TiDB スナップショットのバックアップと復元のアーキテクチャ
このドキュメントでは、バックアップとリストア ( BR ) ツールを例として、TiDB スナップショットのバックアップとリストアのアーキテクチャとプロセスについて説明します。
アーキテクチャ
TiDB スナップショットのバックアップと復元のアーキテクチャは次のとおりです。
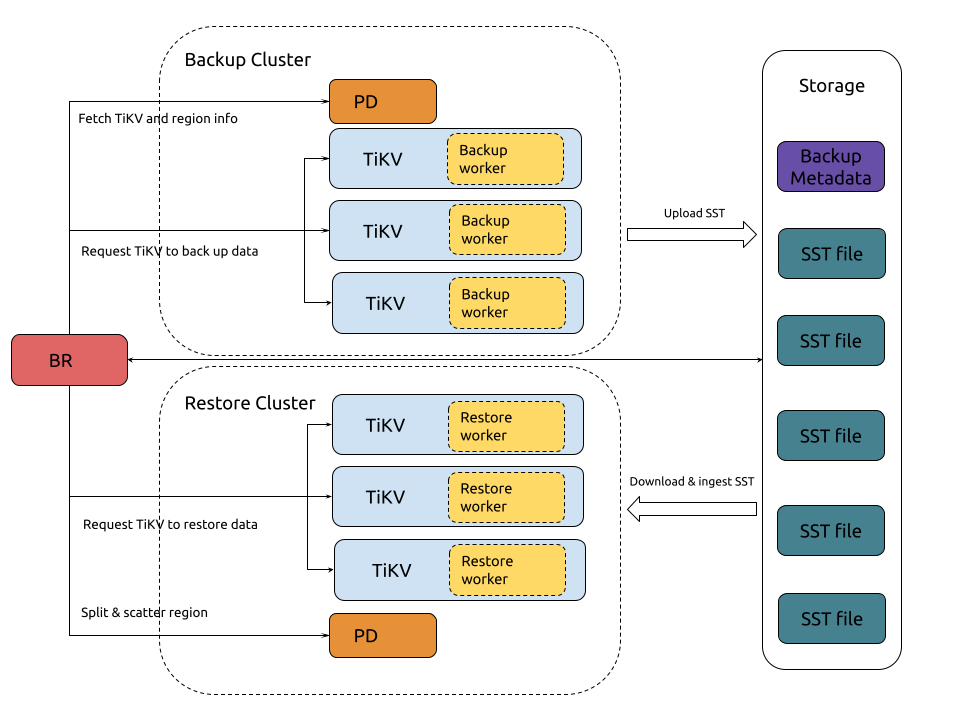
バックアップのプロセス
クラスター スナップショット バックアップのプロセスは次のとおりです。
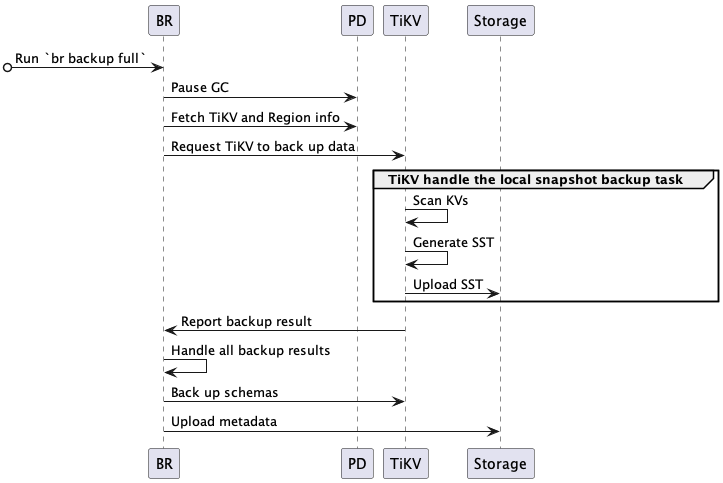
完全なバックアッププロセスは次のとおりです。
BRは
br backup fullコマンドを受信します。- バックアップの時点とstorageパスを取得します。
BR はバックアップ データをスケジュールします。
- GC を一時停止: BR は、バックアップ データがTiDB GCメカニズムまでにクリーンアップされないように TiDB GC 時間を設定します。
- TiKV およびリージョン情報を取得する: BR はPD にアクセスして、すべての TiKV ノードのアドレスとリージョンデータ分布を取得します。
- TiKVにデータのバックアップをリクエスト: BRはバックアップリクエストを作成し、すべてのTiKVノードに送信します。バックアップリクエストには、バックアップの時点、バックアップ対象のリージョン、storageパスが含まれます。
TiKV はバックアップ要求を受け入れ、バックアップ ワーカーを開始します。
TiKV はデータをバックアップします。
- KV のスキャン: バックアップ ワーカーは、リーダーが存在するリージョンからバックアップ時点に対応するデータを読み取ります。
- SST の生成: バックアップ ワーカーはデータを SST ファイルに保存し、メモリに格納します。
- SST のアップロード: バックアップ ワーカーは SST ファイルをstorageパスにアップロードします。
BR は各 TiKV ノードからバックアップ結果を受信します。
- リージョンの変更により一部のデータのバックアップに失敗した場合(たとえば、TiKV ノードがダウンしている場合)、 BR はバックアップを再試行します。
- バックアップに失敗し、再試行できないデータがある場合、バックアップ タスクは失敗します。
- すべてのデータがバックアップされた後、 BR はメタデータをバックアップします。
BR はメタデータをバックアップします。
- スキーマのバックアップ: BR はテーブル スキーマをバックアップし、テーブル データのチェックサムを計算します。
- メタデータのアップロード: BRはバックアップメタデータを生成し、storageパスにアップロードします。バックアップメタデータには、バックアップのタイムスタンプ、テーブルと対応するバックアップファイル、データチェックサム、ファイルチェックサムが含まれます。
復元のプロセス
クラスター スナップショットの復元プロセスは次のとおりです。
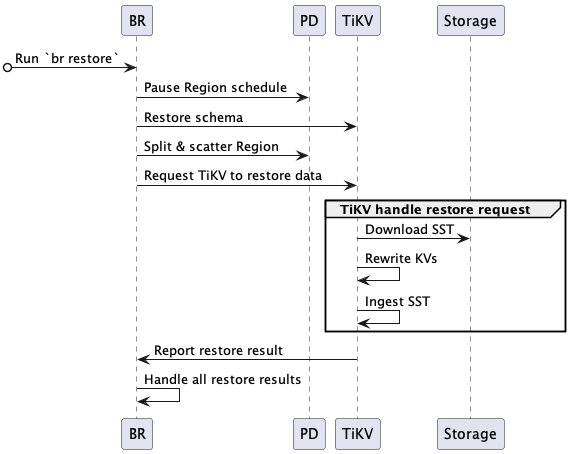
完全な復元プロセスは次のとおりです。
BRは
br restoreコマンドを受信します。- データstorageパスと復元するデータベースまたはテーブルを取得します。
- 復元するテーブルが存在するかどうか、また復元の要件を満たしているかどうかを確認します。
BR はデータの復元をスケジュールします。
- リージョンスケジュールの一時停止: BR は、復元中に自動リージョンスケジュールを一時停止するように PD に要求します。
- 復元スキーマ: BRはバックアップデータと復元対象のデータベースおよびテーブルのスキーマを取得します。新しく作成されたテーブルのIDは、バックアップデータのIDと異なる場合があることに注意してください。
- リージョンの分割と分散: BRはPDにバックアップデータに基づいてリージョン(リージョンの分割)の割り当てを要求し、storageノードに均等に分散するようにスケジュールを設定します(リージョンの分散)。各リージョンには指定されたデータ範囲
[start key, end key)あります。 - TiKVにデータの復元をリクエスト: BRはリージョン分割の結果に基づいて復元リクエストを作成し、対応するTiKVノードに送信します。復元リクエストには、復元するデータと書き換えルールが含まれます。
TiKV は復元要求を受け入れ、復元ワーカーを開始します。
- 復元ワーカーは、復元するために読み取る必要があるバックアップ データを計算します。
TiKV はデータを復元します。
- SST のダウンロード: 復元ワーカーは、対応する SST ファイルをstorageパスからローカル ディレクトリにダウンロードします。
- KVの書き換え:リストアワーカーは新しいテーブルIDに従ってKVデータを書き換えます。つまり、 キーバリューの元のテーブルIDを新しいテーブルIDに置き換えます。リストアワーカーは同様にインデックスIDも書き換えます。
- SSTの取り込み: 復元ワーカーは処理済みの SST ファイルを RocksDB に取り込みます。
- 復元結果の報告: 復元ワーカーは復元結果をBRに報告します。
BR は各 TiKV ノードから復元結果を受信します。
RegionNotFoundまたはEpochNotMatch原因で一部のデータの復元に失敗した場合 (たとえば、TiKV ノードがダウンしている場合)、 BR は復元を再試行します。- 復元に失敗し、再試行できないデータがある場合、復元タスクは失敗します。
- すべてのデータが復元されると、復元タスクは成功します。
バックアップファイル
バックアップファイルの種類
スナップショット バックアップでは、次の種類のファイルが生成されます。
SSTファイル: TiKV ノードがバックアップしたデータを保存します。2SSTのサイズはリージョンのサイズと同じです。backupmetaファイル: すべてのバックアップ ファイルの数、キー範囲、サイズ、各バックアップ ファイルのハッシュ (sha256) 値など、バックアップ タスクのメタデータを保存します。backup.lockファイル: 複数のバックアップ タスクが同じディレクトリにデータを保存するのを防ぎます。
SSTファイルの命名形式
データがGoogle Cloud Storage(GCS)またはAzure Blob Storageにバックアップされると、SSTファイルはstoreID_regionID_regionEpoch_keyHash_timestamp_cfという形式で命名されます。名前の各フィールドの説明は以下のとおりです。
storeIDは TiKV ノード ID です。regionIDはリージョンID です。regionEpochは、リージョンのバージョン番号です。keyHash範囲の startKey のハッシュ (sha256) 値であり、ファイルの一意性を保証します。timestampは、TiKV によって生成されたときの SST ファイルの Unix タイムスタンプです。cfRocksDB のカラムファミリーを示します (cfがdefaultまたはwriteデータのみを復元します)。
データがAmazon S3またはネットワークディスクにバックアップされると、SSTファイルはregionID_regionEpoch_keyHash_timestamp_cfの形式で命名されます。名前の各フィールドの説明は以下のとおりです。
regionIDはリージョンID です。regionEpochは、リージョンのバージョン番号です。keyHashは範囲の startKey のハッシュ (sha256) 値であり、ファイルの一意性を保証します。timestampは、TiKV によって生成されたときの SST ファイルの Unix タイムスタンプです。cfRocksDB のカラムファミリーを示します (cfがdefaultまたはwriteデータのみを復元します)。
SSTファイルの保存形式
- SST ファイルのstorage形式の詳細については、 RocksDB BlockBasedTable形式参照してください。
- SST ファイル内のバックアップ データのエンコード形式の詳細については、 テーブルデータとキー値とのマッピング参照してください。
バックアップファイルの構造
GCS または Azure Blob Storage にデータをバックアップすると、SST ファイル、 backupmetaファイル、およびbackup.lockファイルは次の構造で同じディレクトリに保存されます。
.
└── 20220621
├── backupmeta
|—— backup.lock
├── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
└── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
Amazon S3 またはネットワークディスクにデータをバックアップすると、SST ファイルはstoreIDに基づいてサブディレクトリに保存されます。構造は次のとおりです。
.
└── 20220621
├── backupmeta
|—— backup.lock
├── store1
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store100
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store2
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store3
├── store4
└── store5