TiDBを使用したJavaアプリケーション開発のベストプラクティス
このドキュメントでは、TiDBをより効果的に活用するためのJavaアプリケーション開発におけるベストプラクティスを紹介します。また、バックエンドのTiDBデータベースと連携する一般的なJavaアプリケーションコンポーネントに基づき、開発中に発生する一般的な問題への解決策も提供します。
Javaアプリケーションにおけるデータベース関連コンポーネント
JavaアプリケーションでTiDBデータベースと連携する一般的なコンポーネントには、以下のようなものがあります。
- ネットワーク プロトコル: クライアントは、標準のMySQLプロトコルを介して TiDBサーバーと対話します。
- JDBC APIとJDBCドライバ: Javaアプリケーションは通常、標準のJDBC(Javaデータベース接続) APIを使用してデータベースにアクセスします。TiDBに接続するには、JDBC APIを介してMySQLプロトコルを実装するJDBCドライバを使用できます。MySQL用の一般的なJDBCドライバにはMySQL Connector/JやMariaDB Connector/Jなどがあります。
- データベース接続プール:アプリケーションは通常、接続要求のたびに接続を作成するオーバーヘッドを削減するために、接続プールを使用して接続をキャッシュし、再利用します。JDBCData データソース接続プールAPIを定義しています。必要に応じて、さまざまなオープンソースの接続プール実装から選択できます。
- データアクセスフレームワーク: アプリケーションは通常、 MyBatisやHibernateなどのデータアクセスフレームワークを使用して、データベースアクセス操作をさらに簡素化および管理します。
- アプリケーションの実装: アプリケーション ロジックは、いつどのコマンドをデータベースに送信するかを制御します。一部のアプリケーションは春のトランザクションアスペクトを使用して、トランザクションの開始およびコミットのロジックを管理します。
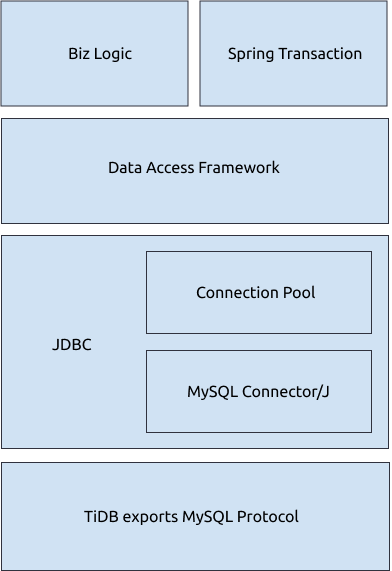
上記の図から、 Javaアプリケーションは次のようなことを行う可能性があることがわかります。
- JDBC APIを介してMySQLプロトコルを実装し、TiDBと連携させる。
- 接続プールから永続的な接続を取得します。
- SQL文を生成および実行するには、MyBatisなどのデータアクセスフレームワークを使用します。
- Spring トランザクションを使用すると、トランザクションを自動的に開始または停止できます。
この文書の残りの部分では、上記のコンポーネントを使用してJavaアプリケーションを開発する際に発生する問題とその解決策について説明します。
JDBC
Javaアプリケーションは、さまざまなフレームワークでカプセル化されたできます。ほとんどのフレームワークでは、データベースサーバーとのやり取りを行うために、最下層でJDBC APIが呼び出されます。JDBCに関しては、以下の点に重点を置くことをお勧めします。
- JDBC APIの使用方法の選択
- API実装者のパラメータ設定
JDBC API
JDBC APIの使用方法については、 JDBC公式チュートリアル参照してください。このセクションでは、いくつかの重要な API の使用法について説明します。
Prepare APIを使用する
OLTP (オンライン トランザクション処理) シナリオの場合、プログラムによってデータベースに送信される SQL ステートメントは、パラメーターの変更を削除した後に枯渇する可能性があるいくつかのタイプです。したがって、通常のテキストファイルからの実行代わりにプリペアドステートメントを使用し、プリペアドステートメントを再利用して直接実行することをお勧めします。これにより、TiDB で SQL 実行プランを繰り返し解析して生成するオーバーヘッドが回避されます。
現在、ほとんどの上位フレームワークはSQL実行のためにPrepare APIを呼び出しています。開発でJDBC APIを直接使用する場合は、Prepare APIを選択するように注意してください。
さらに、MySQL Connector/J のデフォルト実装では、クライアント側のステートメントのみが前処理され、 ?がクライアント側で置換された後、ステートメントはテキストファイルとしてサーバーに送信されます。そのため、Prepare API を使用するだけでなく、TiDB サーバーでステートメントの前処理を実行する前に、JDBC 接続サーバーでuseServerPrepStmts = trueを設定する必要があります。パラメータ設定の詳細については、 MySQL JDBC パラメータドキュメントを参照してください。
バッチAPIを使用する
バッチ挿入の場合は、 addBatch / executeBatch API使用できます。 addBatch()メソッドは、複数の SQL ステートメントを最初にクライアントにキャッシュし、 executeBatchメソッドを呼び出すときにそれらをまとめてデータベースサーバーに送信するために使用されます。
StreamingResultを使用して実行結果を取得します。
ほとんどのシナリオでは、実行効率を向上させるために、JDBCはデフォルトでクエリ結果を事前に取得し、クライアントのメモリに保存します。しかし、クエリが非常に大きな結果セットを返す場合、クライアントはデータベースサーバーに一度に返されるレコード数を減らし、クライアントのメモリが準備できるまで待機し、次のバッチを要求することがよくあります。
JDBCでは通常、以下の2つの処理方法が使用されます。
最初のメソッド:
FetchSizeInteger.MIN_VALUEに設定しますクライアントがキャッシュしないようにします。クライアントはStreamingResultを介してネットワーク接続から実行結果を読み取ります。クライアントがストリーミング読み取り方式を使用する場合、クエリを実行するためにステートメントの使用を続行する前に、読み取りを完了するか
resultsetを閉じる必要があります。そうしないと、エラーNo statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.が返されます。クライアントが
resultset読み取りを完了または閉じる前にクエリでこのようなエラーが発生するのを回避するには、URL にclobberStreamingResults=trueパラメータを追加します。そうすると、resultsetは自動的に閉じられますが、前のストリーミング クエリで読み取られる結果セットは失われます。2番目の方法:まず
FetchSize設定、次にJDBC URLでuseCursorFetch = trueを設定することで、カーソルフェッチを使用します。
TiDBは両方の方法をサポートしていますが、実装がよりシンプルで実行効率も優れているため、 FetchSizeをInteger.MIN_VALUEに設定する最初の方法を使用することをお勧めします。
2番目の方法では、TiDBはまずすべてのデータをTiDBノードにロードし、 FetchSizeに従ってクライアントにデータを返します。そのため、通常は最初の方法よりも多くのメモリを消費します。tidb_enable_tmp_storage_on_oom tidb_enable_tmp_storage_on_oom ONに設定されている場合、TiDBは結果を一時的にハードディスクに書き込む可能性があります。
tidb_enable_lazy_cursor_fetchシステム変数がONに設定されている場合、TiDB はクライアントがデータをフェッチするときにのみデータの一部を読み取ろうとします。これにより、使用されるメモリが少なくなります。詳細と制限については、 tidb_enable_lazy_cursor_fetchシステム変数の完全な説明を参照してください。
MySQL JDBC パラメータ
JDBC は通常、実装関連の設定を JDBC URL パラメーターの形式で提供します。このセクションではMySQL Connector/Jのパラメータ設定を紹介します (MariaDB を使用する場合は、 MariaDBのパラメータ設定参照してください)。このドキュメントではすべての構成項目をカバーすることはできないため、パフォーマンスに影響を与える可能性のあるいくつかのパラメーターに主に焦点を当てています。
準備関連パラメータ
このセクションでPrepareに関連するパラメータを紹介します。
useServerPrepStmts
useServerPrepStmtsはデフォルトでfalseに設定されています。つまり、Prepare API を使用する場合でも、「prepare」操作はクライアント側でのみ実行されます。サーバーの解析オーバーヘッドを回避するため、同じ SQL ステートメントで Prepare API を複数回使用する場合は、この設定をtrueに設定することをお勧めします。
この設定が既に有効になっていることを確認するには、次の操作を実行してください。
- TiDB モニタリング ダッシュボードに移動し、 [クエリ概要] > [インスタンス別 CPS]からリクエスト コマンド タイプを確認します。
- リクエスト内で
COM_QUERYがCOM_STMT_EXECUTEまたはCOM_STMT_PREPAREに置き換えられた場合、この設定は既に有効になっていることを意味します。
cachePrepStmts
useServerPrepStmts=trueはサーバーがプリペアドステートメントを実行できるようにしますが、デフォルトではクライアントは実行後にプリペアドステートメントを閉じ、再利用しません。つまり、「準備」操作はテキストファイルの実行ほど効率的ではありません。この問題を解決するには、 useServerPrepStmts=trueを設定した後、 cachePrepStmts=trueも設定することをお勧めします。これにより、クライアントはプリペアドステートメントをキャッシュできるようになります。
この設定が既に有効になっていることを確認するには、次の操作を実行してください。
- TiDB モニタリング ダッシュボードに移動し、 [クエリ概要] > [インスタンス別 CPS]からリクエスト コマンド タイプを確認します。
- リクエスト内の
COM_STMT_EXECUTEの数がCOM_STMT_PREPAREの数よりはるかに多い場合、この設定は既に有効になっていることを意味します。
さらに、 useConfigs=maxPerformanceを設定すると、 cachePrepStmts=trueを含む複数のパラメーターが同時に設定されます。
prepStmtCacheSqlLimit
cachePrepStmtsの設定後、 prepStmtCacheSqlLimitの設定にも注意してください(デフォルト値は256です)。この設定は、クライアントにキャッシュされるプリペアドステートメントの最大長を制御します。
この最大長を超えるプリペアドステートメントはキャッシュされないため、再利用できません。この場合、アプリケーションの実際のSQLの長さに応じて、この設定値を増やすことを検討してください。
次のような場合は、この設定が小さすぎるかどうかを確認する必要があります。
- TiDB モニタリング ダッシュボードに移動し、 [クエリ概要] > [インスタンス別 CPS]からリクエスト コマンド タイプを確認します。
- そして、
cachePrepStmts=trueが設定されているが、COM_STMT_PREPAREは依然としてCOM_STMT_EXECUTEとほぼ等しく、COM_STMT_CLOSEが存在することがわかった。
prepStmtCacheSize
prepStmtCacheSizeキャッシュされるプリペアド ステートメントの数を制御します (デフォルト値は25です)。アプリケーションで多くの種類の SQL ステートメントを「準備」する必要があり、プリペアド ステートメントを再利用したい場合は、この値を増やすことができます。
この設定が既に有効になっていることを確認するには、次の操作を実行してください。
- TiDB モニタリング ダッシュボードに移動し、 [クエリ概要] > [インスタンス別 CPS]からリクエスト コマンド タイプを確認します。
- リクエスト内の
COM_STMT_EXECUTEの数がCOM_STMT_PREPAREの数よりはるかに多い場合、この設定は既に有効になっていることを意味します。
readOnlyPropagatesToServer
readOnlyPropagatesToServerプロパティを無効にしてください。このプロパティが有効になっている場合、JDBC ドライバはSET SESSION TRANSACTION READ ONLYステートメントをサーバーに送信します。TiDB はこのステートメントをサポートしておらず、すべての TiDB ノードが読み取り接続と書き込み接続の両方を受け入れるため、このステートメントを送信する必要はありません。
バッチ関連パラメータ
バッチ書き込みを処理する際は、 rewriteBatchedStatements=trueを設定することをお勧めします。 addBatch()またはexecuteBatch()を使用した後でも、JDBC はデフォルトでは SQL を 1 つずつ送信します。例:
pstmt = prepare("insert into t (a) values(?)");
pstmt.setInt(1, 10);
pstmt.addBatch();
pstmt.setInt(1, 11);
pstmt.addBatch();
pstmt.setInt(1, 12);
pstmt.executeBatch();
Batchメソッドが使用されていますが、TiDB に送信される SQL ステートメントは依然として個別のINSERTステートメントです。
insert into t(a) values(10);
insert into t(a) values(11);
insert into t(a) values(12);
しかし、 rewriteBatchedStatements=trueを設定すると、TiDB に送信される SQL ステートメントは単一のINSERTステートメントになります。
insert into t(a) values(10),(11),(12);
INSERTステートメントの書き換えは、複数の「values」キーワードの後の値を連結して 1 つの SQL ステートメントにするものであることに注意してください。 INSERTステートメントに他の違いがある場合、書き換えることはできません。たとえば、次のようになります。
insert into t (a) values (10) on duplicate key update a = 10;
insert into t (a) values (11) on duplicate key update a = 11;
insert into t (a) values (12) on duplicate key update a = 12;
上記のINSERT文は 1 つの文に書き換えることはできません。しかし、3 つの文を次のように変更すると次のようになります。
insert into t (a) values (10) on duplicate key update a = values(a);
insert into t (a) values (11) on duplicate key update a = values(a);
insert into t (a) values (12) on duplicate key update a = values(a);
すると、書き換え要件を満たします。上記のINSERT文は、次の 1 つの文に書き換えられます。
insert into t (a) values (10), (11), (12) on duplicate key update a = values(a);
バッチ更新中に3つ以上の更新がある場合、SQLステートメントは書き換えられ、複数のクエリとして送信されます。これにより、クライアントからサーバーへのリクエストのオーバーヘッドは効果的に削減されますが、副作用として、より大きなSQLステートメントが生成されます。例:
update t set a = 10 where id = 1; update t set a = 11 where id = 2; update t set a = 12 where id = 3;
さらに、クライアントのバグのため、バッチ更新中にrewriteBatchedStatements=trueとuseServerPrepStmts=trueを設定する場合は、このバグを回避するためにallowMultiQueries=trueパラメータも設定することをお勧めします。
パラメータを統合する
監視を通じて、アプリケーションがTiDBに対してINSERT操作のみを実行しているにもかかわらず、 SELECT冗長なステートメントが多数存在することに気づくかもしれません。通常、これはJDBCがselect @@session.transaction_read_only設定を照会するためにSQLステートメントを送信することが原因です。これらのSQLステートメントはTiDBでは不要なので、余分なオーバーヘッドを避けるためにuseConfigs=maxPerformanceを設定することをお勧めします。
useConfigs=maxPerformanceには、設定のグループが含まれています。MySQL Connector/J 8.0 および MySQL Connector/J 5.1 の詳細な設定については、それぞれmysql-connector-j 8.0およびmysql-connector-j 5.1を参照してください。
設定後、監視を確認すると、 SELECTステートメントの数が減少していることが確認できます。
タイムアウト関連のパラメータ
TiDBは、以下のMySQL互換のタイムアウト制御パラメータを提供します。
wait_timeout: Javaアプリケーションへの接続における非対話型アイドルタイムアウトを制御します。TiDB v5.4 以降では、wait_timeoutのデフォルト値は28800秒、つまり 8 時間です。TiDB バージョンが v5.4 より前の場合、デフォルト値は0で、タイムアウトは無制限です。interactive_timeout: Javaアプリケーションへの接続における対話型アイドルタイムアウトを制御します。デフォルト値は8時間です。max_execution_time: 接続における SQL 実行のタイムアウトを制御します。これはSELECTステートメント (SELECT ... FOR UPDATEを含む) にのみ有効です。デフォルト値は0で、接続が無限にビジー状態になることを許可します。つまり、SQL ステートメントが無限に長い時間実行されます。
しかし、実際の本番環境では、アイドル状態の接続や実行時間が長すぎる SQL ステートメントは、データベースやアプリケーションに悪影響を及ぼします。アイドル状態の接続や実行時間が長すぎる SQL ステートメントを回避するには、アプリケーションの接続文字列で次の 2 つのパラメータを設定できます。たとえば、 sessionVariables=wait_timeout=3600 (1 時間) とsessionVariables=max_execution_time=300000 (5 分) を設定します。
一般的なJDBC接続文字列パラメータ
上記のパラメータ値を組み合わせると、JDBC接続文字列の設定は次のようになります。
jdbc:mysql://<IP_ADDRESS>:<PORT_NUMBER>/<DATABASE_NAME>?characterEncoding=UTF-8&useSSL=false&useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSqlLimit=10000&prepStmtCacheSize=1000&useConfigs=maxPerformance&rewriteBatchedStatements=true
接続プール
TiDB(MySQL)接続の構築は、(少なくともOLTPシナリオにおいては)比較的コストがかかります。なぜなら、TCP接続の確立に加えて、接続認証も必要となるからです。そのため、クライアントは通常、TiDB(MySQL)接続を接続プールに保存して再利用します。
TiDBは以下のJava接続プールをサポートしています。
実際には、一部の接続プールは特定のセッションを継続的に使用する場合があります。TiDB の計算ノード全体で接続の総数は均等に分散されているように見えますが、アクティブな接続の分散が不均一な場合、実際の負荷の不均衡が生じる可能性があります。分散環境では、接続ライフサイクルを効果的に管理し、アクティブな接続が特定のノードに固定されるのを防ぎ、負荷分散のバランスを保つHikariCPの使用をお勧めします。
典型的な接続プール構成
以下はHikariCPの設定例です。
hikari:
maximumPoolSize: 20
poolName: hikariCP
connectionTimeout: 30000
maxLifetime: 1200000
keepaliveTime: 120000
パラメータの説明は以下の通りです。詳細については、 HikariCPの公式ドキュメントを参照してください。
maximumPoolSize: プール内の最大接続数。デフォルト値は10です。コンテナ化された環境では、 Javaアプリケーションで使用可能な CPU コア数の 4~10 倍に設定することをお勧めします。この値を高く設定しすぎるとリソースの無駄遣いにつながり、低く設定しすぎると接続の取得が遅くなる可能性があります。 詳細については、を参照プールのサイズについてください。minimumIdle: HikariCPでは、このパラメータを設定しないことを推奨します。デフォルト値はmaximumPoolSizeの値と同じで、接続プールのスケーリングを無効にします。これにより、トラフィックの急増時にも接続がすぐに利用可能になり、接続作成による遅延を回避できます。connectionTimeout: アプリケーションが接続プールから接続を取得するために待機する最大時間 (ミリ秒)。デフォルト値は30000ミリ秒 (30 秒) です。この時間内に利用可能な接続が得られない場合、SQLException例外が発生します。maxLifetime: プール内の接続の最大有効期間 (ミリ秒)。デフォルト値は1800000ミリ秒 (30 分) です。使用中の接続には影響しません。接続が閉じられた後、この設定に従って削除されます。この値を低く設定しすぎると、再接続が頻繁に発生する可能性があります。gracefulgraceful-wait-before-shutdown使用している場合は、この値が待機時間よりも小さいことを確認してください。keepaliveTime: プール内の接続に対するキープアライブ操作の間隔 (ミリ秒)。この設定は、データベースまたはネットワークのアイドルタイムアウトによって発生する切断を防ぐのに役立ちます。デフォルト値は120000ミリ秒 (2 分) です。プールは、アイドル状態の接続を維持するために JDBC4isValid()メソッドを使用することを優先します。
プローブ構成
接続プールは、以下のようにクライアントからTiDBへの永続的な接続を維持します。
- バージョン5.4より前のTiDBでは、デフォルトでは(エラーが報告されない限り)クライアント接続を積極的に閉じることはありません。
- バージョン5.4以降、TiDBはデフォルトで
28800秒(つまり8時間)の非アクティブ状態が続くと、クライアント接続を自動的に閉じます。このタイムアウト設定は、TiDBおよびMySQL互換のwait_timeout変数を使用して制御できます。詳細については、 JDBCクエリタイムアウト参照してください。 .
さらに、クライアントとTiDBの間には、 LVSやHAProxyなどのネットワークプロキシが存在する場合があります。これらのプロキシは通常、特定のアイドル期間(プロキシのアイドル設定によって決定されます)が経過すると、接続を自動的にクリーンアップします。接続プールは、プロキシのアイドル設定を監視するだけでなく、キープアライブのために接続を維持またはプローブする必要もあります。
Javaアプリケーションで以下のエラーが頻繁に発生する場合:
The last packet sent successfully to the server was 3600000 milliseconds ago. The driver has not received any packets from the server. com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
n内のn milliseconds agoの値が0または非常に小さい値である場合、通常は実行された SQL 操作によって TiDB が異常終了したことが原因です。原因を特定するには、TiDB の標準エラー ログを確認することをお勧めします。
nの値が非常に大きい場合 (上記の例の3600000など)、この接続が長時間アイドル状態になり、中間プロキシによって閉じられた可能性が高いです。通常の解決策は、プロキシのアイドル設定の値を増やし、接続プールが次の操作を実行できるようにすることです。
- 接続を使用する前に毎回接続が利用可能かどうかを確認してください。
- 別のスレッドを使用して、接続が利用可能かどうかを定期的に確認してください。
- 接続を維持するために、定期的にテストクエリを送信してください。
接続プールの実装によっては、上記の方法のうち1つ以上がサポートされている場合があります。対応する設定については、接続プールのドキュメントを参照してください。
データアクセスフレームワーク
アプリケーションは、データベースへのアクセスを簡素化するために、何らかのデータアクセスフレームワークを使用することが多い。
MyBatis
MyBatis 、人気の高いJavaデータアクセスフレームワークです。主にSQLクエリの管理や、結果セットとJavaオブジェクト間のマッピングに使用されます。MyBatisはTiDBとの互換性が非常に高く、過去の事例に基づくと、問題が発生することは稀です。
この文書では、主に以下の構成に焦点を当てています。
マッパーパラメータ
MyBatis Mapperは2つのパラメータをサポートしています。
select 1 from t where id = #{param1}、プリペアドステートメントとしてselect 1 from t where id =?に変換され、「準備済み」の状態になります。実際のパラメータは再利用されます。このパラメータを前述の接続準備パラメータと併用すると、最高のパフォーマンスが得られます。select 1 from t where id = ${param2}はテキストファイルselect 1 from t where id = 1に置き換えられ、実行されます。このステートメントが異なるパラメータに置き換えられて実行されると、MyBatis はステートメントの「準備」のために TiDB に異なるリクエストを送信します。これにより、TiDB が多数のプリペアドステートメントをキャッシュする可能性があり、この方法で SQL 操作を実行すると、インジェクションのセキュリティリスクが発生します。
動的SQLバッチ
複数のINSERTステートメントをinsert ... values(...), (...), ...の形式に自動的に書き換えることをサポートするために、前述のように JDBC でrewriteBatchedStatements=trueを設定することに加えて、MyBatis は動的 SQL を使用してバッチ挿入を半自動的に生成することもできます。次のマッパーを例にとります。
<insert id="insertTestBatch" parameterType="java.util.List" fetchSize="1">
insert into test
(id, v1, v2)
values
<foreach item="item" index="index" collection="list" separator=",">
(
#{item.id}, #{item.v1}, #{item.v2}
)
</foreach>
on duplicate key update v2 = v1 + values(v1)
</insert>
このマッパーはinsert on duplicate key updateステートメントを生成します。 (?,?,?)に続く「値」の数は、渡されたリストの数によって決まります。最終的な効果はrewriteBatchStatements=trueを使用した場合と同様で、クライアントと TiDB 間の通信オーバーヘッドを効果的に削減します。
前述のとおり、プリペアドステートメントの最大長がprepStmtCacheSqlLimitの値を超えると、キャッシュされないことにも注意する必要があります。
ストリーミング結果
前のセクションJDBC で読み取り実行結果をストリーミングする方法を紹介します。 MyBatis で超大規模な結果セットを読み込む場合は、JDBC の対応する設定に加えて、次の点にも注意する必要があります。
- マッパー構成で単一の SQL ステートメントに対して
fetchSizeを設定できます (前のコードブロックを参照)。その効果は、JDBC でsetFetchSizeを呼び出すのと同等です。 ResultHandlerを使用したクエリ インターフェースを使用すると、結果セット全体を一度に取得することを避けることができます。- ストリーム読み取りには
Cursorクラスを使用できます。
XML を使用してマッピングを設定する場合、マッピングのfetchSize="-2147483648"セクションでInteger.MIN_VALUE } ( <select> ) を設定することで、読み取り結果をストリーミングできます。
<select id="getAll" resultMap="postResultMap" fetchSize="-2147483648">
select * from post;
</select>
コードを使用してマッピングを構成する場合は、 @Options(fetchSize = Integer.MIN_VALUE)アノテーションを追加し、結果のタイプをCursorのままにすることで、SQL の結果をストリーミングで読み取ることができます。
@Select("select * from post")
@Options(fetchSize = Integer.MIN_VALUE)
Cursor<Post> queryAllPost();
ExecutorType
ExecutorTypeの間に { openSession } を選択できます。MyBatis は 3 種類の実行エンジンをサポートしています。
- Simple: プリペアドステートメントは、実行ごとにJDBCに呼び出されます(JDBC構成項目
cachePrepStmtsが有効になっている場合、繰り返し実行されるプリペアドステートメントは再利用されます)。 - Reuse: プリペアドステートメントは
executorにキャッシュされるため、JDBCcachePrepStmtsを使用せずにプリペアドステートメントの重複呼び出しを減らすことができます。 - Batch: 各更新操作 (
INSERT/DELETE/UPDATE) は、まずバッチに追加され、トランザクションがコミットされるかSELECTクエリが実行されるまで実行されます。JDBCレイヤーでrewriteBatchStatementsが有効になっている場合は、ステートメントの書き換えが試みられます。そうでない場合は、ステートメントは 1 つずつ送信されます。
通常、 ExecutorTypeのデフォルト値はSimpleです。 ExecutorTypeを呼び出すときはopenSession } を変更する必要があります。バッチ実行の場合、トランザクション内でUPDATEまたはINSERTステートメントの実行は非常に高速ですが、データの読み取りやトランザクションのコミットは遅くなる場合があります。これは正常な動作ですので、SQL クエリの遅延をトラブルシューティングする際には、この点に注意してください。
春のトランザクション
現実の世界では、アプリケーションは春のトランザクションと AOP のアスペクトを使用してトランザクションを開始および停止する場合があります。
メソッド定義に@Transactionalアノテーションを追加することで、AOP はメソッドが呼び出される前にトランザクションを開始し、メソッドが結果を返す前にトランザクションをコミットします。アプリケーションで同様の要件がある場合は、コード内で@Transactionalを見つけることで、トランザクションの開始と終了のタイミングを判断できます。
埋め込みの特殊なケースに注意してください。埋め込みが発生すると、Spring は伝搬設定に基づいて異なる動作をします。
その他
このセクションでは、 Javaで問題解決に役立つ便利なツールをいくつか紹介します。
トラブルシューティングツール
Javaアプリケーションで問題が発生し、そのアプリケーションロジックが不明な場合は、JVMの強力なトラブルシューティングツールを使用することをお勧めします。以下に、よく使用されるツールをいくつか紹介します。
jstack
jstack Go言語のpprof/goroutineに似ており、プロセスが停止する問題を容易にトラブルシューティングできます。
jstack pidを実行すると、対象プロセス内のすべてのスレッドの ID とスタック情報を出力できます。デフォルトでは、 Javaスタックのみが出力されます。JVM 内の C++ スタックも同時に出力する場合は、 -mオプションを追加してください。
jstackを複数回使用することで、スタックしている問題(例えば、MybatisのBatch ExecutorTypeを使用しているためにアプリケーションビューからのクエリが遅い場合)やアプリケーションのデッドロック問題(例えば、アプリケーションがSQLステートメントを送信する前にロックをプリエンプトしているため、SQLステートメントを送信しない場合)を簡単に特定できます。
さらに、 top -p $ PID -HやJavaスイスナイフは、スレッドIDを表示する一般的な方法です。また、「スレッドが大量のCPUリソースを消費しているが、何を実行しているのか分からない」という問題を特定するには、以下の手順を実行してください。
printf "%x\n" pidを使用して、スレッド ID を 16 進数に変換します。- jstackの出力結果を確認すると、対応するスレッドのスタック情報が表示されます。
jmap & mat
Go の pprof/heap とは異なり、 jmapプロセス全体のメモリスナップショットをダンプし (Go ではディストリビュータのサンプリング)、その後、スナップEclipse MATを別のツールで分析できます。
mat を使用すると、プロセス内のすべてのオブジェクトに関連付けられた情報と属性を確認できるほか、スレッドの実行状態も監視できます。たとえば、mat を使用して、現在のアプリケーションに存在する MySQL 接続オブジェクトの数、および各接続オブジェクトのアドレスと状態情報を調べることができます。
matはデフォルトでは到達可能なオブジェクトのみを処理することに注意してください。ヤングGCの問題をトラブルシューティングしたい場合は、matの設定を調整して到達不可能なオブジェクトを表示できます。また、ヤングGCの問題(または多数の短命オブジェクト)のメモリ割り当てを調査するには、 Java Flight Recorderを使用する方が便利です。
トレース
オンラインアプリケーションは通常、コードの変更をサポートしていませんが、 Javaで動的な計測を実行して問題箇所を特定することが求められる場合がよくあります。そのため、btraceやarthas traceを使用するのが良い選択肢となります。これらのツールは、アプリケーションプロセスを再起動することなく、トレースコードを動的に挿入できます。
炎のグラフ
Javaアプリケーションでフレーム グラフを取得するのは面倒です。詳細については、 Java Flame Graphs入門:みんなのための炎!を参照してください。
結論
このドキュメントでは、データベースと連携する一般的なJavaコンポーネントに基づいて、TiDBを使用したJavaアプリケーション開発における一般的な問題点とその解決策について説明します。TiDBはMySQLプロトコルとの互換性が非常に高いため、MySQLベースのJavaアプリケーション開発におけるベストプラクティスのほとんどがTiDBにも適用できます。
お困りですか?
Discordor Slackコミュニティに質問するか、サポートチケットを送信してください。