双方向レプリケーション
TiCDCは、2つのTiDBクラスタ間の双方向レプリケーション(BDR)をサポートしています。この機能を利用することで、TiCDCを使用したマルチアクティブTiDBソリューションを構築できます。
このセクションでは、2 つの TiDB クラスターを例にして双方向レプリケーションを使用する方法について説明します。
双方向レプリケーションをデプロイ
TiCDCは、指定されたタイムスタンプ以降に発生した増分データ変更のみを下流クラスターに複製します。双方向レプリケーションを開始する前に、次の手順を実行する必要があります。
(オプション) 必要に応じて、データ エクスポート ツールDumplingとデータ インポート ツールTiDB Lightningを使用して、2 つの TiDB クラスターのデータを相互にインポートします。
2つのTiDBクラスターの間に2つのTiCDCクラスターをデプロイ。クラスタートポロジは以下のとおりです。図中の矢印はデータフローの方向を示しています。
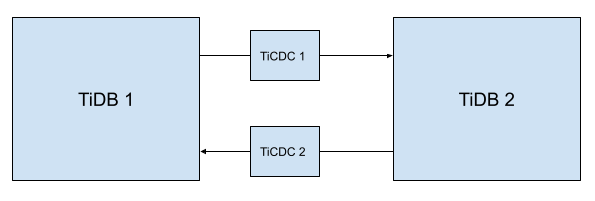
アップストリーム クラスターとダウンストリーム クラスターのデータ複製の開始時点を指定します。
上流クラスタと下流クラスタの時点を確認します。2つのTiDBクラスタがある場合は、特定の時点において2つのクラスタのデータが整合していることを確認します。例えば、TiDB 1の
ts=1時点のデータとTiDB 2のts=2のデータは整合しています。changefeed を作成する際、上流クラスターの changefeed の
--start-ts対応するtsoに設定します。つまり、上流クラスターが TiDB 1 の場合は--start-ts=1、下流クラスターが TiDB 2 の場合は--start-ts=2設定します。
--configパラメータで指定された構成ファイルに、次の構成を追加します。# Whether to enable the bidirectional replication mode bdr-mode = true
構成が有効になると、クラスターは双方向のレプリケーションを実行できるようになります。
DDLタイプ
v7.6.0 以降、双方向レプリケーションで DDL レプリケーションを可能な限りサポートするために、TiDB は、DDL がビジネスに与える影響に応じて、 TiCDCが元々サポートしていたDDLをレプリケート可能な DDL とレプリケート不可能な DDL の 2 種類に分割します。
複製可能なDDL
レプリケート可能な DDL は、双方向レプリケーションで直接実行し、他の TiDB クラスターにレプリケートできる DDL です。
レプリケート可能な DDL には次のものが含まれます。
ALTER TABLE ... ADD COLUMN: 列はnullになるか、not nullとdefault value同時に存在するALTER TABLE ... ADD INDEX(一意ではない)ALTER TABLE ... ADD PARTITIONALTER TABLE ... ALTER COLUMN DROP DEFAULTALTER TABLE ... ALTER COLUMN SET DEFAULTALTER TABLE ... COMMENT=...ALTER TABLE ... DROP PRIMARY KEYALTER TABLE ... MODIFY COLUMN: 列のdefault valueとcommentのみ変更できますALTER TABLE ... RENAME INDEXALTER TABLE ... ALTER INDEX ... INVISIBLEALTER TABLE ... ALTER INDEX ... VISIBLEALTER TABLE REMOVE TTLALTER TABLE TTLCREATE DATABASECREATE INDEXCREATE TABLECREATE VIEWDROP INDEXDROP VIEW
複製不可能なDDL
複製不可能なDDLは、ビジネスへの影響が大きく、クラスタ間のデータ不整合を引き起こす可能性のあるDDLです。複製不可能なDDLは、TiCDCを介した双方向レプリケーションにおいて、他のTiDBクラスタに直接複製することはできません。複製不可能なDDLは、特定の操作を通じて実行する必要があります。
レプリケートできない DDL には次のものが含まれます。
ALTER DATABASE CHARACTER SETALTER TABLE ... ADD COLUMN: 列はnot nullでdefault valueありませんALTER TABLE ... ADD PRIMARY KEYALTER TABLE ... ADD UNIQUE INDEXALTER TABLE ... AUTO_INCREMENT=...ALTER TABLE ... AUTO_RANDOM_BASE=...ALTER TABLE ... CHARACTER SET=...ALTER TABLE ... DROP COLUMNALTER TABLE ... DROP PARTITIONALTER TABLE ... EXCHANGE PARTITIONALTER TABLE ... MODIFY COLUMN:default valueとcomment除く列の属性を変更できますALTER TABLE ... REORGANIZE PARTITIONALTER TABLE ... TRUNCATE PARTITIONDROP DATABASEDROP TABLERECOVER TABLERENAME TABLETRUNCATE TABLE
DDLレプリケーション
レプリケート可能な DDL とレプリケート不可能な DDL の問題を解決するために、TiDB は次の BDR ロールを導入します。
PRIMARY: レプリケート可能なDDLは実行できますが、レプリケート不可能なDDLは実行できません。プライマリクラスターで実行されたレプリケート可能なDDLは、TiCDCによってダウンストリームにレプリケートされます。SECONDARY: レプリケート可能なDDLもレプリケート不可能なDDLも実行できません。ただし、プライマリクラスターで実行されたDDLは、TiCDCによってセカンダリクラスターにレプリケートできます。
BDRロールが設定されていない場合、任意のDDLを実行できます。ただし、BDRモードの変更フィードでは、そのクラスター上のDDLはレプリケートされません。
つまり、BDR モードでは、TiCDC は PRIMARY クラスター内の複製可能な DDL のみをダウンストリームに複製します。
複製可能なDDLのレプリケーションシナリオ
TiDB クラスターを選択し、
ADMIN SET BDR ROLE PRIMARY実行してそれをプライマリ クラスターとして設定します。ADMIN SET BDR ROLE PRIMARY;Query OK, 0 rows affected Time: 0.003s ADMIN SHOW BDR ROLE; +----------+ | BDR_ROLE | +----------+ | primary | +----------+他の TiDB クラスターで
ADMIN SET BDR ROLE SECONDARY実行して、それらをセカンダリ クラスターとして設定します。プライマリクラスターでレプリケート可能なDDLを実行します。正常に実行されたDDLは、TiCDCによってセカンダリクラスターにレプリケートされます。
注記:
不正使用を防ぐために:
複製不可能なDDLのレプリケーションシナリオ
- すべての TiDB クラスターで
ADMIN UNSET BDR ROLE実行して、BDR ロールを設定解除します。 - すべてのクラスターで DDL を実行する必要があるテーブルへのデータの書き込みを停止します。
- すべてのクラスター内の対応するテーブルへのすべての書き込みが他のクラスターに複製されるまで待機し、各 TiDB クラスターですべての DDL を手動で実行します。
- DDL が完了するまで待ってから、データの書き込みを再開します。
- レプリケート可能な DDL のレプリケーション シナリオに戻すには、手順複製可能なDDLのレプリケーションシナリオに従います。
双方向レプリケーションを停止する
アプリケーションがデータの書き込みを停止した後、各クラスターに特別なレコードを挿入できます。2つの特別なレコードをチェックすることで、2つのクラスターのデータの整合性を確認できます。
チェックが完了したら、変更フィードを停止して双方向レプリケーションを停止し、すべての TiDB クラスターでADMIN UNSET BDR ROLE実行できます。
制限事項
BDR ロールは次のシナリオでのみ使用してください。
1
PRIMARYクラスターと nSECONDARYクラスター(複製可能な DDL のレプリケーション シナリオ)BDR ロールを持たない n 個のクラスタ(各クラスタで複製不可能な DDL を手動で実行できるレプリケーション シナリオ)
注記:
他のシナリオではBDRロールを設定しないでください。例えば、BDRロールを
PRIMARY、SECONDARY、そして0つを同時に設定しないでください。BDRロールを誤って設定すると、TiDBはデータレプリケーション中にデータの正確性と一貫性を保証できません。通常、レプリケートされたテーブルでのデータ競合を避けるため、
AUTO_INCREMENTまたはAUTO_RANDOM使用しないでください。5 またはAUTO_INCREMENTAUTO_RANDOM使用する必要がある場合は、異なるクラスタに異なる主キーを割り当てることができるように、異なるクラスタに異なるauto_increment_incrementとauto_increment_offset設定できます。例えば、双方向レプリケーションに3つのTiDBクラスタ(A、B、C)がある場合、次のように設定します。- クラスタAでは、
auto_increment_increment=3とauto_increment_offset=2000設定します - クラスタBでは、
auto_increment_increment=3とauto_increment_offset=2001設定します - クラスタCでは、
auto_increment_increment=3とauto_increment_offset=2002設定します
これにより、A、B、Cは暗黙的に割り当てられた
AUTO_INCREMENTとAUTO_RANDOMで互いに競合することがなくなります。BDRモードでクラスターを追加する必要がある場合は、関連アプリケーションのデータ書き込みを一時的に停止し、すべてのクラスターのauto_increment_incrementとauto_increment_offsetに適切な値を設定してから、関連アプリケーションのデータ書き込みを再開する必要があります。- クラスタAでは、
双方向レプリケーションクラスタは書き込み競合を検出できないため、未定義の動作が発生する可能性があります。そのため、アプリケーション側で書き込み競合がないことを確認する必要があります。
双方向レプリケーションは2つ以上のクラスタをサポートしますが、カスケードモード、つまりTiDB A -> TiDB B -> TiDB C -> TiDB Aのような循環レプリケーションはサポートしません。このようなトポロジでは、1つのクラスタに障害が発生すると、データレプリケーション全体に影響が出ます。したがって、複数のクラスタ間で双方向レプリケーションを有効にするには、各クラスタを他のすべてのクラスタ(例:
TiDB A <-> TiDB BTiDB C <-> TiDB Aに接続するTiDB B <-> TiDB Cがあります。