从 TiDB Self-Managed 迁移到 TiDB Cloud Premium
本文档介绍如何使用 Dumpling 和 TiCDC 将数据从你的 TiDB Self-Managed 集群迁移到 TiDB Cloud Premium(AWS 上)的实例。
整体流程如下:
- 搭建环境并准备工具。
- 迁移全量数据。流程如下:
- 使用 Dumpling 将数据从 TiDB Self-Managed 导出到 Amazon S3。
- 将数据从 Amazon S3 导入到 TiDB Cloud Premium。
- 使用 TiCDC 复制增量数据。
- 验证迁移后的数据。
前提条件
建议将 S3 bucket 和 TiDB Cloud Premium 实例放在同一 region。跨 region 迁移可能会产生额外的数据转换成本。
迁移前,你需要准备以下内容:
- 一个具有管理员访问权限的 AWS account
- 一个 AWS S3 bucket
- 一个 TiDB Cloud account,并且对托管在 AWS 上的目标 TiDB Cloud Premium 实例至少具有
Project Data Access Read-Write权限
准备工具
你需要准备以下工具:
- Dumpling:数据导出工具
- TiCDC:数据复制工具
Dumpling
Dumpling 是一个将 TiDB 或 MySQL 中的数据导出为 SQL 或 CSV 文件的工具。你可以使用 Dumpling 从 TiDB Self-Managed 导出全量数据。
在部署 Dumpling 之前,请注意以下事项:
- 建议在与你的目标 TiDB Cloud Premium 实例位于同一 VPC 的新 EC2 实例上部署 Dumpling。
- 推荐的 EC2 实例类型为 c6g.4xlarge(16 vCPU 和 32 GiB 内存)。你也可以根据需要选择其他 EC2 实例类型。Amazon Machine Image (AMI) 可以是 Amazon Linux、Ubuntu 或 Red Hat。
你可以使用 TiUP 或安装包来部署 Dumpling。
使用 TiUP 部署 Dumpling
使用 TiUP 部署 Dumpling:
## Deploy TiUP {#deploy-tiup}
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
source /root/.bash_profile
## Deploy Dumpling and update to the latest version {#deploy-dumpling-and-update-to-the-latest-version}
tiup install dumpling
tiup update --self && tiup update dumpling
使用安装包部署 Dumpling
要使用安装包部署 Dumpling:
下载 toolkit package。
将其解压到目标机器。你也可以通过运行
tiup install dumpling使用 TiUP 获取 Dumpling。然后,你可以使用tiup dumpling ...运行 Dumpling。更多信息,参见 Dumpling introduction。
为 Dumpling 配置权限
你需要以下权限才能从上游数据库导出数据:
- SELECT
- RELOAD
- LOCK TABLES
- REPLICATION CLIENT
- PROCESS
部署 TiCDC
你需要部署 TiCDC,以便将增量数据从上游 TiDB Self-Managed 集群复制到 TiDB Cloud Premium。
确认当前 TiDB 版本是否支持 TiCDC。TiDB v4.0.8.rc.1 及之后的版本支持 TiCDC。你可以通过在 TiDB Self-Managed 集群中执行
select tidb_version();来检查 TiDB 版本。如果你需要升级,请参见 Upgrade TiDB Using TiUP。将 TiCDC 组件添加到 TiDB Self-Managed 集群。参见 Add or scale out TiCDC to an existing TiDB cluster using TiUP。编辑
scale-out.yml文件以添加 TiCDC:cdc_servers: - host: 10.0.1.3 gc-ttl: 86400 data_dir: /tidb-data/cdc-8300 - host: 10.0.1.4 gc-ttl: 86400 data_dir: /tidb-data/cdc-8300添加 TiCDC 组件并检查状态。
tiup cluster scale-out <cluster-name> scale-out.yml tiup cluster display <cluster-name>
迁移全量数据
要将数据从 TiDB Self-Managed 集群迁移到 TiDB Cloud Premium,请按如下方式执行全量数据迁移:
- 将数据从 TiDB Self-Managed 集群迁移到 Amazon S3。
- 将数据从 Amazon S3 迁移到 TiDB Cloud Premium。
将数据从 TiDB Self-Managed 集群迁移到 Amazon S3
你需要使用 Dumpling 将数据从 TiDB Self-Managed 集群迁移到 Amazon S3。
如果你的 TiDB Self-Managed 集群位于本地 IDC,或者 Dumpling 服务器与 Amazon S3 之间的网络不通,你可以先将文件导出到本地存储,然后稍后再上传到 Amazon S3。
步骤 1. 临时禁用上游 TiDB Self-Managed 集群的 GC 机制
为确保在增量迁移期间新写入的数据不会丢失,你需要在开始迁移前禁用上游集群的垃圾回收(GC)机制,以防止系统清理历史数据。
运行以下命令以验证设置是否成功。
SET GLOBAL tidb_gc_enable = FALSE;
以下是一个输出示例,其中 0 表示已禁用。
SELECT @@global.tidb_gc_enable;
+-------------------------+
| @@global.tidb_gc_enable |
+-------------------------+
| 0 |
+-------------------------+
1 row in set (0.01 sec)
步骤 2. 为 Dumpling 配置对 Amazon S3 bucket 的访问权限
在 AWS 控制台中创建 access key。详情参见 Create an access key。
使用你的 AWS account ID 或 account alias、IAM user name 和密码登录 the IAM console。
在右上角的导航栏中,选择你的用户名,然后点击 My Security Credentials。
要创建 access key,点击 Create access key。然后选择 Download .csv file,将 access key ID 和 secret access key 保存到你计算机上的 CSV 文件中。请将该文件存放在安全位置。此对话框关闭后,你将无法再次访问 secret access key。下载 CSV 文件后,选择 Close。创建 access key 时,key pair 默认处于激活状态,你可以立即使用该 key pair。
步骤 3. 使用 Dumpling 将数据从上游 TiDB Self-Managed 集群导出到 Amazon S3
执行以下操作,使用 Dumpling 将数据从上游 TiDB Self-Managed 集群导出到 Amazon S3:
为 Dumpling 配置环境变量。
export AWS_ACCESS_KEY_ID=${AccessKey} export AWS_SECRET_ACCESS_KEY=${SecretKey}从 AWS 控制台获取 S3 bucket URI 和 region 信息。详情参见 Create a bucket。
以下截图展示了如何获取 S3 bucket URI 信息:
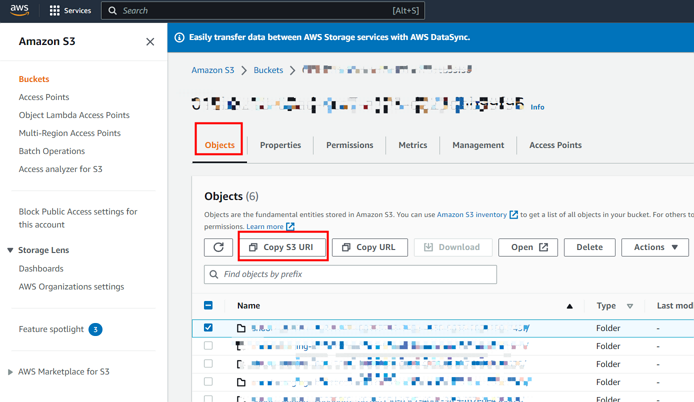
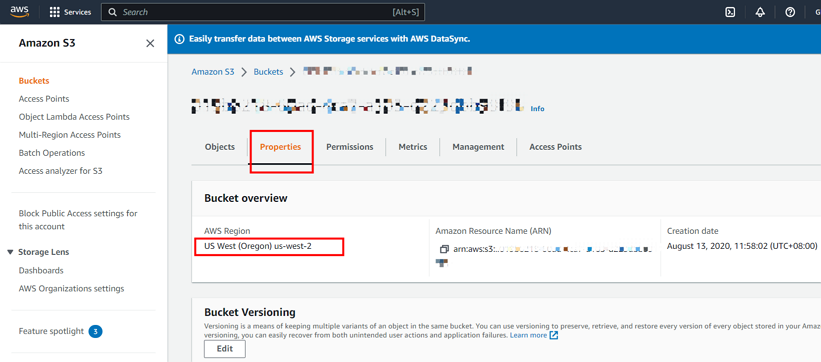
以下截图展示了如何获取 region 信息:
运行 Dumpling,将数据导出到 Amazon S3 bucket。
dumpling \ -u root \ -P 4000 \ -h 127.0.0.1 \ -r 20000 \ --filetype sql \ -F 256MiB \ -t 8 \ -o "${S3 URI}" \ --s3.region "${s3.region}"-t选项指定导出的线程数。增加线程数会提升 Dumpling 的并发度和导出速度,同时也会增加数据库的内存消耗。因此,不要将该参数设置得过大。更多信息,参见 Dumpling。
检查导出的数据。通常,导出的数据包括以下内容:
metadata:该文件包含导出的开始时间以及主 binary log 的位置。{schema}-schema-create.sql:用于创建 schema 的 SQL 文件{schema}.{table}-schema.sql:用于创建表的 SQL 文件{schema}.{table}.{0001}.{sql|csv}:数据文件*-schema-view.sql,*-schema-trigger.sql,*-schema-post.sql:其他导出的 SQL 文件
将数据从 Amazon S3 迁移到 TiDB Cloud Premium
将数据从 TiDB Self-Managed 集群导出到 Amazon S3 后,你需要将这些数据迁移到 TiDB Cloud Premium。
在 TiDB Cloud 控制台中,获取目标 TiDB Cloud Premium 实例的 Account ID 和 External ID。
- 进入 My TiDB 页面,然后点击目标实例的名称。
- 在左侧导航栏中,点击 Data > Import。
- 选择 Import data from Cloud Storage > Amazon S3。
- 记下向导中显示的 Account ID 和 External ID。这些值会嵌入到 CloudFormation 模板中。
在 Source Connection 对话框中,选择 AWS Role ARN,然后点击 Click here to create a new one with AWS CloudFormation,并按照屏幕提示进行操作。如果你的组织无法启动 CloudFormation stack,请参见手动创建 IAM role。
- 在 AWS 控制台中打开预填充的 CloudFormation 模板。
- 提供 role 名称,检查权限,并确认 IAM 警告。
- 创建 stack,并等待状态变为 CREATE_COMPLETE。
- 在 Outputs 选项卡中,复制新生成的 Role ARN。
- 返回 TiDB Cloud Premium,粘贴 Role ARN,然后点击 Confirm。向导会保存该 ARN,以供后续导入任务使用。
继续完成导入向导中的其余步骤,并在提示时使用已保存的 Role ARN。
手动创建 IAM role(可选)
如果你的组织无法部署 CloudFormation stack,请手动创建访问策略和 IAM role:
在 AWS IAM 中,创建一个策略,为你的 bucket(以及 KMS key,如适用)授予以下操作权限:
s3:GetObjects3:GetObjectVersions3:ListBuckets3:GetBucketLocationkms:Decrypt(仅当启用 SSE-KMS 加密时)
以下 JSON 模板展示了所需的结构。请将占位符替换为你的 bucket 路径、bucket ARN 和 KMS key ARN(如需要)。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::<Your customized directory>" }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": "<Your S3 bucket ARN>" }, { "Effect": "Allow", "Action": [ "kms:Decrypt" ], "Resource": "<Your AWS KMS ARN>" } ] }创建一个信任 TiDB Cloud Premium 的 IAM role,方法是提供你之前记下的 Account ID 和 External ID。然后,将上一步创建的策略附加到该 role。
复制生成的 Role ARN,并将其填入 TiDB Cloud Premium 导入向导中。
按照从 Amazon S3 导入数据到 TiDB Cloud Premium中的说明,将数据导入到 TiDB Cloud Premium。
复制增量数据
要复制增量数据,请执行以下操作:
获取增量数据迁移的开始时间。例如,你可以从全量数据迁移的 metadata 文件中获取。
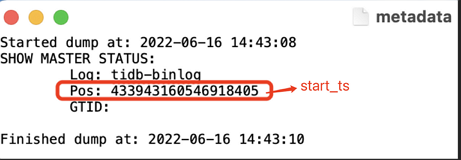
授权 TiCDC 连接到 TiDB Cloud Premium。
- 在 TiDB Cloud 控制台中,进入 My TiDB 页面,然后点击目标 TiDB Cloud Premium 实例的名称,进入其实例概览页面。
- 在左侧导航栏中,点击 Settings > Networking。
- 在 Networking 页面中,点击 Add IP Address。
- 在弹出的对话框中,选择 Use IP addresses,点击 +,在 IP Address 字段中填写 TiCDC 组件的公网 IP 地址,然后点击 Confirm。现在 TiCDC 就可以访问 TiDB Cloud Premium。更多信息,请参见配置 IP 访问列表。
获取下游 TiDB Cloud Premium 实例的连接信息。
- 在 TiDB Cloud 控制台中,进入 My TiDB 页面,然后点击目标 TiDB Cloud Premium 实例的名称,进入其实例概览页面。
- 点击右上角的 Connect。
- 在连接对话框中,从 Connection Type 下拉列表中选择 Public,并从 Connect With 下拉列表中选择 General。
- 从连接信息中,你可以获取该实例的 host IP 地址和端口。更多信息,请参见通过公网连接。
创建并运行增量复制任务。在上游集群中,运行以下命令:
tiup cdc cli changefeed create \ --pd=http://172.16.6.122:2379 \ --sink-uri="tidb://root:123456@172.16.6.125:4000" \ --changefeed-id="upstream-to-downstream" \ --start-ts="431434047157698561"--pd:上游集群的 PD 地址。格式为:[upstream_pd_ip]:[pd_port]--sink-uri:复制任务的下游地址。请按照以下格式配置--sink-uri。当前,scheme 支持mysql、tidb、kafka、s3和local。[scheme]://[userinfo@][host]:[port][/path]?[query_parameters]--changefeed-id:复制任务的 ID。格式必须匹配 ^[a-zA-Z0-9]+(-[a-zA-Z0-9]+)*$ 正则表达式。如果未指定此 ID,TiCDC 会自动生成一个 UUID(version 4 格式)作为 ID。--start-ts:指定 changefeed 的起始 TSO。TiCDC 集群会从该 TSO 开始拉取数据。默认值为当前时间。
更多信息,请参见 TiCDC Changefeed 的 CLI 和配置参数。
在上游集群中重新启用 GC 机制。如果在增量复制中未发现错误或延迟,请启用 GC 机制以恢复集群的垃圾回收。
运行以下命令以验证设置是否生效。
SET GLOBAL tidb_gc_enable = TRUE;以下是一个输出示例,其中
1表示 GC 已启用。SELECT @@global.tidb_gc_enable; +-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 1 | +-------------------------+ 1 row in set (0.01 sec)验证增量复制任务。
如果输出中显示消息 "Create changefeed successfully!",则表示复制任务创建成功。
如果状态为
normal,则表示复制任务正常。tiup cdc cli changefeed list --pd=http://172.16.6.122:2379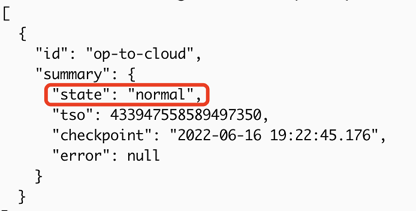
验证复制结果。向上游集群写入一条新记录,然后检查该记录是否已复制到下游 TiDB Cloud Premium 实例。
为上游集群和下游实例设置相同的时区。默认情况下,TiDB Cloud Premium 将时区设置为 UTC。如果上游集群和下游实例的时区不同,则需要为两者设置相同的时区。
在上游集群中,运行以下命令检查时区:
SELECT @@global.time_zone;在下游实例中,运行以下命令设置时区:
SET GLOBAL time_zone = '+08:00';再次检查时区以验证设置:
SELECT @@global.time_zone;
备份上游集群中的查询绑定,并在下游实例中恢复。你可以使用以下查询来备份查询绑定:
SELECT DISTINCT(CONCAT('CREATE GLOBAL BINDING FOR ', original_sql,' USING ', bind_sql,';')) FROM mysql.bind_info WHERE status='enabled';如果没有任何输出,则表示上游集群中未使用查询绑定。在这种情况下,你可以跳过此步骤。
获取查询绑定后,在下游实例中运行这些语句以恢复查询绑定。
备份上游集群中的用户和权限信息,并在下游实例中恢复。你可以使用以下脚本来备份用户和权限信息。请注意,你需要将占位符替换为实际值。
#!/bin/bash export MYSQL_HOST={tidb_op_host} export MYSQL_TCP_PORT={tidb_op_port} export MYSQL_USER=root export MYSQL_PWD={root_password} export MYSQL="mysql -u${MYSQL_USER} --default-character-set=utf8mb4" function backup_user_priv(){ ret=0 sql="SELECT CONCAT(user,':',host,':',authentication_string) FROM mysql.user WHERE user NOT IN ('root')" for usr in `$MYSQL -se "$sql"`;do u=`echo $usr | awk -F ":" '{print $1}'` h=`echo $usr | awk -F ":" '{print $2}'` p=`echo $usr | awk -F ":" '{print $3}'` echo "-- Grants for '${u}'@'${h}';" [[ ! -z "${p}" ]] && echo "CREATE USER IF NOT EXISTS '${u}'@'${h}' IDENTIFIED WITH 'mysql_native_password' AS '${p}' ;" $MYSQL -se "SHOW GRANTS FOR '${u}'@'${h}';" | sed 's/$/;/g' [ $? -ne 0 ] && ret=1 && break done return $ret } backup_user_priv获取用户和权限信息后,在下游 TiDB Cloud Premium 实例中运行生成的 SQL 语句,以恢复用户和权限信息。