。SSTファイルのサイズは、リージョンのサイズと同じです。backupmetaファイル: バックアップ タスクのメタデータを格納します。これには、すべてのバックアップ ファイルの数、キー範囲、サイズ、および各バックアップ ファイルのハッシュ (sha256) 値が含まれます。backup.lockファイル: 複数のバックアップ タスクが同じディレクトリにデータを保存するのを防ぎます。
SSTファイルの命名形式
データが Google Cloud Storage (GCS) または Azure Blob Storage にバックアップされる場合、SST ファイルはstoreID_regionID_regionEpoch_keyHash_timestamp_cfの形式で命名されます。名前に含まれるフィールドについては、以下のように説明します。
storeIDは TiKV ノード ID です。regionIDはリージョンID です。regionEpochはリージョンのバージョン番号です。keyHashは、範囲の開始キーのハッシュ (sha256) 値であり、ファイルの一意性を保証します。timestampは、TiKV によって生成された SST ファイルの Unix タイムスタンプです。cfRocksDB のカラムファミリーを示します (cfがdefaultまたはwriteであるデータのみを復元します)。
データがAmazon S3またはネットワークディスクにバックアップされる場合、SSTファイルはregionID_regionEpoch_keyHash_timestamp_cfという形式で命名されます。名前に含まれるフィールドについては、以下のように説明します。
regionIDはリージョンID です。regionEpochはリージョンのバージョン番号です。keyHashは、範囲の開始キーのハッシュ (sha256) 値であり、ファイルの一意性を保証します。timestampは、TiKV によって生成された SST ファイルの Unix タイムスタンプです。cfRocksDB のカラムファミリーを示します (cfがdefaultまたはwriteであるデータのみを復元します)。
SSTファイルの保存形式
- SST ファイルのストレージ形式の詳細については、 RocksDBブロックベーステーブル形式を参照してください。
- SST ファイルのバックアップ データのエンコード形式の詳細については、「テーブルデータテーブルデータのキー値へのマッピング参照してください。
バックアップファイルの構造
データを GCS または Azure Blob Storage にバックアップすると、SST ファイル、 backupmetaファイル、およびbackup.lockファイルは、次の構造で同じディレクトリに保存されます。
.
└── 20220621
├── backupmeta
|—— backup.lock
├── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
└── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
データをAmazon S3またはネットワークディスクにバックアップすると、SSTファイルはstoreIDに基づいてサブディレクトリに保存されます。構造は次のとおりです。
.
└── 20220621
├── backupmeta
|—— backup.lock
├── store1
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store100
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store2
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store3
├── store4
└── store5