SELECT
SELECT 语句用于从 TiDB 读取数据。
语法图
SelectStmt:

FromDual:

WhereClauseOptional:
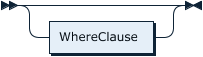
SelectStmtOpts:

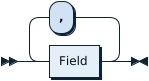
SelectStmtFieldList:
TableRefsClause:
- TableRefsClause
- AsOfClause
TableRefsClause ::=
TableRef AsOfClause? ( ',' TableRef AsOfClause? )*
AsOfClause ::=
'AS' 'OF' 'TIMESTAMP' Expression
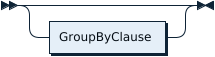
SelectStmtGroup:
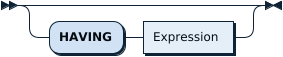
HavingClause:
OrderByOptional:
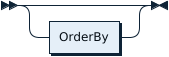
SelectStmtLimit:
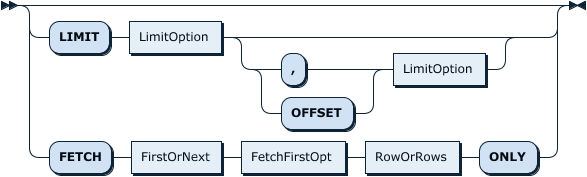
FirstOrNext:

FetchFirstOpt:
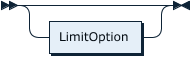
RowOrRows:
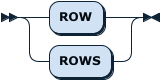
SelectLockOpt:
- SelectLockOpt
- TableList
SelectLockOpt ::=
( ( 'FOR' 'UPDATE' ( 'OF' TableList )? 'NOWAIT'? )
| ( 'LOCK' 'IN' 'SHARE' 'MODE' ) )?
TableList ::=
TableName ( ',' TableName )*
WindowClauseOptional
TableSampleOpt
- TableSampleOpt
TableSampleOpt ::=
'TABLESAMPLE' 'REGIONS()'
语法元素说明
示例
SELECT
CREATE TABLE t1 (id INT NOT NULL PRIMARY KEY AUTO_INCREMENT, c1 INT NOT NULL);
Query OK, 0 rows affected (0.11 sec)
INSERT INTO t1 (c1) VALUES (1),(2),(3),(4),(5);
Query OK, 5 rows affected (0.03 sec)
Records: 5 Duplicates: 0 Warnings: 0
SELECT * FROM t1;
+----+----+
| id | c1 |
+----+----+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
+----+----+
5 rows in set (0.00 sec)
下面这个例子使用 tiup bench tpcc prepare 生成的数据,其中第一个查询展示了 TABLESAMPLE 的用法。
mysql> SELECT AVG(s_quantity), COUNT(s_quantity) FROM stock TABLESAMPLE REGIONS();
+-----------------+-------------------+
| AVG(s_quantity) | COUNT(s_quantity) |
+-----------------+-------------------+
| 59.5000 | 4 |
+-----------------+-------------------+
1 row in set (0.00 sec)
mysql> SELECT AVG(s_quantity), COUNT(s_quantity) FROM stock;
+-----------------+-------------------+
| AVG(s_quantity) | COUNT(s_quantity) |
+-----------------+-------------------+
| 54.9729 | 1000000 |
+-----------------+-------------------+
1 row in set (0.52 sec)
SELECT ... INTO OUTFILE
SELECT ... INTO OUTFILE 语句用于将查询结果写入到文件中。
在该语句中,你可以使用以下子句来指定输出文件的格式:
FIELDS TERMINATED BY:指定文件中字段的分隔符。例如,你可以将分隔符指定为','以输出逗号分隔值(CSV)或'\t'以输出制表符分隔值(TSV)。FIELDS ENCLOSED BY:指定文件中包裹每个字段的字符。LINES TERMINATED BY:如果你希望以某个特殊的字符为结尾来切分行数据,可以使用该子句指定文件中行的终止符。
假设有一个名为 t 的表,包含以下三列:
mysql> CREATE TABLE t (a INT, b VARCHAR(10), c DECIMAL(10,2));
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO t VALUES (1, 'a', 1.1), (2, 'b', 2.2), (3, 'c', 3.3);
Query OK, 3 rows affected (0.01 sec)
以下示例展示了如何使用 SELECT ... INTO OUTFILE 语句将查询结果写入到文件中。
示例 1:
mysql> SELECT * FROM t INTO OUTFILE '/tmp/tmp_file1';
Query OK, 3 rows affected (0.00 sec)
在此示例中,你可以在 /tmp/tmp_file1 中看到以下查询结果:
1 a 1.10
2 b 2.20
3 c 3.30
示例 2:
mysql> SELECT * FROM t INTO OUTFILE '/tmp/tmp_file2' FIELDS TERMINATED BY ',' ENCLOSED BY '"';
Query OK, 3 rows affected (0.00 sec)
在此示例中,你可以在 /tmp/tmp_file2 中看到以下查询结果:
"1","a","1.10"
"2","b","2.20"
"3","c","3.30"
示例 3:
mysql> SELECT * FROM t INTO OUTFILE '/tmp/tmp_file3'
-> FIELDS TERMINATED BY ',' ENCLOSED BY '\'' LINES TERMINATED BY '<<<\n';
Query OK, 3 rows affected (0.00 sec)
在此示例中,你可以在 /tmp/tmp_file3 中看到以下查询结果:
'1','a','1.10'<<<
'2','b','2.20'<<<
'3','c','3.30'<<<
MySQL 兼容性
- 不支持
SELECT ... INTO @variable语法。 - 不支持
SELECT ... INTO DUMPFILE语法。 - 不支持 MySQL 5.7 中支持的
SELECT .. GROUP BY expr语法,而是匹配 MySQL 8.0 的行为,不按照默认的顺序进行排序。 SELECT ... TABLESAMPLE ...是 TiDB 的扩展语法,用于兼容其他数据库以及 ISO/IEC 9075-2 标准,但 MySQL 不支持该语法。