配置 TiDB 以优化性能
本文档介绍如何优化 TiDB 的性能,包括:
- 常见工作负载的最佳实践。
- 针对复杂性能场景的优化策略。
概述
要实现 TiDB 的最佳性能,需要仔细调整各项设置。在许多情况下,实现最佳性能需要将配置调整为非默认值。
默认的配置优先考虑稳定性而非性能。若需获得更高性能,你可能需要采用更激进的配置,甚至启用实验特性。本文推荐的配置基于生产环境部署经验和性能优化实践。
本文介绍了非默认的配置方式,包括其优势和潜在权衡。请根据你的工作负载需求,参考这些信息来优化 TiDB 设置。
常见负载的关键配置
以下配置常用于优化 TiDB 性能:
- 增强执行计划缓存,如 Prepare 语句执行计划缓存、非 Prepare 语句执行计划缓存和实例级执行计划缓存。
- 通过 Optimizer Fix Controls 优化 TiDB 优化器的行为。
- 更积极地使用 Titan 存储引擎。
- 微调 TiKV 的 compaction 与流量控制配置,以确保写入密集型负载下的性能与稳定性。
这些配置可以显著提升多种工作负载的性能。但与任何优化一样,在部署到生产环境之前,请务必在你的环境中进行全面测试。
系统变量
执行以下 SQL 语句以应用推荐的配置:
SET GLOBAL tidb_enable_instance_plan_cache=on;
SET GLOBAL tidb_instance_plan_cache_max_size=2GiB;
SET GLOBAL tidb_enable_non_prepared_plan_cache=on;
SET GLOBAL tidb_ignore_prepared_cache_close_stmt=on;
SET GLOBAL tidb_analyze_column_options='ALL';
SET GLOBAL tidb_stats_load_sync_wait=2000;
SET GLOBAL tidb_opt_limit_push_down_threshold=10000;
SET GLOBAL tidb_opt_derive_topn=on;
SET GLOBAL tidb_runtime_filter_mode=LOCAL;
SET GLOBAL tidb_opt_enable_mpp_shared_cte_execution=on;
SET GLOBAL tidb_rc_read_check_ts=on;
SET GLOBAL tidb_guarantee_linearizability=off;
SET GLOBAL pd_enable_follower_handle_region=on;
SET GLOBAL tidb_opt_fix_control = '44262:ON,44389:ON,44823:10000,44830:ON,44855:ON,52869:ON';
下表说明了部分系统变量配置的作用及注意事项:
以下为 Optimizer Fix Controls 的详细说明,这些配置项可启用额外的优化能力:
44262:ON:当分区表缺少全局统计信息时,使用动态裁剪模式访问分区表。44389:ON:对形如c = 10 and (a = 'xx' or (a = 'kk' and b = 1))的过滤条件,尝试为IndexRangeScan更加完整地构造扫描范围,即range。44823:10000:为节省内存,计划缓存不会缓存参数数量超过该变量值的查询。将参数上限从默认的200提高到10000,使带有超长IN列表的查询也能命中计划缓存。44830:ON:允许计划缓存缓存物理优化阶段生成的包含PointGet算子的执行计划。44855:ON:当IndexJoin算子的Probe端包含Selection算子时,优化器会选择IndexJoin。52869:ON:如果优化器能够为查询计划选择单索引扫描方法(非全表扫描),优化器会自动选择索引合并 index merge。
TiKV 配置
在 TiKV 配置文件中添加如下配置项:
[server]
concurrent-send-snap-limit = 64
concurrent-recv-snap-limit = 64
snap-io-max-bytes-per-sec = "400MiB"
[rocksdb]
max-manifest-file-size = "256MiB"
[rocksdb.titan]
enabled = true
[rocksdb.defaultcf.titan]
min-blob-size = "1KB"
blob-file-compression = "zstd"
[storage]
scheduler-pending-write-threshold = "512MiB"
[storage.flow-control]
l0-files-threshold = 50
soft-pending-compaction-bytes-limit = "512GiB"
[rocksdb.writecf]
level0-slowdown-writes-trigger = 20
soft-pending-compaction-bytes-limit = "192GiB"
[rocksdb.defaultcf]
level0-slowdown-writes-trigger = 20
soft-pending-compaction-bytes-limit = "192GiB"
[rocksdb.lockcf]
level0-slowdown-writes-trigger = 20
soft-pending-compaction-bytes-limit = "192GiB"
下表简要说明主要配置项及注意事项:
请注意,上述表格中的压缩与流控参数调整,主要适用于以下规格的 TiKV 部署实例:
- CPU:32 核
- 内存:128 GiB
- 存储:5 TiB EBS
- 磁盘吞吐:1 GiB/s
写入密集型负载推荐调整
为优化 TiKV 在写入密集型负载下的性能与稳定性,建议根据实例的硬件规格,调整部分压缩与流控参数。例如:
rocksdb.rate-bytes-per-sec:通常建议保持默认值。如果发现压缩 I/O 占用了大量磁盘带宽,可将该速率限制为磁盘最大吞吐量的 60% 左右,以平衡压缩与前台写入,避免磁盘饱和。例如,若磁盘吞吐为 1 GiB/s,可设置为约600MiB。storage.flow-control.soft-pending-compaction-bytes-limit和storage.flow-control.hard-pending-compaction-bytes-limit:可根据磁盘空间适当提高这两个阈值(如分别设置为 1 TiB 和 2 TiB),为压缩进程提供更大的缓冲空间。
这些设置有助于提升资源利用率,并减少写入高峰期的潜在瓶颈。
TiFlash-learner 配置
在 TiFlash-learner 配置文件中添加如下内容:
[server]
snap-io-max-bytes-per-sec = "300MiB"
Benchmark
本节对比了默认配置(基线)与基于前文常见负载的关键配置优化后的性能表现。
在 1000 张表上运行的 Sysbench 负载
测试环境
测试环境如下:
- 3 台 TiDB 服务器(16 核 CPU,64 GiB 内存)
- 3 台 TiKV 服务器(16 核 CPU,64 GiB 内存)
- TiDB 版本:v8.4.0
- 测试负载:sysbench oltp_read_only
性能对比
下表对比了基线配置与优化配置下的吞吐量、延迟和执行计划缓存命中率。
主要优势
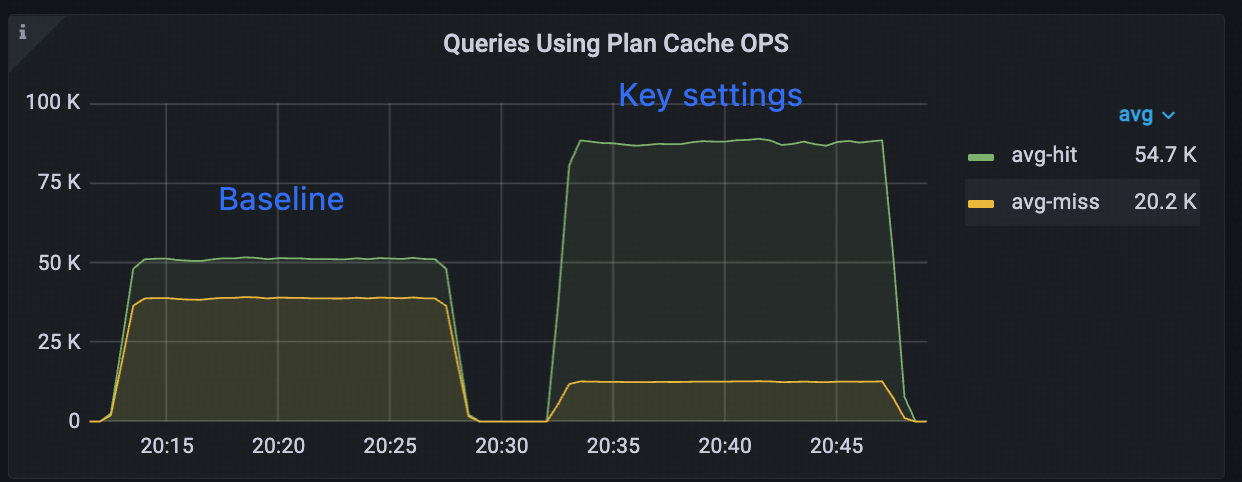
相比基线配置,实例级执行计划缓存 (Instance Plan Cache) 带来了显著的性能提升:
更高的命中率:提升 53.82%(从 56.89% 增加到 87.51%)。
更低的内存占用:降低 26.34%(从 95.3 MiB 降至 70.2 MiB)。
更优的性能表现:
- QPS 提升 12.38%。
- 平均延迟降低 11.01%。
- P95 延迟降低 13.41%。
工作原理
实例级执行计划缓存通过以下机制提升性能:
- 将
SELECT语句的执行计划缓存在内存中。 - 在同一 TiDB 实例的所有连接(最多 200 个)之间共享缓存的执行计划。
- 可高效存储多达 1000 张表、5000 条
SELECT语句的执行计划。 - 仅
BEGIN和COMMIT语句会出现缓存未命中的情况。
实际应用收益
虽然基于简单 sysbench oltp_read_only 查询(每个执行计划约 14 KB)的基准测试仅显示了有限的提升,但在真实业务场景下,实例级执行计划缓存的收益会更显著:
- 复杂查询的执行速度可提升至原来的 20 倍。
- 相比会话级计划缓存,内存利用率更高。
实例级执行计划缓存特别适用于以下场景:
- 有大量列的大表。
- 复杂的 SQL 查询。
- 高并发连接。
- 多样化的查询模式。
内存效率
相比会话级计划缓存 (Session Plan Cache),实例级执行计划缓存 (Instance Plan Cache) 具有更高的内存利用率,原因如下:
- 执行计划在所有连接间共享
- 无需为每个会话重复存储执行计划
- 更高的内存利用率和更高的命中率
在多连接和复杂查询场景下,若使用会话级计划缓存,为达到类似命中率需消耗更多内存,因此实例级计划缓存更高效。
测试负载
执行以下 sysbench oltp_read_only prepare 命令加载数据:
sysbench oltp_read_only prepare --mysql-host={host} --mysql-port={port} --mysql-user=root --db-driver=mysql --mysql-db=test --threads=100 --time=900 --report-interval=10 --tables=1000 --table-size=10000
执行以下 sysbench oltp_read_only run 命令运行测试负载:
sysbench oltp_read_only run --mysql-host={host} --mysql-port={port} --mysql-user=root --db-driver=mysql --mysql-db=test --threads=200 --time=900 --report-interval=10 --tables=1000 --table-size=10000
更多信息,请参阅如何用 Sysbench 测试 TiDB。
大记录值下的 YCSB 测试负载
测试环境
测试环境如下:
- 3 台 TiDB 服务器(16 核 CPU,64 GiB 内存)
- 3 台 TiKV 服务器(16 核 CPU,64 GiB 内存)
- TiDB 版本:v8.4.0
- 测试负载:go-ycsb workloada
性能对比
下表对比了基线配置与优化配置下的吞吐量(每秒操作数,OPS)。
性能分析
从 v7.6.0 开始,Titan 默认启用。在 TiDB v8.4.0 中,Titan 的 min-blob-size 默认值为 32KiB。在此测试中,基线配置采用 31KiB 的记录大小,以确保数据主要存储在 RocksDB 中。而在关键配置中,将 min-blob-size 设置为 1KiB,使数据存储在 Titan 中。
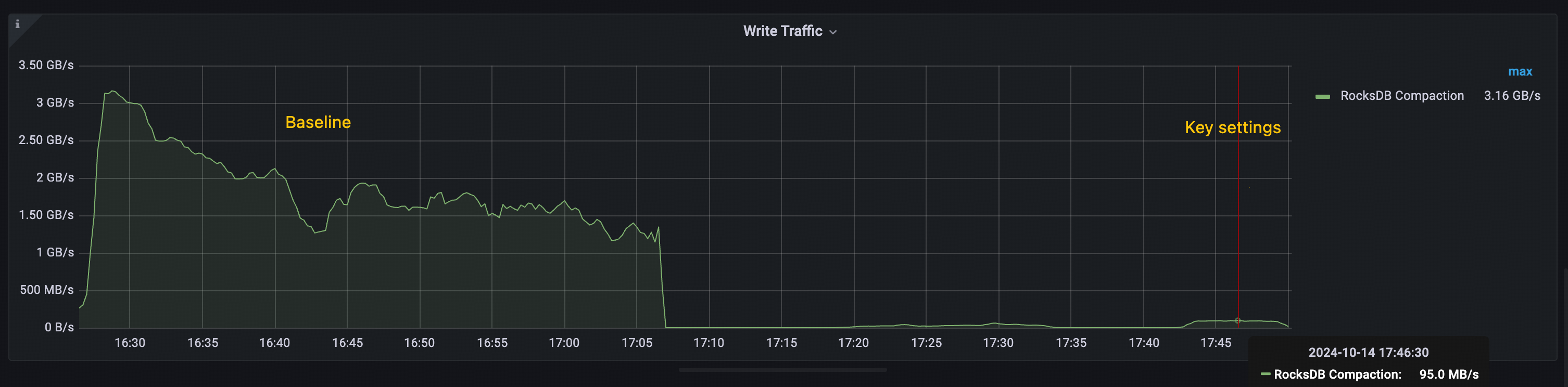
关键配置下的性能提升,主要归因于 Titan 显著减少了 RocksDB 的压缩操作。如下图所示:
- 基线配置:RocksDB 压缩总吞吐量超过 1 GiB/s,峰值超过 3 GiB/s。
- 关键配置:RocksDB 压缩峰值吞吐量低于 100 MiB/s。
压缩开销的大幅降低有助于整体吞吐量的提升,这一提升体现在关键参数配置的优化效果中。
测试负载
执行以下 go-ycsb load 命令加载数据:
go-ycsb load mysql -P /ycsb/workloads/workloada -p {host} -p mysql.port={port} -p threadcount=100 -p recordcount=5000000 -p operationcount=5000000 -p workload=core -p requestdistribution=uniform -pfieldcount=31 -p fieldlength=1024
执行以下 go-ycsb run 命令运行测试负载:
go-ycsb run mysql -P /ycsb/workloads/workloada -p {host} -p mysql.port={port} -p mysql.db=test -p threadcount=100 -p recordcount=5000000 -p operationcount=5000000 -p workload=core -prequestdistribution=uniform -p fieldcount=31 -p fieldlength=1024
边缘场景与专项优化
本节介绍如何针对特定场景进行专项优化,帮助你在基础参数调优的基础上,根据实际业务需求对 TiDB 进行更有针对性的配置和调整。
识别边缘场景
执行以下步骤识别边缘场景:
- 分析查询模式和负载特征。
- 监控系统指标,定位性能瓶颈。
- 收集应用团队关于具体问题的反馈。
常见边缘场景
以下列举了一些常见的边缘场景:
- 高频小查询导致 TSO 等待时间过高
- 针对不同负载选择合适的最大 chunk 大小
- 针对读密集型负载调优 coprocessor cache
- 根据负载特性优化 chunk 大小
- 针对不同负载优化事务模式和 DML 类型
- 通过 TiKV 下推优化
GROUP BY和DISTINCT操作 - 使用内存引擎缓解 MVCC 版本积压
- 批量操作期间优化统计信息收集
- 针对不同实例类型优化线程池设置
后续小节将分别介绍如何应对这些场景。针对每种情况,你需要调整不同参数或使用 TiDB 的特定功能。
高频小查询导致 TSO 等待时间过高
问题排查
如果你的业务负载包含大量高频小事务或频繁请求时间戳的查询,TSO (Timestamp Oracle) 可能成为性能瓶颈。你可以通过 Performance Overview > SQL Execute Time Overview 面板检查 TSO 等待时间是否在 SQL 执行时间中占据较大比例。如果 TSO 等待时间较高,可考虑以下优化措施:
- 对于不需要严格一致性的读操作,启用低精度 TSO (
tidb_low_resolution_tso)。详见方案 1:低精度 TSO。 - 尽量将多个小事务合并为较大的事务。详见方案 2:TSO 请求并行模式。
方案 1:低精度 TSO
你可以通过启用低精度 TSO 功能 (tidb_low_resolution_tso) 来减少 TSO 等待时间。启用后,TiDB 会使用缓存的时间戳进行读取,从而降低 TSO 等待,但可能会读取到过时的数据。
此优化特别适用于以下场景:
- 以读操作为主且对数据新鲜度要求不高的负载。
- 对查询延迟要求高于绝对一致性的场景。
- 应用可以容忍读取到几秒内历史数据的场景。
优势与权衡:
- 通过启用使用缓存 TSO 的读取过时数据的功能,可以减少查询延迟,无需请求新的时间戳。
- 在性能与数据一致性之间取得平衡:该功能仅适用于可接受读取过时数据的场景。不建议在需要严格数据一致性的场景中使用。
启用方法:
SET GLOBAL tidb_low_resolution_tso=ON;
方案 2:TSO 请求并行模式
tidb_tso_client_rpc_mode 系统变量用于切换 TiDB 向 PD 发送 TSO RPC 请求的模式。默认值为 DEFAULT。当满足以下条件时,可以考虑将该变量切换为 PARALLEL 或 PARALLEL-FAST,以获得潜在的性能提升:
- TSO 等待时间在 SQL 查询总执行时间中占比较高。
- PD 的 TSO 分配尚未成为瓶颈。
- PD 和 TiDB 节点的 CPU 资源充足。
- TiDB 与 PD 之间的网络延迟明显高于 PD 分配 TSO 的耗时(即 TSO RPC 的耗时主要由网络延迟决定)。
- 你可以通过 Grafana TiDB 面板的 PD Client > PD TSO RPC Duration 查看 TSO RPC 请求耗时。
- 你可以通过 Grafana PD 面板的 TiDB > PD server TSO handle duration 查看 PD 分配 TSO 的耗时。
- TiDB 与 PD 之间因更多 TSO RPC 请求(
PARALLEL模式下为 2 倍,PARALLEL-FAST模式下为 4 倍)带来的额外网络流量在可接受范围内。
切换并行模式的方法如下:
-- 使用 PARALLEL 模式
SET GLOBAL tidb_tso_client_rpc_mode=PARALLEL;
-- 使用 PARALLEL-FAST 模式
SET GLOBAL tidb_tso_client_rpc_mode=PARALLEL-FAST;
针对读密集型负载调优下推计算结果缓存 (Coprocessor Cache)
通过优化下推计算结果缓存,可以提升读密集型负载下的查询性能。该缓存用于存储协处理器请求的结果,减少对热点数据的重复计算。优化建议如下:
- 通过下推计算结果缓存监控面板观察缓存命中率。
- 增大缓存容量,以提升大工作集下的命中率。
- 根据查询模式调整缓存准入阈值。
以下为读密集型负载的推荐配置:
[tikv-client.copr-cache]
capacity-mb = 4096
admission-max-ranges = 5000
admission-max-result-mb = 10
admission-min-process-ms = 0
根据负载特性优化 chunk 大小
tidb_max_chunk_size 系统变量用于设置执行过程中每个 chunk 的最大行数。根据不同负载调整该值,可提升查询性能。
对于高并发、小事务的 OLTP 负载:
建议设置为
128~256(默认值为1024)。可降低内存占用,提升 limit 查询的速度。
适用场景:点查、小范围扫描。
SET GLOBAL tidb_max_chunk_size = 128;
对于复杂查询、大结果集的 OLAP 或分析型负载:
建议将其值设置为
1024~4096。扫描大量数据时可提升吞吐量。
适用场景:聚合、大表扫描。
SET GLOBAL tidb_max_chunk_size = 4096;
针对不同负载优化事务模式与 DML 类型
TiDB 提供多种事务模式和 DML 执行类型,你可以根据不同负载模式优化性能。
事务模式
你可以通过 tidb_txn_mode 系统变量设置事务模式。
悲观事务模式(默认模式):
- 适用于可能存在写冲突的一般负载。
- 提供更强的一致性保障。
SET SESSION tidb_txn_mode = "pessimistic";- 适用于写冲突较少的负载。
- 多语句事务下性能更优。
- 示例:
BEGIN; INSERT...; INSERT...; COMMIT;。
SET SESSION tidb_txn_mode = "optimistic";
DML 类型
你可以通过 tidb_dml_type 系统变量(自 v8.0.0 引入)控制 DML 语句的执行模式。
如需使用批量 DML 执行模式,将 tidb_dml_type 设置为 "bulk"。该模式适用于无冲突的大批量数据写入,可降低大规模写入时的内存消耗。使用前请确保:
- 已开启自动提交事务
autocommit。 pessimistic-auto-commit配置项设置为false。
SET SESSION tidb_dml_type = "bulk";
使用 TiKV 下推优化 GROUP BY 和 DISTINCT 操作
TiDB 支持将聚合操作下推到 TiKV 层执行,以减少数据传输和处理开销。性能提升幅度取决于数据分布和查询特征。
适用场景
理想场景(性能提升明显):
- 分组列的基数较低(NDV 较小)。
- 数据中存在大量重复值。
- 典型示例:状态字段、类别编码、日期分组等。
非理想场景(可能出现性能下降):
- 分组列的基数很高(NDV 较大)。
- 不重复的标识符或时间戳。
- 典型示例:用户 ID、交易 ID 等。
配置方法
你可以在会话级或全局级别启用聚合下推优化:
-- 开启常规聚合下推
SET GLOBAL tidb_opt_agg_push_down = ON;
-- 开启 distinct 聚合下推
SET GLOBAL tidb_opt_distinct_agg_push_down = ON;
使用内存引擎缓解 MVCC 版本积压
在高读写热点区域或垃圾回收、压缩不及时的情况下,过多的 MVCC 版本会导致性能瓶颈。自 v8.5.0 起,你可以通过启用 TiKV MVCC 内存引擎 (In-Memory Engine, IME) 来缓解该问题。只需在 TiKV 配置文件中添加如下内容:
[in-memory-engine]
enable = true
在批量操作期间优化统计信息收集
通过管理统计信息的收集方式,可以在保持查询优化能力的同时提升批量操作的性能。本节介绍如何有效管理该过程。
何时关闭自动统计信息分析 (Auto Analyze)
在以下场景中,可以通过将系统变量 tidb_enable_auto_analyze 设置为 OFF 来关闭自动统计信息分析:
- 进行大规模数据导入时。
- 执行批量更新操作时。
- 处理对时间敏感的批处理任务时。
- 需要完全控制统计信息收集时机时。
最佳实践
批量操作之前:
-- 关闭自动 analyze SET GLOBAL tidb_enable_auto_analyze = OFF;批量操作之后:
-- 手动收集统计信息 ANALYZE TABLE your_table; -- 重新开启自动 analyze SET GLOBAL tidb_enable_auto_analyze = ON;
为不同实例类型优化线程池设置
为提升 TiKV 的性能,应根据实例的 CPU 资源配置线程池。你可以参考以下原则进行优化:
对于 8 至 16 核的实例,默认设置通常已经足够。
对于 32 核及以上的实例,建议增大线程池大小,以更充分地利用资源。可按如下方式调整设置:
[server] # 增大 gRPC 线程池 grpc-concurrency = 10 [raftstore] # 针对写密集型负载进行优化 apply-pool-size = 4 store-pool-size = 4 store-io-pool-size = 2