TiDBグローバルソート
注記:
- 現在、グローバルソート処理はTiDBノードの計算リソースとメモリリソースを大量に消費しています。ユーザーの業務アプリケーションの実行中にオンラインでインデックスを追加するようなシナリオでは、クラスターに新しいTiDBノードを追加し、これらのノードに
tidb_service_scope変数を設定し、これらのノードに接続してタスクを作成することをお勧めします。これにより、分散フレームワークはこれらのノードにタスクをスケジュールし、他のTiDBノードからのワークロードを分離することで、ADD INDEXやIMPORT INTOなどのバックエンドタスクの実行がユーザーの業務アプリケーションに与える影響を軽減します。- グローバル ソート機能を使用する場合は、OOM を回避するために、少なくとも 16 コアの CPU と 32 GiB のメモリを備えた TiDB ノードを使用することをお勧めします。
注記:
この機能は、クラスターTiDB CloudスターターおよびTiDB Cloudエッセンシャルでは利用できません。
概要
TiDBのグローバルソート機能は、データインポートとDDL(データ定義言語)操作の安定性と効率性を向上させます。1 TiDB 分散実行フレームワーク (DXF)汎用演算子として機能し、クラウド上でグローバルソートサービスを提供します。
現在、グローバルソート機能は、クラウドstorageとして Amazon S3 の使用をサポートしています。
ユースケース
グローバルソート機能は、 IMPORT INTOとCREATE INDEXの安定性と効率性を向上させます。タスクによって処理されるデータをグローバルにソートすることで、TiKVへのデータ書き込みの安定性、制御性、スケーラビリティが向上します。これにより、データインポートやDDLタスクのユーザーエクスペリエンスが向上し、より高品質なサービスが提供されます。
グローバル ソート機能は、統合された DXF 内でタスクを実行し、グローバル スケールでのデータの効率的かつ並列的なソートを保証します。
制限事項
現在、グローバル ソート機能は、クエリ結果のソートを担当するクエリ実行プロセスのコンポーネントとして使用されていません。
使用法
グローバルソートを有効にするには、次の手順に従います。
DXFを有効にするには、値を
tidb_enable_dist_taskからONに設定します。v8.1.0以降では、この変数はデフォルトで有効になっています。v8.1.0以降のバージョンで新しく作成されたクラスターでは、この手順をスキップできます。SET GLOBAL tidb_enable_dist_task = ON;
tidb_cloud_storage_uri正しいクラウドstorageパスに設定します。3 例参照してください。SET GLOBAL tidb_cloud_storage_uri = 's3://my-bucket/test-data?role-arn=arn:aws:iam::888888888888:role/my-role'
注記:
IMPORT INTOについては、CLOUD_STORAGE_URIオプションを使用してクラウドstorageのパスを指定することもできます。tidb_cloud_storage_uriとCLOUD_STORAGE_URI両方に有効なクラウドstorageのパスが設定されている場合、CLOUD_STORAGE_URIの設定がIMPORT INTOに有効になります。
実施原則
グローバルソート機能のアルゴリズムは次のとおりです。
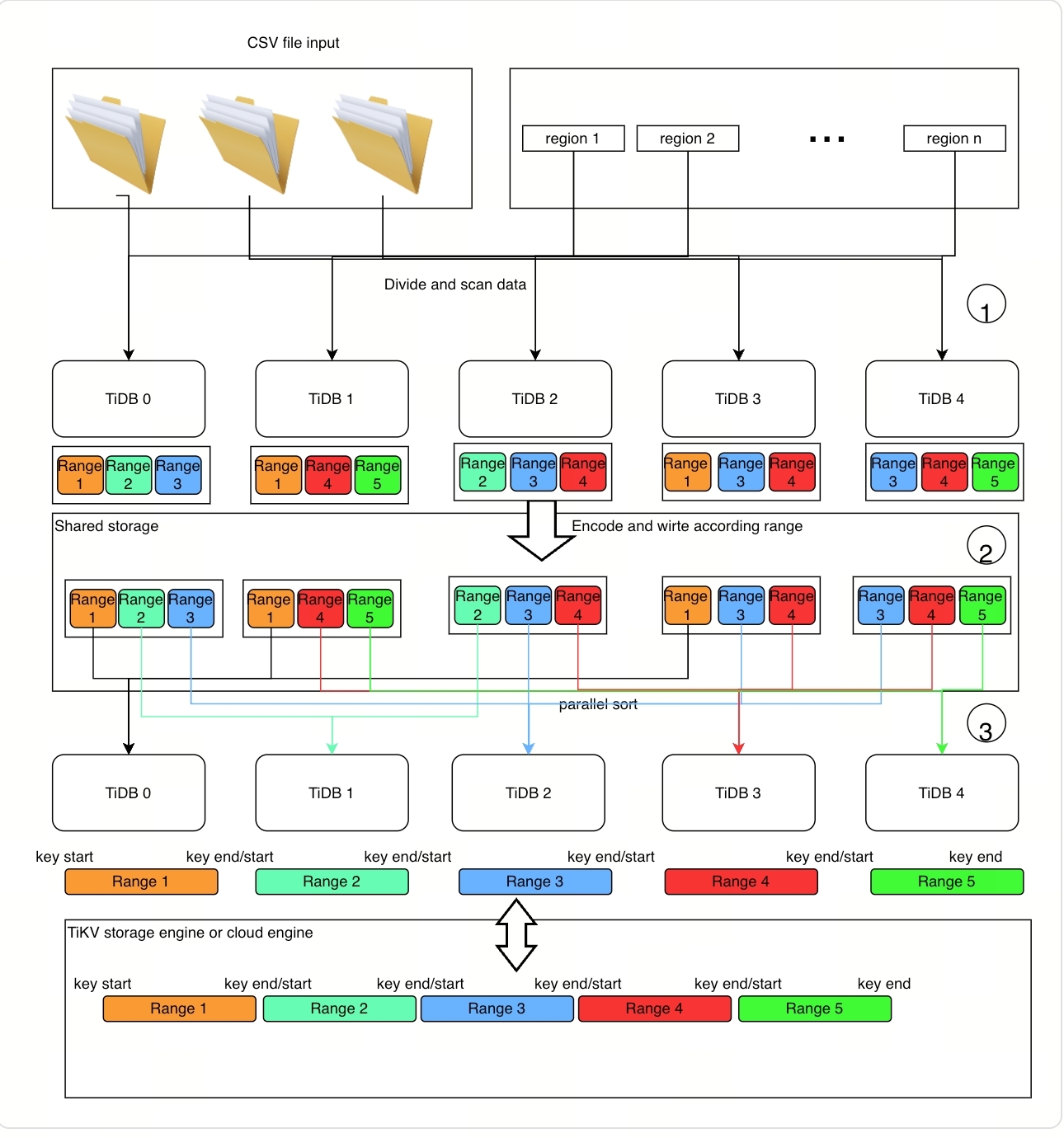
詳細な実装原則は次のとおりです。
ステップ1: データをスキャンして準備する
TiDB ノードが特定の範囲のデータをスキャンした後 (データ ソースは CSV データまたは TiKV のテーブル データのいずれかになります)。
- TiDB ノードはそれらをキーと値のペアにエンコードします。
- TiDB ノードは、キーと値のペアを複数のブロック データ セグメントに分類します (データ セグメントはローカルに分類されます)。各セグメントは 1 つのファイルであり、クラウドstorageにアップロードされます。
TiDBノードは、各セグメントの実際のキーと値の範囲(統計ファイルと呼ばれます)も連続して記録します。これは、スケーラブルなソート実装のための重要な準備です。これらのファイルは、実際のデータと共にクラウドstorageにアップロードされます。
ステップ2: データを分類して分配する
ステップ1では、グローバルソートプログラムはソート済みブロックのリストと対応する統計ファイルを取得します。これらの統計ファイルから、ローカルソート済みブロックの数が得られます。また、このプログラムはPDが分割と分散に使用できる実データスコープも備えています。以下の手順が実行されます。
- 統計ファイル内のレコードを並べ替えて、ほぼ均等なサイズの範囲に分割します。これは、並列で実行されるサブタスクです。
- サブタスクを TiDB ノードに分散して実行します。
- 各 TiDB ノードは、サブタスクのデータを範囲ごとに独立して分類し、重複することなく TiKV に取り込みます。