クラウドストレージへのシンク
このドキュメントでは、TiDB Cloudからクラウドストレージへデータをストリーミングするためのチェンジフィードの作成方法について説明します。現在、Amazon S3、Google Cloud Storage(GCS)、およびAzure Blob Storageがサポートされています。
注記:
- データをクラウドストレージにストリーミングするには、TiDB クラスターのバージョンが v7.1.1 以降であることを確認してください。 TiDB Cloud Dedicatedクラスターを v7.1.1 以降にアップグレードするには、 TiDB Cloudサポートにお問い合わせください。
- TiDB Cloud Starterインスタンスでは、変更フィード機能は利用できません。
- TiDB Cloud Essentialインスタンスの場合、変更フィード機能はベータ版です。詳細については、 変更フィード(ベータ版)を参照してください。
制限
- TiDB Cloud Dedicatedクラスターごとに、最大 100 個のチェンジフィードを作成できます。
- TiDB Cloud はTiCDC を使用して変更フィードを確立するため、同じTiCDCの制限があります。
- 複製対象のテーブルに主キーまたはNULLを許容しない一意インデックスがない場合、複製中に一意制約が存在しないことで、一部の再試行シナリオにおいて、下流で重複データが挿入される可能性があります。
ステップ1. 宛先を設定する
対象のTiDB Cloud Dedicatedクラスターの概要ページに移動します。左側のナビゲーション ペインで[データ] > [変更フィード] をクリックし、 [変更フィードの作成]をクリックして[宛先]ページに移動します。次に、 TiDB Cloud Dedicatedクラスターがホストされているクラウド プロバイダーに応じて、宛先としてAmazon S3 、 GCS 、またはAzure Blob Storage を選択します。構成プロセスは、選択した宛先によって異なります。
Amazon S3の認証には、 AWS ロール ARNまたはAWS アクセス キーのいずれかを使用できます。セキュリティの強化と管理の容易化のため、 AWS ロール ARN の使用をお勧めします。
オプション1:AWSロールARN(推奨)
認証にIAMロールを使用するには、以下の手順に従ってください。
Amazon S3 の宛先ページで、 S3 URIを入力します。S3 バケットが TiDB クラスターと同じ AWS リージョンにあることを確認してください。
バケットアクセスで、 AWSロールARNを選択します。
新しいロールARNを作成するには、こちらをクリックしてAWS CloudFormationで新しいロールARNを作成してください。このテンプレートは必要な権限を自動的に構成します。
ロールを手動で作成する場合は、 「ロールARNを手動で作成」をクリックして、 TiDB Cloudアカウント情報と必要なポリシーを確認してください。
IAMロールに、対象バケットに対する少なくとも以下の権限が付与されていることを確認してください。
s3:ListBuckets3:PutObjects3:GetObjects3:DeleteObject
生成されたロールARNを対応するフィールドに貼り付けてください。
オプション2:AWSアクセスキー
注記:
アクセスキーとシークレットキー(AK/SK)を使用する場合、認証情報の管理とローテーションを手動で行う必要があり、セキュリティリスクが高まります。より強力なセキュリティを確保するには、代わりにAWSロールARNを使用することをお勧めします。
アクセスキーを使用して認証を行うには、以下の手順に従ってください。
Amazon S3 の宛先ページで、 S3 URIを入力します。S3 バケットが TiDB クラスターと同じ AWS リージョンにあることを確認してください。
「バケットアクセス」で「AWSアクセスキー」を選択します。
以下の項目を入力してください。
- アクセスキーID
- 秘密アクセスキー
GCSの場合、 GCSエンドポイントを入力する前に、まずGCSバケットへのアクセス権を付与する必要があります。以下の手順に従ってください。
TiDB Cloudコンソールで、サービスアカウントIDを記録してください。このIDは、 TiDB CloudにGCSバケットへのアクセス権を付与するために使用されます。
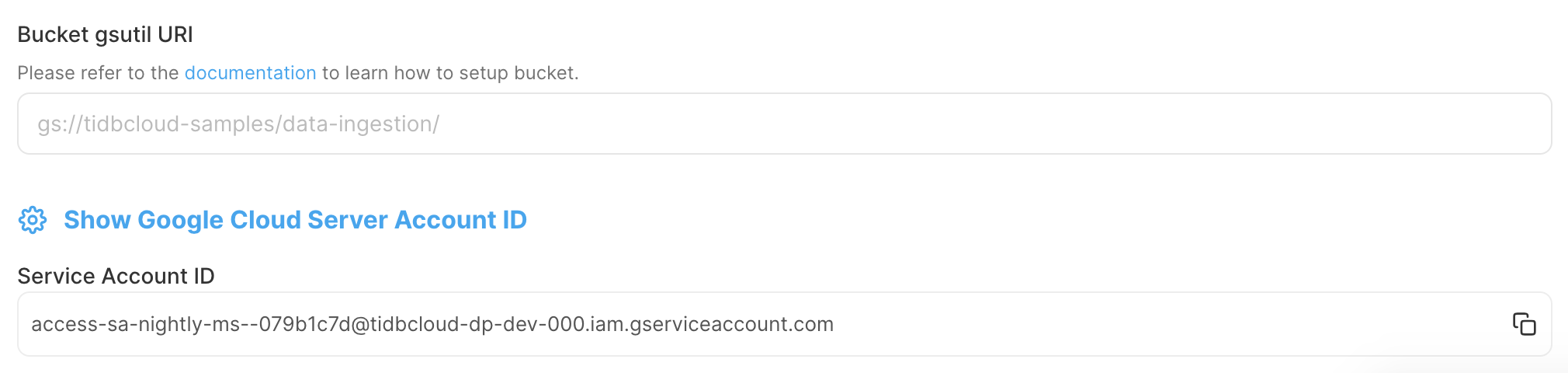
Google Cloud コンソールで、GCS バケット用のIAMロールを作成します。
Google Cloud Consoleにサインインしてください。
に移動して、 役割の作成]をクリックします。
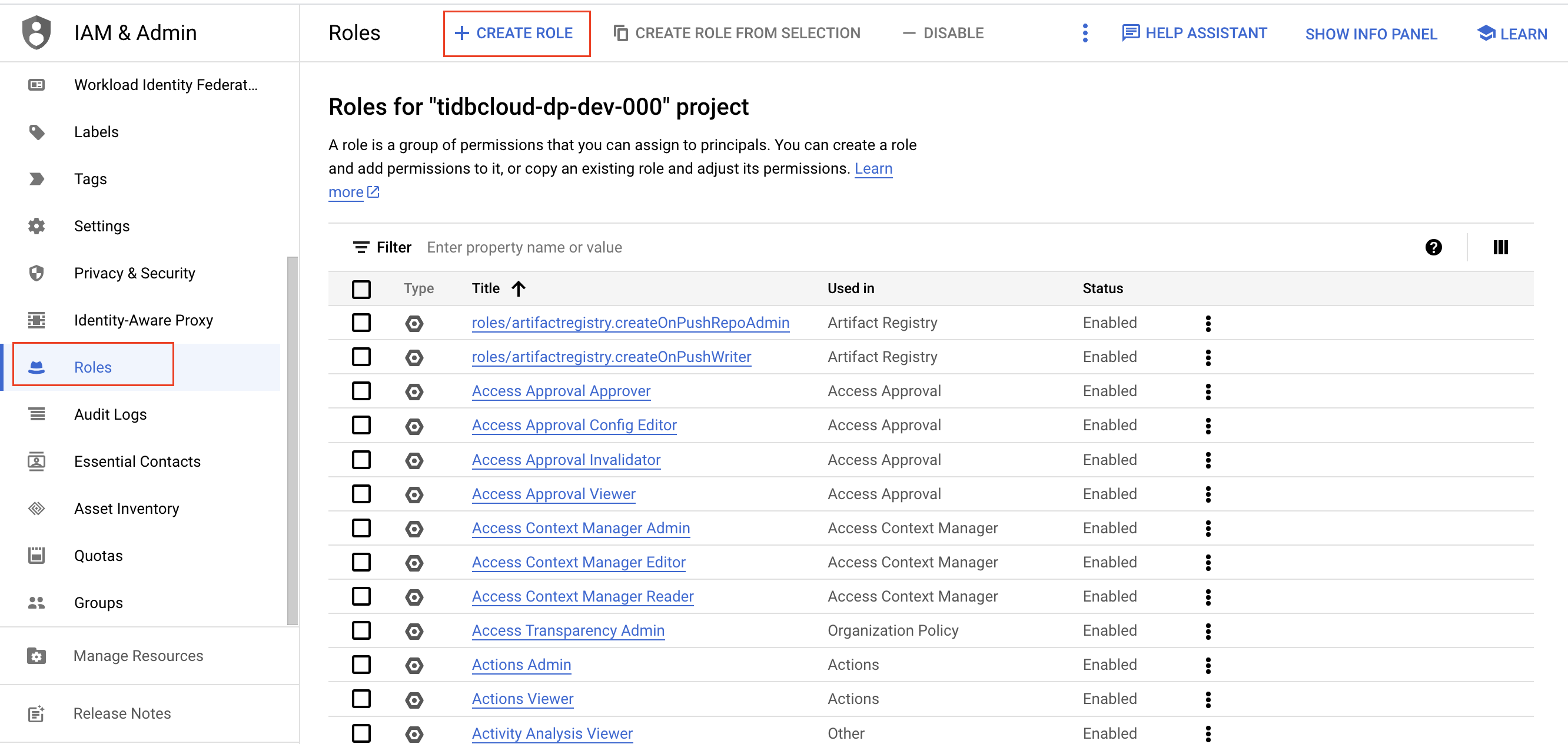
役割の名前、説明、ID、および役割の起動ステージを入力してください。役割名は、作成後に変更することはできません。
「権限の追加」をクリックします。役割に以下の権限を追加し、 「追加」をクリックします。
- storage.buckets.get
- storage.オブジェクト.作成
- storage.オブジェクト.削除
- storage.get
- storage.オブジェクトリスト
- storage.オブジェクト.更新
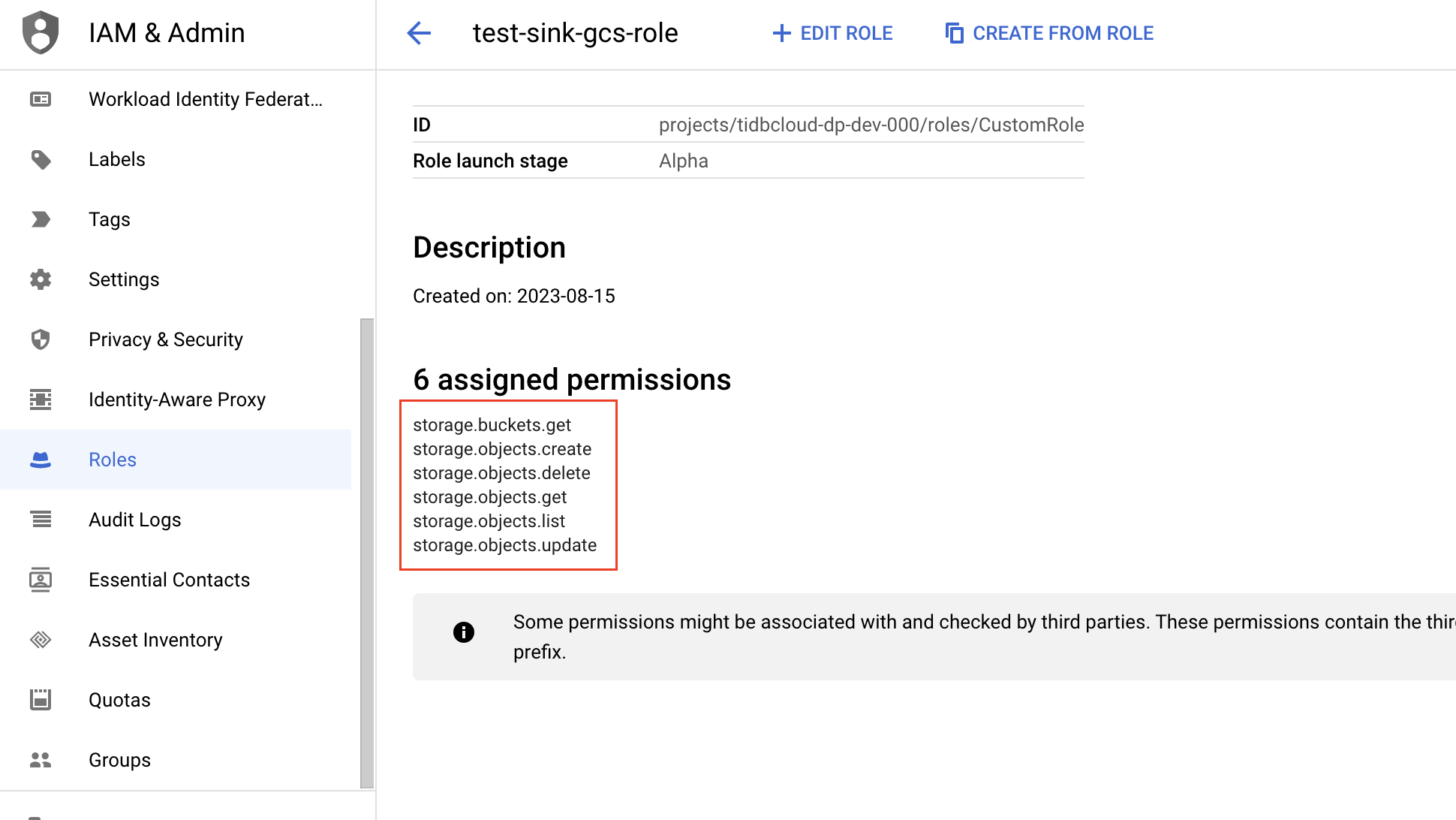
バケツページに移動し、 TiDB CloudがアクセスするGCSバケットを選択してください。GCSバケットは、TiDBクラスタと同じリージョンにある必要があります。
バケットの詳細ページで、 [権限]タブをクリックし、 [アクセスを許可]をクリックします。
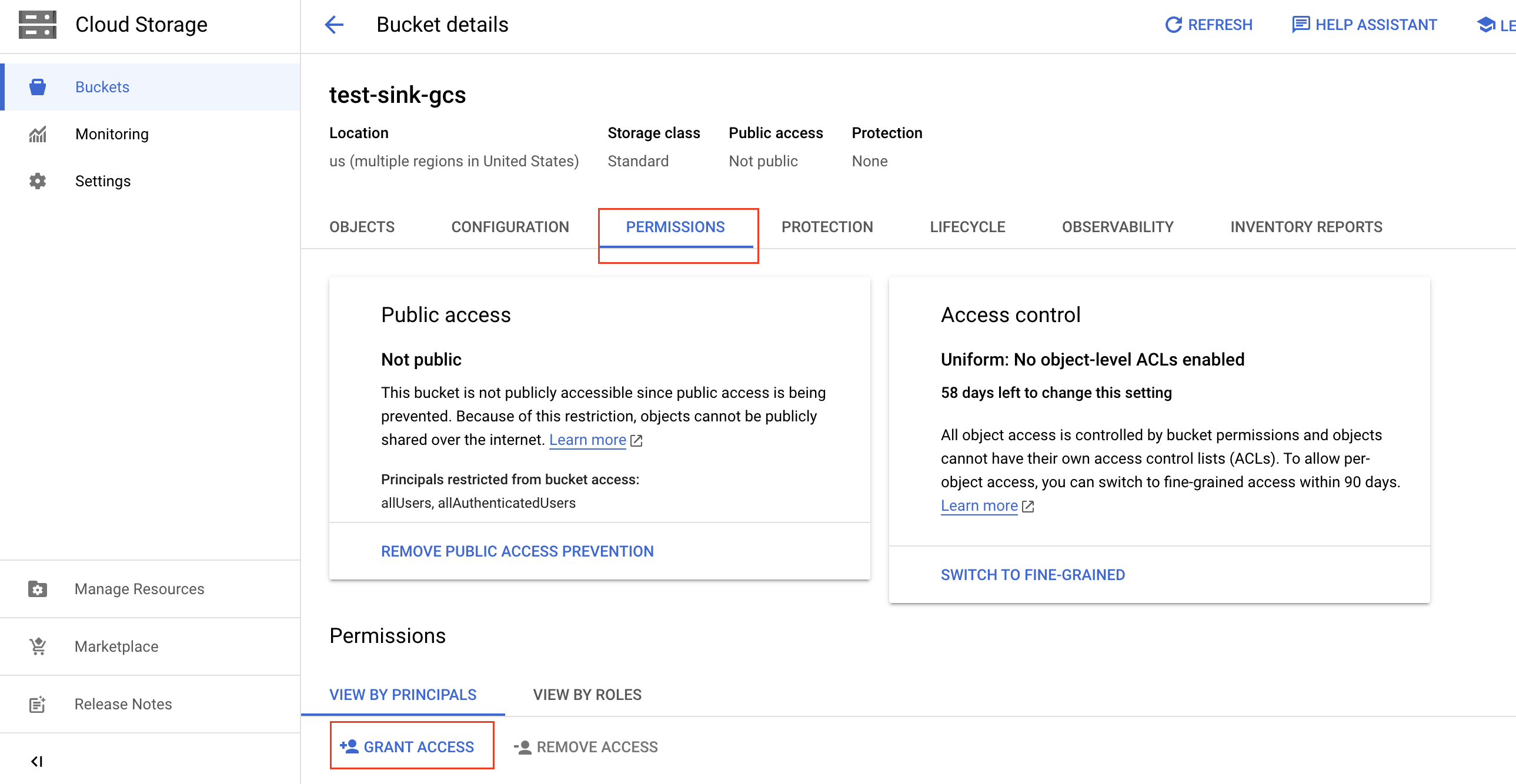
バケットへのアクセスを許可するには、以下の情報を入力し、 「保存」をクリックしてください。
「新しいプリンシパル」フィールドに、以前に記録した対象のTiDBクラスタのサービスアカウントIDを貼り付けます。
「役割を選択」ドロップダウンリストに、先ほど作成したIAMロールの名前を入力し、フィルター結果からその名前を選択します。
注記:
TiDB Cloudへのアクセス権を削除するには、付与したアクセス権を削除するだけです。
バケットの詳細ページで、「オブジェクト」タブをクリックします。
バケットの gsutil URI を取得するには、[コピー] ボタンをクリックし、プレフィックスとして
gs://を追加します。たとえば、バケット名がtest-sink-gcsの場合、URI はgs://test-sink-gcs/になります。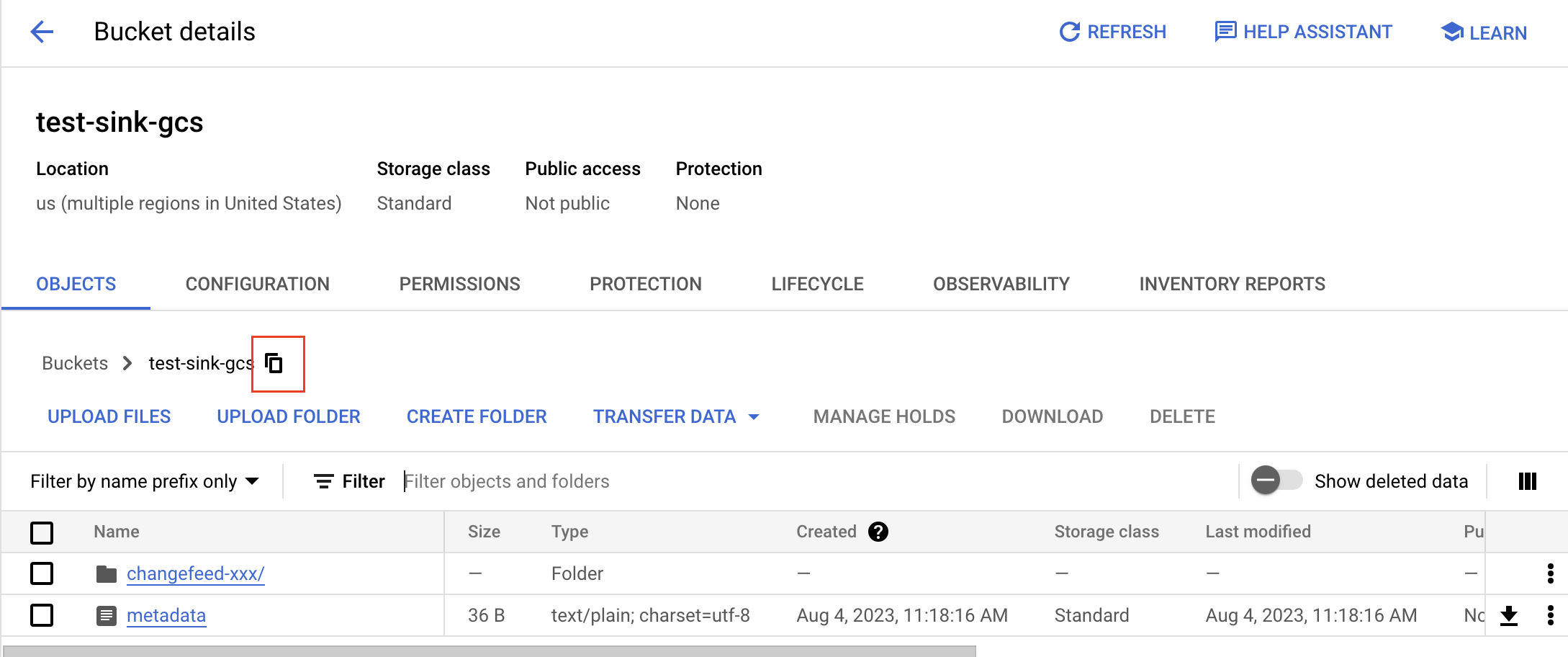
フォルダの gsutil URI を取得するには、フォルダを開き、[コピー] ボタンをクリックし、プレフィックスとして
gs://を追加します。たとえば、バケット名がtest-sink-gcsで、フォルダ名がchangefeed-xxxの場合、URI はgs://test-sink-gcs/changefeed-xxx/になります。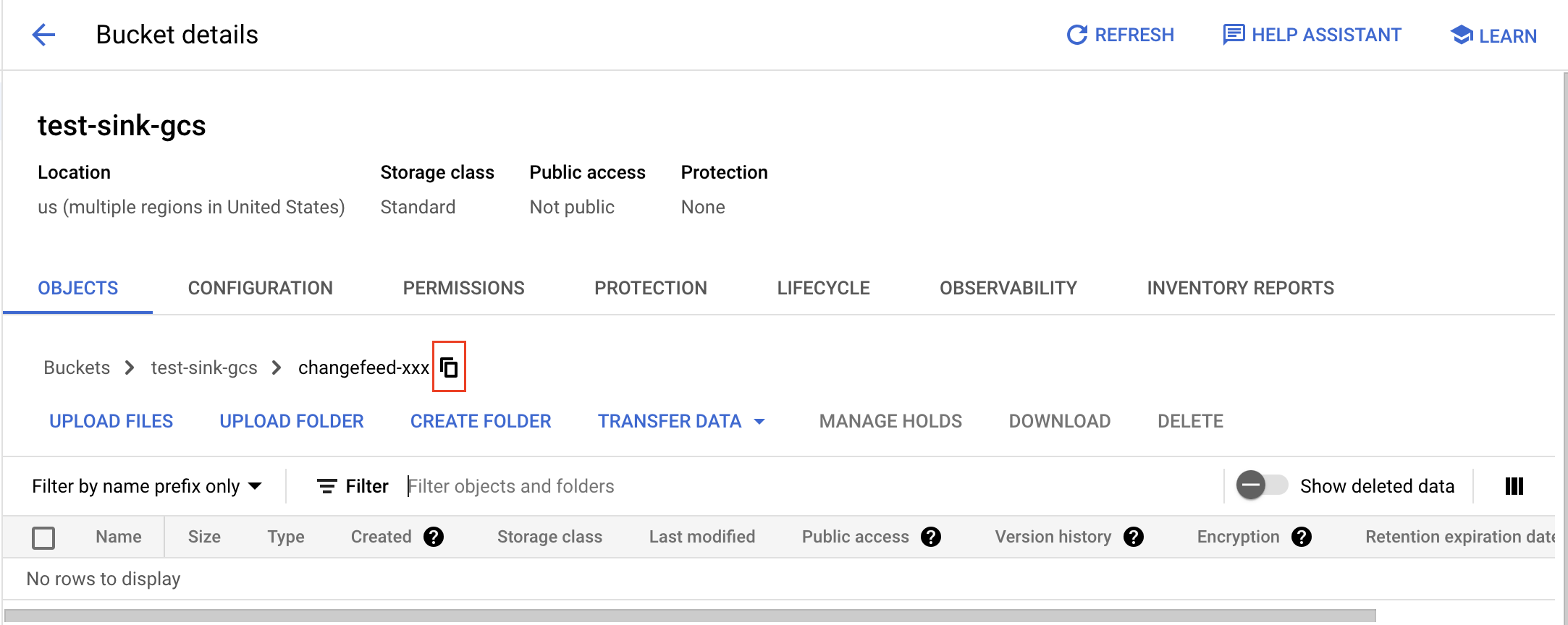
TiDB Cloudコンソールで、Changefeedの宛先ページに移動し、バケットgsutil URIフィールドに入力します。
Azure Blob Storageの場合、まず Azure ポータルでコンテナーを構成し、SAS トークンを取得する必要があります。以下の手順に従ってください。
Azureポータルで、変更フィード データを保存するコンテナーを作成します。
- 左側のナビゲーションペインで「ストレージアカウント」をクリックし、ストレージアカウントを選択します。
- ストレージアカウントのナビゲーションメニューで、 [データストレージ] > [コンテナー]を選択し、 [+コンテナー]をクリックします。
- 新しいコンテナの名前を入力し、匿名アクセスレベルを設定します(推奨レベルはプライベートです)。次に、 [作成]をクリックします。
対象コンテナのURLを取得します。
- コンテナ一覧から、対象のコンテナを選択してください。
- コンテナの「…」をクリックし、次に「コンテナのプロパティ」を選択します。
- URL値を後で使用するために保存します。たとえば
https://<storage_account>.blob.core.windows.net/<container>のように保存します。
SASトークンを生成します。
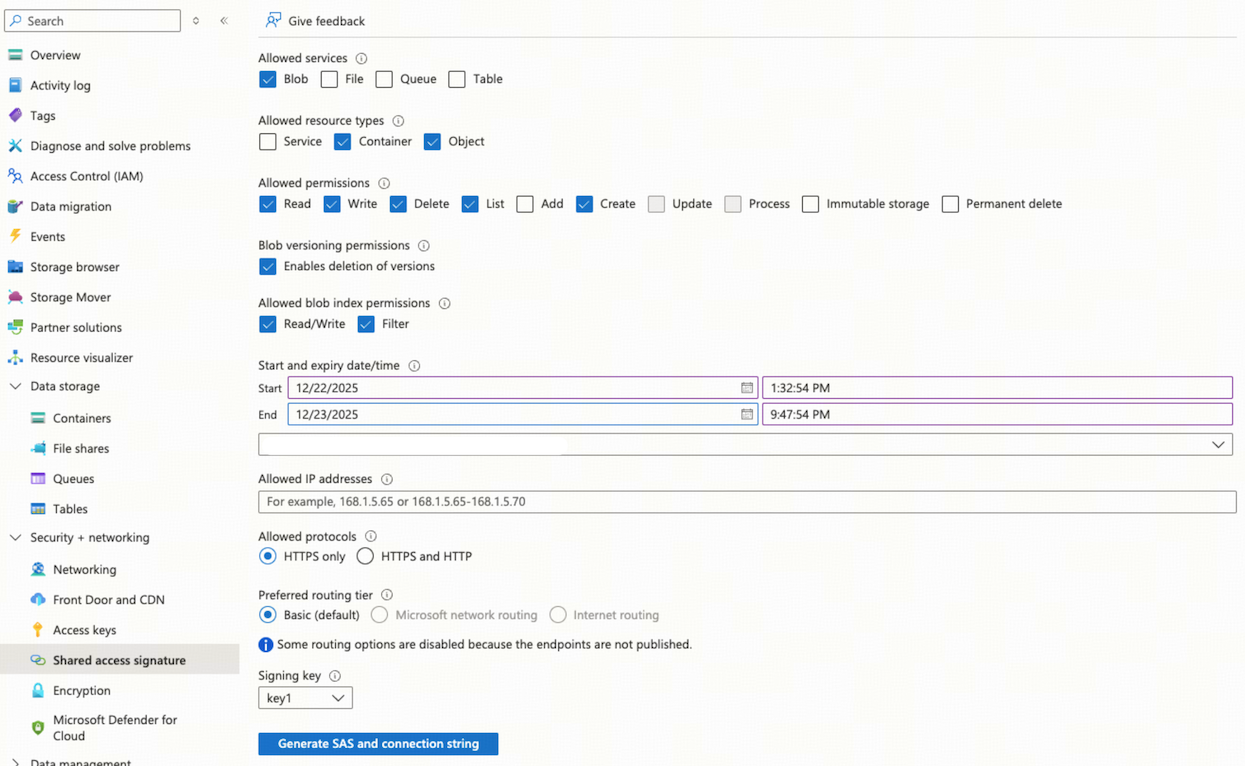
ストレージアカウントのナビゲーション メニューで、 [セキュリティ+ ネットワーク] > [共有アクセス 署名]を選択します。
「許可されたサービス」セクションで、 「Blob」を選択します。
「許可されたリソースの種類」セクションで、 「コンテナ」と「オブジェクト」を選択します。
「許可されたアクセス許可」セクションで、 「読み取り」 、 「書き込み」 、 「削除」 、 「一覧表示」 、 「作成」を選択します。
SASトークンの有効期間を、ニーズを満たすのに十分な長さに指定してください。
注記:
- 変更フィードは継続的にイベントを書き込むため、SASトークンの有効期間が十分に長いことを確認してください。セキュリティ上の理由から、トークンは6~12ヶ月ごとに交換することをお勧めします。
- 生成されたSASトークンは取り消すことができないため、有効期間を慎重に設定してください。
- 継続的な可用性を確保するため、SASトークンの有効期限が切れる前に再生成および更新してください。
「SASと接続文字列を生成」をクリックし、 SASトークンを保存します。
TiDB Cloudコンソールで、Changefeed の宛先ページに移動し、次のフィールドに入力します。
- Blob URL :手順2で取得したコンテナURLを入力してください。必要に応じてプレフィックスを追加できます。
- SASトークン:ステップ3で取得した生成済みのSASトークンを入力してください。
「次へ」をクリックして、 TiDB Cloud DedicatedクラスターからAmazon S3、GCS、またはAzure Blob Storageへの接続を確立します。TiDB Cloudは接続が成功したかどうかを自動的にテストおよび検証します。
- はいの場合、次の設定手順に進みます。
- そうでない場合は、接続エラーが表示されますので、エラーを処理してください。エラーが解決したら、 「次へ」をクリックして接続を再試行してください。
ステップ2. レプリケーションの設定
テーブル フィルターをカスタマイズして、複製するテーブルをフィルターします。ルールの構文については、 テーブルフィルタルールを参照してください。
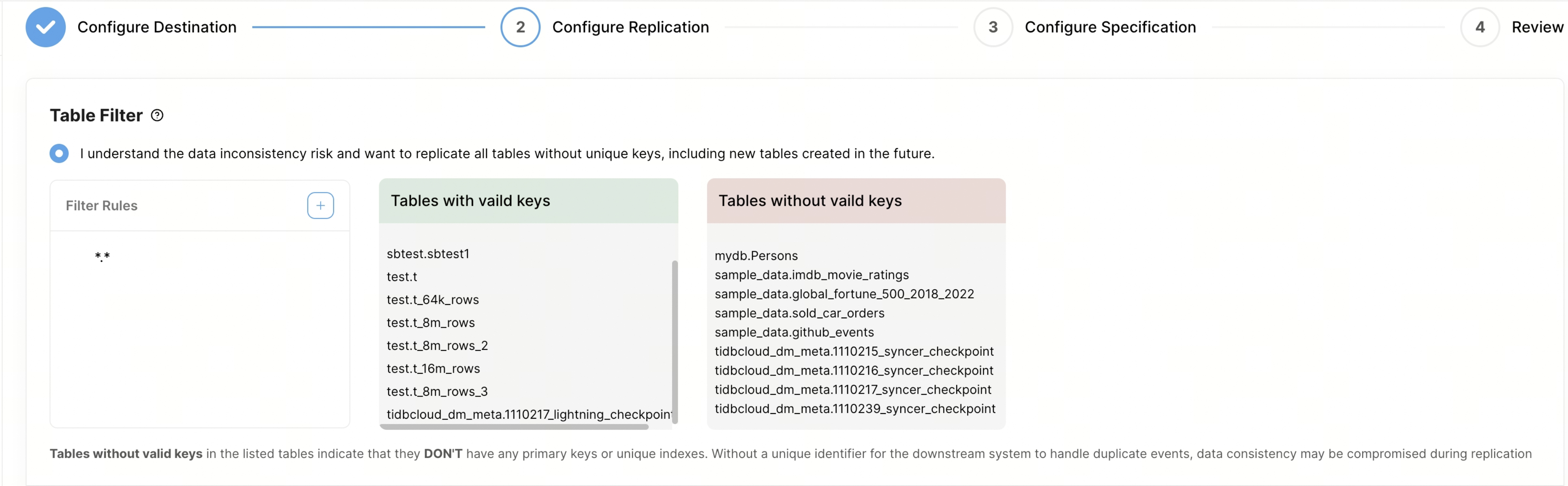
- 大文字小文字の区別:フィルタルールにおけるデータベース名とテーブル名の照合において、大文字小文字を区別するかどうかを設定できます。デフォルトでは、大文字小文字は区別されません。
- フィルタルール:この列でフィルタルールを設定できます。デフォルトでは、すべてのテーブルを複製するルール
*.*が設定されています。新しいルールを追加すると、 TiDB Cloud はTiDB 内のすべてのテーブルをクエリし、右側のボックスにルールに一致するテーブルのみを表示します。フィルタルールは最大 100 個まで追加できます。 - 有効なキーを持つテーブル:この列には、主キーや一意インデックスなど、有効なキーを持つテーブルが表示されます。
- 有効なキーのないテーブル: この列には、主キーまたは一意キーがないテーブルが表示されます。一意の識別子がないと、下流で重複イベントを処理する際にデータの一貫性が失われる可能性があるため、これらのテーブルはレプリケーション中に問題となります。データの一貫性を確保するには、レプリケーションを開始する前に、これらのテーブルに一意キーまたは主キーを追加することをお勧めします。または、フィルタルールを使用してこれらのテーブルを除外することもできます。たとえば、ルール
test.tbl1を使用して、テーブル"!test.tbl1"。
イベントフィルターをカスタマイズして、複製したいイベントを絞り込みます。
- 一致するテーブル:この列では、イベントフィルターを適用するテーブルを設定できます。ルールの構文は、前のテーブルフィルター領域で使用されているものと同じです。変更フィードごとに最大10個のイベントフィルタールールを追加できます。
- イベントフィルター:以下のイベントフィルターを使用して、変更フィードから特定のイベントを除外できます。
- イベントを無視する:指定されたイベントタイプを除外します。
- SQL を無視: 指定された式に一致する DDL イベントを除外します。たとえば、
^dropDROPで始まるステートメントを除外し、add columnはADD COLUMNを含むステートメントを除外します。 - 挿入値の式を無視する: 特定の条件を満たす
INSERTステートメントを除外します。たとえば、id >= 100は、INSERTが 100 以上であるidステートメントを除外します。 - 新しい値の更新式を無視する: 新しい値が指定された条件に一致する
UPDATEステートメントを除外します。たとえば、gender = 'male'はgenderがmaleになるような更新を除外します。 - 古い値の更新を無視する式: 古い値が指定された条件に一致する
UPDATEステートメントを除外します。たとえば、age < 18ageの古い値が 18 未満である場合の更新を除外します。 - 削除値式を無視する: 指定された条件を満たす
DELETEステートメントを除外します。たとえば、name = 'john'はDELETEがnameである'john'ステートメントを除外します。
「レプリケーション開始位置」領域で、以下のいずれかのレプリケーション位置を選択します。
- 今からレプリケーションを開始します
- 特定のTSOからレプリケーションを開始する
- 特定の時間からレプリケーションを開始する
データ形式の領域で、 CSV形式またはCanal-JSON形式のいずれかを選択してください。
CSV形式を設定するには、以下の項目を入力してください。
- バイナリエンコード方式:バイナリデータのエンコード方式。base64(デフォルト)またはhexを**選択できます。AWS DMSと連携する場合は、 hexを**使用してください。
- 日付区切り文字:年、月、日に基づいてデータをローテーションするか、ローテーションしないかを選択します。
- 区切り文字:CSVファイル内の値を区切る文字を指定します。最も一般的に使用される区切り文字はカンマ(
,)です。 - 引用符:区切り文字または特殊文字を含む値を囲むために使用する文字を指定します。通常、引用符には二重引用符(
")が使用されます。 - null/空値:CSVファイル内でnull値または空値がどのように表現されるかを指定します。これは、データの適切な処理と解釈のために重要です。
- コミットTを含める:CSV行に
commit-tsを含めるかどうかを制御します。
Canal-JSONは、プレーンなJSONテキスト形式です。設定するには、以下のフィールドに入力してください。
- 日付区切り文字:年、月、日に基づいてデータをローテーションするか、ローテーションしないかを選択します。
- TiDB 拡張機能を有効にする: このオプションを有効にすると、TiCDC はウォーターマークイベントを送信し、 TiDB拡張フィールドCanal-JSON メッセージに追加します。
フラッシュパラメータ領域では、次の2つの項目を設定できます。
- 洗浄間隔:デフォルトでは60秒に設定されていますが、2秒から10分の範囲で調整可能です。
- ファイルサイズ:デフォルトでは64MBに設定されていますが、1MBから512MBの範囲で調整可能です。

注記:
これら2つのパラメータは、各データベーステーブルごとにクラウドストレージに生成されるオブジェクトの数に影響します。テーブル数が多い場合、同じ設定を使用すると生成されるオブジェクトの数が増加し、結果としてクラウドストレージAPIの呼び出しコストが上昇します。そのため、リカバリポイント目標(RPO)とコスト要件に基づいて、これらのパラメータを適切に設定することをお勧めします。
[イベントの分割]エリアで、
UPDATEイベントを別々のDELETEとINSERTイベントに分割するか、生のUPDATEイベントとして保持するかを選択します。詳細については、 MySQL以外のシンクにおける、主キーまたは一意キーを分割したUPDATEイベント参照してください。
ステップ3.仕様の設定
「次へ」をクリックして、変更フィードの仕様を設定してください。
- 変更フィード仕様領域で、変更フィードで使用するレプリケーション容量ユニット(RCU)の数を指定します。
- 変更フィード名欄に、変更フィードの名前を指定します。
ステップ4.構成を確認し、レプリケーションを開始する
「次へ」をクリックして、変更フィードの設定を確認してください。
- すべての設定が正しいことを確認したら、 「作成」をクリックして変更フィードの作成に進んでください。
- 設定を変更する必要がある場合は、 「前へ」をクリックして戻り、必要な変更を行ってください。
シンクはまもなく起動し、シンクの状態が「作成中」から「実行中」に変わるのが確認できます。
変更フィードの名前をクリックすると、その詳細ページに移動します。このページでは、チェックポイントの状態、レプリケーションのレイテンシー、その他の関連メトリックなど、変更フィードに関する詳細情報を確認できます。