TiDB Xアーキテクチャ
TiDB Xは、クラウドネイティブのオブジェクトstorageをTiDBのバックボーンとする新しい分散SQLアーキテクチャです。現在、 TiDB Cloudで利用可能です。
TiDB Xは、 クラシックTiDBのシェアード・ナッシング・アーキテクチャからクラウドネイティブのシェアード・ストレージ・アーキテクチャへの根本的な進化を表しています。オブジェクト・storageを共有永続storageレイヤーとして活用することで、TiDB Xはオンライン・トランザクション・ワークロードとリソースを大量に消費するバックグラウンド・タスクを分離し、コンピューティング・ワークロードを分離します。
このドキュメントでは、TiDB Xアーキテクチャを紹介し、TiDB X の背後にある動機を説明し、従来の TiDBアーキテクチャと比較した主な革新について説明します。
従来のTiDBの制限
このセクションでは、従来の TiDB のアーキテクチャと、TiDB X の開発の動機となったその制限を分析します。
従来のTiDBの強み
クラシックTiDBのシェアードナッシングアーキテクチャは、従来のモノリシックデータベースの限界に対処します。コンピューティングとstorageを分離し、 Raftコンセンサスアルゴリズムを活用することで、分散SQLワークロードに必要な耐障害性とスケーラビリティを実現します。
従来の TiDBアーキテクチャは、次の基本機能を提供します。
- 水平スケーラビリティ:読み取りと書き込みの両方のパフォーマンスにおいて、線形スケーリングをサポートします。クラスターは、1秒あたり数百万件のクエリ(QPS)を処理できるスケールを実現し、数千万のテーブルにわたる1PiBを超えるデータを管理できます。
- ハイブリッドトランザクションおよび分析処理(HTAP) :トランザクションと分析のワークロードを統合します。負荷の高い集計および結合処理をTiFlash (列指向storageエンジン)にプッシュダウンすることで、複雑なETLパイプラインを必要とせず、最新のトランザクションデータに対する予測可能なリアルタイム分析を実現します。
- 非ブロッキングなスキーマ変更:完全にオンラインのDDL実装を使用します。スキーマ変更によって読み取りや書き込みがブロックされることがないため、アプリケーションのレイテンシーや可用性への影響を最小限に抑えながらデータモデルを進化させることができます。
- 高可用性:シームレスなクラスタアップグレードとスケーリング操作をサポートします。これにより、メンテナンスやリソース調整中でも重要なサービスへのアクセスが確保されます。
- マルチクラウドサポート:オープンソースソリューションとして動作し、
Amazon Web Services (AWS)、Google Cloud、Microsoft Azure、Alibaba Cloud Amazon Web Services (AWS)、Google Cloud、Microsoft Azure これにより、ベンダー ロックインのないクラウド中立性が実現されます。
従来のTiDBの課題
従来のTiDBのシェアードナッシングアーキテクチャは高い耐障害性を提供しますが、storageとコンピューティングがローカルノード上で密結合されているため、非常に大規模な環境では限界が生じます。データ量が増加し、クラウドネイティブの要件が進化するにつれて、いくつかの構造的な課題が生じます。
スケーラビリティの制限
データ移動のオーバーヘッド:従来のTiDBでは、スケールアウト(ノードの追加)またはスケールイン(ノードの削除)操作を行う際に、ノード間でSSTファイルを物理的に移動する必要があります。大規模なデータセットの場合、このプロセスは時間がかかり、データ移動中のCPUおよびI/Oの消費量の増加により、オンライントラフィックのパフォーマンスが低下する可能性があります。
ストレージエンジンのボトルネック:従来のTiDBの基盤となるRocksDBstorageエンジンは、グローバルミューテックスで保護された単一のLSMツリーを使用しています。この設計により、大規模なデータセット(例えば、6TiBを超えるデータやTiKVノードあたり30万個を超えるSSTファイルなど)の処理にシステムが苦労するスケーラビリティの上限が生じ、システムがハードウェア容量を最大限に活用できなくなります。
安定性とパフォーマンスの干渉
リソース競合:書き込みトラフィックが急増すると、SSTファイルをマージするための大規模なローカルコンパクションジョブが起動されます。従来のTiDBでは、これらのコンパクションジョブはオンライントラフィックを処理する同じTiKVノード上で実行されるため、CPUとI/Oリソースの競合が発生し、オンラインアプリケーションに影響を与える可能性があります。
物理的な分離の欠如:論理リージョンと物理SSTファイルの間には物理的な分離がありません。リージョンの移動(バランシング)などの操作は、ユーザークエリと直接競合するコンパクションのオーバーヘッドを発生させ、パフォーマンスのジッターにつながる可能性があります。
書き込みスロットリング:書き込み負荷が高い場合、バックグラウンドコンパクションがフォアグラウンドの書き込みトラフィックに対応できない場合、従来のTiDBはstorageエンジンを保護するためにフロー制御メカニズムを起動します。その結果、書き込みスループットのスロットリングが発生し、アプリケーションのレイテンシーが急上昇します。
資源の利用とコスト
オーバープロビジョニング: ピーク時のトラフィックやバックグラウンドメンテナンス中に安定性を維持し、パフォーマンスを確保するために、ユーザーは「最高水準点」の要件に基づいてハードウェアをオーバープロビジョニングすることがよくあります。
柔軟性のないスケーリング: コンピューティングとstorageが結合されているため、CPU 使用率が低い場合でも、ユーザーはstorage容量を増やすためだけに高価なコンピューティング負荷の高いノードを追加しなければならない場合があります。
TiDB Xの動機
TiDB Xへの移行は、データを物理的なコンピューティングリソースから分離する必要性から生まれました。シェアードナッシングアーキテクチャからシェアードストレージアーキテクチャへの移行により、TiDB Xは結合ノードの物理的な限界に対処し、以下の技術目標を達成します。
- 高速スケーリング: 物理的なデータ移行の必要性を排除することで、スケーリング パフォーマンスが最大 10 倍向上します。
- タスクの分離: バックグラウンド メンテナンス タスク (圧縮など) とオンライン トランザクション トラフィック間の干渉がゼロであることを保証します。
- リソースの弾力性: コンピューティング リソースがstorageボリュームとは独立して拡張される、真の「従量課金制」モデルを実装します。
このアーキテクチャの開発に関する追加情報については、ブログ投稿TiDB X の誕生:起源、アーキテクチャ、そして今後の展望を参照してください。
TiDB Xアーキテクチャの概要
TiDB Xは、従来のTiDB分散設計をクラウドネイティブに進化させたものです。従来のTiDBから以下のアーキテクチャ上の強みを継承しています。
- ステートレス SQLレイヤー: SQLレイヤー(TiDBサーバー) はステートレスであり、永続データを保存せずにクエリの解析、最適化、および実行を担当します。
- ゲートウェイと接続管理:TiProxy(またはロードバランサー)は、永続的なクライアント接続を維持し、SQLトラフィックをシームレスにルーティングします。元々はオンラインアップグレードをサポートするために設計されたTiProxyですが、現在ではゲートウェイコンポーネントとして自然に機能します。
- リージョンによる動的シャーディング:TiKVは、リージョン(デフォルトは256MiB)と呼ばれる範囲ベースのシャーディング単位を使用します。データは数百万のリージョンに分割され、システムはリージョンの配置、移動、ノード間の負荷分散を自動的に管理します。
TiDB Xは、ローカルのシェアードナッシングstorageをクラウドネイティブのシェアードストレージオブジェクトstorageバックボーンに置き換えることで、これらの基盤を進化させます。この移行により、「 コンピューティングとコンピューティングの分離 」モデルが実現され、リソースを大量に消費するタスクをエラスティックプールにオフロードすることで、瞬時のスケーラビリティと予測可能なパフォーマンスを実現します。
TiDB Xアーキテクチャは次のとおりです。
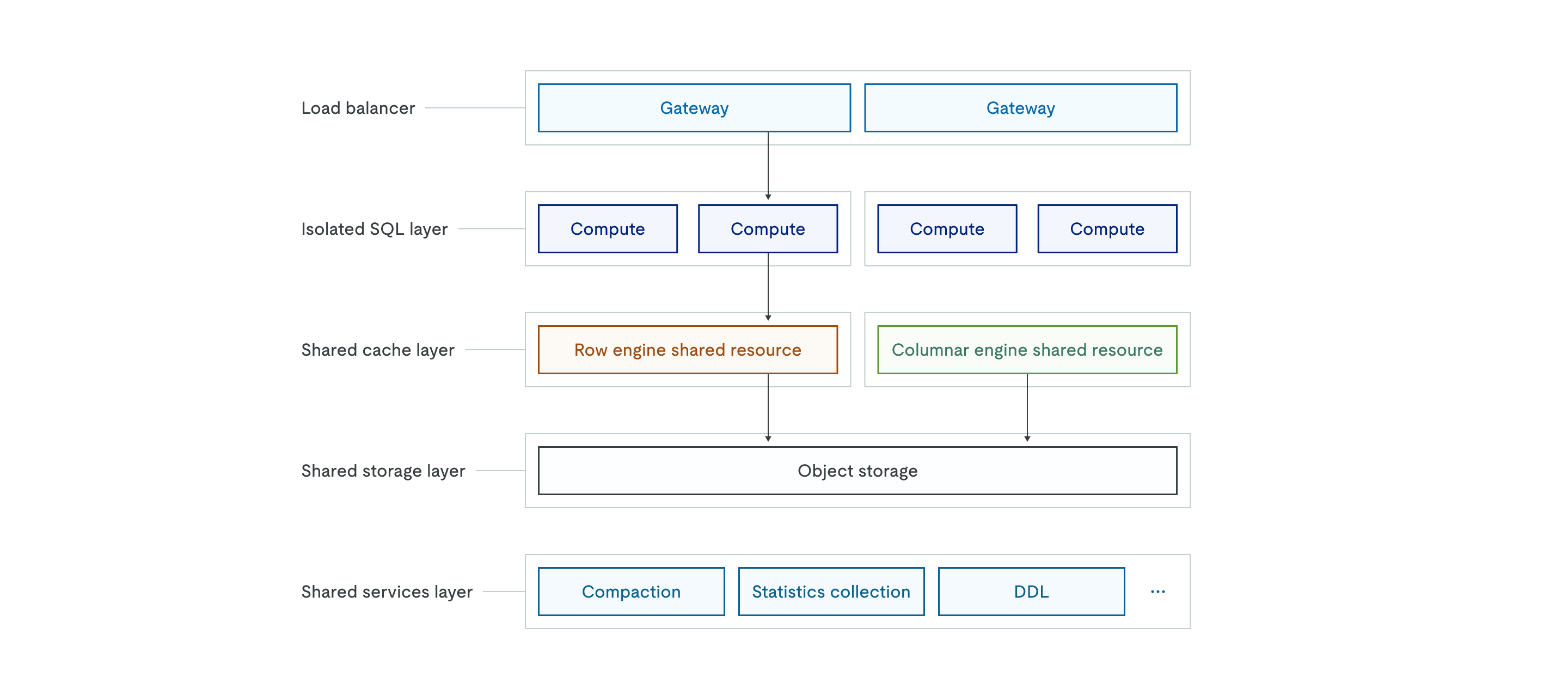
オブジェクトstorageのサポート
TiDB Xは、Amazon S3などのオブジェクトstorageを、すべてのデータの唯一の信頼できる情報源として使用します。データがローカルディスクに保存される従来のアーキテクチャとは異なり、TiDB Xは、すべてのデータの永続的なコピーを共有オブジェクトstorageレイヤーに保存します。上位の共有キャッシュレイヤー(行エンジンと列エンジン)は、低レイテンシーを保証する高性能キャッシュとして機能します。
信頼できるデータは既にオブジェクトstorageに保存されているため、バックアップはS3に保存されている増分Raftログとメタデータのみを使用するため、総データ量に関わらず、数秒でバックアップ処理を完了できます。スケールアウト処理中、新しいTiKVノードは既存のノードから大量のデータをコピーする必要はありません。代わりに、オブジェクトstorageに接続し、必要なデータをオンデマンドでロードすることで、スケールアウト処理を大幅に高速化します。
自動スケーリングメカニズム
TiDB Xアーキテクチャは、ロードバランサと分離されたSQLレイヤーのステートレス性によって、弾力的なスケーリングを実現するように設計されています。共有キャッシュレイヤーは、CPU使用率またはディスク容量に基づいてスケーリングできます。システムは、リアルタイムのワークロード需要に適応するために、数秒以内にコンピューティングポッドを自動的に追加または削除します。
この技術的な弾力性により、使用量ベースの従量課金モデルが実現します。ユーザーはピーク負荷に備えてリソースをプロビジョニングする必要がなくなります。システムはトラフィックの急増時には自動的にスケールアウトし、アイドル時にはスケールインすることでコストを最小限に抑えます。
マイクロサービスとワークロードの分離
TiDB Xは、多様なワークロードが互いに干渉しないように、高度な職務分離を実装しています。分離されたSQLレイヤーは、独立したコンピューティングノードのグループで構成されており、ワークロードの分離や、異なるアプリケーションが同一の基盤データを共有しながら専用のコンピューティングリソースを利用できるマルチテナントシナリオを実現します。
共有サービスレイヤーは、圧縮、統計情報収集、DDL実行といった負荷の高いデータベース操作を独立したマイクロサービスに分解します。インデックス作成や大規模データのインポートといったリソースを大量に消費するバックグラウンド操作をこのレイヤーにオフロードすることで、TiDB Xは、これらの操作がオンラインユーザートラフィックを処理するコンピューティングノードとCPUやメモリリソースを競合することを防ぎます。この設計により、重要なアプリケーションのパフォーマンス予測が容易になり、ゲートウェイ、SQLコンピューティング、キャッシュ、バックグラウンドサービスといった各コンポーネントが、それぞれのリソース需要に基づいて独立してスケーリングできるようになります。
TiDB Xの主な革新
次の図は、従来のTiDBとTiDB Xアーキテクチャを並べて比較したものです。シェアード・ナッシング設計から共有**ストレージ**設計への移行と、コンピューティング・ワークロードの分離の導入が強調されています。
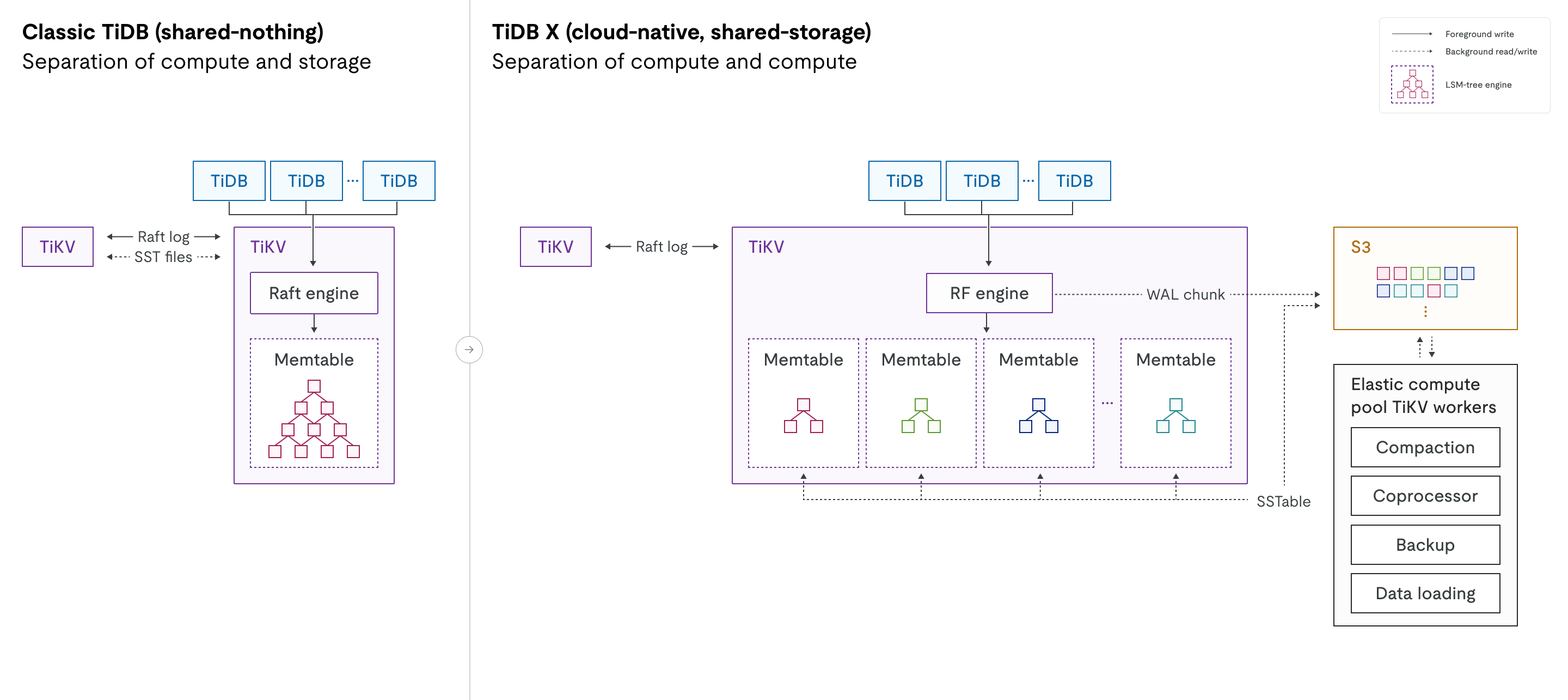
エンジンの進化:従来のTiDBでは、 Raftエンジンがマルチラフトログを管理し、RocksDBがローカルディスク上の物理データstorageを処理していました。TiDB Xでは、これらのコンポーネントは新しいRFエンジン(Raftエンジン)と再設計されたKVエンジンに置き換えられました。KVエンジンは、RocksDBに代わるLSMツリーstorageエンジンです。どちらの新しいエンジンも、高パフォーマンスとオブジェクトstorageとのシームレスな統合を実現するために特別に最適化されています。
コンピューティングワークロードの分離:図中の点線は、オブジェクトstorageレイヤーへのバックグラウンド読み取りおよび書き込み操作を表しています。TiDB Xでは、RF/KVエンジンとオブジェクトstorage間のこれらの相互作用はフォアグラウンドプロセスから分離されており、バックグラウンド操作がオンライントラフィックのレイテンシーに影響を与えないことが保証されています。
コンピューティングとコンピューティングの分離
従来のTiDBでは既にコンピューティング(SQLレイヤー)とstorage(TiKV)が分離されていますが、TiDB XではSQL層とstorage層の両方に新たな分離レイヤーが導入されています。この設計により、オンライントランザクションワークロード向けの軽量コンピューティングと、リソースを大量に消費するバックグラウンドタスク向けの高負荷コンピューティングを区別できます。
軽量コンピューティング: ユーザー クエリなどの OLTP ワークロード専用のリソース。
軽量なOLTPワークロードの場合、高負荷のコンピューティングタスクはElastic Compute Poolにオフロードされるため、ユーザートラフィックを処理するTiKVサーバーはオンラインクエリ専用に予約されます。その結果、TiDB Xはより少ないリソースで、より安定した予測可能なパフォーマンスを実現します。この分離により、バックグラウンドタスクがオンライントランザクション処理に干渉することがなくなります。
ヘビーコンピューティング: 圧縮、バックアップ、統計収集、データの読み込み、低速クエリ処理などのバックグラウンド タスク用の個別のエラスティック コンピューティング プール。
DDL操作や大規模データのインポートといった高負荷なコンピューティングタスクに対して、TiDB Xは、オンライントラフィックへの影響を最小限に抑えながら、これらのワークロードをフルスピードで実行するための柔軟なコンピューティングリソースを自動的にプロビジョニングできます。例えば、インデックスを追加すると、TiDBワーカー、コプロセッサーワーカー、TiKVワーカーがデータ量に応じて動的にプロビジョニングされます。これらのプロビジョニングされた柔軟なコンピューティングリソースは、オンライントラフィックを処理するTiDBサーバーおよびTiKVサーバーから分離されているため、リソースを大量に消費する操作が重要なOLTPクエリと競合することがなくなります。実際のシナリオでは、オンラインサービスに影響を与えることなく、インデックス作成は従来のTiDBと比較して最大5倍高速化されます。
シェアードナッシングからシェアードストレージへの移行
TiDB Xは、TiKVノード間でデータを物理的にコピーする必要がある従来のシェアードナッシングアーキテクチャから、共有ストレージアーキテクチャへと移行します。TiDB Xでは、ローカルディスクではなく、オブジェクトstorage(Amazon S3など)がすべての永続データの唯一の信頼できるソースとして機能します。これにより、スケーリング操作中に大量のデータをコピーする必要がなくなり、迅速な弾力性を実現します。
オブジェクトstorageに移行しても、フォアグラウンドの読み取りおよび書き込みのパフォーマンスは低下しません。
- 読み取り操作:軽量なリクエストはローカルキャッシュとディスクから処理されます。負荷の高い読み取りワークロードのみがリモートのエラスティックコプロセッサワーカーにオフロードされます。
- 書き込み操作:オブジェクトstorageとのやり取りは非同期です。Raftログはまずローカルディスクに保存され、 Raft WAL(先行書き込みログ)チャンクはRaftグラウンドでオブジェクトstorageにアップロードされます。
- 圧縮: MemTableのデータがいっぱいになり、ローカルディスクにフラッシュされると、リージョンリーダーは SST ファイルをオブジェクトstorageにアップロードします。Elastic Compression Worker によるリモート圧縮が完了すると、TiKV ノードに通知が送られ、圧縮された SST ファイルをオブジェクトstorageからロードします。
柔軟な TCO (従量課金制)
従来のTiDBでは、ピーク時のトラフィックとバックグラウンドタスクを同時に処理するために、クラスターが過剰にプロビジョニングされることがよくあります。TiDB Xは自動スケーリングを可能にし、ユーザーは消費したリソースに対してのみ料金を支払うことができます(従量課金制)。負荷の高いタスク用のバックグラウンドリソースはオンデマンドでプロビジョニングされ、不要になったら解放されるため、無駄なコストを削減できます。
TiDB Xでは、プロビジョニングされたコンピューティング能力をリクエスト容量単位 (RCU)単位で測定します。1RCUは、一定数のSQLリクエストを処理できる固定量のコンピューティングリソースを提供します。プロビジョニングするRCUの数によって、クラスターのベースラインパフォーマンスとスループット能力が決まります。上限を設定することでコストを抑えつつ、弾力的なスケーリングのメリットを維持できます。
LSMツリーからLSMフォレストへ
従来の TiDB では、各 TiKV ノードは単一の RocksDB インスタンスを実行し、すべてのリージョンのデータを 1 つの大きな LSM ツリーに格納します。数千のリージョンのデータが混在するため、リージョンの移動、スケールアウト、スケールインなどの操作によって、大規模なコンパクションがトリガーされる可能性があります。これにより、CPU と I/O リソースが大量に消費され、オンライン トラフィックに影響を及ぼす可能性があります。単一の LSM ツリーは、グローバル ミューテックスによって保護されています。データサイズが大きくなるにつれて(たとえば、TiKV ノードあたり 6 TiB を超えるデータ、または 300,000 を超える SST ファイルなど)、グローバル ミューテックス ロックの競合が増加し、読み取りと書き込みの両方のパフォーマンスに影響を及ぼす可能性があります。
TiDB Xは、単一のLSMツリーからLSMフォレストへと移行することでstorageエンジンを再設計しました。論理的なリージョン抽象化を維持しながら、TiDB Xは各リージョンに独立したLSMツリーを割り当てます。この物理的な分離により、スケーリング、リージョン移動、データロードなどの操作におけるリージョン間のコンパクションのオーバーヘッドが排除されます。1つのリージョンに対する操作は、そのリージョンのツリー内に限定され、グローバルミューテックスの競合は発生しません。
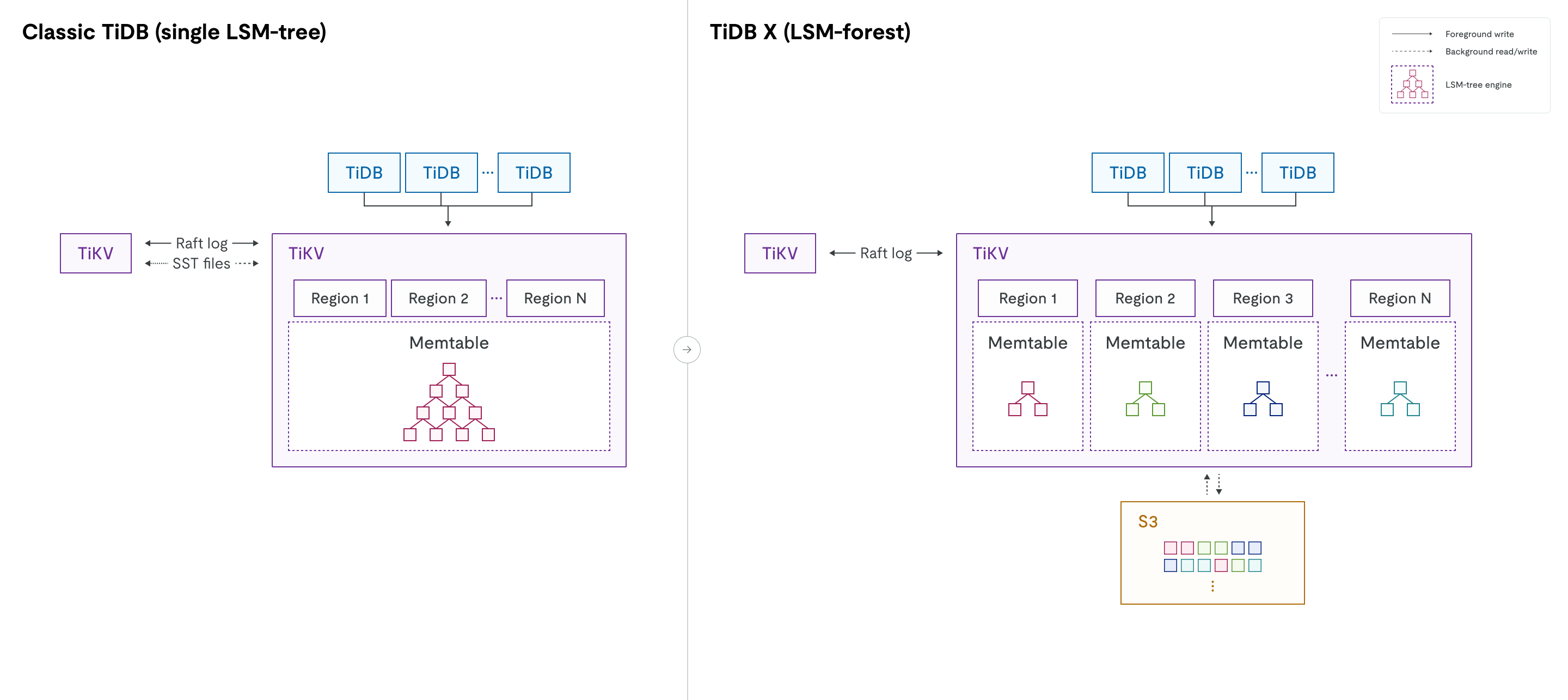
迅速で弾力的なスケーラビリティ
TiDB Xでは、データを共有オブジェクトstorageに保存し、各リージョンを独立したLSMツリーで管理することで、TiKVノードの追加や削除時に物理的なデータ移行や大規模なコンパクションを行う必要がなくなります。その結果、スケーリング処理は従来のTiDBと比較して5倍から10倍高速化され、オンラインワークロードのレイテンシーも安定して維持されます。
アーキテクチャ比較の概要
次の表は、従来の TiDB から TiDB X へのアーキテクチャの移行をまとめたものであり、TiDB X によってスケーラビリティ、パフォーマンスの分離、コスト効率がどのように向上するかを説明しています。
| 特徴 | クラシック TiDB | TiDB X | 主な利点(TiDB X) |
|---|---|---|---|
| アーキテクチャ | シェアードナッシング(データはローカルディスクに保存される) | 共有ストレージ(信頼できる永続storageとしてのオブジェクトstorage) | オブジェクトstorageはクラウドネイティブの弾力性を実現します |
| 安定性 | フォアグラウンドタスクとバックグラウンドタスクは同じリソースを共有する | コンピューティングとコンピューティングの分離(負荷の高いタスク用の柔軟なコンピューティング プール) | 書き込み集中型またはメンテナンスワークロード下の OLTP ワークロードを保護します |
| パフォーマンス | OLTPとバックグラウンドタスクがCPUとI/Oを奪い合う | 負荷の高いタスク専用のエラスティックプール | OLTP のレイテンシーを短縮し、負荷の高いタスクをより速く完了 |
| スケーリングメカニズム | 物理的なデータ移行(TiKVノード間のSSTファイルのコピー) | TiKVノードはオブジェクトstorage経由でSSTファイルの読み取りまたは書き込みのみを行います。 | スケールアウトとスケールインが5~10倍高速化 |
| ストレージエンジン | TiKV ノードごとに単一の LSM ツリー (RocksDB) | LSM フォレスト (リージョンごとに 1 つの独立した LSM ツリー) | グローバルミューテックスの競合を排除し、圧縮の干渉を軽減します |
| DDL実行 | DDLはローカルCPUとI/Oを巡ってユーザートラフィックと競合する | DDL を弾力性のあるコンピューティング リソースにオフロード | より予測可能なレイテンシーでより高速なスキーマ変更 |
| コストモデル | ピーク時のワークロードに備えてオーバープロビジョニングが必要 | 柔軟な TCO (従量課金制) | 実際のリソース消費に対してのみ支払います |
| バックアップ | データボリュームに依存する物理バックアップ | オブジェクトstorage統合によるメタデータ駆動 | バックアップ操作が大幅に高速化 |