クラウドストレージに保存
このドキュメントでは、TiDB Cloudからクラウドstorageにデータをストリーミングするための変更フィードを作成する方法について説明します。現在、Amazon S3、Google Cloud Storage (GCS)、Azure Blob Storage がサポートされています。
注記:
- クラウドstorageにデータをストリーミングするには、TiDB クラスタのバージョンが v7.1.1 以降であることを確認してください。TiDB TiDB Cloud Dedicated クラスタを v7.1.1 以降にアップグレードするには、 TiDB Cloudサポートにお問い合わせください実行します。
- クラスターTiDB CloudスターターおよびTiDB Cloudエッセンシャルでは、changefeed 機能は使用できません。
制限
- TiDB Cloudクラスターごとに、最大 100 個の変更フィードを作成できます。
- TiDB Cloud は、変更フィードを確立するために TiCDC を使用するため、同じTiCDCとしての制限持ちます。
- レプリケートするテーブルに主キーまたは NULL 以外の一意のインデックスがない場合、レプリケーション中に一意の制約がないと、再試行シナリオによっては下流に重複したデータが挿入される可能性があります。
ステップ1. 宛先を設定する
対象のTiDBクラスターのクラスター概要ページに移動します。左側のナビゲーションペインで「データ」 > 「Changefeed」をクリックし、 「Changefeedの作成」をクリックして「宛先」ページに移動し、クラスターがホストされているクラウドプロバイダーに応じて、 Amazon S3 、 GCS 、またはAzure Blob Storageを宛先として選択します。設定プロセスは、選択した宛先によって異なります。
Amazon S3の場合、認証にはAWS ロール ARNまたはAWS アクセスキーを使用できます。セキュリティ強化と管理の容易化のため、 AWS ロール ARN の使用をお勧めします。
オプション 1: AWS ロール ARN (推奨)
認証にIAMロールを使用するには、次の手順に従います。
Amazon S3の「Destination」ページで、 S3 URIを入力します。S3バケットがTiDBクラスターと同じAWSリージョンにあることを確認してください。
「バケットアクセス」で、 「AWS ロール ARN」を選択します。
新しいロールARNを作成するには、 「AWS CloudFormationで新しいロールARNを作成するにはここをクリックしてください」をクリックします。このテンプレートは必要な権限を自動的に設定します。
ロールを手動で作成する場合は、 「ロール ARN を手動で作成」をクリックして、 TiDB Cloudアカウント情報と必要なポリシーを表示します。
IAMロールに、ターゲット バケットに対する少なくとも次の権限があることを確認します。
s3:ListBuckets3:PutObjects3:GetObjects3:DeleteObject
生成されたロール ARN を対応するフィールドに貼り付けます。
オプション2: AWSアクセスキー
注記:
アクセスキーとシークレットキー( AK/SK )を使用すると、手動で認証情報の管理とローテーションを行う必要があり、セキュリティリスクが高まります。セキュリティを強化するには、代わりにAWSロールARNを使用することをお勧めします。
認証にアクセス キーを使用するには、次の手順に従います。
Amazon S3の「Destination」ページで、 S3 URIを入力します。S3バケットがTiDBクラスターと同じAWSリージョンにあることを確認してください。
「バケットアクセス」で、 「AWS アクセスキー」を選択します。
次のフィールドに入力します。
- アクセスキーID
- 秘密アクセスキー
GCSの場合、 GCS エンドポイントを入力する前に、まず GCS バケットへのアクセスを許可する必要があります。以下の手順に従ってください。
TiDB Cloudコンソールで、サービス アカウント IDを記録します。この ID は、 TiDB Cloudに GCS バケットへのアクセスを許可するために使用されます。
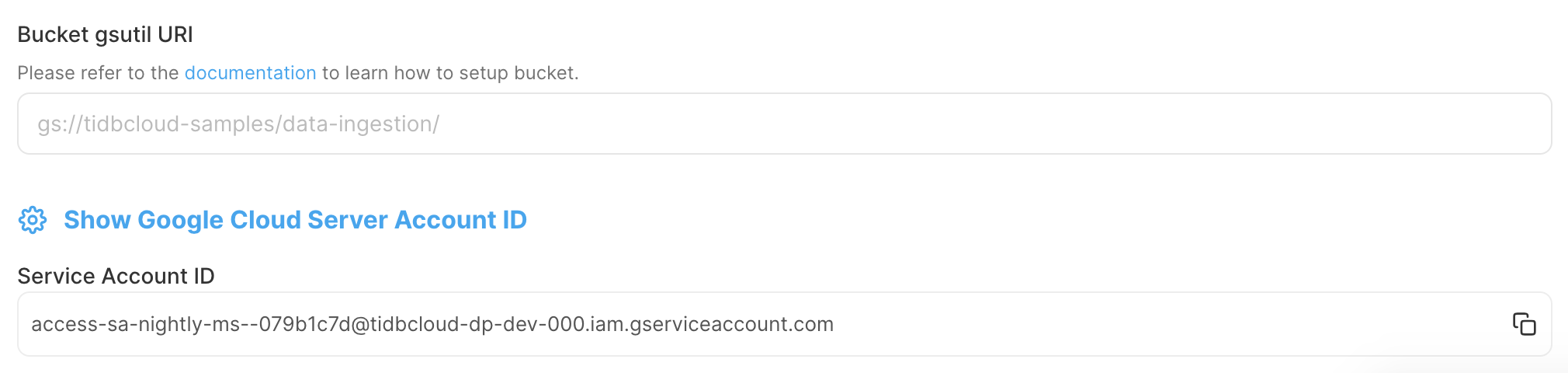
Google Cloud コンソールで、GCS バケットのIAMロールを作成します。
Google Cloud コンソールにサインインします。
役割ページに移動し、 [ロールの作成]をクリックします。
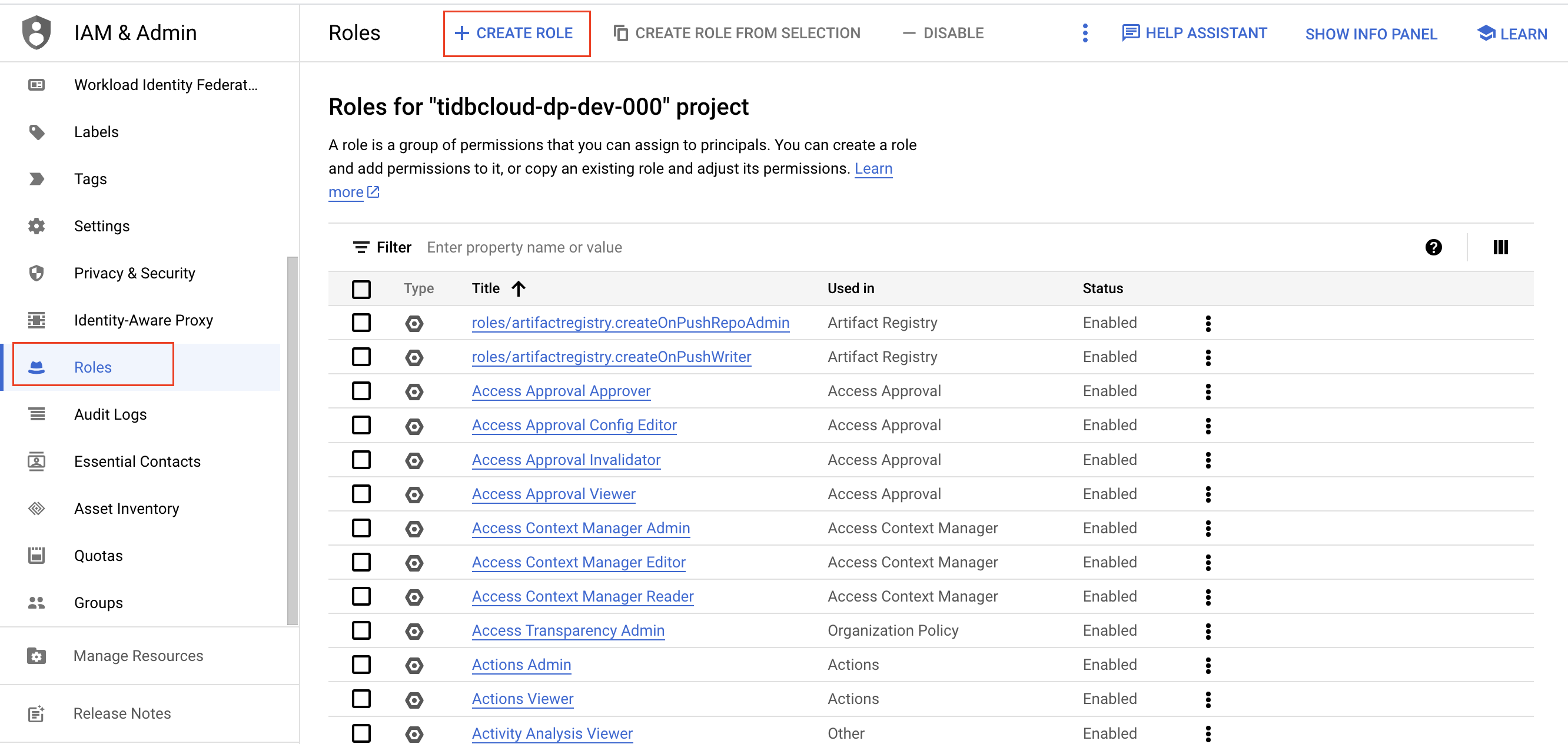
ロールの名前、説明、ID、およびロールの起動ステージを入力します。ロールの作成後は、ロール名を変更できません。
「権限の追加」をクリックします。次の権限をロールに追加し、 「追加」をクリックします。
- storage.buckets.get
- storage.objects.create
- storage.オブジェクト.削除
- storage.objects.get
- storage.objects.list
- storage.objects.update
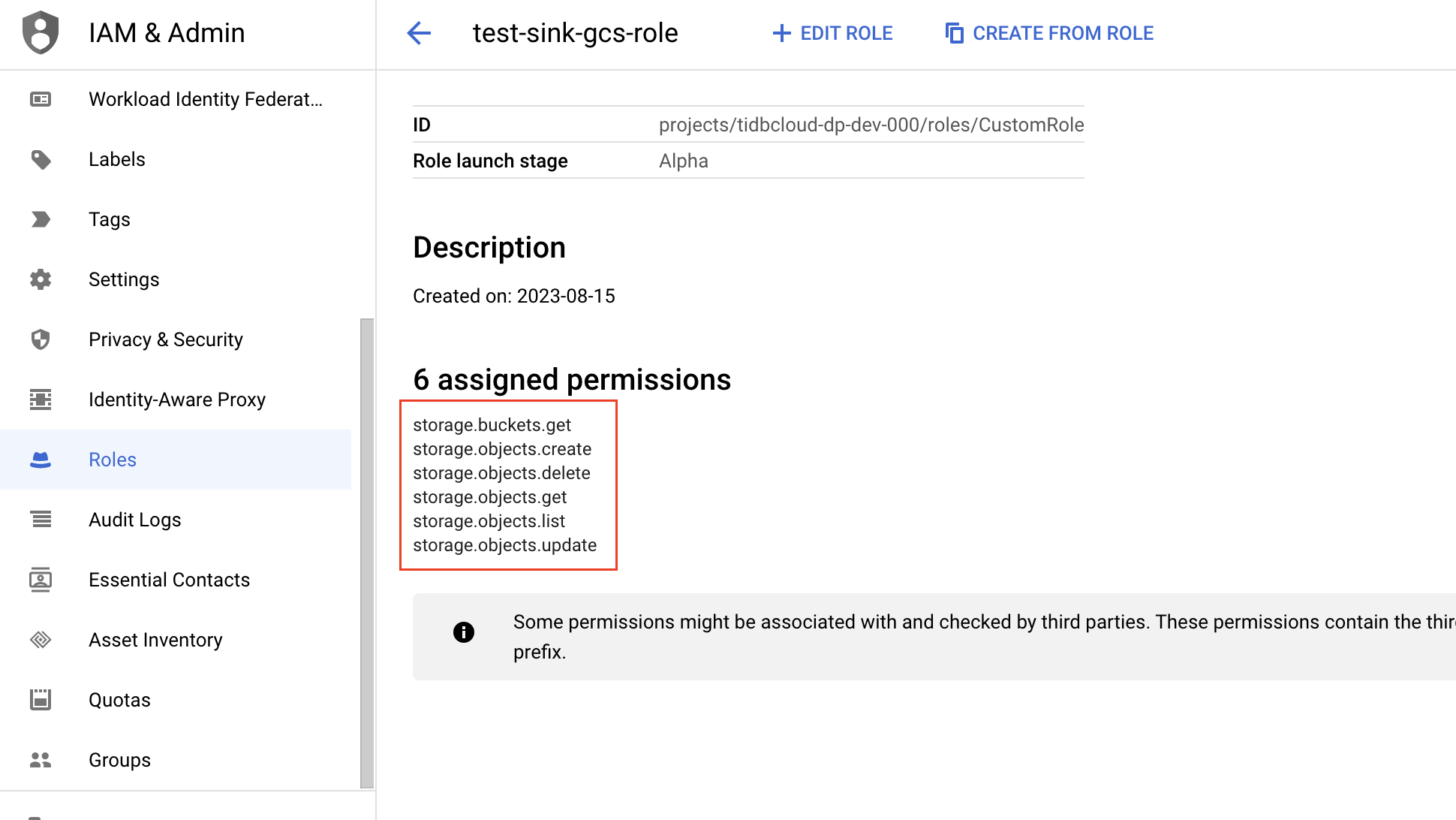
バケツページ目に移動し、 TiDB Cloudがアクセスする GCS バケットを選択します。GCS バケットは TiDB クラスタと同じリージョンにある必要があります。
バケットの詳細ページで、 [権限]タブをクリックし、 [アクセスを許可]をクリックします。
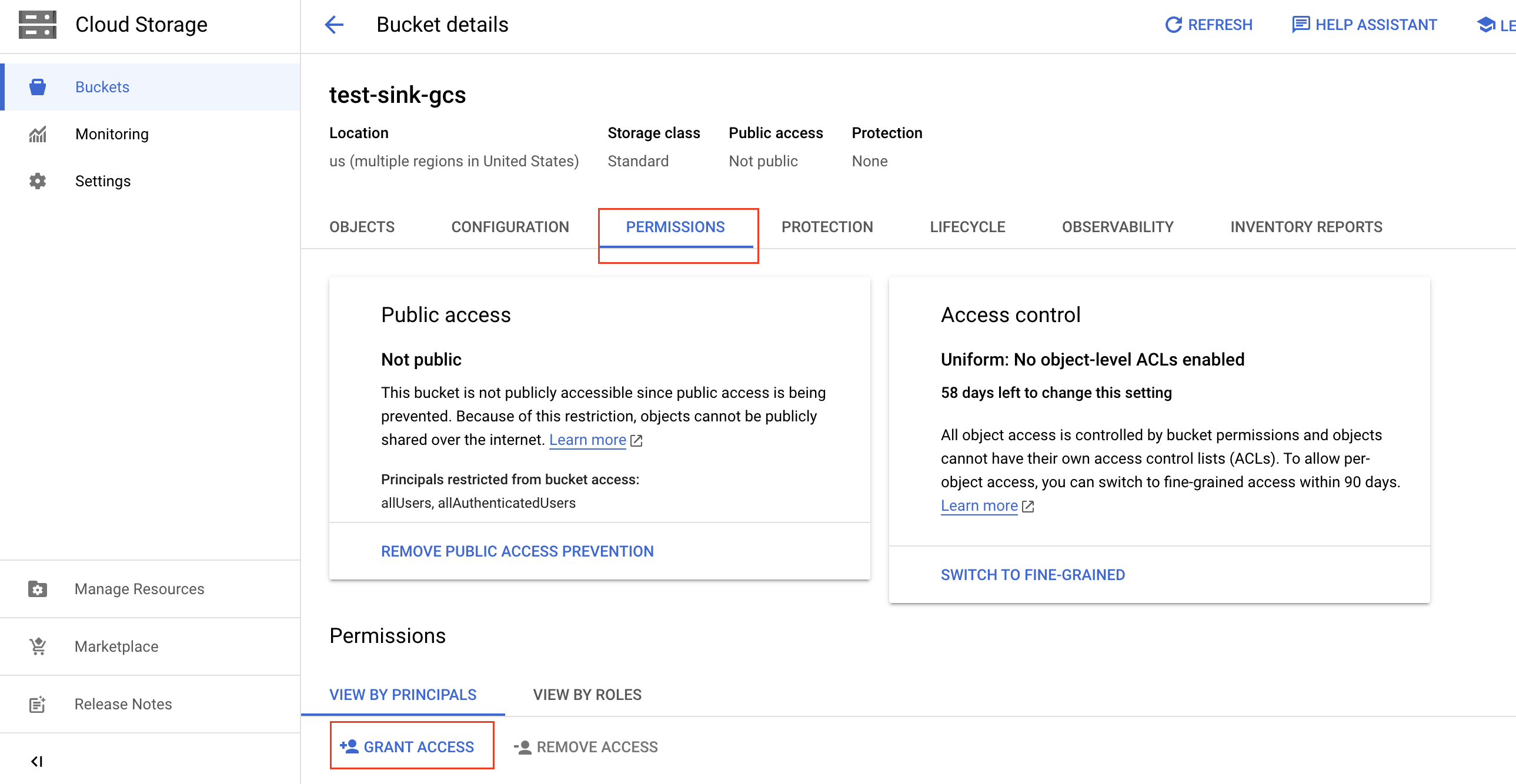
バケットへのアクセスを許可するには次の情報を入力し、 「保存」をクリックします。
[新しいプリンシパル]フィールドに、前に記録したターゲット TiDB クラスターのサービス アカウント IDを貼り付けます。
[ロールの選択]ドロップダウン リストに、作成したIAMロールの名前を入力し、フィルター結果から名前を選択します。
注記:
TiDB Cloudへのアクセスを削除するには、許可したアクセスを削除するだけです。
バケットの詳細ページで、オブジェクトタブをクリックします。
バケットのgsutil URIを取得するには、コピーボタンをクリックし、プレフィックスとして
gs://追加します。例えば、バケット名がtest-sink-gcs場合、URIはgs://test-sink-gcs/になります。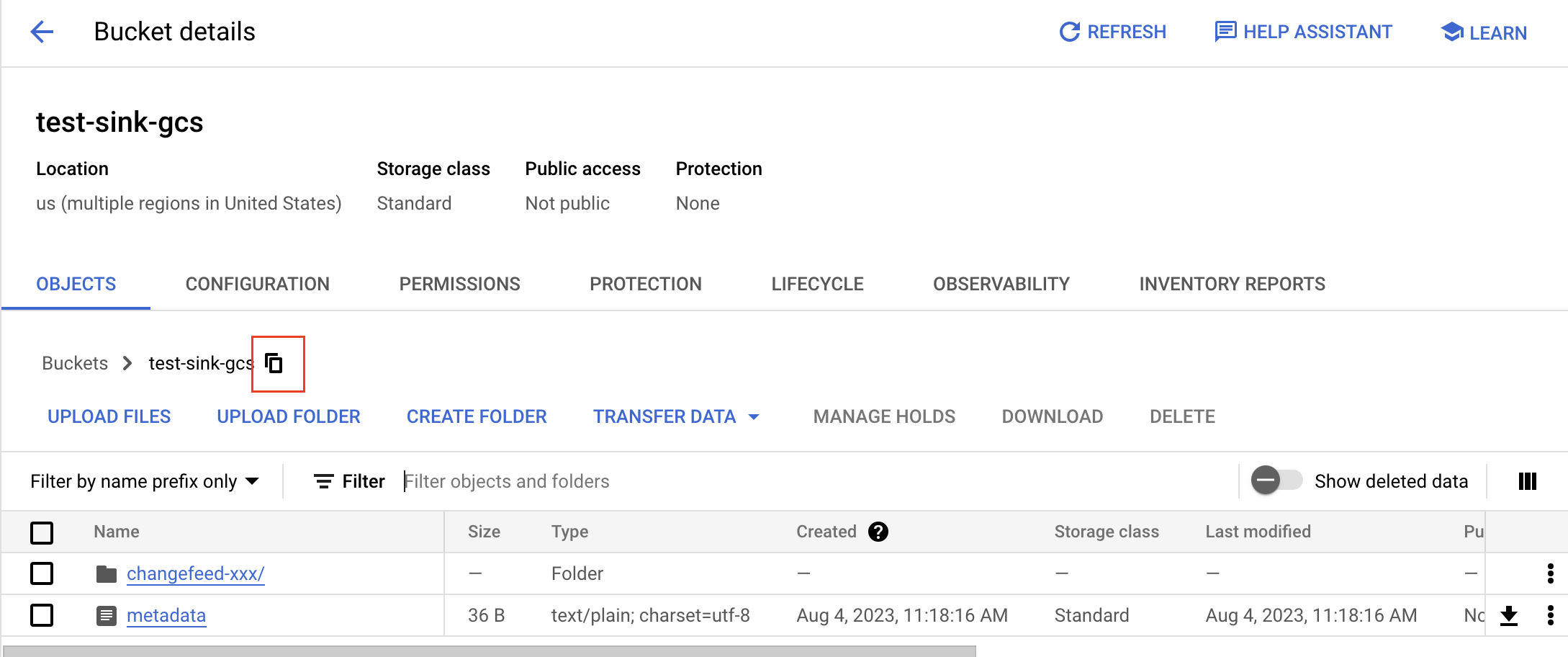
フォルダのgsutil URIを取得するには、フォルダを開き、コピーボタンをクリックし、プレフィックスとして
gs://を追加します。例えば、バケット名がtest-sink-gcsでフォルダ名がchangefeed-xxxの場合、URIはgs://test-sink-gcs/changefeed-xxx/になります。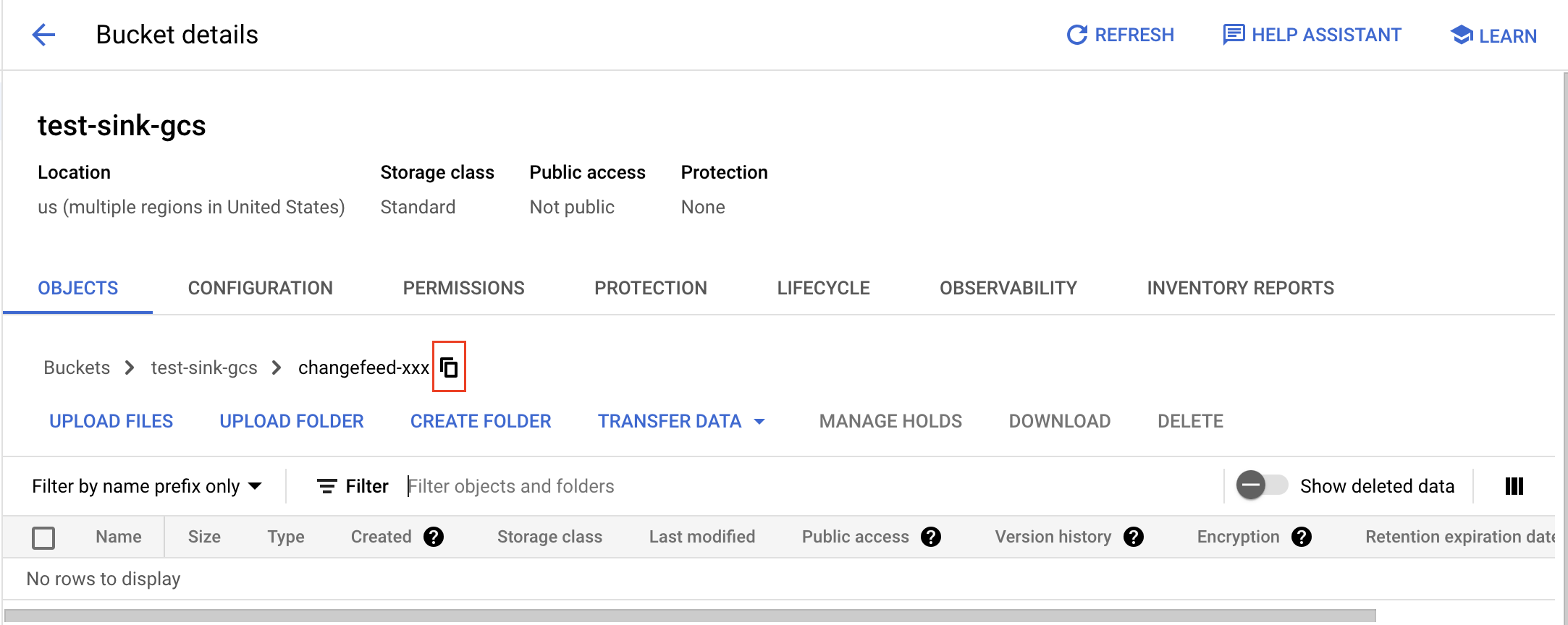
TiDB Cloudコンソールで、Changefeed の宛先ページに移動し、バケットの gsutil URIフィールドに入力します。
Azure Blob Storageの場合は、まずAzureポータルでコンテナーを構成し、SASトークンを取得する必要があります。以下の手順に従ってください。
Azureポータルで、changefeed データを保存するコンテナーを作成します。
- 左側のナビゲーション ウィンドウで、 [ストレージ アカウント]をクリックし、storageアカウントを選択します。
- storageアカウントのナビゲーション メニューで、 [データstorage] > [コンテナー]を選択し、 [+ コンテナー]をクリックします。
- 新しいコンテナの名前を入力し、匿名アクセス レベル (推奨レベルはプライベート) を設定して、 [作成]をクリックします。
ターゲット コンテナの URL を取得します。
- コンテナ リストで、ターゲット コンテナを選択します。
- コンテナーの[...]をクリックし、 [コンテナーのプロパティ]を選択します。
- 後で使用するためにURL値を保存します (例
https://<storage_account>.blob.core.windows.net/<container>。
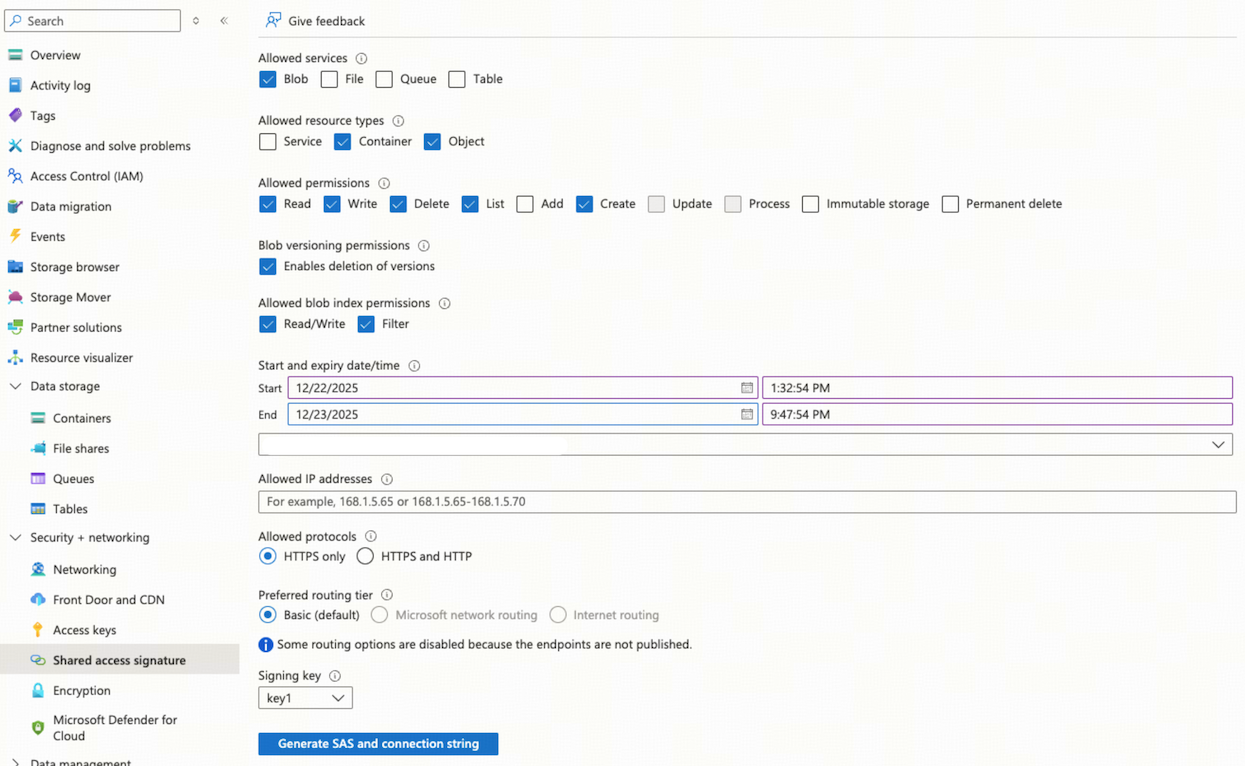
SAS トークンを生成します。
storageアカウントのナビゲーション メニューで、 [Security+ ネットワーク] > [共有アクセス署名]を選択します。
[許可されたサービス]セクションで、 [Blob]を選択します。
[許可されるリソースの種類]セクションで、 [コンテナー]と[オブジェクト]を選択します。
[許可された権限]セクションで、 [読み取り] 、 [書き込み] 、 [削除] 、 [一覧表示] 、および[作成]を選択します。
ニーズを満たすのに十分な長さの SAS トークンの有効期間を指定します。
注記:
- チェンジフィードは継続的にイベントを書き込むため、SASトークンの有効期間が十分に長いことを確認してください。セキュリティ上、トークンは6~12か月ごとに交換することをお勧めします。
- 生成された SAS トークンは取り消すことができないため、有効期間を慎重に設定してください。
- 継続的な可用性を確保するには、SAS トークンの有効期限が切れる前に再生成して更新してください。
[SAS と接続文字列の生成]をクリックし、 SAS トークンを保存します。
TiDB Cloudコンソールで、Changefeed の宛先ページに移動し、次のフィールドに入力します。
- BLOB URL : 手順 2 で取得したコンテナー URL を入力します。必要に応じてプレフィックスを追加できます。
- SAS トークン: 手順 3 で取得した生成された SAS トークンを入力します。
「次へ」をクリックすると、 TiDB Cloud Dedicated クラスターから Amazon S3、GCS、または Azure Blob Storage への接続が確立されます。TiDB TiDB Cloud は自動的に接続の成功をテストし、検証します。
- はいの場合は、構成の次の手順に進みます。
- そうでない場合は接続エラーが表示されるので、エラーに対処する必要があります。エラーが解決したら、 「次へ」をクリックして接続を再試行してください。
ステップ2. レプリケーションを構成する
テーブルフィルターをカスタマイズして、複製するテーブルをフィルタリングします。ルールの構文については、 テーブルフィルタルールを参照してください。
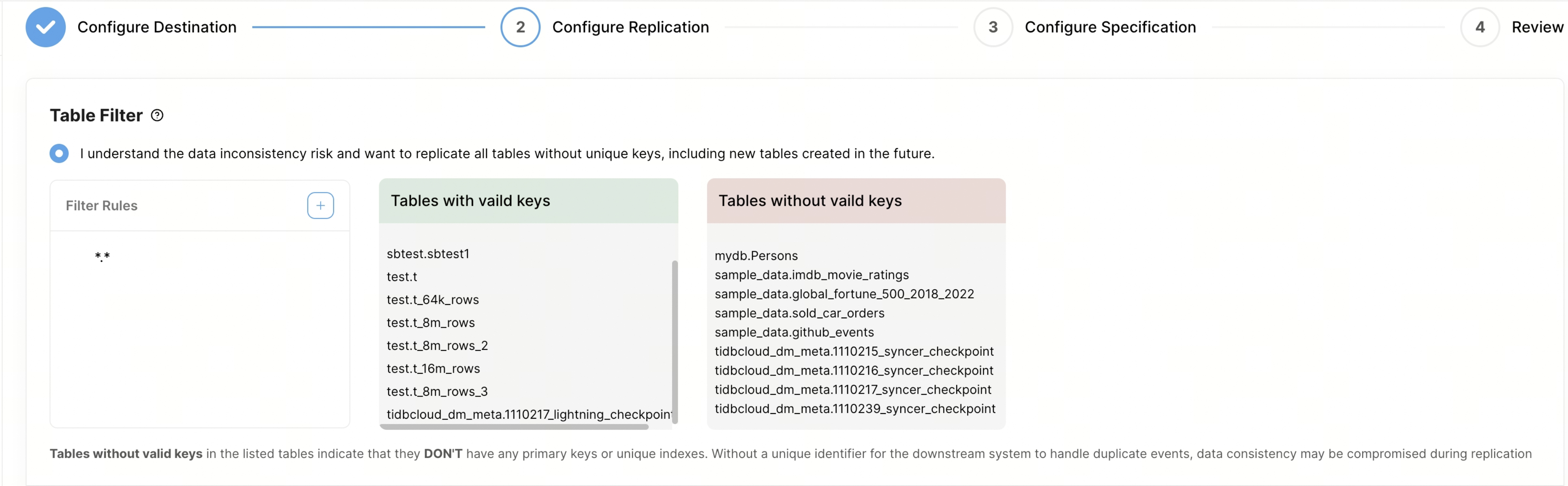
- 大文字と小文字を区別: フィルタールール内のデータベース名とテーブル名のマッチングで大文字と小文字を区別するかどうかを設定できます。デフォルトでは、大文字と小文字は区別されません。
- フィルタールール: この列でフィルタールールを設定できます。デフォルトでは、すべてのテーブルを複製するルール
*.*が設定されています。新しいルールを追加すると、 TiDB CloudはTiDB内のすべてのテーブルをクエリし、ルールに一致するテーブルのみを右側のボックスに表示されます。フィルタールールは最大100件まで追加できます。 - 有効なキーを持つテーブル: この列には、主キーや一意のインデックスなどの有効なキーを持つテーブルが表示されます。
- 有効なキーのないテーブル: この列には、主キーまたは一意キーがないテーブルが表示されます。これらのテーブルは、一意の識別子がないと、下流で重複イベントを処理する際にデータの不整合が発生する可能性があるため、レプリケーション中に問題が発生します。データの整合性を確保するには、レプリケーションを開始する前に、これらのテーブルに一意のキーまたは主キーを追加することをお勧めします。または、フィルタールールを使用してこれらのテーブルを除外することもできます。例えば、ルール
"!test.tbl1"を使用してテーブルtest.tbl1を除外できます。
イベント フィルターをカスタマイズして、複製するイベントをフィルターします。
- 一致するテーブル: この列では、イベントフィルターを適用するテーブルを設定できます。ルールの構文は、前述の「テーブルフィルター」領域で使用した構文と同じです。変更フィードごとに最大10個のイベントフィルタールールを追加できます。
- イベント フィルター: 次のイベント フィルターを使用して、変更フィードから特定のイベントを除外できます。
- イベントを無視: 指定されたイベント タイプを除外します。
- SQLを無視: 指定した式に一致するDDLイベントを除外します。例えば、
^drop指定するとDROPで始まる文が除外され、add column指定するとADD COLUMNを含む文が除外されます。 - 挿入値式を無視: 特定の条件を満たす
INSERT文を除外します。例えば、id >= 100指定すると、idが100以上のINSERT文が除外されます。 - 新しい値の更新式を無視: 新しい値が指定条件に一致する
UPDATE文を除外します。例えば、gender = 'male'指定すると、genderがmaleになる更新は除外されます。 - 更新前の値を無視: 指定した条件に一致する古い値を持つステートメントを
UPDATE除外します。例えば、age < 18指定すると、古い値ageが18未満となる更新は除外されます。 - 削除値式を無視: 指定された条件を満たす
DELETE文を除外します。例えば、name = 'john'指定すると、nameが'john'となるDELETE文が除外されます。
[レプリケーション開始位置]領域で、次のいずれかのレプリケーション位置を選択します。
- 今からレプリケーションを開始します
- 特定のTSOからレプリケーションを開始する
- 特定の時間からレプリケーションを開始する
データ形式領域で、 CSVまたはCanal-JSON形式のいずれかを選択します。
CSV形式を設定するには、次のフィールドに入力します。
- バイナリエンコード方式: バイナリデータのエンコード方式。base64(デフォルト)またはhex を**選択できます。AWS DMS と統合する場合はhex を**使用してください。
- 日付区切り: 年、月、日に基づいてデータを回転するか、まったく回転しないことを選択します。
- 区切り文字: CSVファイル内の値を区切る文字を指定します。最も一般的に使用される区切り文字はカンマ(
,)です。 - 引用符: 区切り文字または特殊文字を含む値を囲む文字を指定します。引用符としては通常、二重引用符 (
") が使用されます。 - Null/Empty値:CSVファイル内でnullまたは空の値をどのように表現するかを指定します。これは、データを適切に処理および解釈するために重要です。
- コミット Ts を含める: CSV 行に
commit-ts含めるかどうかを制御します。
Canal-JSONはプレーンなJSONテキスト形式です。設定するには、以下のフィールドに入力してください。
- 日付区切り: 年、月、日に基づいてデータを回転するか、まったく回転しないことを選択します。
- TiDB 拡張機能を有効にする: このオプションを有効にすると、TiCDC はウォーターマークイベント送信し、 TiDB拡張フィールド Canal-JSON メッセージに追加します。
フラッシュ パラメータ領域では、次の 2 つの項目を設定できます。
- フラッシュ間隔: デフォルトでは 60 秒に設定されていますが、2 秒から 10 分の範囲で調整可能です。
- ファイル サイズ: デフォルトでは 64 MB に設定されていますが、1 MB ~ 512 MB の範囲で調整可能です。

注記:
これら2つのパラメータは、クラウドstorageに生成される各データベーステーブルごとのオブジェクト数に影響します。テーブル数が多い場合、同じ設定を使用すると生成されるオブジェクト数が増加し、クラウドstorageAPIの呼び出しコストが増加します。したがって、RPO(Recovery Point Objective:復旧時点目標)とコスト要件に基づいて、これらのパラメータを適切に設定することをお勧めします。
「イベントの分割」エリアでは、
UPDATEイベントをDELETEつとINSERTイベントに分割するか、UPDATEイベントのままにするかを選択します。詳細については、 MySQL以外のシンクの主キーまたは一意キーのUPDATEイベントを分割する参照してください。
ステップ3. 仕様を構成する
次へをクリックして、変更フィード仕様を構成します。
- 「Changefeed 仕様」領域で、Changefeed で使用されるレプリケーション容量単位 (RCU) の数を指定します。
- 「Changefeed 名」領域で、Changefeed の名前を指定します。
ステップ4. 構成を確認してレプリケーションを開始する
「次へ」をクリックして、変更フィード構成を確認します。
- すべての構成が正しいことを確認したら、 [作成]をクリックして、変更フィードの作成を続行します。
- 設定を変更する必要がある場合は、 「前へ」をクリックして戻って必要な変更を加えます。
シンクはすぐに起動し、シンクのステータスが「作成中」から「実行中」に変わることがわかります。
変更フィードの名前をクリックすると、詳細ページに移動します。このページでは、チェックポイントのステータス、レプリケーションのレイテンシー、その他の関連メトリックなど、変更フィードに関する詳細情報を確認できます。