SQLチューニングの概要
このドキュメントでは、 TiDB CloudでSQLパフォーマンスをチューニングする方法を紹介します。最高のSQLパフォーマンスを得るには、以下の手順を実行してください。
- SQL パフォーマンスをチューニングします。クエリ ステートメントの分析、実行プランの最適化、フル テーブル スキャンの最適化など、SQL パフォーマンスを最適化する方法は多数あります。
- スキーマ設計を最適化します。ビジネスワークロードの種類によっては、トランザクションの競合やホットスポットを回避するためにスキーマを最適化する必要がある場合があります。
SQLパフォーマンスのチューニング
SQL ステートメントのパフォーマンスを向上させるには、次の原則を考慮してください。
- スキャンするデータの範囲を最小限に抑えます。常に、最小限の範囲のデータのみをスキャンし、すべてのデータをスキャンしないようにすることがベストプラクティスです。
- 適切なインデックスを使用してください。SQL文の
WHERE番目の句の各列には、対応するインデックスが設定されていることを確認してください。そうでないと、WHERE番目の句でテーブル全体がスキャンされ、パフォーマンスが低下します。 - 適切な結合タイプを使用してください。クエリ内の各テーブルのサイズと相関関係に応じて、適切な結合タイプを選択することが非常に重要です。通常、TiDBのコストベースオプティマイザは最適な結合タイプを自動的に選択します。ただし、場合によっては、結合タイプを手動で指定する必要があります。詳細については、 テーブル結合を使用する文を説明する参照してください。
- 適切なstorageエンジンを使用してください。ハイブリッドトランザクションおよび分析処理(HTAP)ワークロードには、 TiFlashstorageエンジンの使用をお勧めしますHTAPクエリ参照してください。
TiDB Cloudは、クラスター上のスロークエリの分析に役立つツールをいくつか提供しています。以下のセクションでは、スロークエリを最適化するためのいくつかのアプローチについて説明します。
診断ページのステートメントを使用する
TiDB Cloudコンソールの診断ページ目にタブSQL文があります。このタブでは、クラスター上のすべてのデータベースのSQL文の実行統計を収集します。これにより、合計または1回の実行で長時間かかるSQL文を特定し、分析することができます。
このページでは、同じ構造を持つSQLクエリ(クエリパラメータが一致していなくても)は、同じSQL文にグループ化されていることに注意してください。例えば、 SELECT * FROM employee WHERE id IN (1, 2, 3)とselect * from EMPLOYEE where ID in (4, 5)どちらも同じSQL文select * from employee where id in (...)の一部です。
SQL ステートメントでいくつかの重要な情報を表示できます。
SQL テンプレート: SQL ダイジェスト、SQL テンプレート ID、現在表示されている時間範囲、実行プランの数、実行が行われるデータベースが含まれます。
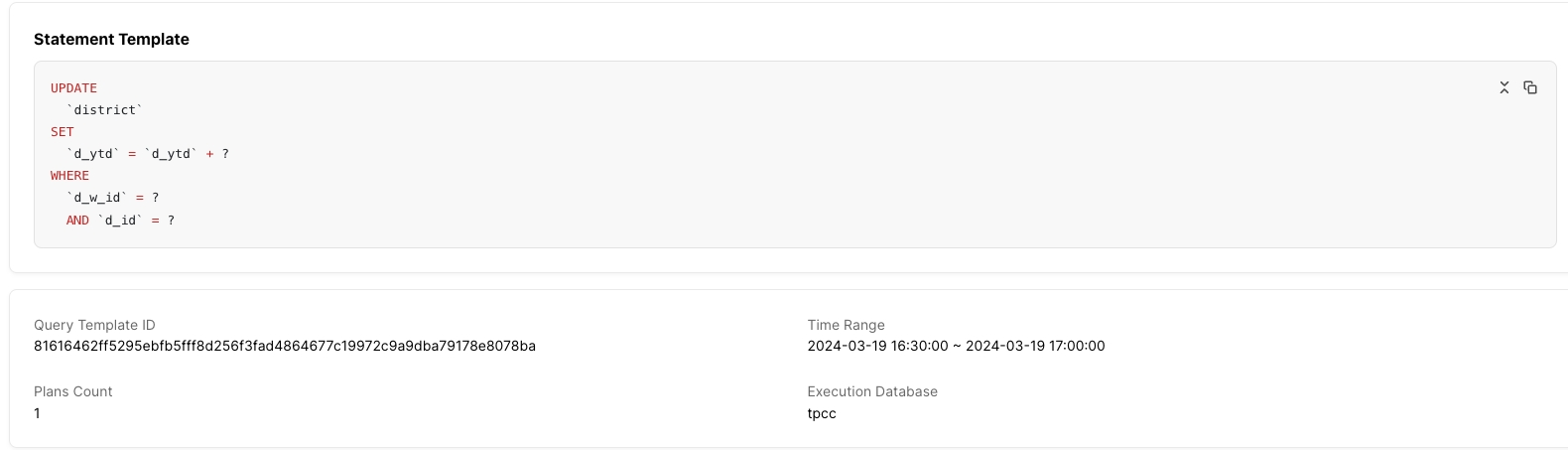
実行プランリスト: SQL文に複数の実行プランがある場合、リストが表示されます。複数の実行プランを選択すると、選択した実行プランの詳細がリストの下部に表示されます。実行プランが1つしかない場合、リストは表示されません。
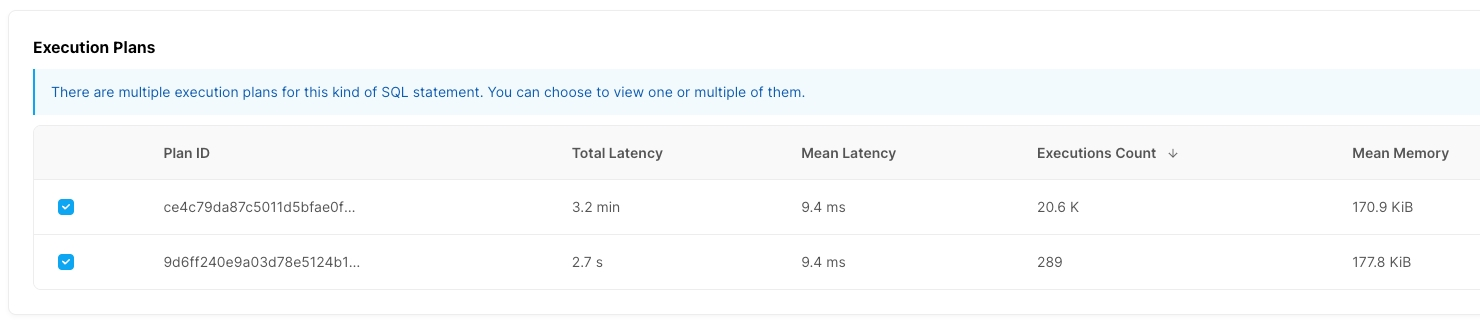
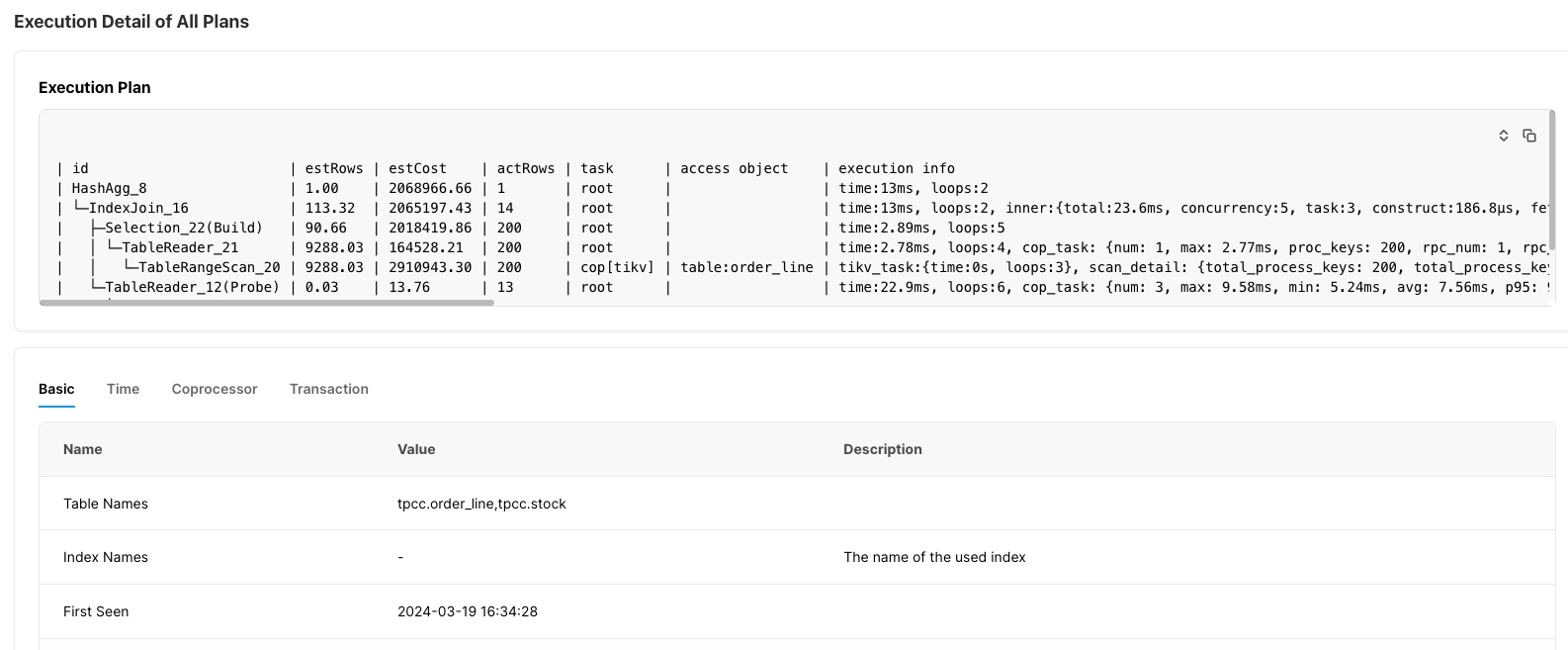
実行計画の詳細: 選択した実行計画の詳細を表示します。SQLの種類ごとの実行計画と、それに対応する実行時間を複数の観点から収集し、より詳細な情報を取得するのに役立ちます実行計画参照してください。
関連する遅いクエリ
ステートメントダッシュボードの情報に加えて、次のセクションで説明するように、 TiDB Cloudの SQL ベスト プラクティスもいくつかあります。
実行計画を確認する
EXPLAIN使用すると、コンパイル時に TiDB がステートメントに対して計算した実行プランを確認できます。つまり、TiDB は数百または数千の実行プランを推定し、消費リソースが最も少なく、実行速度が最も速い最適な実行プランを選択します。
TiDB によって選択された実行プランが最適でない場合は、 EXPLAINまたはEXPLAIN ANALYZE使用して診断できます。
実行計画を最適化する
TiDBは、元のクエリテキストをparserで解析し、基本的な妥当性を検証した後、まずクエリに論理的に同等な変更を加えます。詳細については、 SQL論理最適化参照してください。
これらの等価性の変更により、クエリは論理実行プランで処理しやすくなります。等価性の変更後、TiDBは元のクエリと等価なクエリプラン構造を取得し、その後、データ分布と演算子固有の実行オーバーヘッドに基づいて最終的な実行プランを取得します。詳細については、 SQL物理最適化参照してください。
また、TiDB では、 実行プランキャッシュの準備で紹介されているように、 PREPAREステートメントを実行するときに実行プランの作成オーバーヘッドを削減するために実行プラン キャッシュを有効にすることを選択できます。
全テーブルスキャンの最適化
SQLクエリが遅くなる最も一般的な原因は、 SELECTの文がフルテーブルスキャンを実行するか、不適切なインデックスを使用していることです。EXPLAINまたはEXPLAIN ANALYZEを使用すると、クエリの実行プランを表示し、実行速度が遅い原因を特定できます。最適化に使用できる方法は3つの方法あります。
- セカンダリインデックスを使用する
- カバーインデックスを使用する
- プライマリインデックスを使用する
DMLのベストプラクティス
主キーを選択する際のDDLのベストプラクティス
インデックスのベストプラクティス
インデックス作成のベストプラクティスインデックスの作成と使用に関するベスト プラクティスが含まれています。
デフォルトではインデックス作成の速度は控えめですが、シナリオによってはインデックス作成プロセスを変数の変更倍高速化できます。
スキーマ設計を最適化する
SQL パフォーマンス チューニングを行ってもパフォーマンスが向上しない場合は、トランザクションの競合やホットスポットを回避するために、スキーマ設計とデータ読み取りモデルを確認する必要がある可能性があります。
トランザクションの競合
トランザクションの競合を見つけて解決する方法の詳細については、 ロックの競合のトラブルシューティング参照してください。
ホットスポットの問題
キービジュアライザー使用してホットスポットの問題を分析できます。
Key Visualizer を使用すると、TiDB クラスタの使用パターンを分析し、トラフィックのホットスポットをトラブルシューティングできます。このページでは、TiDB クラスタのトラフィックの推移を時系列で視覚的に表示します。
Key Visualizerでは以下の情報を確認できます。まずは基本的な概念について理解しておく必要があるかもしれません。
- 全体的なトラフィックを時間の経過とともに表示する大きなヒートマップ
- ヒートマップの座標に関する詳細情報
- 左側に表示される表や索引などの識別情報
Key Visualizer には4つの一般的なヒートマップ結果あります。
- 均等に分散された作業負荷:望ましい結果
- X軸(時間)に沿って明暗が交互に変化:ピーク時にリソースをチェックする必要がある
- Y軸に沿って明暗が交互に変化:生成されたホットスポットの集約度合いを確認する必要がある
- 明るい斜線:ビジネスモデルを確認する必要がある
X 軸と Y 軸の明暗が交互に変わるどちらの場合も、読み取りおよび書き込みの圧力に対処する必要があります。
SQL パフォーマンスの最適化の詳細については、「SQL FAQ」のSQL最適化参照してください。