TiDB Self-ManagedからTiDB Cloudへの移行
このドキュメントでは、 DumplingとTiCDCを使用して、TiDB Self-ManagedクラスタからTiDB Cloud(AWS上)へデータを移行する方法について説明します。
全体の手順は以下のとおりです。
- 環境を構築し、ツールを準備する。
- 全データを移行します。手順は以下のとおりです。
- Dumplingを使用して、TiDB Self-ManagedからAmazon S3にデータをエクスポートします。
- Amazon S3 からTiDB Cloudへデータをインポートします。
- TiCDCを使用して増分データを複製します。
- 移行されたデータを確認してください。
前提条件
S3バケットとTiDB Cloudリソースは同じリージョンに配置することをお勧めします。リージョンをまたいでの移行には、データ変換のための追加コストが発生する可能性があります。
移行前に、以下のものを準備する必要があります。
- 管理者アクセス権を持つAWSアカウント
- AWS S3バケット
- TiDB Cloudアカウントには、AWSでホストされている対象のTiDB Cloudリソースへの
Project Data Access Read-Writeアクセス権が少なくとも必要です。
道具を準備する
以下の道具を準備する必要があります。
- Dumpling:データエクスポートツール
- TiCDC:データ複製ツール
Dumpling
Dumplingは、TiDBまたはMySQLからSQLファイルまたはCSVファイルにデータをエクスポートするツールです。Dumplingを使用すると、TiDB Self-Managedからすべてのデータをエクスポートできます。
Dumpling をデプロイする前に、以下の点にご注意ください。
- TiDB Cloudリソースと同じVPC内の新しいEC2インスタンスにDumplingをデプロイすることをお勧めします。
- 推奨されるEC2インスタンスタイプはc6g.4xlarge (16 vCPU、32 GiBメモリ)です。必要に応じて他のEC2インスタンスタイプを選択することもできます。Amazonマシンイメージ(AMI)は、Amazon Linux、Ubuntu、またはRed Hatから選択可能です。
TiUPを使用するか、インストールパッケージを使用することで、 Dumplingをデプロイできます。
TiUPを使用してDumplingをデプロイ
TiUPを使用してDumplingをデプロイします。
## Deploy TiUP
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
source /root/.bash_profile
## Deploy Dumpling and update to the latest version
tiup install dumpling
tiup update --self && tiup update dumpling
インストールパッケージを使用してDumplingをデプロイ
インストールパッケージを使用してDumplingをデプロイするには:
ツールキットパッケージをダウンロードします。
対象マシンに展開してください。TiUPを使用して
tiup install dumplingを実行すると、 Dumpling を入手できます。その後、tiup dumpling ...を使用してDumplingを実行できます。詳細については、 Dumplingの紹介を参照してください。 。
Dumplingの権限を設定する
上流データベースからデータをエクスポートするには、以下の権限が必要です。
- 選択
- リロード
- ロックテーブル
- レプリケーションクライアント
- プロセス
TiCDCをデプロイ
アップストリームの TiDB Self-Managed クラスターからダウンストリームのTiDB Cloudリソースに増分データをレプリケートするには、 TiCDCをデプロイする必要があります。
アップストリーム TiDB Self-Managedクラスターの現在の TiDB バージョンが TiCDC をサポートしているかどうかを確認します。 TiDB v4.0.8.rc.1 以降のバージョンは TiCDC をサポートします。 TiDB のバージョンを確認するには、上流の TiDB Self-Managedクラスターで
select tidb_version();を実行します。アップグレードする必要がある場合は、 TiUPを使用してTiDBをアップグレードするを参照してください。TiCDCコンポーネントをアップストリームの TiDB Self-Managedクラスターに追加します。 TiUPを使用して、既存のTiDBクラスタにTiCDCを追加またはスケールアウトしますを参照してください。
scale-out.ymlファイルを編集して TiCDC を追加します。cdc_servers: - host: 10.0.1.3 gc-ttl: 86400 data_dir: /tidb-data/cdc-8300 - host: 10.0.1.4 gc-ttl: 86400 data_dir: /tidb-data/cdc-8300TiCDCコンポーネントを追加し、ステータスを確認してください。
tiup cluster scale-out <cluster-name> scale-out.yml tiup cluster display <cluster-name>
全てのデータを移行する
TiDB Self-ManagedクラスタからTiDB Cloudへデータを移行するには、以下の手順で完全なデータ移行を実行します。
- TiDB Self-ManagedクラスターからAmazon S3へデータを移行します。
- Amazon S3からTiDB Cloudへデータを移行します。
TiDB Self-ManagedクラスターからAmazon S3へデータを移行する
TiDB Self-ManagedクラスターからAmazon S3へDumplingを使用してデータを移行する必要があります。
TiDB Self-ManagedクラスターがローカルIDCにある場合、またはDumplingサーバーとAmazon S3間のネットワークが接続されていない場合は、まずファイルをローカルストレージにエクスポートしてから、後でAmazon S3にアップロードすることができます。
ステップ1. アップストリームのTiDB Self-ManagedクラスタのGCメカニズムを一時的に無効にします。
増分移行中に新しく書き込まれたデータが失われないようにするには、移行を開始する前にアップストリームクラスタのガベージコレクション(GC)メカニズムを無効にして、システムが履歴データをクリーンアップしないようにする必要があります。
設定が成功したかどうかを確認するには、次のコマンドを実行してください。
SET GLOBAL tidb_gc_enable = FALSE;
以下は出力例です。 0は無効になっていることを示します。
SELECT @@global.tidb_gc_enable;
+-------------------------+
| @@global.tidb_gc_enable |
+-------------------------+
| 0 |
+-------------------------+
1 row in set (0.01 sec)
ステップ2. Dumpling用のAmazon S3バケットへのアクセス権限を設定します
AWS コンソールでアクセスキーを作成します。詳細についてはアクセスキーを作成するを参照してください。
AWSアカウントIDまたはアカウントエイリアス、 IAMユーザー名、およびパスワードを使用してIAMコンソールにサインインしてください。
右上にあるナビゲーションバーでユーザー名を選択し、 「マイセキュリティ認証情報」をクリックします。
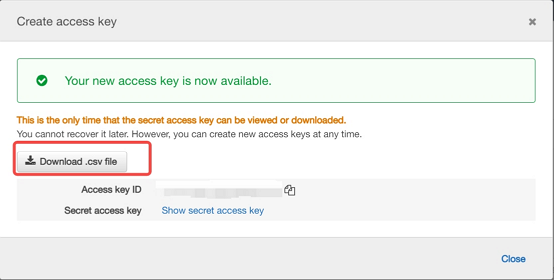
アクセスキーを作成するには、 「アクセスキーの作成」をクリックします。次に、 「.csv ファイルのダウンロード」を選択して、アクセスキー ID とシークレット アクセスキーをコンピュータの CSV ファイルに保存します。このファイルは安全な場所に保存してください。このダイアログボックスを閉じると、シークレット アクセスキーには再度アクセスできなくなります。CSV ファイルをダウンロードしたら、 「閉じる」を選択します。アクセスキーを作成すると、キー ペアはデフォルトで有効になり、すぐに使用できます。
ステップ3. Dumplingを使用して、上流のTiDBクラスターからAmazon S3にデータをエクスポートします。
Dumplingを使用して、アップストリームのTiDBクラスタからAmazon S3にデータをエクスポートするには、次の手順を実行します。
Dumplingの環境変数を設定します。
export AWS_ACCESS_KEY_ID=${AccessKey} export AWS_SECRET_ACCESS_KEY=${SecretKey}AWS コンソールから S3 バケット URI とリージョン情報を取得します。詳細についてはバケットを作成するを参照してください。
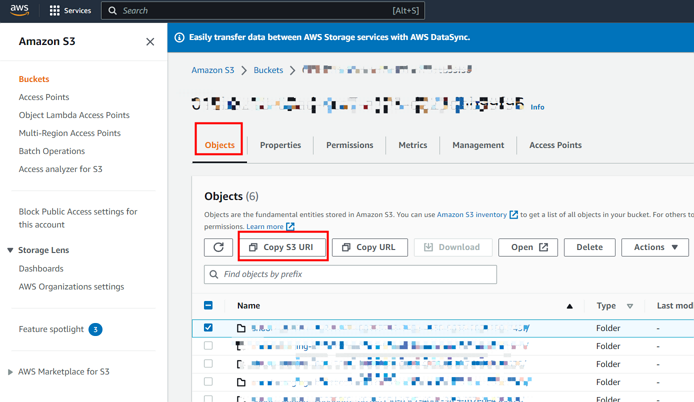
以下のスクリーンショットは、S3バケットURI情報を取得する方法を示しています。
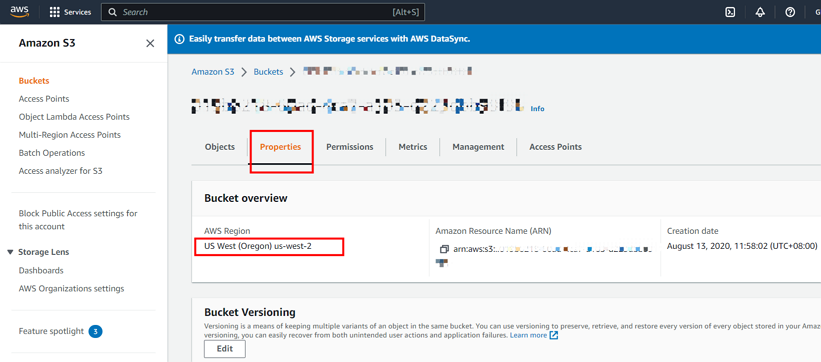
以下のスクリーンショットは、地域情報を取得する方法を示しています。
Dumplingを実行して、データをAmazon S3バケットにエクスポートします。
dumpling \ -u root \ -P 4000 \ -h 127.0.0.1 \ -r 20000 \ --filetype {sql|csv} \ -F 256MiB \ -t 8 \ -o "${S3 URI}" \ --s3.region "${s3.region}"-tオプションは、エクスポートに使用するスレッド数を指定します。スレッド数を増やすと、Dumplingの並列処理能力とエクスポート速度が向上しますが、データベースのメモリ使用量も増加します。そのため、このパラメータには大きすぎる値を設定しないでください。詳細については、 Dumplingを参照してください。
エクスポートデータを確認してください。通常、エクスポートデータには以下の内容が含まれます。
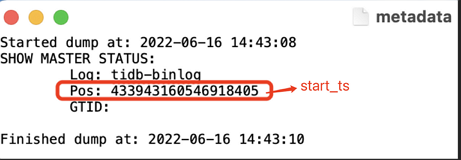
metadata: このファイルには、エクスポートの開始時刻とマスターバイナリログの場所が含まれています。{schema}-schema-create.sql: スキーマを作成するための SQL ファイル{schema}.{table}-schema.sql: テーブルを作成するための SQL ファイル{schema}.{table}.{0001}.{sql|csv}: データファイル*-schema-view.sql、*-schema-trigger.sql、*-schema-post.sql:その他のエクスポートされたSQLファイル
Amazon S3からTiDB Cloudへデータを移行する
TiDB Self-ManagedクラスターからAmazon S3にデータをエクスポートした後、データをTiDB Cloudに移行する必要があります。
TiDB Cloudコンソール以下のドキュメントに従って、対象のTiDBリソースのアカウントIDと外部IDを取得してください。
- TiDB Cloud Dedicatedクラスターについては、 ロールARNを使用してAmazon S3へのアクセスを設定するを参照してください。
- TiDB Cloud StarterまたはTiDB Cloud Essentialインスタンスについては、 ロールARNを使用してAmazon S3へのアクセスを設定するを参照してください。
Amazon S3 のアクセス権限を設定します。通常、以下の読み取り専用権限が必要です。
- s3:GetObject
- s3:GetObjectVersion
- s3:リストバケット
- s3:GetBucketLocation
S3バケットがサーバー側暗号化(SSE-KMS)を使用している場合は、KMS権限も追加する必要があります。
- kms:復号化
アクセスポリシーを設定します。 AWSコンソール > IAM > アクセス管理 > ポリシーしてリージョンに切り替えて、 TiDB Cloudのアクセス ポリシーが既に存在するかどうかを確認します。存在しない場合は、このドキュメントに従ってポリシーを作成します。 JSONタブでポリシーを作成する。
以下は、JSONポリシーのテンプレート例です。
## Create a json policy template ##<Your customized directory>: fill in the path to the folder in the S3 bucket where the data files to be imported are located. ##<Your S3 bucket ARN>: fill in the ARN of the S3 bucket. You can click the Copy ARN button on the S3 Bucket Overview page to get it. ##<Your AWS KMS ARN>: fill in the ARN for the S3 bucket KMS key. You can get it from S3 bucket > Properties > Default encryption > AWS KMS Key ARN. For more information, see https://docs.aws.amazon.com/AmazonS3/latest/userguide/viewing-bucket-key-settings.html { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::<Your customized directory>" }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": "<Your S3 bucket ARN>" } // If you have enabled SSE-KMS for the S3 bucket, you need to add the following permissions. { "Effect": "Allow", "Action": [ "kms:Decrypt" ], "Resource": "<Your AWS KMS ARN>" } , { "Effect": "Allow", "Action": "kms:Decrypt", "Resource": "<Your AWS KMS ARN>" } ] }ロールを設定します。 IAMロールの作成(コンソール)を参照してください。 「アカウント ID」フィールドに、ステップ 1 で書き留めたTiDB Cloudアカウント ID とTiDB Cloud外部 ID を入力します。
ロール ARN を取得します。 AWSコンソール > IAM > アクセス管理 > ロール。お住まいの地域に切り替えてください。作成したロールをクリックし、ARN をメモします。これは、データをTiDB Cloudにインポートするときに使用します。
TiDB Cloudにデータをインポートします。
- TiDB Cloud Dedicatedクラスターについては、クラウドストレージからTiDB Cloud DedicatedにCSVファイルをインポートする。
- TiDB Cloud StarterまたはTiDB Cloud Essentialインスタンスについては、 TiDB Cloud StarterまたはEssentialにクラウドストレージからCSVファイルをインポートする。
増分データを複製する
増分データを複製するには、次の手順を実行します。
増分データ移行の開始時刻を取得します。例えば、完全データ移行のメタデータファイルから取得できます。
TiCDCがTiDB Cloudに接続できるようにします。
TiDB Cloudコンソールで、私のTiDBページに移動し、ターゲット リソースの名前をクリックして、その概要ページに移動します。
左側のナビゲーションペインで、 [設定] > [ネットワーク]をクリックします。
TiDB Cloudのプランに応じて、TiCDCがTiDB Cloudに接続できるようにするために、以下のいずれかの操作を行ってください。
- TiDB Cloud StarterまたはEssentialの場合は、 「認可されたネットワーク」セクションで「ルールの追加」をクリックします。表示されたダイアログで、TiCDCコンポーネントのパブリック IP アドレスを使用するファイアウォール ルールを追加し、 [保存]をクリックします。詳細については、 パブリックエンドポイント向けにTiDB Cloud StarterまたはEssential Firewallルールを設定するを参照してください。
- TiDB Cloud Dedicatedの場合は、 「IP アドレスの追加」をクリックします。表示されたダイアログで、 [IP アドレスを使用する]を選択し、 [ **+]をクリックし、TiCDCコンポーネントのパブリック IP アドレスを[IP アドレス]フィールドに入力して、 [確認]**をクリックします。詳細については、 IPアクセスリストを設定するを参照してください。
下流のTiDB Cloudリソースの接続情報を取得します。
- TiDB Cloudコンソールで、私のTiDBページに移動し、ターゲットのTiDB Cloudリソースの名前をクリックして、その概要ページに移動します。
- 右上隅の「接続」をクリックしてください。
- 接続ダイアログで、 「接続タイプ」ドロップダウンリストから「パブリック」を選択し、 「接続先」ドロップダウンリストから「一般」を選択します。
- 接続情報から、 TiDB Cloudリソースのホスト IP アドレスとポートを取得できます。詳細については、 公共回線経由で接続するを参照してください。
増分レプリケーションタスクを作成して実行します。アップストリームクラスターで、以下を実行します。
tiup cdc cli changefeed create \ --pd=http://172.16.6.122:2379 \ --sink-uri="tidb://root:123456@172.16.6.125:4000" \ --changefeed-id="upstream-to-downstream" \ --start-ts="431434047157698561"--pd: アップストリームクラスタのPDアドレス。形式は[upstream_pd_ip]:[pd_port]です。--sink-uri: レプリケーション タスクのダウンストリーム アドレス。--sink-uriは、次の形式に従って構成します。現在、このスキームはmysql、tidb、kafka、s3、およびlocal。[scheme]://[userinfo@][host]:[port][/path]?[query_parameters]--changefeed-id: レプリケーションタスクのID。形式は、^[a-zA-Z0-9]+(-[a-zA-Z0-9]+)*$ の正規表現に一致する必要があります。このIDが指定されていない場合、TiCDCは自動的にUUID(バージョン4形式)をIDとして生成します。--start-ts: 変更フィードの開始TSOを指定します。TiCDCクラスタはこのTSOからデータの取得を開始します。デフォルト値は現在時刻です。
詳細については、 TiCDC ChangefeedsのCLIとコンフィグレーションパラメータを参照してください。
アップストリームクラスタでGCメカニズムを再度有効にします。増分レプリケーションでエラーや遅延が検出されない場合は、GCメカニズムを有効にして、アップストリームクラスタのガベージコレクションを再開します。
設定が正しく機能しているかどうかを確認するには、以下のコマンドを実行してください。
SET GLOBAL tidb_gc_enable = TRUE;以下は出力例です。
1は、GC が無効になっていることを示します。SELECT @@global.tidb_gc_enable; +-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 1 | +-------------------------+ 1 row in set (0.01 sec)増分レプリケーションタスクを確認します。
出力に「変更フィードの作成に成功しました!」というメッセージが表示された場合、レプリケーションタスクは正常に作成されています。
状態が
normalの場合、レプリケーションタスクは正常です。tiup cdc cli changefeed list --pd=http://172.16.6.122:2379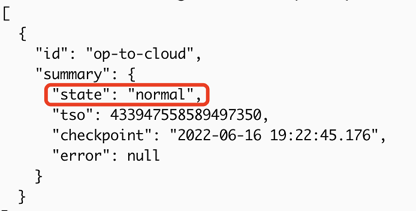
レプリケーションを確認します。アップストリームクラスタに新しいレコードを書き込み、そのレコードがダウンストリームのTiDB Cloudリソースにレプリケートされているかどうかを確認します。
アップストリームとダウンストリームで同じタイムゾーンを設定してください。デフォルトでは、 TiDB CloudはタイムゾーンをUTCに設定します。アップストリームとダウンストリームでタイムゾーンが異なる場合は、両方で同じタイムゾーンを設定する必要があります。
上流の TiDB Self-Managed クラスタで、次のコマンドを実行してタイムゾーンを確認します。
SELECT @@global.time_zone;ダウンストリームのTiDB Cloudリソースで、次のコマンドを実行してタイムゾーンを設定します。
SET GLOBAL time_zone = '+08:00';設定を確認するために、タイムゾーンを再度確認してください。
SELECT @@global.time_zone;
アップストリームの TiDB Self-Managed クラスターでクエリバインディングをバックアップし、ダウンストリームのTiDB Cloudリソースに復元します。クエリバインディングをバックアップするには、クエリバインディングの次のクエリを使用できます。
SELECT DISTINCT(CONCAT('CREATE GLOBAL BINDING FOR ', original_sql,' USING ', bind_sql,';')) FROM mysql.bind_info WHERE status='enabled';出力が得られない場合は、クエリバインディングがアップストリームクラスタで使用されていない可能性があります。この場合は、この手順をスキップできます。
クエリバインディングを取得したら、下流のTiDB Cloudリソースでそれらを実行して、クエリバインディングを復元します。
上流の TiDB Self-Managed クラスタでユーザー情報と権限情報をバックアップし、下流のTiDB Cloudリソースに復元します。ユーザー情報と権限情報のバックアップには、以下のスクリプトを使用できます。プレースホルダーを実際の値に置き換える必要があることに注意してください。
#!/bin/bash export MYSQL_HOST={tidb_op_host} export MYSQL_TCP_PORT={tidb_op_port} export MYSQL_USER=root export MYSQL_PWD={root_password} export MYSQL="mysql -u${MYSQL_USER} --default-character-set=utf8mb4" function backup_user_priv(){ ret=0 sql="SELECT CONCAT(user,':',host,':',authentication_string) FROM mysql.user WHERE user NOT IN ('root')" for usr in `$MYSQL -se "$sql"`;do u=`echo $usr | awk -F ":" '{print $1}'` h=`echo $usr | awk -F ":" '{print $2}'` p=`echo $usr | awk -F ":" '{print $3}'` echo "-- Grants for '${u}'@'${h}';" [[ ! -z "${p}" ]] && echo "CREATE USER IF NOT EXISTS '${u}'@'${h}' IDENTIFIED WITH 'mysql_native_password' AS '${p}' ;" $MYSQL -se "SHOW GRANTS FOR '${u}'@'${h}';" | sed 's/$/;/g' [ $? -ne 0 ] && ret=1 && break done return $ret } backup_user_privユーザー情報と権限情報を取得したら、生成されたSQLステートメントを下流のTiDB Cloudリソースで実行して、ユーザー情報と権限情報を復元します。