常规统计信息
TiDB 使用统计信息作为优化器的输入,用于估算 SQL 语句的执行计划中每个步骤处理的行数。优化器会估算每个可用执行计划的成本,包括索引的选择和表连接的顺序,并为每个可用执行计划生成成本。然后,优化器会选择总体成本最低的执行计划。
收集统计信息
本小节介绍收集统计信息的两种方式:自动更新和手动收集。
自动更新
对于 INSERT、DELETE 或 UPDATE 语句,TiDB 会自动更新统计信息中表的总行数和修改的行数。
TiDB 会定期持久化更新的统计信息,更新周期为 20 * stats-lease。stats-lease 配置项的默认值为 3s,如果将其指定为 0,TiDB 将停止自动更新统计信息。
TiDB 根据表的变更次数自动调度 ANALYZE 来收集这些表的统计信息。统计信息的自动更新由下表中的系统变量控制。
当某个表 tbl 的修改行数与总行数的比值大于 tidb_auto_analyze_ratio,并且当前时间在 tidb_auto_analyze_start_time 和 tidb_auto_analyze_end_time 之间时,TiDB 会在后台执行 ANALYZE TABLE tbl 语句自动更新这个表的统计信息。
为了避免小表因为少量数据修改而频繁触发自动更新,当表的行数小于 1000 时,TiDB 不会触发对此表的自动更新。你可以通过 SHOW STATS_META 语句来查看表的行数。
手动收集
目前 TiDB 收集统计信息为全量收集。你可以通过 ANALYZE TABLE 语句的以下语法来全量收集统计信息:
收集
TableNameList中所有表的统计信息:ANALYZE TABLE TableNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];WITH NUM BUCKETS用于指定生成直方图的桶数量上限。WITH NUM TOPN用于指定生成的TOPN数量的上限。WITH NUM CMSKETCH DEPTH用于指定 CM Sketch 的长。WITH NUM CMSKETCH WIDTH用于指定 CM Sketch 的宽。WITH NUM SAMPLES用于指定采样的数目。WITH FLOAT_NUM SAMPLERATE用于指定采样率。
WITH NUM SAMPLES 与 WITH FLOAT_NUM SAMPLERATE 这两种设置对应了两种不同的收集采样的算法。
相关详细解释参见直方图、Top-N 值 and CMSketch (Count-Min Sketch)。关于 SAMPLES 和 SAMPLERATE,参见提升统计信息收集性能。
关于持久化 ANALYZE 配置以便后续沿用的更多信息,参见持久化 ANALYZE 配置。
统计信息的类型
本小节介绍统计信息的三种类型:直方图、Count-Min Sketch 和 Top-N。
直方图
直方图统计信息被优化器用于估算区间或范围谓词的选择,并可能用于确定列中不同值的数量,以估算 Version 2 统计信息(参见统计信息版本)中的等值查询或 IN 查询的谓词。
直方图是对数据分布的近似表示。它将整个数值范围划分为一系列桶,并使用简单的数据来描述每个桶,例如落入该桶的数值数量。在 TiDB 中,会为每个表的具体列创建等深直方图,可用于估算区间查询。
等深直方图,就是让落入每个桶里的数值数量尽量相等。例如,对于给定的集合 {1.6, 1.9, 1.9, 2.0, 2.4, 2.6, 2.7, 2.7, 2.8, 2.9, 3.4, 3.5} 生成 4 个桶,那么最终的等深直方图就会如下图所示,包含四个桶 [1.6, 1.9],[2.0, 2.6],[2.7, 2.8],[2.9, 3.5],其桶深均为 3。
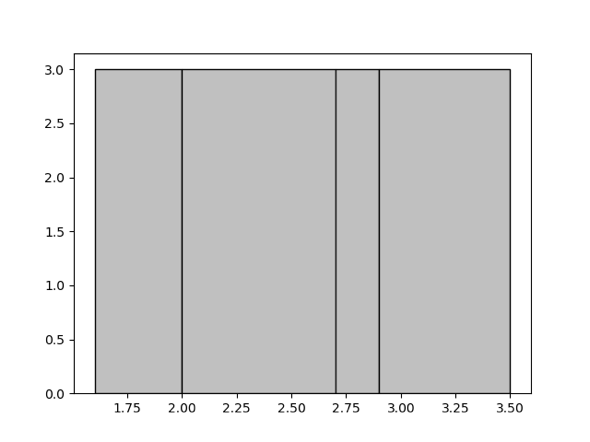
你可以通过 WITH NUM BUCKETS 参数控制直方图的桶数量上限,参见手动收集小节。桶数量越多,直方图的估算精度就越高,不过也会同时增加统计信息的内存使用。可以视具体情况来调整桶的数量上限。
Count-Min Sketch
Count-Min Sketch 是一种哈希结构,当处理等值查询(如 a = 1)或者 IN 查询(如 a in (1, 2, 3))时,TiDB 便会使用这种数据结构来进行估算。
由于 Count-Min Sketch 是一个哈希结构,就有出现哈希冲突的可能。当在 EXPLAIN 语句中发现等值查询的估算偏离实际值较大时,就可以认为是一个比较大的值和一个比较小的值被哈希到了一起。这时有以下两种方法来避免哈希冲突:
- 修改
WITH NUM TOPN参数。TiDB 会将出现频率前 x 的数据单独储存,之后的数据再储存到 Count-Min Sketch 中。因此,为了避免一个比较大的值和一个比较小的值被哈希到一起,可以调大WITH NUM TOPN的值。该参数的默认值是20,最大值是1024。关于该参数的更多信息,参见手动收集小节。 - 修改
WITH NUM CMSKETCH DEPTH和WITH NUM CMSKETCH WIDTH两个参数。这两个参数会影响哈希的桶数和冲突概率,可视具体情况适当调大这两个参数的值来减少冲突概率,不过调大后也会增加统计信息的内存使用。WITH NUM CMSKETCH DEPTH的默认值是5,WITH NUM CMSKETCH WIDTH的默认值是2048。关于这两个参数的更多信息,参见手动收集小节。
Top-N
Top-N 值是列或索引中出现次数前 N 的值。Top-N 统计信息通常被称为频率统计信息或数据倾斜。
TiDB 会记录 Top-N 的值和出现次数。参数 WITH NUM TOPN 控制 Top-N 值的数量,默认值是 20,表示收集出现频率最高的前 20 个值;最大值是 1024。关于该参数的详细信息,参见手动收集小节。
选择性收集统计信息
本小节介绍如何选择性地收集统计信息。
收集索引的统计信息
如果要收集 TableName 中 IndexNameList 里所有索引的统计信息,请使用以下语法:
ANALYZE TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
当 IndexNameList 为空时,该语法将收集 TableName 中所有索引的统计信息。
收集部分列的统计信息
当 TiDB 执行 SQL 语句时,优化器在大多数情况下只会用到部分列的统计信息。例如,WHERE、JOIN、ORDER BY、GROUP BY 子句中出现的列,这些被用到的列称为 PREDICATE COLUMNS。
如果一个表有很多列,收集所有列的统计信息会产生较大的开销。为了降低开销,你可以只收集选定列或者 PREDICATE COLUMNS 的统计信息供优化器使用。如果要持久化列配置以便将来沿用,参见持久化列配置。
如果要收集指定列的统计信息,请使用以下语法:
ANALYZE TABLE TableName COLUMNS ColumnNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];其中,
ColumnNameList表示指定列的名称列表。如果需要指定多列,请使用用逗号,分隔列名。例如,ANALYZE table t columns a, b。该语法除了收集指定表中指定列的统计信息,将同时收集该表中索引列的统计信息以及所有索引的统计信息。如果要收集
PREDICATE COLUMNS的统计信息,请使用以下语法:ANALYZE TABLE TableName PREDICATE COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];TiDB 将每隔 100 *
stats-lease的时间将PREDICATE COLUMNS信息写入系统表mysql.column_stats_usage。以上语法除了收集指定表中
PREDICATE COLUMNS的统计信息之外,将同时收集该表中索引列的统计信息以及所有索引的统计信息。如果要收集所有列的统计信息以及所有索引的统计信息,请使用以下语法:
ANALYZE TABLE TableName ALL COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
收集分区的统计信息
如果要收集
TableName中PartitionNameList里所有分区的统计信息,请使用以下语法:ANALYZE TABLE TableName PARTITION PartitionNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];如果要收集
TableName中PartitionNameList里所有分区的索引统计信息,请使用以下语法:ANALYZE TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];当收集分区的统计信息时,如果只需要收集部分列的统计信息,请使用以下语法:
ANALYZE TABLE TableName PARTITION PartitionNameList [COLUMNS ColumnNameList|PREDICATE COLUMNS|ALL COLUMNS] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
收集动态裁剪模式下的分区表统计信息
在分区表开启动态裁剪模式(从 v6.3.0 开始,默认开启)的情况下,TiDB 将收集表级别的汇总统计信息,即分区表的全局统计信息。分区表的全局统计信息合并汇总了所有分区的统计信息。在动态裁剪模式下,表中任何分区的统计信息更新都可能触发该表全局统计信息的更新。
如果某些分区的统计信息为空,或者某些分区中列的统计信息有缺失,那么统计信息收集行为将受 tidb_skip_missing_partition_stats 变量的控制:
当触发全局统计信息更新且
tidb_skip_missing_partition_stats为OFF时:- 如果某些分区缺失统计信息(例如从未进行过 analyze 的新分区),全局统计信息生成会中断,并显示 warning 信息提示这些分区没有可用的统计信息。
- 如果某些分区中缺失某些列的统计信息(这些分区中指定了不同的列进行 analyze),当这些列的统计信息被合并汇总时,全局统计信息生成会中断,并显示 warning 信息提示某些分区中缺少某些列的统计信息。
当触发全局统计信息更新且
tidb_skip_missing_partition_stats为ON时:- 如果某些分区缺失全部列或部分列的统计信息,TiDB 在生成全局统计信息时会跳过这些缺失的分区统计信息,不影响全局统计信息的生成。
在动态裁剪模式下,分区和分区表的 ANALYZE 配置应保持一致。因此,如果在 ANALYZE TABLE TableName PARTITION PartitionNameList 语句后指定了 COLUMNS 配置或在 WITH 后指定了 OPTIONS 配置,TiDB 将忽略这些配置并返回 warning 信息提示。
提升统计信息收集性能
TiDB 提供了两种方法来提升统计信息收集的性能:
- 收集列的子集的统计信息。参见收集部分列的统计信息。
- 采样。参见统计信息采样。
统计信息采样
采样是通过 ANALYZE 语句的两个选项来实现的,每个选项对应一种不同的收集算法:
WITH NUM SAMPLES指定了采样集的大小,在 TiDB 中是以蓄水池采样的方式实现。当表较大时,不推荐使用这种方式收集统计信息。因为蓄水池采样中间结果集会产生一定的冗余结果,会对内存等资源造成额外的压力。WITH FLOAT_NUM SAMPLERATE是从 v5.3.0 开始引入的采样方式,指定了采样率的大小,取值范围是(0, 1]。在 TiDB 中是以伯努利采样的方式实现,更适合对较大的表进行采样,在收集效率和资源使用上更有优势。
在 v5.3.0 之前,TiDB 采用蓄水池采样的方式收集统计信息。自 v5.3.0 版本起,TiDB Version 2 的统计信息默认会选取伯努利采样的方式收集统计信息。若要重新使用蓄水池采样的方式采样,可以使用 WITH NUM SAMPLES 语句。
目前采样率基于自适应算法进行计算。当你通过 SHOW STATS_META 可以观察到一个表的行数时,可通过这个行数去计算采集 10 万行所对应的采样率。如果你观察不到这个值,可通过表 SHOW TABLE REGIONS 结果中所有 APPROXIMATE_KEYS 列值的总和作为另一个参考来计算采样率。
统计信息收集的内存限制
TiDB 从 v6.1.0 开始引入了统计信息收集的内存限制,你可以通过 tidb_mem_quota_analyze 变量来控制 TiDB 更新统计信息时的最大总内存占用。
要合理地配置 tidb_mem_quota_analyze 的值,你需要考虑集群的数据规模。在使用默认采样率的情况下,主要考虑列的数量、列值的大小,以及 TiDB 的内存配置。你可参考以下建议来配置该变量的最大值和最小值:
- 最小值:需要大于 TiDB 从集群上列最多的表收集统计信息时使用的最大内存。一个粗略的参考信息是,在测试集上,20 列的表在默认配置下,统计信息收集的最大内存使用量约为 800 MiB;160 列的表在默认配置下,统计信息收集的最大内存使用量约为 5 GiB。
- 最大值:需要小于集群在不进行统计信息收集时的内存空余量。
持久化 ANALYZE 配置
从 v5.4.0 起,TiDB 支持 ANALYZE 配置持久化,方便后续收集统计信息时沿用已有配置。
TiDB 支持以下 ANALYZE 配置的持久化:
开启 ANALYZE 配置持久化
ANALYZE 配置持久化功能默认开启,即系统变量 tidb_analyze_version 为默认值 2,tidb_persist_analyze_options 为默认值 ON。
ANALYZE 配置持久化功能可用于记录手动执行 ANALYZE 语句时指定的持久化配置。记录后,当 TiDB 下一次自动更新统计信息或者你手动收集统计信息但未指定配置时,TiDB 会按照记录的配置收集统计信息。
如果要查询某张表上的持久化配置用于自动更新统计信息,使用以下 SQL 语句:
SELECT sample_num, sample_rate, buckets, topn, column_choice, column_ids FROM mysql.analyze_options opt JOIN information_schema.tables tbl ON opt.table_id = tbl.tidb_table_id WHERE tbl.table_schema = '{db_name}' AND tbl.table_name = '{table_name}';
TiDB 会使用最新的 ANALYZE 语句中指定的配置覆盖先前记录的持久化配置。例如,如果你运行 ANALYZE TABLE t WITH 200 TOPN; ,它将在 ANALYZE 语句中设置前 200 个值。随后,执行 ANALYZE TABLE t WITH 0.1 SAMPLERATE; 将为自动 ANALYZE 语句同时设置前 200 个值和 0.1 的采样率,类似于 ANALYZE TABLE t WITH 200 TOPN, 0.1 SAMPLERATE;。
关闭 ANALYZE 配置持久化
如果要关闭 ANALYZE 配置持久化功能,请将系统变量 tidb_persist_analyze_options 设置为 OFF。此外,由于 ANALYZE 配置持久化功能在 tidb_analyze_version = 1 的情况下不适用,因此设置 tidb_analyze_version = 1 同样会达到关闭配置持久化的效果。
关闭 ANALYZE 配置持久化功能后,已持久化的配置记录不会被清除。因此,当再次开启该功能时,TiDB 会继续使用之前记录的持久化配置收集统计信息。
持久化列配置
如果要持久化 ANALYZE 语句中列的配置(包括 COLUMNS ColumnNameList、PREDICATE COLUMNS、ALL COLUMNS),请将系统变量 tidb_persist_analyze_options 的值设置为 ON,以开启持久化 ANALYZE 配置功能。开启 ANALYZE 配置持久化之后:
- 当 TiDB 自动收集统计信息或者你手动执行
ANALYZE语句收集统计信息但未指定列的配置时,TiDB 会继续沿用之前持久化的配置。 - 当多次手动执行
ANALYZE语句并指定列的配置时,TiDB 会使用最新一次ANALYZE指定的配置项覆盖上一次记录的持久化配置。
如果要查看一个表中哪些列是 PREDICATE COLUMNS、哪些列的统计信息已经被收集,请使用 SHOW COLUMN_STATS_USAGE 语句。
在以下示例中,执行 ANALYZE TABLE t PREDICATE COLUMNS; 后,TiDB 将收集 b、c、d 列的统计信息,其中 b 列是 PREDICATE COLUMN,c 列和 d 列是索引列。
CREATE TABLE t (a INT, b INT, c INT, d INT, INDEX idx_c_d(c, d));
Query OK, 0 rows affected (0.00 sec)
-- 在此查询中优化器用到了 b 列的统计信息。
SELECT * FROM t WHERE b > 1;
Empty set (0.00 sec)
-- 等待一段时间(100 * stats-lease)后,TiDB 将收集的 `PREDICATE COLUMNS` 写入 mysql.column_stats_usage。
-- 指定 `last_used_at IS NOT NULL` 表示显示 TiDB 收集到的 `PREDICATE COLUMNS`。
SHOW COLUMN_STATS_USAGE WHERE db_name = 'test' AND table_name = 't' AND last_used_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+------------------+
| test | t | | b | 2022-01-05 17:21:33 | NULL |
+---------+------------+----------------+-------------+---------------------+------------------+
1 row in set (0.00 sec)
ANALYZE TABLE t PREDICATE COLUMNS;
Query OK, 0 rows affected, 1 warning (0.03 sec)
-- 指定 `last_analyzed_at IS NOT NULL` 表示显示收集过统计信息的列。
SHOW COLUMN_STATS_USAGE WHERE db_name = 'test' AND table_name = 't' AND last_analyzed_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+---------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+---------------------+
| test | t | | b | 2022-01-05 17:21:33 | 2022-01-05 17:23:06 |
| test | t | | c | NULL | 2022-01-05 17:23:06 |
| test | t | | d | NULL | 2022-01-05 17:23:06 |
+---------+------------+----------------+-------------+---------------------+---------------------+
3 rows in set (0.00 sec)
统计信息版本
系统变量 tidb_analyze_version 用于控制 TiDB 收集统计信息的行为。目前 TiDB 支持两个版本的统计信息,即 tidb_analyze_version = 1 和 tidb_analyze_version = 2。
- 从 v5.3.0 开始,变量
tidb_analyze_version的默认值从1变为了2。 - 如果从 v5.3.0 之前版本的集群升级至 v5.3.0 或之后的版本,该变量的默认值不会发生变化。
推荐使用统计信息版本 2 。与版本 1 相比,版本 2 提高了大数据量场景下多项统计信息的准确性。此外,版本 2 在进行谓词选择率估算时不再需要收集 Count-Min Sketch 统计信息,从而提高了收集性能。
以下表格列出了两个统计信息版本为优化器估算收集的信息:
切换统计信息版本
建议所有表、索引和分区使用相同的统计信息版本。如果你的集群仍在使用统计信息版本 1,请尽快迁移至统计信息版本 2。在为某个对象(例如表、索引或分区)收集到 Version 2 的统计信息之前,TiDB 会继续使用该对象现有的 Version 1 统计信息。
迁移的一个主要原因是,版本 1 可能对等值/IN 谓词产生不准确的估算,因为 Count-Min Sketch 可能存在哈希冲突。更多信息,请参阅 Count-Min Sketch。为避免此问题,请设置 tidb_analyze_version = 2 并对所有对象重新运行 ANALYZE。
要为从统计信息版本 1 迁移到统计信息版本 2 做好 ANALYZE 准备,请根据情况进行以下操作:
如果
ANALYZE语句是手动执行的,请手动统计每张需要统计的表:SELECT DISTINCT(CONCAT('ANALYZE TABLE ', table_schema, '.', table_name, ';')) FROM information_schema.tables JOIN mysql.stats_histograms ON table_id = tidb_table_id WHERE stats_ver = 1;如果
ANALYZE语句是由 TiDB 自动执行的(当开启自动更新统计信息时),在你设置tidb_analyze_version = 2后,TiDB 会通过后续的 Auto Analyze 逐步将统计信息刷新至版本 2。在为某个对象收集到版本 2 的统计信息之前,TiDB 可以继续使用其现有的版本 1 统计信息。若要加速重要对象的迁移,请手动对其运行ANALYZE。如果上一条语句的返回结果太长,不方便复制粘贴,可以将结果导出到临时文件后,再执行:
SELECT DISTINCT ... INTO OUTFILE '/tmp/sql.txt'; mysql -h ${TiDB_IP} -u user -P ${TIDB_PORT} ... < '/tmp/sql.txt'
查看统计信息
你可以使用一些 SQL 语句来查看 ANALYZE 的状态和统计信息的情况。
ANALYZE 状态
在执行 ANALYZE 语句时,可以使用 SHOW ANALYZE STATUS 语句来查看当前 ANALYZE 的状态。
从 TiDB v6.1.0 起,执行 SHOW ANALYZE STATUS 语句将显示集群级别的任务,且 TiDB 重启后仍能看到重启之前的任务记录。在 TiDB v6.1.0 之前,执行 SHOW ANALYZE STATUS 语句仅显示实例级别的任务,且 TiDB 重启后任务记录会被清空。
SHOW ANALYZE STATUS 仅显示最近的任务记录。从 TiDB v6.1.0 起,你可以通过系统表 mysql.analyze_jobs 查看过去 7 天内的历史记录。
当设置了系统变量 tidb_mem_quota_analyze 且 TiDB 后台的统计信息自动更新任务的内存占用超过了这个阈值时,自动更新任务会重试。失败的任务和重试的任务都可以在 SHOW ANALYZE STATUS 语句的执行结果中查看。
当 tidb_max_auto_analyze_time 大于 0 时,如果后台统计信息自动更新任务的执行时间超过这个阈值,该任务会被终止。
语法如下:
SHOW ANALYZE STATUS [ShowLikeOrWhere];
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| Table_schema | Table_name | Partition_name | Job_info | Processed_rows | Start_time | End_time | State | Fail_reason |
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| test | sbtest1 | | retry auto analyze table all columns with 100 topn, 0.055 samplerate | 2000000 | 2022-05-07 16:41:09 | 2022-05-07 16:41:20 | finished | NULL |
| test | sbtest1 | | auto analyze table all columns with 100 topn, 0.5 samplerate | 0 | 2022-05-07 16:40:50 | 2022-05-07 16:41:09 | failed | analyze panic due to memory quota exceeds, please try with smaller samplerate |
表的元信息
你可以使用 SHOW STATS_META 语句来查看表的总行数以及修改的行数等信息。
表的健康度信息
你可以使用 SHOW STATS_HEALTHY 语句查看表的统计信息健康度,并粗略估计表上统计信息的准确度。当 modify_count >= row_count 时,健康度为 0;当 modify_count < row_count 时,健康度为 (1 - modify_count/row_count) * 100。
列的元信息
你可以使用 SHOW STATS_HISTOGRAMS 语句查看列的不同值数量以及 NULL 数量等信息。
直方图桶的信息
你可以使用 SHOW STATS_BUCKETS 语句查看直方图每个桶的信息。
Top-N 信息
你可以使用 SHOW STATS_TOPN 语句查看当前 TiDB 收集的 Top-N 值的信息。
删除统计信息
你可以通过执行 DROP STATS 语句来删除统计信息。
加载统计信息
默认情况下,列的统计信息占用空间大小不同,TiDB 对统计信息的加载方式也会不同:
- 对于 count、distinctCount、nullCount 等占用空间较小的统计信息,只要有数据更新,TiDB 就会自动将对应的统计信息加载进内存供 SQL 优化阶段使用。
- 对于直方图、TopN、CMSketch 等占用空间较大的统计信息,为了确保 SQL 执行的性能,TiDB 会按需进行异步加载。例如,对于直方图,只有当某条 SQL 语句的优化阶段使用到了某列的直方图统计信息时,TiDB 才会将该列的直方图信息加载到内存。按需异步加载的优势是统计信息加载不会影响到 SQL 执行的性能,但在 SQL 优化时有可能使用不完整的统计信息。
从 v5.4.0 开始,TiDB 引入了统计信息同步加载的特性,支持执行当前 SQL 语句时将直方图、TopN、CMSketch 等占用空间较大的统计信息同步加载到内存,提高该 SQL 语句优化时统计信息的完整性。
要开启该特性,请将系统变量 tidb_stats_load_sync_wait 的值设置为 SQL 优化可以等待的同步加载完整的列统计信息的最长超时时间(单位为毫秒)。该变量的默认值为 100,代表开启统计信息同步加载。
开启同步加载统计信息特性后,你可以进一步配置该特性:
- 通过修改系统变量
tidb_stats_load_pseudo_timeout的值控制 SQL 优化等待超时后 TiDB 的行为。该变量默认值为ON,表示超时后 SQL 优化过程不会使用任何列上的直方图、TopN 或 CMSketch。当该变量设置为OFF时,表示超时后 SQL 执行失败。 - 通过修改 TiDB 配置项
stats-load-concurrency的值控制统计信息同步加载可以并发处理的最大列数。从 v8.2.0 起,该配置项的默认值为0,表示根据服务器情况自动调节并发度。 - 通过修改 TiDB 配置项
stats-load-queue-size的值设置统计信息同步加载最多可以缓存多少列的请求。该配置项的默认值为1000。
在 TiDB 启动阶段,初始统计信息加载完成之前执行的 SQL 可能有不合理的执行计划,从而影响性能。为了避免这种情况,从 v7.1.0 开始,TiDB 引入了配置参数 force-init-stats。你可以使用该配置参数控制 TiDB 启动时是否在统计信息初始化完成后再对外提供服务。该配置参数从 v7.2.0 起默认开启。
从 v7.1.0 开始,TiDB 引入了配置参数 lite-init-stats,用于控制是否开启轻量级的统计信息初始化。
- 当
lite-init-stats设置为true时,统计信息初始化时列和索引的直方图、TopN、Count-Min Sketch 均不会加载到内存中。 - 当
lite-init-stats设置为false时,统计信息初始化时索引和主键的直方图、TopN、Count-Min Sketch 会被加载到内存中,非主键列的直方图、TopN、Count-Min Sketch 不会加载到内存中。当优化器需要某一索引或者列的直方图、TopN、Count-Min Sketch 时,这些统计信息会被同步或异步加载到内存中。
lite-init-stats 的默认值为 true,即开启轻量级的统计信息初始化。将 lite-init-stats 设置为 true 可以加速统计信息初始化,避免加载不必要的统计信息,从而减少 TiDB 的内存使用。
导出和导入统计信息
本小节介绍如何导出和导入统计信息。
导出统计信息
统计信息的导出接口如下:
通过以下接口可以获取数据库
${db_name}中的表${table_name}的 JSON 格式的统计信息:http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}示例如下:
curl -s http://127.0.0.1:10080/stats/dump/test/t1 -o /tmp/t1.json通过以下接口可以获取数据库
${db_name}中的表${table_name}在指定时间上的 JSON 格式的统计信息。指定的时间应在 GC SafePoint 之后。http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyyMMddHHmmss}
导入统计信息
导入的统计信息一般指通过统计信息导出接口得到的 JSON 文件。你可以使用 LOAD STATS 语句来导入统计信息。
语法如下:
LOAD STATS 'file_name';
file_name 为要导入的统计信息的文件名。
锁定统计信息
从 v6.5.0 开始,TiDB 支持锁定统计信息。当一张表或一个分区的统计信息被锁定以后,该表或分区的统计信息将无法被修改,也无法对该表进行 ANALYZE 操作。示例如下:
创建表 t,并插入一些数据。在未锁定表 t 的统计信息时,可以成功执行 ANALYZE 语句:
mysql> CREATE TABLE t(a INT, b INT);
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO t VALUES (1,2), (3,4), (5,6), (7,8);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "Row count in stats_meta is much smaller compared with the row count got by PD, use min(1, 15000/4) as the sample-rate=1" |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
锁定表 t 的统计信息,再执行 ANALYZE 语句,warning 提示跳过对表 t 的 ANALYZE:
mysql> LOCK STATS t;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATS_LOCKED;
+---------+------------+----------------+--------+
| Db_name | Table_name | Partition_name | Status |
+---------+------------+----------------+--------+
| test | t | | locked |
+---------+------------+----------------+--------+
1 row in set (0.01 sec)
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> SHOW WARNINGS;
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "use min(1, 110000/8) as the sample-rate=1" |
| Warning | 1105 | skip analyze locked table: test.t |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
解锁表 t 的统计信息,可以成功执行 ANALYZE 语句:
mysql> UNLOCK STATS t;
Query OK, 0 rows affected (0.01 sec)
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "use min(1, 110000/8) as the sample-rate=1" |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
另外,你也可以通过 LOCK STATS 语句锁定分区的统计信息。示例如下:
创建分区表 t,并插入一些数据。在未锁定分区 p1 的统计信息时,可以成功执行 ANALYZE 语句:
mysql> CREATE TABLE t(a INT, b INT) PARTITION BY RANGE (a) (PARTITION p0 VALUES LESS THAN (10), PARTITION p1 VALUES LESS THAN (20), PARTITION p2 VALUES LESS THAN (30));
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO t VALUES (1,2), (3,4), (5,6), (7,8);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 6 warning (0.02 sec)
mysql> SHOW WARNINGS;
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p0, reason to use this rate is "Row count in stats_meta is much smaller compared with the row count got by PD, use min(1, 15000/4) as the sample-rate=1" |
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p2, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
6 rows in set (0.01 sec)
锁定分区 p1 的统计信息,再执行 ANALYZE 语句,warning 提示跳过对分区 p1 的 ANALYZE:
mysql> LOCK STATS t PARTITION p1;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATS_LOCKED;
+---------+------------+----------------+--------+
| Db_name | Table_name | Partition_name | Status |
+---------+------------+----------------+--------+
| test | t | p1 | locked |
+---------+------------+----------------+--------+
1 row in set (0.00 sec)
mysql> ANALYZE TABLE t PARTITION p1;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> SHOW WARNINGS;
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
| Warning | 1105 | skip analyze locked table: test.t partition (p1) |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
解锁分区 p1 的统计信息,可以成功执行 ANALYZE 语句:
mysql> UNLOCK STATS t PARTITION p1;
Query OK, 0 rows affected (0.00 sec)
mysql> ANALYZE TABLE t PARTITION p1;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> SHOW WARNINGS;
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
锁定统计信息的行为说明
- 如果统计信息在分区表上锁定,那么该分区表上所有分区的统计信息就都保持锁定。
- 如果表或者分区被 truncate,该表或分区上的统计信息锁定将会被解除。
具体行为参见下面表格:
管理 ANALYZE 任务与并发
本小节介绍如何终止后台的 ANALYZE 任务,如何控制 ANALYZE 并发度。
终止后台的 ANALYZE 任务
从 TiDB v6.0 起,TiDB 支持通过 KILL 语句终止正在后台运行的 ANALYZE 任务。如果发现正在后台运行的 ANALYZE 任务消耗大量资源影响业务,你可以通过以下步骤终止该 ANALYZE 任务:
执行以下 SQL 语句:
SHOW ANALYZE STATUS查看
instance列和process_id列,获得正在执行后台ANALYZE任务的 TiDB 实例地址和任务ID。终止正在后台运行的
ANALYZE任务。- 如果
enable-global-kill的值为true(默认为true),你可以直接执行KILL TIDB ${id};语句。其中,${id}为上一步中查询得到的后台ANALYZE任务的ID。 - 如果
enable-global-kill的值为false,你需要先使用客户端连接到执行后台ANALYZE任务的 TiDB 实例,然后再执行KILL TIDB ${id};语句。如果使用客户端连接到其他 TiDB 实例,或者客户端和 TiDB 中间有代理,则KILL语句不能终止后台的ANALYZE任务。
关于
KILL语句的更多信息,参见KILL。- 如果
控制 ANALYZE 并发度
执行 ANALYZE 语句的时候,你可以通过一些系统变量来调整并发度,以控制对系统的影响。
相关系统变量的关系如下图所示:

tidb_build_stats_concurrency、tidb_build_sampling_stats_concurrency 和 tidb_analyze_partition_concurrency 为上下游关系。实际的总并发为:tidb_build_stats_concurrency* (tidb_build_sampling_stats_concurrency + tidb_analyze_partition_concurrency) 。所以在变更这些参数的时候,需要同时考虑这三个参数的值。建议按 tidb_analyze_partition_concurrency、tidb_build_sampling_stats_concurrency、tidb_build_stats_concurrency 的顺序逐个调节,并观察对系统的影响。这三个参数的值越大,对系统的资源开销就越大。
tidb_build_stats_concurrency
该变量控制手动收集统计信息时,构建统计信息的并发度,例如可以同时处理的表或分区的分析任务的数量。其默认值为 2。在 TiDB v7.4.0 及之前的版本中,其默认值为 4。
tidb_build_sampling_stats_concurrency
该变量控制 ANALYZE 在以下方面的并发情况:
- 合并从不同 Region 收集的样本时的并发度。
- 针对特殊索引(例如基于虚拟生成列的索引)收集统计信息的并发度,例如 TiDB 可同时为多少个特殊索引收集统计信息。
其默认值为 2。
tidb_analyze_partition_concurrency
该变量控制保存 ANALYZE 结果(将 TopN 和直方图写入系统表)的并发度。其默认值为 2。在 TiDB v7.4.0 及之前的版本中,其默认值为 1。
tidb_analyze_distsql_scan_concurrency
该变量控制 ANALYZE 在以下方面的并发情况:
- 扫描 TiKV Region 的并发度。
- 为特殊索引(基于虚拟生成列的索引)扫描 Region 的并发度。
其默认值为 4。