TiDBセルフマネージドからTiDB Cloudへの移行
このドキュメントでは、 Dumplingと TiCDC を使用して、TiDB セルフマネージド クラスターからTiDB Cloud (AWS 上) にデータを移行する方法について説明します。
全体的な手順は次のとおりです。
- 環境を構築し、ツールを準備します。
- 全データを移行します。手順は次のとおりです。
- Dumplingを使用して、TiDB Self-Managed から Amazon S3 にデータをエクスポートします。
- Amazon S3 からTiDB Cloudにデータをインポートします。
- TiCDC を使用して増分データを複製します。
- 移行されたデータを確認します。
前提条件
S3バケットとTiDB Cloudクラスターは同じリージョンに配置することをお勧めします。リージョン間の移行では、データ変換のために追加コストが発生する可能性があります。
移行する前に、次のものを準備する必要があります。
- 管理者アクセス権を持つAWSアカウント
- AWS S3バケット
- AWS でホストされているターゲットTiDB Cloudクラスターへのアクセス権が少なくとも
Project Data Access Read-WriteつあるTiDB Cloudアカウント
ツールを準備する
以下のツールを準備する必要があります。
- Dumpling:データエクスポートツール
- TiCDC: データ複製ツール
Dumpling
Dumplingは、TiDBまたはMySQLからSQLまたはCSVファイルにデータをエクスポートするツールです。Dumplingを使用すると、TiDB Self-Managedから完全なデータをエクスポートできます。
Dumpling をデプロイする前に、次の点に注意してください。
- TiDB Cloudの TiDB クラスターと同じ VPC 内の新しい EC2 インスタンスにDumplingをデプロイすることをお勧めします。
- 推奨されるEC2インスタンスタイプはc6g.4xlarge (16 vCPU、32 GiBメモリ)です。ニーズに応じて、他のEC2インスタンスタイプも選択できます。Amazonマシンイメージ(AMI)は、Amazon Linux、Ubuntu、Red Hatから選択できます。
Dumpling は、 TiUPまたはインストール パッケージを使用して展開できます。
TiUPを使用してDumplingをデプロイ
TiUPを使用してDumplingを展開します:
## Deploy TiUP
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
source /root/.bash_profile
## Deploy Dumpling and update to the latest version
tiup install dumpling
tiup update --self && tiup update dumpling
インストールパッケージを使用してDumplingをデプロイ
インストール パッケージを使用してDumplingを展開するには:
ツールキットパッケージをダウンロードしてください。
対象マシンに解凍してください。TiUPを使ってDumpling を入手するには、
tiup install dumpling実行します。その後、tiup dumpling ...使用してDumplingを実行します。詳細については、 Dumplingの紹介参照してください。
Dumplingの権限を設定する
アップストリーム データベースからデータをエクスポートするには、次の権限が必要です。
- 選択
- リロード
- ロックテーブル
- レプリケーションクライアント
- プロセス
TiCDCをデプロイ
アップストリーム TiDB クラスターからTiDB Cloudに増分データを複製するには、 TiCDCを展開するが必要です。
現在のTiDBバージョンがTiCDCをサポートしているかどうかを確認してください。TiDB v4.0.8.rc.1以降のバージョンはTiCDCをサポートしています。TiDBクラスタで
select tidb_version();実行すると、TiDBのバージョンを確認できます。アップグレードが必要な場合は、 TiUPを使用して TiDB をアップグレードする参照してください。TiCDCコンポーネントをTiDBクラスタに追加します。1 TiUPを使用して既存の TiDB クラスターに TiCDC を追加またはスケールアウトする参照してください。3
scale-out.ymlを編集してTiCDCを追加します。cdc_servers: - host: 10.0.1.3 gc-ttl: 86400 data_dir: /tidb-data/cdc-8300 - host: 10.0.1.4 gc-ttl: 86400 data_dir: /tidb-data/cdc-8300TiCDCコンポーネントを追加し、ステータスを確認します。
tiup cluster scale-out <cluster-name> scale-out.yml tiup cluster display <cluster-name>
全データを移行する
TiDB Self-Managed クラスターからTiDB Cloudにデータを移行するには、次のようにして完全なデータ移行を実行します。
- TiDB セルフマネージド クラスターから Amazon S3 にデータを移行します。
- Amazon S3 からTiDB Cloudにデータを移行します。
TiDBセルフマネージドクラスターからAmazon S3にデータを移行する
Dumplingを使用して、TiDB セルフマネージド クラスターから Amazon S3 にデータを移行する必要があります。
TiDB クラスターがローカル IDC 内にある場合、またはDumplingサーバーと Amazon S3 間のネットワークが接続されていない場合は、最初にファイルをローカルstorageにエクスポートし、後で Amazon S3 にアップロードすることができます。
ステップ1.上流のTiDBセルフマネージドクラスタのGCメカニズムを一時的に無効にする
増分移行中に新しく書き込まれたデータが失われないようにするには、移行を開始する前にアップストリーム クラスターのガベージコレクション(GC) メカニズムを無効にして、システムが履歴データをクリーンアップしないようにする必要があります。
設定が成功したかどうかを確認するには、次のコマンドを実行します。
SET GLOBAL tidb_gc_enable = FALSE;
以下は出力例です。1 0無効であることを示します。
SELECT @@global.tidb_gc_enable;
+-------------------------+
| @@global.tidb_gc_enable |
+-------------------------+
| 0 |
+-------------------------+
1 row in set (0.01 sec)
ステップ2. DumplingのAmazon S3バケットへのアクセス権限を設定する
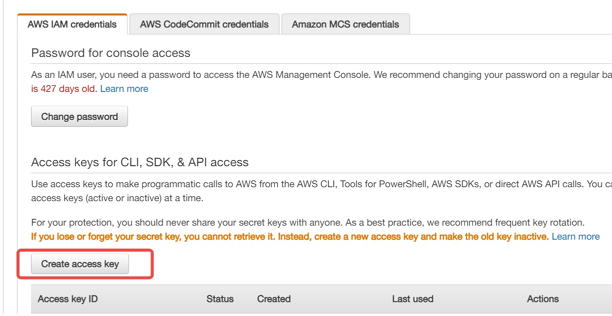
AWSコンソールでアクセスキーを作成します。詳細はアクセスキーを作成するご覧ください。
AWS アカウント ID またはアカウントエイリアス、 IAMユーザー名、およびパスワードを使用してIAMコンソールにサインインします。
右上のナビゲーション バーでユーザー名を選択し、 [Security資格情報]をクリックします。
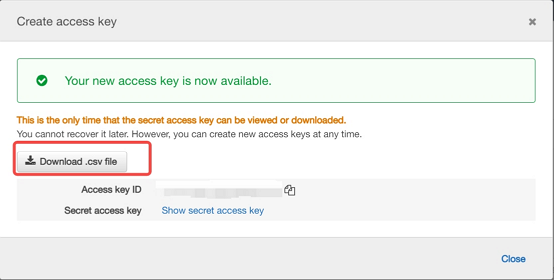
アクセスキーを作成するには、 「アクセスキーの作成」をクリックします。次に、 「.csvファイルのダウンロード」を選択して、アクセスキーIDとシークレットアクセスキーをコンピューター上のCSVファイルに保存します。ファイルは安全な場所に保管してください。このダイアログボックスを閉じると、シークレットアクセスキーに再度アクセスできなくなります。CSVファイルをダウンロードしたら、 「閉じる」を選択します。アクセスキーを作成すると、キーペアはデフォルトでアクティブになり、すぐに使用できます。
ステップ3. Dumplingを使用して上流のTiDBクラスターからAmazon S3にデータをエクスポートする
Dumplingを使用してアップストリーム TiDB クラスターから Amazon S3 にデータをエクスポートするには、次の手順を実行します。
Dumplingの環境変数を設定します。
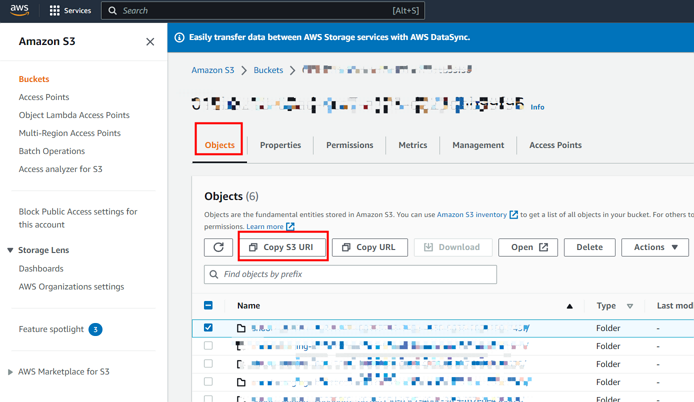
export AWS_ACCESS_KEY_ID=${AccessKey} export AWS_SECRET_ACCESS_KEY=${SecretKey}AWSコンソールからS3バケットのURIとリージョン情報を取得します。詳細はバケットを作成する参照してください。
次のスクリーンショットは、S3 バケット URI 情報を取得する方法を示しています。
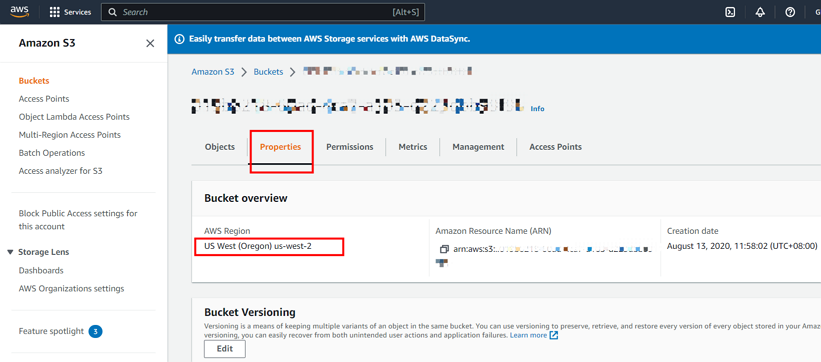
次のスクリーンショットは、地域情報を取得する方法を示しています。
Dumplingを実行して、データを Amazon S3 バケットにエクスポートします。
dumpling \ -u root \ -P 4000 \ -h 127.0.0.1 \ -r 20000 \ --filetype {sql|csv} \ -F 256MiB \ -t 8 \ -o "${S3 URI}" \ --s3.region "${s3.region}"-tオプションは、エクスポートのスレッド数を指定します。スレッド数を増やすと、 Dumplingの同時実行性とエクスポート速度が向上しますが、データベースのメモリ消費量も増加します。したがって、このパラメータにあまり大きな数値を設定しないでください。詳細についてはDumpling参照してください。
エクスポートデータを確認してください。通常、エクスポートされたデータには以下が含まれます。
metadata: このファイルには、エクスポートの開始時刻とマスター バイナリ ログの場所が含まれています。{schema}-schema-create.sql: スキーマを作成するためのSQLファイル{schema}.{table}-schema.sql: テーブルを作成するためのSQLファイル{schema}.{table}.{0001}.{sql|csv}: データファイル*-schema-view.sql:その他のエクスポートされた*-schema-trigger.sql*-schema-post.sql
Amazon S3 からTiDB Cloudへのデータ移行
TiDB セルフマネージド クラスターから Amazon S3 にデータをエクスポートした後、そのデータをTiDB Cloudに移行する必要があります。
TiDB Cloudコンソールでは、次のドキュメントに従って、ターゲット クラスターのアカウント ID と外部 ID を取得します。
- TiDB Cloud Dedicated クラスターについては、 ロール ARN を使用して Amazon S3 アクセスを構成する参照してください。
- TiDB Cloud Starter またはTiDB Cloud Essential クラスターについては、 ロール ARN を使用して Amazon S3 アクセスを構成する参照してください。
Amazon S3 のアクセス権限を設定します。通常、以下の読み取り専用権限が必要です。
- s3:GetObject
- s3:オブジェクトバージョンを取得
- s3:リストバケット
- s3:GetBucketLocation
S3 バケットがサーバー側暗号化 SSE-KMS を使用する場合は、KMS 権限も追加する必要があります。
- kms:復号化
アクセスポリシーを設定します。1 に移動し、リージョンを切り替えてAWSコンソール > IAM > アクセス管理 > ポリシー TiDB Cloudのアクセスポリシーが既に存在するかどうかを確認します。存在しない場合は、このドキュメントJSONタブでポリシーを作成するに従ってポリシーを作成してください。
以下は、json ポリシーのテンプレートの例です。
## Create a json policy template ##<Your customized directory>: fill in the path to the folder in the S3 bucket where the data files to be imported are located. ##<Your S3 bucket ARN>: fill in the ARN of the S3 bucket. You can click the Copy ARN button on the S3 Bucket Overview page to get it. ##<Your AWS KMS ARN>: fill in the ARN for the S3 bucket KMS key. You can get it from S3 bucket > Properties > Default encryption > AWS KMS Key ARN. For more information, see https://docs.aws.amazon.com/AmazonS3/latest/userguide/viewing-bucket-key-settings.html { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::<Your customized directory>" }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": "<Your S3 bucket ARN>" } // If you have enabled SSE-KMS for the S3 bucket, you need to add the following permissions. { "Effect": "Allow", "Action": [ "kms:Decrypt" ], "Resource": "<Your AWS KMS ARN>" } , { "Effect": "Allow", "Action": "kms:Decrypt", "Resource": "<Your AWS KMS ARN>" } ] }ロールを設定しますIAMロールの作成 (コンソール)を参照してください。「アカウントID」フィールドに、手順1でメモしたTiDB CloudアカウントIDとTiDB Cloud外部IDを入力します。
ロールARNを取得します。1に進みAWSコンソール > IAM > アクセス管理 > ロール 。リージョンに切り替えます。作成したロールをクリックし、ARNをメモします。これはTiDB Cloudにデータをインポートするときに使用します。
TiDB Cloudにデータをインポートします。
- TiDB Cloud Dedicated クラスターについては、 クラウドストレージからTiDB Cloud DedicatedにCSVファイルをインポートする参照してください。
- TiDB Cloud Starter またはTiDB Cloud Essential クラスターについては、 クラウドストレージからTiDB Cloud StarterまたはEssentialにCSVファイルをインポートする参照してください。
増分データを複製する
増分データを複製するには、次の手順を実行します。
増分データ移行の開始時刻を取得します。例えば、完全データ移行のメタデータファイルから取得できます。
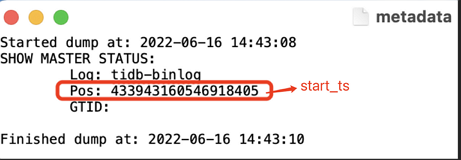
TiCDC にTiDB Cloudへの接続を許可します。
- TiDB Cloudコンソールでクラスターページに移動し、ターゲット クラスターの名前をクリックして概要ページに移動します。
- 左側のナビゲーション ペインで、 [設定] > [ネットワーク]をクリックします。
- [ネットワーク]ページで、 [IP アドレスの追加]をクリックします。
- 表示されたダイアログで「IPアドレスを使用する」を選択し、「 +」をクリックして、 「IPアドレス」フィールドにTiCDCコンポーネントのパブリックIPアドレスを入力し、 「確認」をクリックします。これでTiCDCはTiDB Cloudにアクセスできるようになります。詳細については、 IPアクセスリストを構成する参照してください。
ダウンストリームTiDB Cloudクラスターの接続情報を取得します。
- TiDB Cloudコンソールでクラスターページに移動し、ターゲット クラスターの名前をクリックして概要ページに移動します。
- 右上隅の「接続」をクリックします。
- 接続ダイアログで、[**接続タイプ]ドロップダウン リストから[パブリック]を選択し、 [接続先]ドロップダウン リストから[一般]**を選択します。
- 接続情報から、クラスターのホストIPアドレスとポートを取得できます。詳細については、 パブリック接続経由で接続する参照してください。
増分レプリケーションタスクを作成して実行します。アップストリームクラスターで、以下のコマンドを実行します。
tiup cdc cli changefeed create \ --pd=http://172.16.6.122:2379 \ --sink-uri="tidb://root:123456@172.16.6.125:4000" \ --changefeed-id="upstream-to-downstream" \ --start-ts="431434047157698561"--pd: 上流クラスタのPDアドレス。形式は[upstream_pd_ip]:[pd_port]です。--sink-uri: レプリケーションタスクのダウンストリームアドレス--sink-uri以下の形式で設定してください。現在、このスキームはmysql、tidb、kafka、s3、localをサポートしています。[scheme]://[userinfo@][host]:[port][/path]?[query_parameters]--changefeed-id: レプリケーションタスクのID。形式は ^[a-zA-Z0-9]+(-[a-zA-Z0-9]+)*$ 正規表現に一致する必要があります。このIDが指定されていない場合、TiCDCは自動的にUUID(バージョン4形式)をIDとして生成します。--start-ts: チェンジフィードの開始TSOを指定します。このTSOから、TiCDCクラスターはデータのプルを開始します。デフォルト値は現在時刻です。
詳細についてはTiCDC 変更フィードの CLI とコンフィグレーションパラメータ参照してください。
上流クラスタでGCメカニズムを再度有効化します。増分レプリケーションでエラーや遅延が見つからない場合、GCメカニズムを有効化してクラスタのガベージコレクションを再開します。
設定が機能するかどうかを確認するには、次のコマンドを実行します。
SET GLOBAL tidb_gc_enable = TRUE;以下は出力例です。1
1GC が無効であることを示します。SELECT @@global.tidb_gc_enable; +-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 1 | +-------------------------+ 1 row in set (0.01 sec)増分レプリケーション タスクを確認します。
出力に「Create changefeed successfully!」というメッセージが表示されたら、レプリケーション タスクは正常に作成されています。
状態が
normal場合、レプリケーション タスクは正常です。tiup cdc cli changefeed list --pd=http://172.16.6.122:2379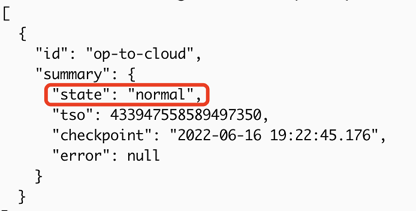
レプリケーションを確認します。アップストリームクラスタに新しいレコードを書き込み、そのレコードがダウンストリームTiDB Cloudクラスタにレプリケートされているかどうかを確認します。
アップストリームクラスタとダウンストリームクラスタに同じタイムゾーンを設定してください。デフォルトでは、 TiDB Cloud はタイムゾーンを UTC に設定します。アップストリームクラスタとダウンストリームクラスタのタイムゾーンが異なる場合は、両方のクラスタに同じタイムゾーンを設定する必要があります。
アップストリーム クラスターで次のコマンドを実行してタイムゾーンを確認します。
SELECT @@global.time_zone;ダウンストリーム クラスターで、次のコマンドを実行してタイムゾーンを設定します。
SET GLOBAL time_zone = '+08:00';設定を確認するには、タイムゾーンをもう一度確認してください。
SELECT @@global.time_zone;
上流クラスターのクエリバインディングバックアップし、下流クラスターに復元します。クエリバインディングをバックアップするには、次のクエリを使用します。
SELECT DISTINCT(CONCAT('CREATE GLOBAL BINDING FOR ', original_sql,' USING ', bind_sql,';')) FROM mysql.bind_info WHERE status='enabled';出力が表示されない場合は、上流クラスターでクエリバインディングが使用されていない可能性があります。その場合は、この手順をスキップできます。
クエリ バインディングを取得したら、ダウンストリーム クラスターでそれを実行して、クエリ バインディングを復元します。
上流クラスタのユーザーと権限情報をバックアップし、下流クラスタに復元します。以下のスクリプトを使用して、ユーザーと権限情報をバックアップできます。プレースホルダは実際の値に置き換える必要があることに注意してください。
#!/bin/bash export MYSQL_HOST={tidb_op_host} export MYSQL_TCP_PORT={tidb_op_port} export MYSQL_USER=root export MYSQL_PWD={root_password} export MYSQL="mysql -u${MYSQL_USER} --default-character-set=utf8mb4" function backup_user_priv(){ ret=0 sql="SELECT CONCAT(user,':',host,':',authentication_string) FROM mysql.user WHERE user NOT IN ('root')" for usr in `$MYSQL -se "$sql"`;do u=`echo $usr | awk -F ":" '{print $1}'` h=`echo $usr | awk -F ":" '{print $2}'` p=`echo $usr | awk -F ":" '{print $3}'` echo "-- Grants for '${u}'@'${h}';" [[ ! -z "${p}" ]] && echo "CREATE USER IF NOT EXISTS '${u}'@'${h}' IDENTIFIED WITH 'mysql_native_password' AS '${p}' ;" $MYSQL -se "SHOW GRANTS FOR '${u}'@'${h}';" | sed 's/$/;/g' [ $? -ne 0 ] && ret=1 && break done return $ret } backup_user_privユーザーと権限の情報を取得したら、ダウンストリーム クラスターで生成された SQL ステートメントを実行して、ユーザーと権限の情報を復元します。