TiFlashの概要
TiFlashは、TiDB を本質的にハイブリッド トランザクション/分析処理 (HTAP) データベースにする重要なコンポーネントです。 TiFlash は、TiKV のカラムナ型storage拡張機能として、優れた分離レベルと強力な一貫性保証の両方を提供します。
TiFlashでは、柱状レプリカはRaft Learnerコンセンサス アルゴリズムに従って非同期的に複製されます。これらのレプリカが読み取られるとき、 Raftインデックスとマルチバージョン同時実行制御 (MVCC) を検証することによって、スナップショット分離レベルの一貫性が実現されます。
アーキテクチャ
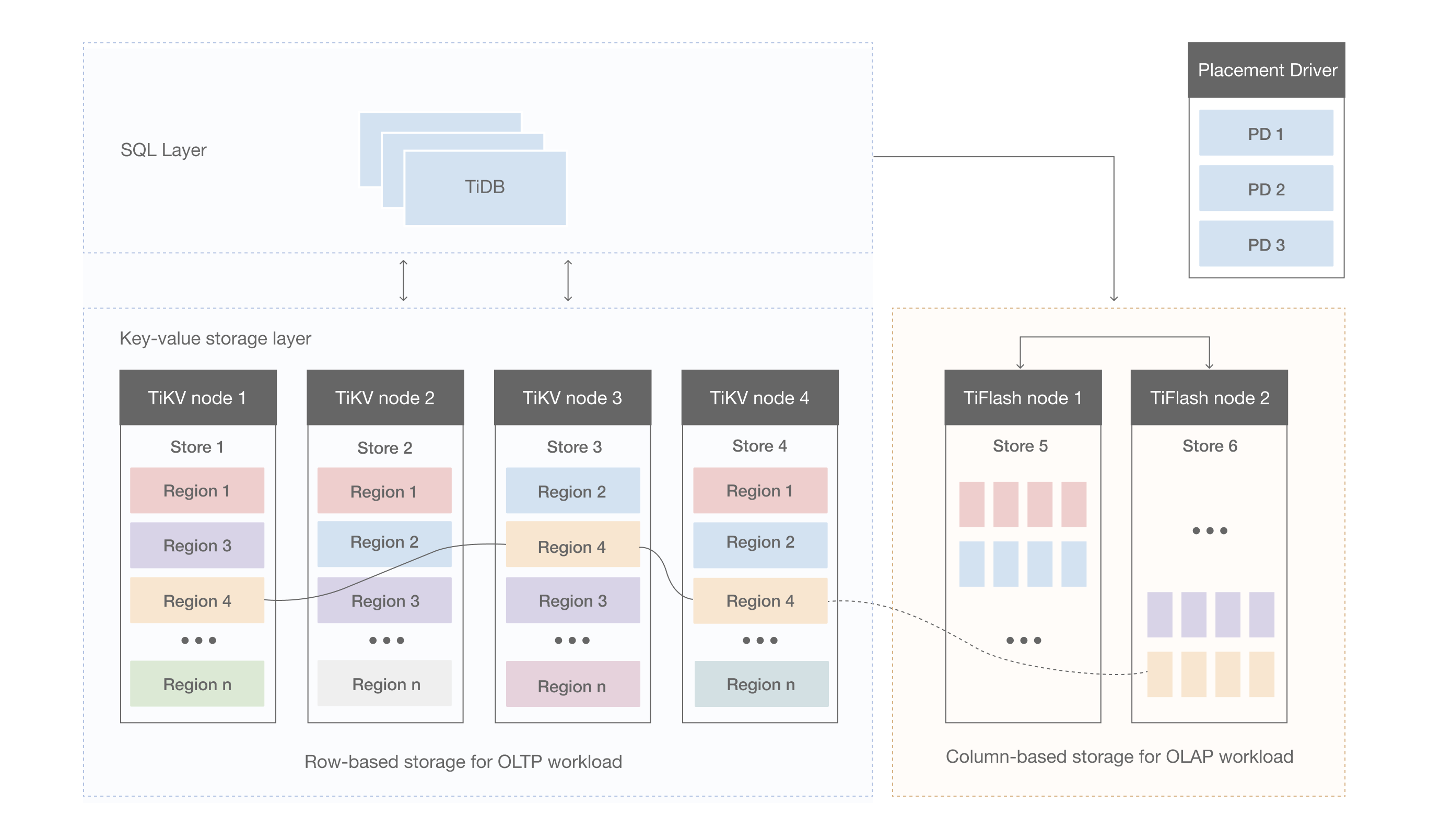
上の図は、 TiFlashノードを含む HTAP 形式の TiDB のアーキテクチャです。
TiFlash は、ClickHouse によって効率的に実装されたコプロセッサレイヤーを備えたカラム型storageを提供します。 TiKV と同様に、 TiFlashにも Multi-Raft システムがあり、リージョン単位でのデータの複製と分散をサポートしています (詳細はデータストレージを参照)。
TiFlash は、 TiKV への書き込みをブロックしない低コストで、TiKV ノード内のデータのリアルタイム レプリケーションを実行します。一方、TiKV と同じ読み取り一貫性が提供され、最新のデータが確実に読み取られます。 TiFlashのリージョンレプリカは、論理的には TiKV のレプリカと同一であり、TiKV のLeaderレプリカと同時に分割およびマージされます。
Linux AMD64アーキテクチャでTiFlashを導入するには、CPU が AVX2 命令セットをサポートしている必要があります。 cat /proc/cpuinfo | grep avx2に出力があることを確認します。 Linux ARM64アーキテクチャでTiFlashを導入するには、CPU が ARMv8 命令セットアーキテクチャをサポートしている必要があります。 cat /proc/cpuinfo | grep 'crc32' | grep 'asimd'に出力があることを確認します。命令セット拡張を使用することにより、TiFlash のベクトル化エンジンはより優れたパフォーマンスを実現できます。
TiFlash はTiDB と TiSpark の両方と互換性があるため、これら 2 つのコンピューティング エンジンから自由に選択できます。
ワークロードを確実に分離するために、TiKV とは別のノードにTiFlashをデプロイすることをお勧めします。ビジネスの分離が必要ない場合は、 TiFlashと TiKV を同じノードに導入することもできます。
現在、データをTiFlashに直接書き込むことはできません。 TiKV はLearnerの役割として TiDB クラスターに接続するため、データを TiKV に書き込んでからTiFlashにレプリケートする必要があります。 TiFlash はテーブル単位でのデータ複製をサポートしていますが、展開後のデフォルトではデータは複製されません。指定したテーブルのデータを複製するには、 テーブルのTiFlashレプリカを作成するを参照してください。
TiFlash には、柱状storageモジュール、 tiflash proxy 、およびpd buddyつのコンポーネントがあります。 tiflash proxy Multi-Raft コンセンサス アルゴリズムを使用した通信を担当します。 pd buddy PDと連携してTiKVからTiFlashへテーブル単位でデータを複製します。
TiDB がTiFlashにレプリカを作成する DDL コマンドを受信すると、 pd buddyコンポーネントはTiDB のステータス ポートを介してレプリケーション対象のテーブルの情報を取得し、その情報を PD に送信します。次に、PD はpd buddyによって提供された情報に従って、対応するデータ スケジューリングを実行します。
主な特徴
TiFlashには次の主要な機能があります。
非同期レプリケーション
TiFlash内のレプリカは、特別なロールRaft Learnerとして非同期的にレプリケートされます。つまり、 TiFlashノードがダウンしている場合や、ネットワークレイテンシーが発生している場合でも、TiKV のアプリケーションは通常どおり続行できるということです。
このレプリケーション メカニズムは、自動負荷分散と高可用性という TiKV の 2 つの利点を継承しています。
- TiFlash は追加のレプリケーション チャネルに依存せず、多対多の方法で TiKV からデータを直接受信します。
- TiKV 内のデータが失われない限り、いつでもTiFlashにレプリカを復元できます。
一貫性
TiFlash は、 TiKV と同じスナップショット分離レベルの一貫性を提供し、最新のデータが確実に読み取られるようにします。つまり、以前に TiKV に書き込まれたデータを読み取ることができます。このような一貫性は、データ複製の進行状況を検証することによって実現されます。
TiFlash が読み取りリクエストを受信するたびに、リージョンレプリカは進行状況検証リクエスト (軽量 RPC リクエスト) をLeaderレプリカに送信します。 TiFlash は、現在のレプリケーションの進行状況に読み取りリクエストのタイムスタンプでカバーされるデータが含まれた後にのみ読み取り操作を実行します。
インテリジェントな選択
TiDB は、 TiFlash (列方向) または TiKV (行方向) の使用を自動的に選択したり、1 つのクエリで両方を使用して最高のパフォーマンスを保証したりできます。
この選択メカニズムは、クエリを実行するためにさまざまなインデックスを選択する TiDB のメカニズムと似ています。 TiDB オプティマイザーは、読み取りコストの統計に基づいて適切な選択を行います。
コンピューティングの高速化
TiFlash は、次の 2 つの方法で TiDB のコンピューティングを高速化します。
- カラム型storageエンジンは、読み取り操作の実行効率が高くなります。
- TiFlash は、 TiDB のコンピューティング ワークロードの一部を共有します。
TiFlash は、 TiKVコプロセッサーと同じ方法でコンピューティング ワークロードを共有します。TiDB は、storageレイヤーで完了できるコンピューティングをプッシュダウンします。コンピューティングをプッシュダウンできるかどうかは、 TiFlashのサポートに依存します。詳細はサポートされているプッシュダウン計算を参照してください。
TiFlashを使用する
TiFlashの展開後、データ レプリケーションは自動的に開始されません。レプリケートするテーブルを手動で指定する必要があります。
TiDB を使用して中規模の分析処理用にTiFlashレプリカを読み取ることも、TiSpark を使用して大規模な分析処理用にTiFlashレプリカを読み取ることもできますが、これは独自のニーズに基づいています。詳細については、次のセクションを参照してください。
データのインポートから TPC-H データセットでのクエリまでのプロセス全体を体験するには、 TiDB HTAPのクイック スタート ガイドを参照してください。
こちらも参照
- TiFlashノードを含む新しいクラスターをデプロイするには、 TiUPを使用して TiDB クラスターをデプロイを参照してください。
- デプロイされたクラスターにTiFlashノードを追加するには、 TiFlashクラスターをスケールアウトするを参照してください。
- TiFlashクラスターを管理 。
- TiFlash のパフォーマンスを調整する 。
- TiFlashを構成する 。
- TiFlashクラスターを監視する 。
- TiFlashアラート ルールを学びます。
- TiFlashクラスターのトラブルシューティング 。
- TiFlashでサポートされるプッシュダウン計算
- TiFlashでのデータ検証
- TiFlashの互換性