ベクトルサーチの概要
ベクトル検索は、文書、画像、音声、動画など、多様なデータタイプにわたる意味的類似性検索のための強力なソリューションを提供します。開発者は、MySQLの専門知識を活用して、生成型AI機能を備えた拡張性の高いアプリケーションを構築でき、高度な検索機能の統合を簡素化できます。
概念
ベクトル検索とは、データの意味を優先して関連性の高い結果を提供する検索手法です。
キーワードの厳密な一致や単語の出現頻度に依存する従来の全文検索とは異なり、ベクトル検索はテキスト、画像、音声などの様々なデータタイプを高次元ベクトルに変換し、これらのベクトル間の類似性に基づいてクエリを実行します。この検索方法は、データの意味論的な意味や文脈情報を捉えるため、ユーザーの意図をより正確に理解することができます。
検索語がデータベース内のコンテンツと完全に一致しない場合でも、ベクトル検索はデータの意味を分析することで、ユーザーの意図に沿った結果を提供することができます。
例えば、「泳ぐ動物」というキーワードで全文検索を行うと、このキーワードと完全に一致する結果のみが表示されます。一方、ベクトル検索では、キーワードと完全に一致しない場合でも、魚やアヒルなど、他の泳ぐ動物に関する結果も表示されることがあります。
ベクトル埋め込み
ベクトル埋め込み(または埋め込み)とは、現実世界のオブジェクトを高次元空間で表現する数値のシーケンスです。これは、文書、画像、音声、動画などの非構造化データの意味と文脈を捉えます。
ベクトル埋め込みは機械学習において不可欠であり、意味的類似性検索の基盤となる。
TiDB は、ベクトル埋め込みのstorageと検索を最適化するように設計された、シームレス ベクトルデータ型とベクトル検索インデックスを導入し、AI アプリケーションでの使用を強化します。ベクトル エンベディングを TiDB に保存し、ベクトル検索クエリを実行して、これらのデータ タイプを使用して最も関連性の高いデータを見つけることができます。
埋め込みモデル
埋め込みモデルは、データをベクトル埋め込みに変換するアルゴリズムです。
適切な埋め込みモデルを選択することは、セマンティック検索結果の精度と関連性を確保するために重要です。非構造化テキスト データの場合は、 大規模テキスト埋め込みベンチマーク(MTEB)リーダーボードリーダーボードで最高のパフォーマンスのテキスト埋め込みモデルを見つけることができます。
特定のデータタイプに対応したベクトル埋め込みを生成する方法については、統合チュートリアルまたは埋め込みモデルの例を参照してください。
ベクトル検索の仕組み
生データをベクトル埋め込みに変換してTiDBに保存した後、アプリケーションはベクトル検索クエリを実行して、ユーザーのクエリに対して意味的または文脈的に最も関連性の高いデータを見つけることができます。
TiDBベクトル検索は、 距離関数指定されたベクトルとデータベースに格納されているベクトル間の距離を計算するために用いられます。クエリで指定されたベクトルに最も近いベクトルは、意味的に最も類似したデータを表します。
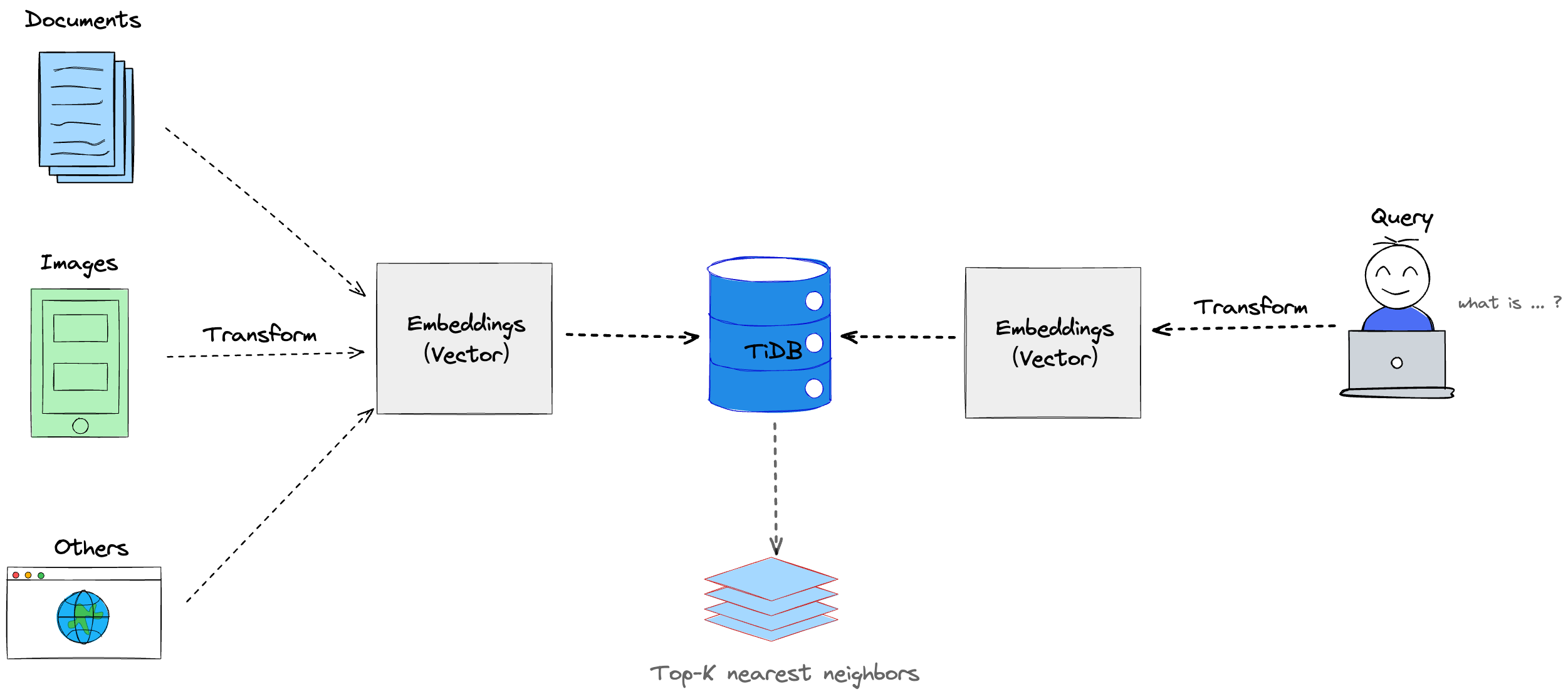
TiDBは、ベクトル検索機能を統合したリレーショナルデータベースとして、データとその対応するベクトル表現(ベクトル埋め込み)を1つのデータベースにまとめて保存できます。データの保存方法は以下のいずれかの方法を選択できます。
- データとその対応するベクトル表現を、同じテーブルの異なる列に格納します。
- データとその対応するベクトル表現を別々のテーブルに格納します。このため、データを取得する際には
JOINクエリを使用してテーブルを結合する必要があります。
ユースケース
検索拡張生成(RAG)
検索拡張生成(RAG)は、大規模言語モデル(LLM)の出力を最適化するために設計されたアーキテクチャです。RAGアプリケーションは、ベクトル検索を用いることで、ベクトル埋め込みをデータベースに保存し、LLMが応答を生成する際に、関連する文書を追加のコンテキストとして取得することができます。これにより、応答の質と関連性が向上します。
セマンティック検索
セマンティック検索とは、単にキーワードを照合するのではなく、クエリの意味に基づいて検索結果を返す検索技術です。埋め込み表現を用いて、異なる言語や様々な種類のデータ(テキスト、画像、音声など)における意味を解釈します。そして、ベクトル検索アルゴリズムがこれらの埋め込み表現を利用して、ユーザーのクエリに最も合致する関連性の高いデータを見つけ出します。
レコメンデーションエンジン
レコメンデーションエンジンとは、ユーザーにとって関連性が高くパーソナライズされたコンテンツ、製品、サービスを積極的に提案するシステムです。これは、ユーザーの行動や嗜好を表す埋め込みデータを作成することで実現されます。これらの埋め込みデータは、他のユーザーが操作したり興味を示したりした類似アイテムをシステムが特定するのに役立ちます。これにより、レコメンデーションがユーザーにとって関連性が高く魅力的なものになる可能性が高まります。
関連項目
TiDB Vector Searchの利用を開始するには、以下のドキュメントを参照してください。
