SQLチューニングの実践ガイド
このガイドは、 TiDB SQLチューニングの初心者向けに設計されています。以下の主要な原則に焦点を当てています。
- 参入障壁が低い: チューニングの概念と方法を段階的に導入します。
- 実践指向: それぞれの最適化のヒントについて具体的な手順と例を提供します。
- クイック スタート: 最も一般的で効果的な最適化方法を優先します。
- 緩やかな学習曲線: 複雑な理論ではなく実践的なテクニックを重視します。
- シナリオベース: 実際のビジネス ケースを使用して最適化の効果を実証します。
SQLチューニング入門
SQLチューニングは、データベースのパフォーマンスを最適化するために不可欠です。SQLチューニングでは、以下の典型的な手順を通じて、SQLクエリの効率を体系的に改善します。
影響の大きい SQL ステートメントを特定します。
- SQL 実行履歴を確認して、大量のシステム リソースを消費したり、アプリケーションのワークロードに大きく影響したりするステートメントを見つけます。
- 監視ツールとパフォーマンス メトリックを使用して、リソースを大量に消費するクエリを識別します。
実行プランを分析します。
- 特定されたステートメントに対してクエリ オプティマイザーによって生成された実行プランを調べます。
- これらのプランが合理的に効率的であり、適切なインデックスと結合方法が使用されているかどうかを確認します。
最適化を実装する:
非効率なSQL文に最適化を実装します。最適化には、SQL文の書き換え、インデックスの追加または変更、統計の更新、データベースパラメータの調整などが含まれます。
以下の手順を繰り返す:
- システムのパフォーマンスは目標要件を満たしています。
- 残りのステートメントについては、これ以上の改善はできません。
SQLチューニングは継続的なプロセスです。データ量が増加し、クエリパターンが変化するにつれて、以下の点に注意する必要があります。
- クエリのパフォーマンスを定期的に監視します。
- 最適化戦略を再評価します。
- 新たなパフォーマンスの課題に対処するためにアプローチを調整します。
これらのプラクティスを一貫して適用することで、長期にわたって最適なデータベース パフォーマンスを維持できます。
SQLチューニングの目的
SQL チューニングの主な目的は次のとおりです。
- エンドユーザーへの応答時間を短縮します。
- クエリ実行中のリソース消費を最小限に抑えます。
これらの目標を達成するには、次の戦略を使用できます。
クエリ実行を最適化する
SQLチューニングは、クエリの機能を変えずに同じワークロードをより効率的に処理する方法を見つけることに重点を置いています。クエリ実行は次のように最適化できます。
実行計画の改善:
- より効率的な処理のためにクエリ構造を分析および変更します。
- 適切なインデックスを使用して、データ アクセスと処理時間を短縮します。
- 大規模なデータセットに対する分析クエリにTiFlashを有効にし、複雑な集計や結合に超並列処理(MPP)エンジンを活用します。
データアクセス方法の強化:
- カバーリング インデックスを使用すると、テーブル全体のスキャンを回避し、インデックスから直接クエリを満たすことができます。
- データスキャンを関連するパーティションに制限するためのパーティション戦略を実装します。
例:
- 頻繁にクエリされる列にインデックスを作成すると、特にテーブルの小さな部分にアクセスするクエリの場合、リソース使用量が大幅に削減されます。
- 完全なテーブルスキャンとソート操作を回避するために、限られた数のソートされた結果を返すクエリにはインデックスのみのスキャンを使用します。
作業負荷の分散をバランスよく行う
TiDBのような分散アーキテクチャでは、TiKVノード間でワークロードを分散させることが最適なパフォーマンスを得るために不可欠です。読み取りと書き込みのホットスポットを特定して解決するには、 ホットスポットの問題のトラブルシューティング参照してください。
これらの戦略を実装することで、TiDB クラスターが利用可能なすべてのリソースを効率的に利用し、個々の TiKV ノードでのワークロードの不均一な分散やシリアル化によって発生するボトルネックを回避できるようになります。
高負荷SQLを特定する
リソースを大量に消費する SQL 文を特定する最も効率的な方法は、 TiDBダッシュボード使用することです。また、ビューやログなどの他のツールを使用して、負荷の高い SQL 文を特定することもできます。
TiDBダッシュボードを使用してSQL文を監視する
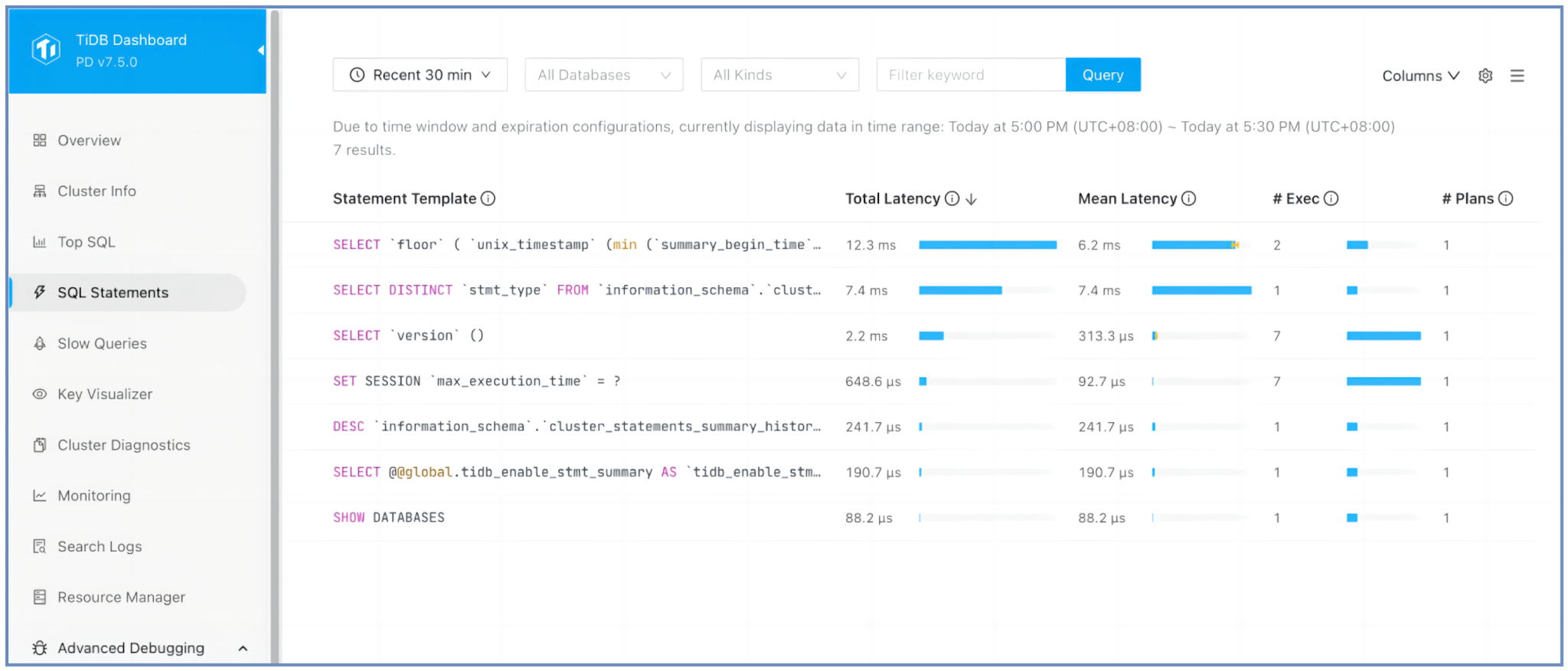
SQL文ページ
TiDBダッシュボードでSQL文ページに移動して、次の点を確認します。
- 合計レイテンシーが最も長い SQL ステートメント。これは、複数回の実行にわたって実行に最も長い時間がかかるステートメントです。
- 各 SQL ステートメントが実行された回数。実行頻度が最も高いステートメントを識別するのに役立ちます。
- 各 SQL ステートメントをクリックすると、
EXPLAIN ANALYZE結果が表示され、実行の詳細が表示されます。
TiDBは、リテラルとバインド変数を?に置き換えることで、SQL文をテンプレートに正規化します。この正規化とソートのプロセスにより、最適化が必要な可能性のある、最もリソースを消費するクエリを迅速に特定できます。
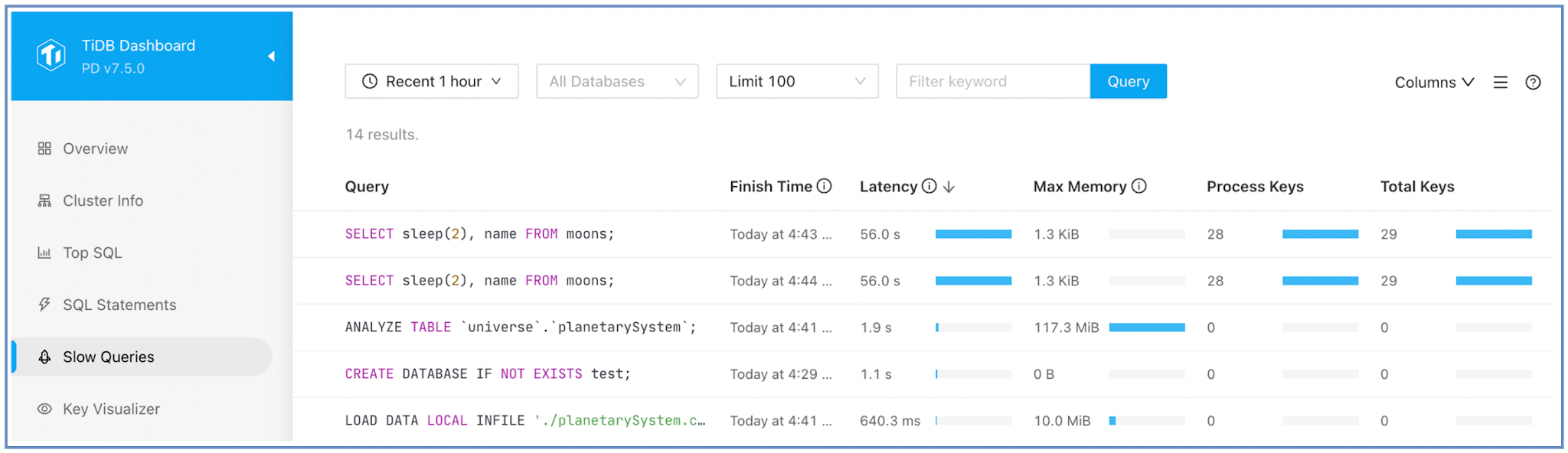
遅いクエリページ
TiDBダッシュボードで遅いクエリページに移動して次の項目を見つけます。
- 最も遅い SQL クエリ。
- TiKV から最も多くのデータを読み取る SQL クエリ。
- 詳細な実行分析を行うには、クエリをクリックして
EXPLAIN ANALYZE出力します。
「スロークエリ」ページにはSQL実行頻度は表示されません。クエリの実行時間が単一インスタンスのtidb_slow_log_threshold設定項目を超えた場合、このページにそのクエリが表示されます。
他のツールを使用してTop SQLを特定する
TiDBダッシュボードに加えて、他のツールを使用してリソースを大量に消費するSQLクエリを特定することもできます。各ツールは独自の分析情報を提供し、さまざまな分析シナリオで役立ちます。これらのツールを組み合わせて使用することで、包括的なSQLパフォーマンス監視と最適化を実現できます。
- TiDBダッシュボードのTop SQLページ
- ログ: スロークエリログとTiDBログ内の高価なクエリ
- ビュー:
cluster_statements_summaryビューとcluster_processlistビュー
識別されたSQL文に関するデータを収集する
特定された上位のSQL文については、 PLAN REPLAYER使用してTiDBクラスタからSQL実行情報を取得・保存できます。このツールは、さらなる分析のために実行環境を再現するのに役立ちます。SQL実行情報をエクスポートするには、次の構文を使用します。
PLAN REPLAYER DUMP EXPLAIN [ANALYZE] [WITH STATS AS OF TIMESTAMP expression] sql-statement;
可能な限りEXPLAIN ANALYZE使用してください。これは、実行プランと実際のパフォーマンス メトリックの両方が提供され、クエリ パフォーマンスに関するより正確な分析情報が得られるためです。
SQLチューニングガイド
このガイドでは、TiDBにおけるSQLクエリの最適化に関する初心者向けの実践的なアドバイスを提供します。これらのベストプラクティスに従うことで、クエリのパフォーマンスを向上させ、SQLチューニングを効率化できます。このガイドでは、以下のトピックを取り上げます。
クエリ処理を理解する
このセクションでは、クエリ処理ワークフロー、オプティマイザーの基礎、および統計管理について説明します。
クエリ処理ワークフロー
クライアントがTiDBにSQL文を送信すると、その文はTiDBサーバーのプロトコルレイヤーを通過します。このレイヤーはTiDBサーバーとクライアント間の接続を管理し、SQL文を受信してクライアントにデータを返します。
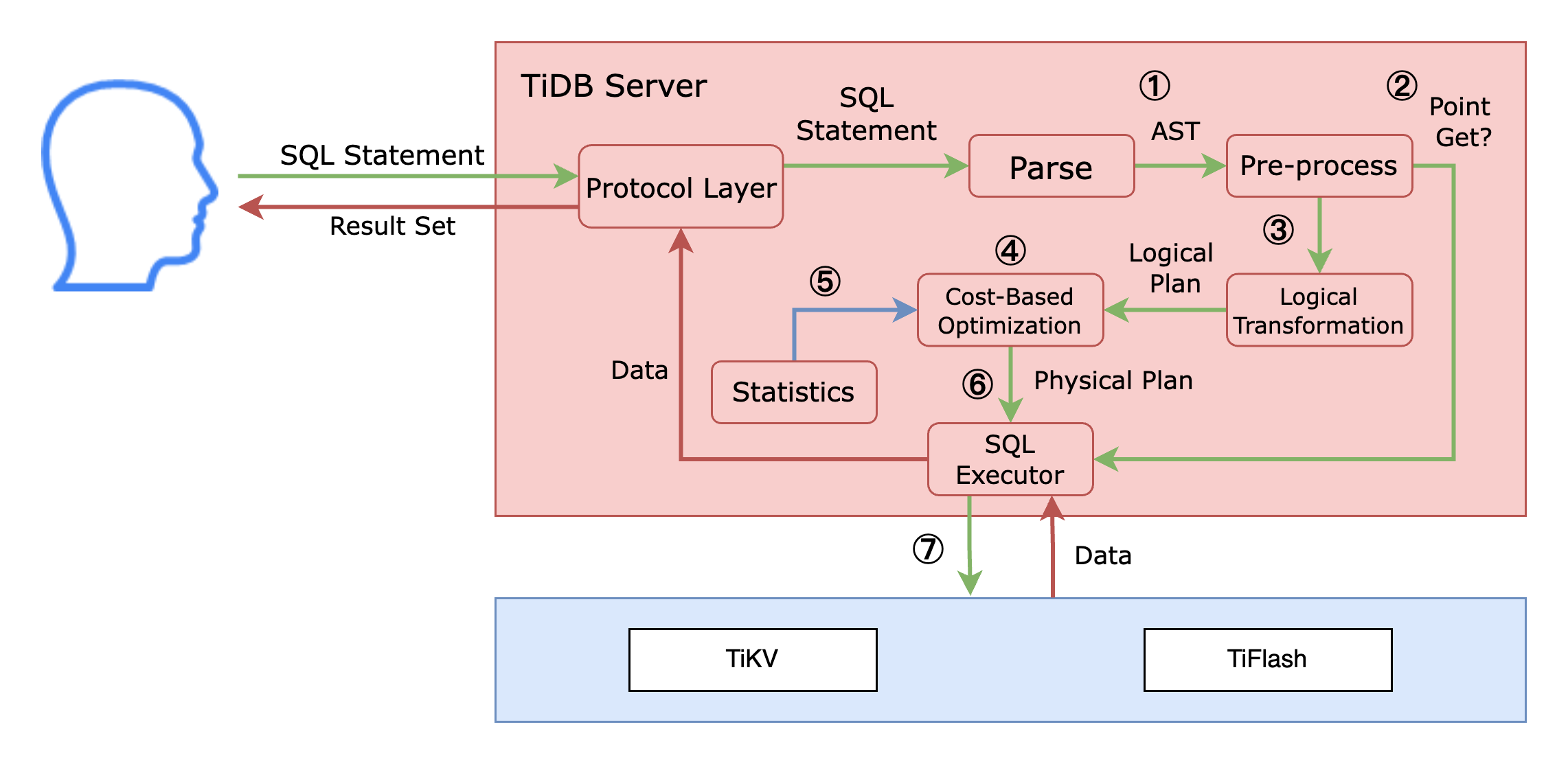
上の図では、プロトコルレイヤーの右側に TiDBサーバーのオプティマイザーがあり、次のように SQL ステートメントを処理します。
- SQL ステートメントはプロトコルレイヤーを介して SQL オプティマイザーに到達し、抽象構文ツリー (AST) に解析されます。
- TiDBは、それがポイントゲット文であるかどうかを識別します。1文は、
SELECT * FROM t WHERE pk_col = 1やSELECT * FROM t WHERE uk_col IN (1,2,3)などの主キーまたは一意キーを介した単純な1テーブル検索です。7Point Getの場合、TiDBは後続の最適化手順をスキップし、SQLエグゼキュータで直接実行します。 - クエリが
Point Getでない場合、AST は論理変換され、TiDB は特定のルールに基づいて SQL を論理的に書き換えます。 - 論理変換後、TiDB はコストベースの最適化を通じて AST を処理します。
- コストベースの最適化では、オプティマイザーは統計を使用して適切な演算子を選択し、物理的な実行プランを生成します。
- 生成された物理実行プランは、実行のために TiDB ノードの SQL 実行プログラムに送信されます。
- 従来のシングルノードデータベースとは異なり、TiDBは、データが格納されているTiKVノードまたはTiFlashノードに演算子またはコプロセッサをプッシュダウンします。このアプローチは、データが格納されている実行プランの一部を処理するため、分散アーキテクチャを効率的に活用し、リソースを並列化し、ネットワークデータ転送を削減します。その後、TiDBノードエグゼキュータが最終結果を組み立て、クライアントに返します。
オプティマイザーの基礎
TiDBはコストベースオプティマイザ(CBO)を使用して、SQL文に対して最も効率的な実行プランを決定します。オプティマイザは複数の実行戦略を評価し、推定コストが最も低いものを選択します。コストは以下のような要因に依存します。
- SQL文
- スキーマ設計
- 統計には以下が含まれます:
- 表統計
- インデックス統計
- カラム統計
これらの入力に基づいて、コスト モデルは、TiDB が SQL ステートメントを実行する方法を詳細に示す実行プランを生成します。これには次の内容が含まれます。
- アクセス方法
- 結合方法
- 結合順序
オプティマイザの有効性は、受け取る情報の質に依存します。最適なパフォーマンスを実現するには、統計が最新であること、インデックスが適切に設計されていることを確認してください。
統計管理
統計はTiDBオプティマイザにとって不可欠です。TiDBは統計をオプティマイザの入力として使用し、SQL実行プランの各ステップで処理される行数を推定します。
統計は次の 2 つのレベルに分かれています。
- テーブル レベルの統計: テーブル内の行の合計数と、最後の統計収集以降に変更された行数が含まれます。
- インデックス/列レベルの統計: ヒストグラム、Count-Min Sketch、Top-N (最も多く出現する値またはインデックス)、さまざまな値の分布と量、NULL 値の数などの詳細情報が含まれます。
統計の正確性と健全性を確認するには、次の SQL ステートメントを使用できます。
SHOW STATS_META: テーブル統計に関するメタデータを表示します。SHOW STATS_META WHERE table_name='T2'\G;*************************** 1. row *************************** Db_name: test Table_name: T2 Partition_name: Update_time: 2023-05-11 02:16:50 Modify_count: 10000 Row_count: 20000 1 row in set (0.03 sec)SHOW STATS_HEALTHY: テーブル統計のヘルス ステータスを表示します。SHOW STATS_HEALTHY WHERE table_name='T2'\G;*************************** 1. row *************************** Db_name: test Table_name: T2 Partition_name: Healthy: 50 1 row in set (0.00 sec)
TiDBは、統計情報を収集する方法として、自動収集と手動収集の2種類を提供しています。ほとんどの場合、自動収集で十分です。TiDBは、特定の条件が満たされると自動収集をトリガーします。一般的なトリガー条件には、次のようなものがあります。
tidb_auto_analyze_ratio: 健全性トリガー。tidb_auto_analyze_start_timeおよびtidb_auto_analyze_end_time: 自動統計収集の時間ウィンドウ。
SHOW VARIABLES LIKE 'tidb\_auto\_analyze%';
+-----------------------------------------+-------------+
| Variable_name | Value |
+-----------------------------------------+-------------+
| tidb_auto_analyze_ratio | 0.5 |
| tidb_auto_analyze_start_time | 00:00 +0000 |
| tidb_auto_analyze_end_time | 23:59 +0000 |
+-----------------------------------------+-------------+
自動収集ではニーズを満たせない場合があります。デフォルトでは00:00 ~ 23:59回収集されるため、分析ジョブはいつでも実行できます。オンラインビジネスへのパフォーマンスへの影響を最小限に抑えるため、統計収集の開始時間と終了時間を指定することもできます。
ANALYZE TABLE table_nameステートメントを使用して手動で統計情報を収集できます。これにより、サンプルレート、上位N値の数などの設定を調整したり、特定の列のみの統計を収集したりできます。
手動収集後、後続の自動収集ジョブは新しい設定を継承します。つまり、手動収集中に行われたカスタマイズは、将来の自動分析にも適用されます。
テーブル統計のロックは、次のシナリオで役立ちます。
- 表の統計はすでにデータを適切に表しています。
- テーブルが非常に大きいため、統計の収集には時間がかかります。
- 特定の時間枠内でのみ統計を維持したい。
テーブルの統計をロックするには、 LOCK STATS table_nameステートメントを使用できます。
詳細については統計参照してください。
実行計画を理解する
実行プランとは、TiDBがSQLクエリを実行する際に実行する手順の詳細です。このセクションでは、TiDBがどのように実行プランを作成するか、そして実行プランを生成、表示、解釈する方法について説明します。
TiDBが実行計画を構築する方法
SQL ステートメントは、TiDB オプティマイザーで主に 3 つの最適化段階を経ます。
1. 前処理
TiDBは前処理中に、SQL文がPoint_GetまたはBatch_Point_Get方法で実行できるかを判断します。これらの操作では、主キーまたは一意キーを使用して、TiKVから正確なキー検索によって直接読み取ります。プランがPoint_GetまたはBatch_Point_Get条件を満たす場合、オプティマイザは論理変換とコストベースの最適化の手順をスキップします。これは、直接キー検索が行へのアクセスに最も効率的な方法であるためです。
以下はPoint_Getクエリの例です。
EXPLAIN SELECT id, name FROM emp WHERE id = 901;
+-------------+---------+------+---------------+---------------+
| id | estRows | task | access object | operator info |
+-------------+---------+------+---------------+---------------+
| Point_Get_1 | 1.00 | root | table:emp | handle:901 |
+-------------+---------+------+---------------+---------------+
2. 論理変換
論理変換では、TiDBはSELECTリスト、 WHERE述語、およびその他の条件に基づいてSQL文を最適化します。クエリに注釈を付けて書き換えるための論理実行プランを生成します。この論理プランは、次の段階であるコストベースの最適化で使用されます。この変換では、列プルーニング、パーティションプルーニング、結合順序の変更といったルールベースの最適化が適用されます。このプロセスはルールベースで自動的に実行されるため、通常は手動での調整は不要です。
詳細についてはSQL論理最適化参照してください。
3. コストベースの最適化
TiDBオプティマイザは、統計情報を用いてSQL文の各ステップで処理される行数を推定し、各ステップにコストを割り当てます。コストベースの最適化では、オプティマイザはインデックスアクセスや結合方法など、考えられるすべてのプランを評価し、各プランの合計コストを計算します。そして、合計コストが最小となる実行プランを選択します。
次の図は、コストベース最適化において考慮される様々なデータアクセスパスと行セット操作を示しています。データ取得パスについては、オプティマイザーはインデックススキャンとフルテーブルスキャンのどちらが最も効率的な方法であるかを判断し、行ベースのTiKVstorageと列指向のTiFlashstorageのどちらからデータを取得するかを決定します。
オプティマイザは、集計、結合、ソートなど、行セットを操作する操作も評価します。例えば、集計演算子ではHashAggまたはStreamAggいずれかが使用される可能性がありますが、結合方法ではHashJoin 、 MergeJoin 、またはIndexJoinいずれかが選択されます。
さらに、物理最適化フェーズでは、式と演算子を物理storageエンジンにプッシュダウンします。物理プランは、基盤となるstorageエンジンに基づいて、以下のように異なるコンポーネントに分配されます。
- ルート タスクは TiDBサーバー上で実行されます。
- Cop (コプロセッサー) タスクは TiKV 上で実行されます。
- MPP タスクはTiFlash上で実行されます。
この分散により、コンポーネント間のコラボレーションが可能になり、効率的なクエリ処理が可能になります。
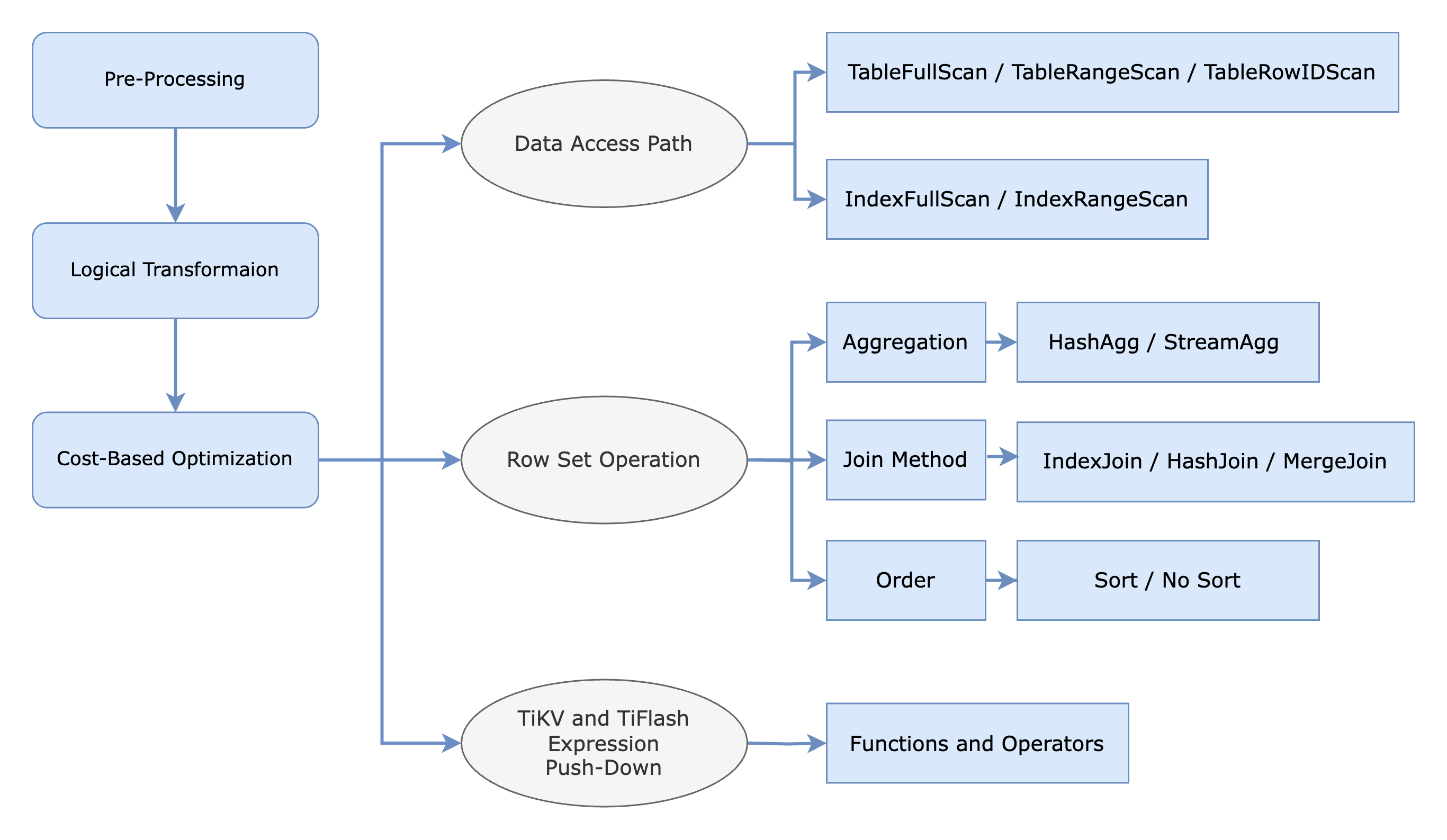
詳細についてはSQL物理最適化参照してください。
実行計画を生成して表示する
TiDBダッシュボードから実行計画情報にアクセスするだけでなく、 EXPLAINのステートメントを使用してSQLクエリの実行計画を表示できます。3 EXPLAIN出力には以下の列が含まれます。
id: オペレータ名とステップの一意の識別子。estRows: 特定のステップからの推定行数。task: オペレータが実行されるレイヤーを示します。例えば、rootTiDBサーバー上での実行、cop[tikv]TiKV 上での実行、mpp[tiflash]TiFlash上での実行を示します。access object: 行ソースが配置されているオブジェクト。operator info: ステップ内の演算子に関する追加の詳細。
EXPLAIN SELECT COUNT(*) FROM trips WHERE start_date BETWEEN '2017-07-01 00:00:00' AND '2017-07-01 23:59:59';
+--------------------------+-------------+--------------+-------------------+----------------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+--------------------------+-------------+--------------+-------------------+----------------------------------------------------------------------------------------------------+
| StreamAgg_20 | 1.00 | root | | funcs:count(Column#13)->Column#11 |
| └─TableReader_21 | 1.00 | root | | data:StreamAgg_9 |
| └─StreamAgg_9 | 1.00 | cop[tikv] | | funcs:count(1)->Column#13 |
| └─Selection_19 | 250.00 | cop[tikv] | | ge(trips.start_date, 2017-07-01 00:00:00.000000), le(trips.start_date, 2017-07-01 23:59:59.000000) |
| └─TableFullScan_18 | 10000.00 | cop[tikv] | table:trips | keep order:false, stats:pseudo |
+--------------------------+-------------+--------------+-------------------+----------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)
EXPLAINとは異なり、 EXPLAIN ANALYZE対応するSQL文を実行し、その実行時情報を記録し、実行計画とともに返します。この実行時情報は、クエリ実行のデバッグに不可欠です。詳細については、 EXPLAIN ANALYZE参照してください。
EXPLAIN ANALYZE出力には以下が含まれます。
actRows: 演算子によって出力される行数。execution info: オペレータの詳細な実行情報。2time、すべてのサブオペレータの合計実行時間を含む合計wall time表します。オペレータが親オペレータによって何度も呼び出される場合、時間は累積時間を参照します。memory: 演算子によって使用されるメモリ。disk: オペレータが使用するディスク容量。
以下は例です。書式設定を簡素化するため、一部の属性と表の列は省略されています。
EXPLAIN ANALYZE
SELECT SUM(pm.m_count) / COUNT(*)
FROM (
SELECT COUNT(m.name) m_count
FROM universe.moons m
RIGHT JOIN (
SELECT p.id, p.name
FROM universe.planet_categories c
JOIN universe.planets p
ON c.id = p.category_id
AND c.name = 'Jovian'
) pc ON m.planet_id = pc.id
GROUP BY pc.name
) pm;
+-----------------------------------------+.+---------+-----------+---------------------------+----------------------------------------------------------------+.+-----------+---------+
| id |.| actRows | task | access object | execution info |.| memory | disk |
+-----------------------------------------+.+---------+-----------+---------------------------+----------------------------------------------------------------+.+-----------+---------+
| Projection_14 |.| 1 | root | | time:1.39ms, loops:2, RU:1.561975, Concurrency:OFF |.| 9.64 KB | N/A |
| └─StreamAgg_16 |.| 1 | root | | time:1.39ms, loops:2 |.| 1.46 KB | N/A |
| └─Projection_40 |.| 4 | root | | time:1.38ms, loops:4, Concurrency:OFF |.| 8.24 KB | N/A |
| └─HashAgg_17 |.| 4 | root | | time:1.36ms, loops:4, partial_worker:{...}, final_worker:{...} |.| 82.1 KB | N/A |
| └─HashJoin_19 |.| 25 | root | | time:1.29ms, loops:2, build_hash_table:{...}, probe:{...} |.| 2.25 KB | 0 Bytes |
| ├─HashJoin_35(Build) |.| 4 | root | | time:1.08ms, loops:2, build_hash_table:{...}, probe:{...} |.| 25.7 KB | 0 Bytes |
| │ ├─IndexReader_39(Build) |.| 1 | root | | time:888.5µs, loops:2, cop_task: {...} |.| 286 Bytes | N/A |
| │ │ └─IndexRangeScan_38 |.| 1 | cop[tikv] | table:c, index:name(name) | tikv_task:{time:0s, loops:1}, scan_detail: {...} |.| N/A | N/A |
| │ └─TableReader_37(Probe) |.| 10 | root | | time:543.7µs, loops:2, cop_task: {...} |.| 577 Bytes | N/A |
| │ └─TableFullScan_36 |.| 10 | cop[tikv] | table:p | tikv_task:{time:0s, loops:1}, scan_detail: {...} |.| N/A | N/A |
| └─TableReader_22(Probe) |.| 28 | root | | time:671.7µs, loops:2, cop_task: {...} |.| 876 Bytes | N/A |
| └─TableFullScan_21 |.| 28 | cop[tikv] | table:m | tikv_task:{time:0s, loops:1}, scan_detail: {...} |.| N/A | N/A |
+-----------------------------------------+.+---------+-----------+---------------------------+----------------------------------------------------------------+.+-----------+---------+
実行プランの読み取り: 最初の子を先頭とする
遅いSQLクエリを診断するには、実行プランの読み方を理解する必要があります。重要な原則は「最初の子が先 – 再帰降下」です。プラン内の各演算子は行セットを生成し、実行順序によってこれらの行がプランツリー内をどのように流れるかが決まります。
「最初の子が先」ルールとは、演算子が出力を生成する前に、すべての子演算子から行を取得する必要があることを意味します。例えば、結合演算子は結合を実行するために、両方の子演算子から行を取得する必要があります。「再帰下降」ルールとは、各演算子が子演算子の出力に依存するため、実際のデータは下から上へと流れるものの、プランは上から下へと分析することを意味します。
実行プランを読むときは、次の 2 つの重要な概念を考慮してください。
親子相互作用:親演算子は子演算子を順番に呼び出しますが、複数回循環して実行される場合もあります。例えば、インデックス検索やネストループ結合では、親演算子は最初の子演算子から行のバッチを取得し、次に2番目の子演算子から0行以上の行を取得します。このプロセスは、最初の子演算子の結果セットが完全に処理されるまで繰り返されます。
ブロッキング演算子と非ブロッキング演算子: 演算子はブロッキングまたは非ブロッキングのいずれかになります。
TopNやHashAggなどのブロッキング演算子は、データを親に渡す前に結果セット全体を作成する必要があります。IndexLookupやIndexJoinなどの非ブロッキング演算子は、必要に応じて行を段階的に生成して渡します。
実行計画を読む際は、上から下に向かって読み進めてください。次の例では、計画ツリーのリーフノードはTableFullScan_18で、テーブル全体のスキャンを実行します。このスキャンで得られた行はSelection_19演算子によって使用され、 ge(trips.start_date, 2017-07-01 00:00:00.000000), le(trips.start_date, 2017-07-01 23:59:59.000000)に基づいてデータがフィルタリングされます。その後、 group-by 演算子StreamAgg_9によって最終的な集計COUNT(*)実行されます。
これらの3つの演算子( TableFullScan_18 ) Selection_19 TiKV( StreamAgg_9でcop[tikv] )にプッシュダウンされ、TiKVでの早期フィルタリングと集計が可能になり、TiKVとTiDB間のデータ転送が削減されます。最後に、 TableReader_21 StreamAgg_9からデータを読み取り、 StreamAgg_20最終的な集計count(*)実行します。
EXPLAIN SELECT COUNT(*) FROM trips WHERE start_date BETWEEN '2017-07-01 00:00:00' AND '2017-07-01 23:59:59';
+--------------------------+-------------+--------------+-------------------+----------------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+--------------------------+-------------+--------------+-------------------+----------------------------------------------------------------------------------------------------+
| StreamAgg_20 | 1.00 | root | | funcs:count(Column#13)->Column#11 |
| └─TableReader_21 | 1.00 | root | | data:StreamAgg_9 |
| └─StreamAgg_9 | 1.00 | cop[tikv] | | funcs:count(1)->Column#13 |
| └─Selection_19 | 250.00 | cop[tikv] | | ge(trips.start_date, 2017-07-01 00:00:00.000000), le(trips.start_date, 2017-07-01 23:59:59.000000) |
| └─TableFullScan_18 | 10000.00 | cop[tikv] | table:trips | keep order:false, stats:pseudo |
+--------------------------+-------------+--------------+-------------------+----------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)
次の例では、プランツリーの最初のリーフノードであるIndexRangeScan_47調べることから始めます。オプティマイザは、 starsテーブルからnameとid列のみを選択します。これらの列はname(name)インデックスから取得できます。その結果、 starsのルートリーダーはIndexReader_48ではなくTableReaderなります。
starsとplanetsの結合はハッシュ結合です( HashJoin_44 )。7 planetsテーブルはフルテーブルスキャン( TableFullScan_45 )を使用してアクセスされます。結合後、 TopN_26とTopN_19それぞれORDER BYとLIMIT句を適用します。最後の演算子Projection_16 、最後の列t5.name選択します。
EXPLAIN
SELECT t5.name
FROM (
SELECT p.name, p.gravity, p.distance_from_sun
FROM universe.planets p
JOIN universe.stars s
ON s.id = p.sun_id
AND s.name = 'Sun'
ORDER BY p.distance_from_sun ASC
LIMIT 5
) t5
ORDER BY t5.gravity DESC
LIMIT 3;
+-----------------------------------+----------+-----------+---------------------------+
| id | estRows | task | access object |
+-----------------------------------+----------+-----------+---------------------------+
| Projection_16 | 3.00 | root | |
| └─TopN_19 | 3.00 | root | |
| └─TopN_26 | 5.00 | root | |
| └─HashJoin_44 | 5.00 | root | |
| ├─IndexReader_48(Build) | 1.00 | root | |
| │ └─IndexRangeScan_47 | 1.00 | cop[tikv] | table:s, index:name(name) |
| └─TableReader_46(Probe) | 10.00 | root | |
| └─TableFullScan_45 | 10.00 | cop[tikv] | table:p |
+-----------------------------------+----------+-----------+---------------------------+
次の図は、2 番目の実行プランのプラン ツリーを示しています。
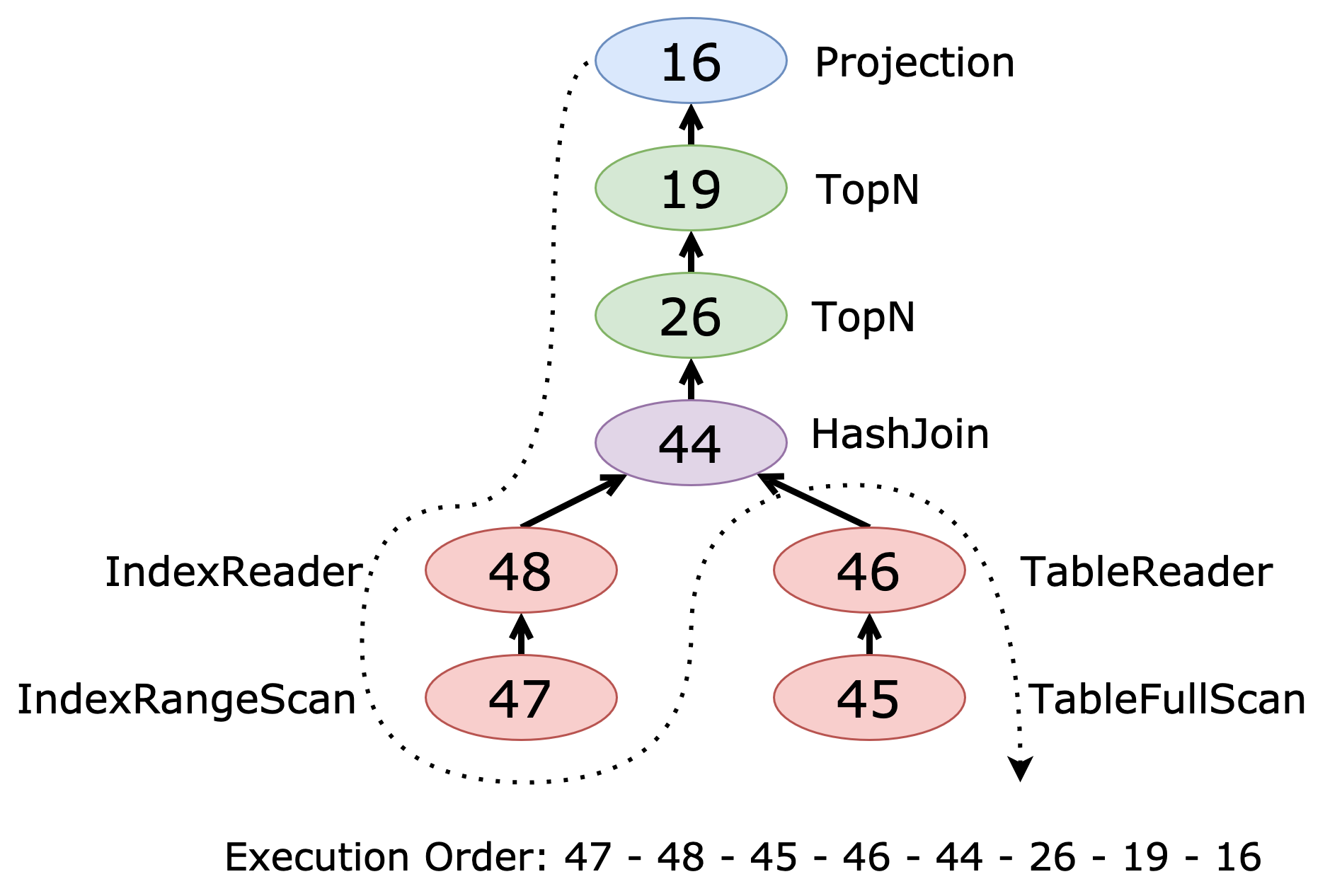
実行プランは、プラン ツリーの後方順序のトラバーサル (左、右、ルート) に対応する、上から下への、最初の子を先頭とするトラバーサルに従います。
この計画は次の順序で読むことができます。
- 一番上から
Projection_16から始めます。 - その子
TopN_19に移動します。 TopN_26に進みます。HashJoin_44に進みます。HashJoin_44の場合、その左側の (Build) 子を最初に処理します。IndexReader_48IndexRangeScan_47
HashJoin_44の場合、その右側の(プローブ)子を処理します。TableReader_46TableFullScan_45
このトラバーサルにより、各演算子の入力が演算子自体の前に処理され、効率的なクエリ実行が可能になります。
実行計画のボトルネックを特定する
実行プランを分析する際は、 actRows (実際の行数)とestRows (推定行数)を比較して、オプティマイザの推定値の精度を評価します。これらの値に大きな差がある場合は、統計情報が古くなっているか不正確である可能性があり、クエリプランが最適ではない可能性があります。
遅いクエリのボトルネックを特定するには、次の手順を実行します。
- 実行時間が長い演算子に焦点を当てて、セクション
execution info上から下まで確認します。 - かなりの時間を消費する最初の子演算子の場合:
- 推定精度を評価するには、
actRowsとestRowsを比較します。 - 実行時間の長さやその他のメトリックなど、
execution infoの詳細なメトリックを分析します。 - 潜在的なリソース制約について、
memoryとdisk使用状況を確認します。
- 推定精度を評価するには、
- これらの要因を相関させることで、パフォーマンス問題の根本原因を特定できます。例えば、
TableFullScan操作でactRowsカウントが高く、execution infoで実行時間が長い場合は、インデックスの作成を検討してください。7HashJoin操作でメモリ使用量と実行時間が高い場合は、結合順序を最適化するか、別の結合方法を使用することを検討してください。
以下の実行プランでは、クエリは5分51秒間実行された後、キャンセルされます。主な問題点は次のとおりです。
- 重大な過小評価:最初のリーフノード
IndexReader_76インデックスindex_orders_on_adjustment_id(adjustment_id)からデータを読み取ります。実際の行数(actRows)は256,811,189で、推定された1行(estRows)よりも大幅に多くなっています。 - メモリ オーバーフロー: この過小評価により、ハッシュ結合演算子
HashJoin_69予想よりもはるかに多くのデータを含むハッシュ テーブルを構築し、過剰なメモリ(22.6 GB) とディスク領域 (7.65 GB) を消費します。 - クエリの終了:
0HashJoin_69の演算子の値がactRowsの場合、1は一致する行がないか、リソース制約によりクエリが終了したことを示します。この場合、ハッシュ結合はメモリを過剰に消費し、メモリ制御メカニズムがトリガーされてクエリが終了します。 - 結合順序が正しくありません: この非効率的な計画の根本的な原因は、
estRowsIndexRangeScan_75に対して大幅に過小評価していることであり、オプティマイザーが誤った結合順序を選択することになります。
これらの問題に対処するには、特にordersテーブルとindex_orders_on_adjustment_idインデックスのテーブル統計が最新であることを確認します。
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------...----------------------+
| id | estRows | estCost | actRows | task | access object | execution info ...| memory | disk |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------...----------------------+
| TopN_19 | 1.01 | 461374372.63 | 0 | root | | time:5m51.1s, l...| 0 Bytes | 0 Bytes |
| └─IndexJoin_32 | 1.01 | 460915067.45 | 0 | root | | time:5m51.1s, l...| 0 Bytes | N/A |
| ├─HashJoin_69(Build) | 1.01 | 460913065.41 | 0 | root | | time:5m51.1s, l...| 21.6 GB | 7.65 GB |
| │ ├─IndexReader_76(Build) | 1.00 | 18.80 | 256805045 | root | | time:1m4.1s, lo...| 12.4 MB | N/A |
| │ │ └─IndexRangeScan_75 | 1.00 | 186.74 | 256811189 | cop[tikv] | table:orders, index:index_orders_on_adjustment_id(adjustment_id) | tikv_task:{proc...| N/A | N/A |
| │ └─Projection_74(Probe) | 30652.93 | 460299612.60 | 1024 | root | | time:1.08s, loo...| 413.4 KB | N/A |
| │ └─IndexLookUp_73 | 30652.93 | 460287375.95 | 6144 | root | partition:all | time:1.08s, loo...| 107.8 MB | N/A |
| │ ├─IndexRangeScan_70(Build) | 234759.64 | 53362737.50 | 390699 | cop[tikv] | table:rates, index:index_rates_on_label_id(label_id) | time:29.6ms, lo...| N/A | N/A |
| │ └─Selection_72(Probe) | 30652.93 | 110373973.91 | 187070 | cop[tikv] | | time:36.8s, loo...| N/A | N/A |
| │ └─TableRowIDScan_71 | 234759.64 | 86944962.10 | 390699 | cop[tikv] | table:rates | tikv_task:{proc...| N/A | N/A |
| └─TableReader_28(Probe) | 0.00 | 43.64 | 0 | root | | ...| N/A | N/A |
| └─Selection_27 | 0.00 | 653.96 | 0 | cop[tikv] | | ...| N/A | N/A |
| └─TableRangeScan_26 | 1.01 | 454.36 | 0 | cop[tikv] | table:labels | ...| N/A | N/A |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------...----------------------+
以下の実行プランは、テーブルordersの誤った推定値を修正した後の期待される結果を示しています。クエリの実行時間は1.96秒となり、以前の5分51秒から大幅に改善されました。
- 正確な推定:
estRows値がactRowsほぼ一致するようになりました。これは、統計が更新され、より正確であることを示しています。 - 効率的な結合順序:クエリは
labelsのテーブルでTableReader、ratesテーブルでIndexJoin、そしてordersテーブルでIndexJoinと続きます。この結合順序は、実際のデータ分布に合わせてより効率的に機能します。 - メモリオーバーフローなし: 前のプランとは異なり、この実行では過剰なメモリまたはディスク使用量の兆候は見られず、クエリが予想されるリソース制限内で実行されていることを示しています。
この最適化されたプランは、クエリパフォーマンスにおける正確な統計と適切な結合順序の重要性を示しています。実行時間の短縮(351秒から1.96秒)は、推定エラーへの対処による効果を示しています。
+---------------------------------------+----------+---------+-----------+----------------------------------------------------------------------------------------+---------------...+----------+------+
| id | estRows | actRows | task | access object | execution info...| memory | disk |
+---------------------------------------+----------+---------+-----------+----------------------------------------------------------------------------------------+---------------...+----------+------+
| Limit_24 | 1000.00 | 1000 | root | | time:1.96s, lo...| N/A | N/A |
| └─IndexJoin_88 | 1000.00 | 1000 | root | | time:1.96s, lo...| 1.32 MB | N/A |
| ├─IndexJoin_99(Build) | 1000.00 | 2458 | root | | time:1.96s, lo...| 77.7 MB | N/A |
| │ ├─TableReader_109(Build) | 6505.62 | 158728 | root | | time:1.26s, lo...| 297.0 MB | N/A |
| │ │ └─Selection_108 | 6505.62 | 171583 | cop[tikv] | | tikv_task:{pro...| N/A | N/A |
| │ │ └─TableRangeScan_107 | 80396.43 | 179616 | cop[tikv] | table:labels | tikv_task:{pro...| N/A | N/A |
| │ └─Projection_98(Probe) | 1000.00 | 2458 | root | | time:2.13s, lo...| 59.2 KB | N/A |
| │ └─IndexLookUp_97 | 1000.00 | 2458 | root | partition:all | time:2.13s, lo...| 1.20 MB | N/A |
| │ ├─Selection_95(Build) | 6517.14 | 6481 | cop[tikv] | | time:798.6ms, ...| N/A | N/A |
| │ │ └─IndexRangeScan_93 | 6517.14 | 6481 | cop[tikv] | table:rates, index:index_rates_on_label_id(label_id) | tikv_task:{pro...| N/A | N/A |
| │ └─Selection_96(Probe) | 1000.00 | 2458 | cop[tikv] | | time:444.4ms, ...| N/A | N/A |
| │ └─TableRowIDScan_94 | 6517.14 | 6481 | cop[tikv] | table:rates | tikv_task:{pro...| N/A | N/A |
| └─TableReader_84(Probe) | 984.56 | 1998 | root | | time:207.6ms, ...| N/A | N/A |
| └─Selection_83 | 984.56 | 1998 | cop[tikv] | | tikv_task:{pro...| N/A | N/A |
| └─TableRangeScan_82 | 1000.00 | 2048 | cop[tikv] | table:orders | tikv_task:{pro...| N/A | N/A |
+---------------------------------------+----------+---------+-----------+----------------------------------------------------------------------------------------+---------------...+----------+------+
詳細については、 TiDB クエリ実行プランの概要およびEXPLAINウォークスルー参照してください。
TiDBのインデックス戦略
TiDBは、SQLレイヤー(TiDBサーバー)とstorageレイヤー(TiKV)を分離した分散SQLデータベースです。従来のデータベースとは異なり、TiDBは計算ノードにデータをキャッシュするためにバッファプールを使用しません。そのため、SQLクエリのパフォーマンスとクラスタ全体のパフォーマンスは、処理が必要なキーバリュー(KV)RPCリクエストの数に依存します。一般的なKV RPCリクエストには、 Point_Get 、およびコプロセッサーBatch_Point_Getあります。
TiDBのパフォーマンスを最適化するには、インデックスを効果的に使用することが不可欠です。インデックスはKV RPCリクエストの数を大幅に削減できるためです。KV RPCリクエストが減ることで、クエリのパフォーマンスとシステム効率が向上します。以下に、インデックスの最適化に役立つ主要な戦略をいくつか示します。
- テーブル全体のスキャンを避けてください。
- ソート操作を避けてください。
- 行の検索を減らすには、カバーリング インデックスを使用するか、不要な列を除外します。
このセクションでは、一般的なインデックス戦略とインデックスコストについて説明します。また、TiDBにおける効果的なインデックス構築の実例を3つ紹介し、特にSQLチューニングのための複合インデックスとカバーリングインデックスに焦点を当てます。
複合指数戦略ガイドライン
効率的な複合インデックスを作成するには、列を戦略的に順序付けます。列の順序は、インデックスによるデータのフィルタリングと並べ替えの効率に直接影響します。
複合インデックスの場合は、次の推奨列順序ガイドラインに従ってください。
直接アクセスするには、インデックス プレフィックス列から始めます。
- 同等の条件を持つ列
- 条件が
IS NULLある列 IN条件に1つの値(例:IN (1)が含まれる列
次に並べ替え用の列を追加します。
- インデックスでソート操作を処理できるようにする
- ソートを有効にして TiKV へのプッシュダウンを制限する
- ソート順を維持する
行の検索を減らすために追加のフィルタリング列を含めます。
- 複数の値を持つ条件は
IN - 日付時刻列の時間範囲条件
!=<>の他の非IS NOT NULLのNOT IN
- 複数の値を持つ条件は
カバーインデックスを最大限に活用するには、
SELECTリストから列を追加するか、集計に使用します。
特別な考慮: IN条件
複合インデックスを設計する場合、 IN条件を慎重に処理する必要があります。
- 単一の値: 単一の値 (
IN (1)など) を持つIN句は等価条件と同様に機能し、インデックスの先頭に配置できます。 - 複数の値:複数の値を持つ
IN句は複数の範囲を生成します。このような列をソートに使用する列の前に置くと、ソート順序が崩れる可能性があります。ソート順序を維持するには、複合インデックスにおいて、ソートに使用する列を複数値条件を持つIN列の前に置くようにしてください。
インデックス作成のコスト
インデックスによりクエリのパフォーマンスは向上しますが、考慮すべきコストも発生します。
書き込み時のパフォーマンスへの影響:
- 非クラスター化インデックスを使用すると、シングルフェーズコミットの最適化の可能性が低くなります。
- 追加のインデックスごと
DELETE書き込み操作が遅くなります (INSERTなど)UPDATE - データが変更された場合は、影響を受けるすべてのインデックスを更新する必要があります。
- テーブルに含まれるインデックスの数が増えるほど、書き込みパフォーマンスへの影響が大きくなります。
リソース消費:
- インデックスには追加のディスク領域が必要です。
- 頻繁にアクセスされるインデックスをキャッシュするには、より多くのメモリが必要です。
- バックアップおよびリカバリ操作に時間がかかります。
ホットスポットリスクを記述します:
- セカンダリインデックスは書き込みホットスポットを引き起こす可能性があります。例えば、単調に増加する日付時刻インデックスは、テーブルへの書き込み時にホットスポットを引き起こします。
- ホットスポットはパフォーマンスの大幅な低下につながる可能性があります。
以下にいくつかのベストプラクティスを示します。
- パフォーマンス上の明らかな利点がある場合にのみインデックスを作成します。
TIDB_INDEX_USAGE使用してインデックスの使用状況統計を定期的に確認します。- インデックスを設計するときは、ワークロードの書き込み/読み取り比率を考慮してください。
カバーインデックスを使用したSQLチューニング
カバリングインデックスには、 WHEREとSELECT節で参照されるすべての列が含まれます。カバリングインデックスを使用すると、追加のインデックス参照が不要になり、クエリのパフォーマンスが大幅に向上します。
次のクエリは2,597,411行のインデックス検索を必要とし、実行に46.4秒かかります。TiDBはlogs_idxインデックス範囲スキャンに67のcopタスク( IndexRangeScan_11 )を、テーブルアクセスに301のcopタスク( TableRowIDScan_12 )をディスパッチします。
SELECT
SUM(`logs`.`amount`)
FROM
`logs`
WHERE
`logs`.`user_id` = 1111
AND `logs`.`snapshot_id` IS NULL
AND `logs`.`status` IN ('complete', 'failure')
AND `logs`.`source_type` != 'online'
AND (
`logs`.`source_type` IN ('user', 'payment')
OR `logs`.`source_type` IN (
'bank_account',
)
AND `logs`.`target_type` IN ('bank_account')
);
元の実行プランは次のとおりです。
+-------------------------------+------------+---------+-----------+--------------------------------------------------------------------------+------------------------------------------------------------+
| id | estRows | actRows | task | access object | execution info |
+-------------------------------+------------+---------+-----------+--------------------------------------------------------------------------+------------------------------------------------------------+
| HashAgg_18 | 1.00 | 2571625.22 | 1 | root | | time:46.4s, loops:2, partial_worker:{wall_time:46.37, ...|
| └─IndexLookUp_19 | 1.00 | 2570096.68 | 301 | root | | time:46.4s, loops:2, index_task: {total_time: 45.8s, ...|
| ├─IndexRangeScan_11(Build) | 1309.50 | 317033.98 | 2597411 | cop[tikv] | table:logs, index:logs_idx(snapshot_id, user_id, status) | time:228ms, loops:2547, cop_task: {num: 67, max: 2.17s, ...|
| └─HashAgg_7(Probe) | 1.00 | 588434.48 | 301 | cop[tikv] | | time:3m46.7s, loops:260, cop_task: {num: 301, ...|
| └─Selection_13 | 1271.37 | 561549.27 | 2566562 | cop[tikv] | | tikv_task:{proc max:10s, min:0s, avg: 915.3ms, ...|
| └─TableRowIDScan_12 | 1309.50 | 430861.31 | 2597411 | cop[tikv] | table:logs | tikv_task:{proc max:10s, min:0s, avg: 908.7ms, ...|
+-------------------------------+------------+---------+-----------+--------------------------------------------------------------------------+------------------------------------------------------------+
クエリのパフォーマンスを向上させるには、 source_type 、 target_type 、 amount列を含むカバーリングインデックスを作成します。この最適化により、追加のテーブル参照が不要になり、実行時間が90ミリ秒に短縮されます。TiDBはデータスキャンのためにTiKVに1つのcopタスクを送信するだけで済みます。
インデックスを作成したら、 ANALYZE TABLEステートメントを実行して統計情報を収集します。TiDBでは、インデックスを作成しても統計は自動的に更新されないため、テーブルを分析することで、オプティマイザーが新しいインデックスを選択するようになります。
CREATE INDEX logs_covered ON logs(snapshot_id, user_id, status, source_type, target_type, amount);
ANALYZE TABLE logs INDEX logs_covered;
新しい実行プランは次のとおりです。
+-------------------------------+------------+---------+-----------+---------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------+
| id | estRows | actRows | task | access object | execution info |
+-------------------------------+------------+---------+-----------+---------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------+
| HashAgg_13 | 1.00 | 1 | root | | time:90ms, loops:2, RU:158.885311, ...|
| └─IndexReader_14 | 1.00 | 1 | root | | time:89.8ms, loops:2, cop_task: {num: 1, ...|
| └─HashAgg_6 | 1.00 | 1 | cop[tikv] | | tikv_task:{time:88ms, loops:52}, ...|
| └─Selection_12 | 5245632.33 | 52863 | cop[tikv] | | tikv_task:{time:80ms, loops:52} ...|
| └─IndexRangeScan_11 | 5245632.33 | 52863 | cop[tikv] | table:logs, index:logs_covered(snapshot_id, user_id, status, source_type, target_type, amount) | tikv_task:{time:60ms, loops:52} ...|
+-------------------------------+------------+---------+-----------+---------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------+
ソートを含む複合インデックスを使用したSQLチューニング
フィルタリング列とソート列の両方を含む複合インデックスを作成することで、 ORDER BY句を含むクエリを最適化できます。このアプローチにより、TiDBは必要な順序を維持しながら効率的にデータにアクセスできるようになります。
たとえば、特定の条件に基づいてtestからデータを取得する次のクエリを考えます。
EXPLAIN ANALYZE SELECT
test.*
FROM
test
WHERE
test.snapshot_id = 459840
AND test.id > 998464
ORDER BY
test.id ASC
LIMIT
1000
実行プランには170ミリ秒の期間が表示されています。TiDBはtest_index使用して、フィルターsnapshot_id = 459840でIndexRangeScan_20実行します。次に、テーブルからすべての列を取得し、 IndexLookUp_23後に5,715行をTiDBに返します。TiDBはこれらの行をソートし、1,000行を返します。
列idは主キーであるため、暗黙的にインデックスtest_idxに含まれます。ただし、 IndexRangeScan_20順序を保証しません。これは、列test_idxはインデックスプレフィックス列snapshot_id後に 2 つの追加列( user_idとstatus )が含まれているためです。その結果、列idの順序は保持されません。
当初の計画は次のとおりです。
+------------------------------+---------+---------+-----------+----------------------------------------------------------+-----------------------------------------------+--------------------------------------------+
| id | estRows | actRows | task | access object | execution info | operator info |
+------------------------------+---------+---------+-----------+----------------------------------------------------------+-----------------------------------------------+--------------------------------------------+
| id | estRows | actRows | task | access object | execution info ...| test.id, offset:0, count:1000 |
| TopN_10 | 19.98 | 1000 | root | | time:170.6ms, loops:2 ...| |
| └─IndexLookUp_23 | 19.98 | 5715 | root | | time:166.6ms, loops:7 ...| |
| ├─Selection_22(Build) | 19.98 | 5715 | cop[tikv] | | time:18.6ms, loops:9, cop_task: {num: 3, ...| gt(test.id, 998464) |
| │ └─IndexRangeScan_20 | 433.47 | 7715 | cop[tikv] | table:test, index:test_idx(snapshot_id, user_id, status) | tikv_task:{proc max:4ms, min:4ms, avg: 4ms ...| range:[459840,459840], keep order:false |
| └─TableRowIDScan_21(Probe) | 19.98 | 5715 | cop[tikv] | table:test | time:301.6ms, loops:10, cop_task: {num: 3, ...| keep order:false |
+------------------------------+---------+---------+-----------+----------------------------------------------------------+-----------------------------------------------+--------------------------------------------+
クエリを最適化するには、 (snapshot_id)に新しいインデックスを作成します。これにより、 id各snapshot_idグループ内でソートされるようになります。このインデックスにより、実行時間は96ミリ秒に短縮されます。 IndexRangeScan_33のkeep orderプロパティはtrueになり、 TopN Limitに置き換えられます。その結果、 IndexLookUp_35 TiDBに1,000行のみを返すため、追加のソート操作は不要になります。
以下は、最適化されたインデックスを含むクエリ ステートメントです。
CREATE INDEX test_new ON test(snapshot_id);
ANALYZE TABLE test INDEX test_new;
新しい計画は次のとおりです。
+----------------------------------+---------+---------+-----------+----------------------------------------------+----------------------------------------------+----------------------------------------------------+
| id | estRows | actRows | task | access object | execution info | operator info |
+----------------------------------+---------+---------+-----------+----------------------------------------------+----------------------------------------------+----------------------------------------------------+
| Limit_14 | 17.59 | 1000 | root | | time:96.1ms, loops:2, RU:92.300155 | offset:0, count:1000 |
| └─IndexLookUp_35 | 17.59 | 1000 | root | | time:96.1ms, loops:1, index_task: ...| |
| ├─IndexRangeScan_33(Build) | 17.59 | 5715 | cop[tikv] | table:test, index:test_new(snapshot_id) | time:7.25ms, loops:8, cop_task: {num: 3, ...| range:(459840 998464,459840 +inf], keep order:true |
| └─TableRowIDScan_34(Probe) | 17.59 | 5715 | cop[tikv] | table:test | time:232.9ms, loops:9, cop_task: {num: 3, ...| keep order:false |
+----------------------------------+---------+---------+-----------+----------------------------------------------+----------------------------------------------+----------------------------------------------------+
効率的なフィルタリングとソートのための複合インデックスを使用したSQLチューニング
以下のクエリの実行には11分9秒かかります。これは、101行しか返さないクエリとしては長すぎます。パフォーマンスの低下には、いくつかの要因が考えられます。
- 非効率的なインデックスの使用: オプティマイザーは
created_atのインデックスを選択し、結果として 25,147,450 行がスキャンされます。 - 大きな中間結果セット: 日付範囲フィルターを適用した後も、12,082,311 行の処理が必要です。
- 遅延フィルタリング: テーブルにアクセスした後、最も選択的な述語
(mode, user_id, and label_id)適用され、結果は 16,604 行になります。 - ソートのオーバーヘッド: 16,604 行の最終ソート操作により、追加の処理時間が発生します。
クエリステートメントは次のとおりです。
SELECT `orders`.*
FROM `orders`
WHERE
`orders`.`mode` = 'production'
AND `orders`.`user_id` = 11111
AND orders.label_id IS NOT NULL
AND orders.created_at >= '2024-04-07 18:07:52'
AND orders.created_at <= '2024-05-11 18:07:52'
AND orders.id >= 1000000000
AND orders.id < 1500000000
ORDER BY orders.id DESC
LIMIT 101;
ordersの既存のインデックスは次のとおりです。
PRIMARY KEY (`id`),
UNIQUE KEY `index_orders_on_adjustment_id` (`adjustment_id`),
KEY `index_orders_on_user_id` (`user_id`),
KEY `index_orders_on_label_id` (`label_id`),
KEY `index_orders_on_created_at` (`created_at`)
元の実行プランは次のとおりです。
+--------------------------------+-----------+---------+-----------+--------------------------------------------------------------------------------+-----------------------------------------------------+----------------------------------------------------------------------------------------+----------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+--------------------------------+-----------+---------+-----------+--------------------------------------------------------------------------------+-----------------------------------------------------+----------------------------------------------------------------------------------------+----------+------+
| TopN_10 | 101.00 | 101 | root | | time:11m9.8s, loops:2 | orders.id:desc, offset:0, count:101 | 271 KB | N/A |
| └─IndexLookUp_39 | 173.83 | 16604 | root | | time:11m9.8s, loops:19, index_task: {total_time:...}| | 20.4 MB | N/A |
| ├─Selection_37(Build) | 8296.70 | 12082311| cop[tikv] | | time:26.4ms, loops:11834, cop_task: {num: 294, m...}| ge(orders.id, 1000000000), lt(orders.id, 1500000000) | N/A | N/A |
| │ └─IndexRangeScan_35 | 6934161.90| 25147450| cop[tikv] | table:orders, index:index_orders_on_created_at(created_at) | tikv_task:{proc max:2.15s, min:0s, avg: 58.9ms, ...}| range:[2024-04-07 18:07:52,2024-05-11 18:07:52), keep order:false | N/A | N/A |
| └─Selection_38(Probe) | 173.83 | 16604 | cop[tikv] | | time:54m46.2s, loops:651, cop_task: {num: 1076, ...}| eq(orders.mode, "production"), eq(orders.user_id, 11111), not(isnull(orders.label_id)) | N/A | N/A |
| └─TableRowIDScan_36 | 8296.70 | 12082311| cop[tikv] | table:orders | tikv_task:{proc max:44.8s, min:0s, avg: 3.33s, p...}| keep order:false | N/A | N/A |
+--------------------------------+-----------+---------+-----------+--------------------------------------------------------------------------------+-----------------------------------------------------+----------------------------------------------------------------------------------------+----------+------+
orders(user_id, mode, id, created_at, label_id)に複合インデックスidx_compositeを作成すると、クエリのパフォーマンスが大幅に向上します。実行時間は11分9秒からわずか5.3ミリ秒に短縮され、クエリは126,000倍以上高速化します。この大幅な改善は、以下の要因によるものです。
- 効率的なインデックスの使用:新しいインデックスにより、最も選択性の高い述語である
user_id、mode、idに対するインデックス範囲スキャンが可能になります。これにより、スキャンされる行数が数百万行からわずか224行に削減されます。 - インデックスのみのソート: 実行プランの
keep order:true、ソートがインデックス構造を使用して実行されることを示し、個別のソート操作は不要です。 - 早期フィルタリング: 最も選択的な述語が最初に適用され、さらにフィルタリングされる前に結果セットが 224 行に削減されます。
- 制限プッシュダウン:
LIMIT句がインデックス スキャンにプッシュダウンされ、101 行が見つかった時点でスキャンを早期に終了できるようになります。
この事例は、適切に設計されたインデックスがクエリのパフォーマンスに大きく影響することを示しています。インデックス構造をクエリの述語、ソート順、および必要な列と一致させることで、クエリのパフォーマンスは5桁以上向上します。
CREATE INDEX idx_composite ON orders(user_id, mode, id, created_at, label_id);
ANALYZE TABLE orders index idx_composite;
新しい実行プランは次のとおりです。
+--------------------------------+-----------+---------+-----------+--------------------------------------------------------------------------------+-----------------------------------------------------+----------------------------------------------------------------------------------------------------------------------+----------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+--------------------------------+-----------+---------+-----------+--------------------------------------------------------------------------------+-----------------------------------------------------+----------------------------------------------------------------------------------------------------------------------+----------+------+
| IndexLookUp_32 | 101.00 | 101 | root | | time:5.3ms, loops:2, RU:3.435006, index_task: {t...}| limit embedded(offset:0, count:101) | 128.5 KB | N/A |
| ├─Limit_31(Build) | 101.00 | 101 | cop[tikv] | | time:1.35ms, loops:1, cop_task: {num: 1, max: 1....}| offset:0, count:101 | N/A | N/A |
| │ └─Selection_30 | 535.77 | 224 | cop[tikv] | | tikv_task:{time:0s, loops:3} | ge(orders.created_at, 2024-04-07 18:07:52), le(orders.created_at, 2024-05-11 18:07:52), not(isnull(orders.label_id)) | N/A | N/A |
| │ └─IndexRangeScan_28 | 503893.42 | 224 | cop[tikv] | table:orders, index:idx_composite(user_id, mode, id, created_at, label_id) | tikv_task:{time:0s, loops:3} | range:[11111 "production" 1000000000,11111 "production" 1500000000), keep order:true, desc | N/A | N/A |
| └─TableRowIDScan_29(Probe) | 101.00 | 101 | cop[tikv] | table:orders | time:2.9ms, loops:2, cop_task: {num: 3, max: 2.7...}| keep order:false | N/A | N/A |
+--------------------------------+-----------+---------+-----------+--------------------------------------------------------------------------------+-----------------------------------------------------+----------------------------------------------------------------------------------------------------------------------+----------+------+
TiFlashを使用する場合
このセクションでは、TiDBでTiFlashを使用するタイミングについて説明します。TiFlashは、複雑な計算、集計、大規模データセットのスキャンを伴う分析クエリに最適化されています。列指向storage形式とMPPモードにより、これらのシナリオにおけるパフォーマンスが大幅に向上します。
TiFlash は次のシナリオで使用します。
- 大規模データ分析: TiFlashは、大規模なデータスキャンを必要とするOLAPワークロードにおいて、より高速なパフォーマンスを提供します。列指向storageとMPP実行モードにより、TiKVと比較してクエリ効率が最適化されます。
- 複雑なスキャン、集計、結合: TiFlash は、必要な列のみを読み取ることで、集計や結合の負荷が高いクエリをより効率的に処理します。
- 混合ワークロード: トランザクション (OLTP) ワークロードと分析 (OLAP) ワークロードの両方が同時に実行されるハイブリッド環境では、 TiFlash はトランザクション クエリに対する TiKV のパフォーマンスに影響を与えずに分析クエリを処理します。
- 任意のフィルタリング要件を持つSaaSアプリケーション:クエリでは、多くの場合、多数の列にまたがるフィルタリングが必要になります。すべての列にインデックスを付けるのは現実的ではなく、特にテナントIDがクエリの主キーの一部に含まれている場合はなおさらです。TiFlashは主キーに基づいてデータをソートおよびクラスタ化するため、このようなワークロードに最適です。TiFlashの遅い実現機能により、効率的なテーブル範囲スキャンが可能になり、複数のインデックスを維持するオーバーヘッドなしでクエリパフォーマンスが向上します。
TiFlash を戦略的に使用することで、クエリパフォーマンスが向上し、データ集約型の分析クエリにおける TiDB のリソース使用が最適化されます。以下のセクションでは、 TiFlashのユースケース例を紹介します。
分析クエリ
このセクションでは、TiKV およびTiFlashstorageエンジンでの TPC-H クエリ 14 の実行パフォーマンスを比較します。
TPC-Hクエリ14は、テーブルorder_lineとテーブルitem結合を伴います。このクエリはTiKVでは21.1秒かかりますが、 TiFlash MPPモードではわずか1.41秒で実行され、15倍の速度向上が見込まれます。
- TiKVプラン:TiDBはテーブル
lineitemから3,864,397行、テーブルpartから1000万行を取得します。ハッシュ結合演算(HashJoin_21)と、それに続く射影演算(Projection_38)および集計演算(HashAgg_9)はTiDB内で実行されます。 - TiFlashプラン:オプティマイザーは、テーブル数
order_lineとitem両方でTiFlashレプリカを検出します。TiDBはコスト見積もりに基づいて自動的にMPPモードを選択し、クエリ全体をTiFlash列指向storageエンジン内で実行します。これにはテーブルスキャン、ハッシュ結合、列プロジェクション、集計が含まれ、TiKVプランと比較してパフォーマンスが大幅に向上します。
クエリは次のとおりです。
select 100.00 * sum(case when i_data like 'PR%' then ol_amount else 0 end) / (1+sum(ol_amount)) as promo_revenue
from order_line, item
where ol_i_id = i_id and ol_delivery_d >= '2007-01-02 00:00:00.000000' and ol_delivery_d < '2030-01-02 00:00:00.000000';
TiKV での実行プランは次のとおりです。
+-------------------------------+--------------+-----------+-----------+----------------+----------------------------------------------+
| ID | ESTROWS | ACTROWS | TASK | ACCESS OBJECT | EXECUTION INFO |
+-------------------------------+--------------+-----------+-----------+----------------+----------------------------------------------+
| Projection_8 | 1.00 | 1 | root | | time:21.1s, loops:2, RU:1023225.707561, ... |
| └─HashAgg_9 | 1.00 | 1 | root | | time:21.1s, loops:2, partial_worker:{ ... |
| └─Projection_38 | 3839984.46 | 3864397 | root | | time:21.1s, loops:3776, Concurrency:5 |
| └─HashJoin_21 | 3839984.46 | 3864397 | root | | time:21.1s, loops:3776, build_hash_table:... |
| ├─TableReader_24(Build) | 3826762.62 | 3864397 | root | | time:18.4s, loops:3764, cop_task: ... |
| │ └─Selection_23 | 3826762.62 | 3864397 | cop[tikv] | | tikv_task:{proc max:717ms, min:265ms, ... |
| │ └─TableFullScan_22 | 300005811.00 | 300005811 | cop[tikv] | table:lineitem | tikv_task:{proc max:685ms, min:252ms, ... |
| └─TableReader_26(Probe) | 10000000.00 | 10000000 | root | | time:1.29s, loops:9780, cop_task: ... |
| └─TableFullScan_25 | 10000000.00 | 10000000 | cop[tikv] | table:part | tikv_task:{proc max:922ms, min:468ms, ... |
+-------------------------------+--------------+-----------+-----------+----------------+----------------------------------------------+
TiFlash上の実行プランは次のとおりです。
+--------------------------------------------+-------------+----------+--------------+----------------+--------------------------------------+
| ID | ESTROWS | ACTROWS | TASK | ACCESS OBJECT | EXECUTION INFO |
+--------------------------------------------+-------------+----------+--------------+----------------+--------------------------------------+
| Projection_8 | 1.00 | 1 | root | | time:1.41s, loops:2, RU:45879.127909 |
| └─HashAgg_52 | 1.00 | 1 | root | | time:1.41s, loops:2, ... |
| └─TableReader_54 | 1.00 | 1 | root | | time:1.41s, loops:2, ... |
| └─ExchangeSender_53 | 1.00 | 1 | mpp[tiflash] | | tiflash_task:{time:1.41s, ... |
| └─HashAgg_13 | 1.00 | 1 | mpp[tiflash] | | tiflash_task:{time:1.41s, ... |
| └─Projection_74 | 3813443.11 | 3864397 | mpp[tiflash] | | tiflash_task:{time:1.4s, ... |
| └─Projection_51 | 3813443.11 | 3864397 | mpp[tiflash] | | tiflash_task:{time:1.39s, ... |
| └─HashJoin_50 | 3813443.11 | 3864397 | mpp[tiflash] | | tiflash_task:{time:1.39s, ... |
| ├─ExchangeReceiver_31(Build) | 3800312.67 | 3864397 | mpp[tiflash] | | tiflash_task:{time:1.05s, ... |
| │ └─ExchangeSender_30 | 3800312.67 | 3864397 | mpp[tiflash] | | tiflash_task:{time:1.2s, ... |
| │ └─TableFullScan_28 | 3800312.67 | 3864397 | mpp[tiflash] | table:lineitem | tiflash_task:{time:1.15s, ... |
| └─ExchangeReceiver_34(Probe) | 10000000.00 | 10000000 | mpp[tiflash] | | tiflash_task:{time:1.24s, ... |
| └─ExchangeSender_33 | 10000000.00 | 10000000 | mpp[tiflash] | | tiflash_task:{time:1.4s, ... |
| └─TableFullScan_32 | 10000000.00 | 10000000 | mpp[tiflash] | table:part | tiflash_task:{time:59.2ms, ... |
+--------------------------------------------+-------------+----------+--------------+----------------+--------------------------------------+
SaaS 任意フィルタリングワークロード
SaaSアプリケーションでは、テーブルでテナント識別情報を含む複合主キーが使用されることがよくあります。次の例は、 TiFlashがこれらのシナリオにおいてクエリパフォーマンスを大幅に向上させる方法を示しています。
ケーススタディ: マルチテナントデータアクセス
複合主キーを持つテーブルを考えてみましょう: (tenantId, objectTypeId, objectId) 。このテーブルの典型的なクエリパターンは次のとおりです。
- 数百、数千の列にランダムフィルターを適用しながら、特定のテナントとオブジェクトタイプの最初のNレコードを取得します。このため、すべてのフィルターの組み合わせに対してインデックスを作成することは現実的ではありません。クエリには、フィルタリング後の並べ替え操作も含まれる場合があります。
- フィルター条件に一致するレコードの合計数を計算します。
パフォーマンス比較
異なるstorageエンジンで同じクエリを実行すると、パフォーマンスに大きな違いが見られます。
- TiKV プラン: TiKV ではクエリに 2 分 38.6 秒かかります。データが 5,121 のリージョンに分散されているため、
TableRangeScan5,121 の cop タスクが送信されます。 - TiFlashプラン:同じクエリをTiFlash MPPエンジンで実行すると、わずか3.44秒で実行できます。これは約46倍の高速化です。TiFlashはデータを主キーでソートして保存するため、主キーのプレフィックスでフィルタリングされたクエリでは、テーブル全体をスキャンする代わりに
TableRangeScanのタスクで済みます。TiFlashに必要なMPPタスクは、TiKVの5,121タスクと比較してわずか2タスクです。
クエリステートメントは次のとおりです。
WITH `results` AS (
SELECT field1, field2, field3, field4
FROM usertable
where tenantId = 1234 and objectTypeId = 6789
),
`limited_results` AS (
SELECT field1, field2, field3, field4
FROM `results` LIMIT 100
)
SELECT field1, field2, field3, field4
FROM
(
SELECT 100 `__total__`, field1, field2, field3, field4
FROM `limited_results`
UNION ALL
SELECT count(*) `__total__`, field1, field2, field3, field4
FROM `results`
) `result_and_count`;
TiKV での実行プランは次のとおりです。
+--------------------------------+-----------+---------+-----------+-----------------------+-----------------------------------------------------+
| id | estRows | actRows | task | access object | execution info |
+--------------------------------+-----------+---------+-----------+-----------------------+-----------------------------------------------------+
| Union_18 | 101.00 | 101 | root | | time:2m38.6s, loops:3, RU:8662189.451027 |
| ├─Limit_20 | 100.00 | 100 | root | | time:23ms, loops:2 |
| │ └─TableReader_25 | 100.00 | 100 | root | | time:23ms, loops:1, cop_task: {num: 1, max: 22.8...}|
| │ └─Limit_24 | 100.00 | 100 | cop[tikv] | | tikv_task:{time:21ms, loops:3}, scan_detail: {...} |
| │ └─TableRangeScan_22 | 100.00 | 100 | cop[tikv] | table:usertable | tikv_task:{time:21ms, loops:3} |
| └─Projection_26 | 1.00 | 1 | root | | time:2m38.6s, loops:2, Concurrency:OFF |
| └─HashAgg_34 | 1.00 | 1 | root | | time:2m38.6s, loops:2, partial_worker:{...}, fin.. .|
| └─TableReader_35 | 1.00 | 5121 | root | | time:2m38.6s, loops:7, cop_task: {num: 5121, max:...|
| └─HashAgg_27 | 1.00 | 5121 | cop[tikv] | | tikv_task:{proc max:0s, min:0s, avg: 462.8ms, p...} |
| └─TableRangeScan_32 | 10000000 | 10000000| cop[tikv] | table:usertable | tikv_task:{proc max:0s, min:0s, avg: 460.5ms, p...} |
+--------------------------------+-----------+---------+-----------+-----------------------+-----------------------------------------------------+
TiFlash上の実行プランは次のとおりです。
+--------------------------------+-----------+---------+--------------+--------------------+-----------------------------------------------------+
| id | estRows | actRows | task | access object | execution info |
+--------------------------------+-----------+---------+--------------+--------------------+-----------------------------------------------------+
| Union_18 | 101.00 | 101 | root | | time:3.44s, loops:3, RU:0.000000 |
| ├─Limit_22 | 100.00 | 100 | root | | time:146.7ms, loops:2 |
| │ └─TableReader_30 | 100.00 | 100 | root | | time:146.7ms, loops:1, cop_task: {num: 1, max: 0...}|
| │ └─ExchangeSender_29 | 100.00 | 0 | mpp[tiflash] | | |
| │ └─Limit_28 | 100.00 | 0 | mpp[tiflash] | | |
| │ └─TableRangeScan_27 | 100.00 | 0 | mpp[tiflash] | table:usertable | |
| └─Projection_31 | 1.00 | 1 | root | | time:3.42s, loops:2, Concurrency:OFF |
| └─HashAgg_49 | 1.00 | 1 | root | | time:3.42s, loops:2, partial_worker:{...}, fin... |
| └─TableReader_51 | 1.00 | 2 | root | | time:3.42s, loops:2, cop_task: {num: 4, max: 0...} |
| └─ExchangeSender_50 | 1.00 | 2 | mpp[tiflash] | | tiflash_task:{proc max:3.4s, min:3.15s, avg: 3...} |
| └─HashAgg_36 | 1.00 | 2 | mpp[tiflash] | | tiflash_task:{proc max:3.4s, min:3.15s, avg: 3...} |
| └─TableRangeScan_48 | 10000000 | 10000000| mpp[tiflash] | table:usertable | tiflash_task:{proc max:3.4s, min:3.15s, avg: 3...} |
+--------------------------------+-----------+---------+--------------+--------------------+-----------------------------------------------------+
TiKVとTiFlash間のクエリルーティング
大量のマルチテナント データを持つテーブルに対してTiFlashレプリカを有効にすると、オプティマイザーは行数に基づいてクエリを TiKV またはTiFlashのいずれかにルーティングします。
- 小規模テナント: TiKV は、テーブル範囲スキャンによる小規模クエリに高い同時実行性を提供するため、データ サイズが小さいテナントに適しています。
- 大規模テナント: 大規模なデータセット (この場合は 1,000 万行など) を持つテナントの場合、 TiFlash は次の利点により効率的です。
- TiFlash は、特定のインデックスを必要とせずに動的なフィルタリング条件を処理します。
- TiDB は、
COUNT、SORT、LIMIT操作をTiFlashにプッシュダウンできます。 - TiFlash は、列指向storageを使用して必要な列のみをスキャンします。