統計入門
TiDB は統計を使用して決定しますどのインデックスを選択するか 。 tidb_analyze_version変数は、TiDB によって収集される統計を制御します。現在、 tidb_analyze_version = 1とtidb_analyze_version = 2の 2 つのバージョンの統計がサポートされています。
- オンプレミス TiDB の場合、この変数のデフォルト値は v5.1.0 より前は
1です。 v5.3.0 以降のバージョンでは、この変数のデフォルト値は2です。クラスターが v5.3.0 より前のバージョンから v5.3.0 以降にアップグレードされた場合、デフォルト値のtidb_analyze_versionは変更されません。 - TiDB Cloudの場合、この変数のデフォルト値は
1です。
ノート:
tidb_analyze_version = 2の場合、ANALYZE実行後にメモリオーバーフローが発生した場合は、tidb_analyze_version = 1設定して次のいずれかの操作を実行する必要があります。
ANALYZEステートメントを手動で実行する場合は、分析するすべてのテーブルを手動で分析します。自動分析が有効になっているために TiDB が
ANALYZEステートメントを自動的に実行する場合は、DROP STATSステートメントを生成する次のステートメントを実行します。前のステートメントの結果が長すぎてコピー アンド ペーストできない場合は、結果を一時テキスト ファイルにエクスポートし、次のようにファイルから実行できます。
これら 2 つのバージョンには、TiDB に異なる情報が含まれています。
バージョン 1 と比較して、バージョン 2 の統計では、データ ボリュームが膨大な場合にハッシュの衝突によって生じる可能性のある不正確さが回避されます。また、ほとんどのシナリオで推定精度が維持されます。
このドキュメントでは、ヒストグラム、Count-Min Sketch、および Top-N について簡単に紹介し、統計の収集と維持について詳しく説明します。
ヒストグラム
ヒストグラムは、データの分布を近似的に表したものです。値の範囲全体を一連のバケットに分割し、単純なデータを使用して、バケットに含まれる値の数など、各バケットを記述します。 TiDB では、各テーブルの特定の列に対して同じ深さのヒストグラムが作成されます。等深度ヒストグラムを使用して、間隔クエリを推定できます。
ここで「等深さ」とは、各バケットに入る値の数が可能な限り等しいことを意味します。たとえば、特定のセット {1.6, 1.9, 1.9, 2.0, 2.4, 2.6, 2.7, 2.7, 2.8, 2.9, 3.4, 3.5} に対して、4 つのバケットを生成する必要があります。等深度ヒストグラムは次のとおりです。 [1.6, 1.9]、[2.0, 2.6]、[2.7, 2.8]、[2.9, 3.5] の 4 つのバケットが含まれています。バケットの深さは 3 です。
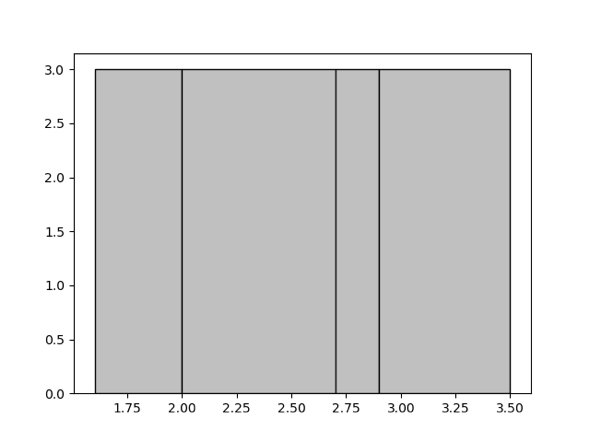
ヒストグラムのバケット数の上限を決めるパラメータについては、 手動収集を参照してください。バケットの数が多いほど、ヒストグラムの精度は高くなります。ただし、精度を高くすると、メモリリソースの使用量が犠牲になります。この数は、実際のシナリオに従って適切に調整できます。
カウントミンスケッチ
Count-Min Sketch はハッシュ構造です。等価クエリにa = 1またはINクエリ (たとえば、 a in (1, 2, 3) ) が含まれている場合、TiDB はこのデータ構造を使用して推定します。
Count-Min Sketch はハッシュ構造であるため、ハッシュ衝突が発生する可能性があります。 EXPLAINステートメントにおいて、同等のクエリの見積もりが実際の値から大きく外れている場合は、大きい値と小さい値が一緒にハッシュされていると見なすことができます。この場合、次のいずれかの方法でハッシュの衝突を回避できます。
WITH NUM TOPNパラメータを変更します。 TiDB は高頻度 (上位 x) データを個別に保存し、その他のデータは Count-Min Sketch に保存します。したがって、大きい値と小さい値が一緒にハッシュされるのを防ぐために、WITH NUM TOPNの値を増やすことができます。 TiDB では、デフォルト値は 20 です。最大値は 1024 です。このパラメーターの詳細については、 フルコレクションを参照してください。- 2 つのパラメーター
WITH NUM CMSKETCH DEPTHとWITH NUM CMSKETCH WIDTHを変更します。どちらもハッシュ バケットの数と衝突確率に影響します。実際のシナリオに従って 2 つのパラメーターの値を適切に増やして、ハッシュ衝突の可能性を減らすことができますが、統計のメモリ使用量が高くなります。 TiDB では、WITH NUM CMSKETCH DEPTHのデフォルト値は 5 で、WITH NUM CMSKETCH WIDTHのデフォルト値は 2048 です。2 つのパラメーターの詳細については、 フルコレクション参照してください。
上位 N の値
トップ N 値は、列またはインデックスで上位 N 個のオカレンスを持つ値です。 TiDB は、上位 N 値の値と発生を記録します。
統計を収集する
手動収集
ANALYZEステートメントを実行して、統計を収集できます。
ノート:
TiDB での
ANALYZE TABLEの実行時間は、MySQL や InnoDB よりも長くなります。 InnoDB では少数のページのみがサンプリングされますが、TiDB では包括的な統計セットが完全に再構築されます。 MySQL 用に作成されたスクリプトは、単純にANALYZE TABLE短時間の操作であると想定している可能性があります。迅速な分析のために、
tidb_enable_fast_analyze~1を設定してクイック分析機能を有効にすることができます。このパラメーターのデフォルト値は0です。クイック分析を有効にすると、TiDB は約 10,000 行のデータをランダムにサンプリングして統計を作成します。そのため、データ分布が不均一な場合やデータ量が比較的少ない場合、統計情報の精度は比較的低くなります。間違ったインデックスを選択するなど、不適切な実行計画につながる可能性があります。通常の
ANALYZEステートメントの実行時間が許容できる場合は、クイック分析機能を無効にすることをお勧めします。
tidb_enable_fast_analyzeは実験的機能であり、現在のところtidb_analyze_version=2の統計情報と正確には一致しません。したがって、tidb_enable_fast_analyzeが有効な場合は、tidb_analyze_versionから1の値を設定する必要があります。
フルコレクション
次の構文を使用して、完全なコレクションを実行できます。
TableNameListのすべてのテーブルの統計を収集するには:
```sql
ANALYZE TABLE TableNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
WITH NUM BUCKETS生成されたヒストグラムのバケットの最大数を指定します。WITH NUM TOPN生成されるTOPNの最大数を指定します。WITH NUM CMSKETCH DEPTHCM スケッチの深さを指定します。WITH NUM CMSKETCH WIDTHCM スケッチの幅を指定します。WITH NUM SAMPLESサンプル数を指定します。WITH FLOAT_NUM SAMPLERATEサンプリング レートを指定します。
WITH NUM SAMPLESとWITH FLOAT_NUM SAMPLERATEサンプルを収集する 2 つの異なるアルゴリズムに対応します。
WITH NUM SAMPLES、TiDB のリザーバー サンプリング メソッドで実装されるサンプリング セットのサイズを指定します。テーブルが大きい場合、この方法を使用して統計を収集することはお勧めしません。リザーバ サンプリングの中間結果セットには冗長な結果が含まれているため、メモリなどのリソースにさらに負荷がかかります。WITH FLOAT_NUM SAMPLERATEは v5.3.0 で導入されたサンプリング方法です。値の範囲が(0, 1]の場合、このパラメーターはサンプリング レートを指定します。これは、TiDB のベルヌーイ サンプリングの方法で実装されています。これは、より大きなテーブルのサンプリングに適していて、収集効率とリソース使用率が優れています。
v5.3.0 より前の TiDB は、リザーバー サンプリング メソッドを使用して統計を収集します。 v5.3.0 以降、TiDB バージョン 2 統計は、デフォルトでベルヌーイ サンプリング法を使用して統計を収集します。リザーバー サンプリング法を再利用するには、 WITH NUM SAMPLESステートメントを使用できます。
現在のサンプリング レートは、適応アルゴリズムに基づいて計算されます。 SHOW STATS_METAを使用してテーブル内の行数を観測できる場合、この行数を使用して 100,000 行に対応するサンプリング レートを計算できます。この数を確認できない場合は、 TABLE_STORAGE_STATSの表のTABLE_KEYS列を別の参照として使用して、サンプリング レートを計算できます。
ノート:
通常、
STATS_METAはTABLE_KEYSより信頼性が高くなります。ただし、 TiDB Lightningのような方法でデータをインポートすると、STATS_METAの結果は0になります。この状況に対処するために、STATS_METAの結果がTABLE_KEYSの結果よりもはるかに小さい場合、TABLE_KEYS使用してサンプリング レートを計算できます。
一部の列で統計を収集する
ほとんどの場合、SQL ステートメントを実行するとき、オプティマイザーは一部の列 ( WHERE 、 JOIN 、 ORDER BY 、およびGROUP BYステートメントの列など) の統計のみを使用します。これらの列はPREDICATE COLUMNSと呼ばれます。
テーブルに多数の列がある場合、すべての列の統計を収集すると、大きなオーバーヘッドが発生する可能性があります。オーバーヘッドを削減するために、オプティマイザが使用する特定の列またはPREDICATE COLUMNSの列のみに関する統計を収集できます。
ノート:
一部の列に関する統計の収集は、
tidb_analyze_version = 2にのみ適用されます。
- 特定の列の統計を収集するには、次の構文を使用します。
```sql
ANALYZE TABLE TableName COLUMNS ColumnNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
構文で、 `ColumnNameList`ターゲット列の名前リストを指定します。複数の列を指定する必要がある場合は、コンマ`,`を使用して列名を区切ります。たとえば、 `ANALYZE table t columns a, b`です。この構文は、特定のテーブル内の特定の列に関する統計を収集するだけでなく、そのテーブル内のインデックス付きの列とすべてのインデックスに関する統計を同時に収集します。
> **ノート:**
>
> 上記の構文は完全なコレクションです。たとえば、この構文を使用して列`a`と`b`統計を収集した後、列`c`の統計も収集する場合は、 `ANALYZE TABLE t COLUMNS c`を使用して追加の列`c`のみを指定するのではなく、 `ANALYZE table t columns a, b, c`を使用して 3 つの列すべてを指定する必要があります。
PREDICATE COLUMNSに関する統計を収集するには、次の手順を実行します。tidb_enable_column_trackingシステム変数の値をONに設定して、TiDB がPREDICATE COLUMNSを収集できるようにします。設定後、TiDB は 100 *
stats-leaseごとにPREDICATE COLUMNS情報をmysql.column_stats_usageシステム テーブルに書き込みます。ビジネスのクエリ パターンが比較的安定したら、次の構文を使用して
PREDICATE COLUMNSに関する統計を収集します。
```sql
ANALYZE TABLE TableName PREDICATE COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
この構文は、特定のテーブルの`PREDICATE COLUMNS`に関する統計を収集するだけでなく、インデックス付きの列とそのテーブル内のすべてのインデックスに関する統計を同時に収集します。
> **ノート:**
>
> - `mysql.column_stats_usage`システム テーブルにそのテーブルの`PREDICATE COLUMNS`レコードが含まれていない場合、上記の構文は、そのテーブル内のすべての列とすべてのインデックスに関する統計を収集します。
> - この構文を使用して統計を収集した後、新しいタイプの SQL クエリを実行すると、オプティマイザは一時的に古い列または疑似列の統計を使用する可能性があり、TiDB は次回から使用された列の統計を収集します。
- すべての列とインデックスの統計を収集するには、次の構文を使用します。
```sql
ANALYZE TABLE TableName ALL COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
ANALYZEステートメント ( COLUMNS ColumnNameList 、 PREDICATE COLUMNS 、およびALL COLUMNSを含む) で列構成を保持する場合は、 tidb_persist_analyze_optionsシステム変数の値をONに設定してANALYZE 構成の永続性機能を有効にします。 ANALYZE 構成永続化機能を有効にした後:
- TiDB が自動的に統計を収集する場合、または列構成を指定せずに
ANALYZEステートメントを実行して手動で統計を収集する場合、TiDB は以前に永続化された構成を使用して統計収集を続行します。 - 列構成を指定して
ANALYZEステートメントを複数回手動で実行すると、TiDB は、最新のANALYZEステートメントで指定された新しい構成を使用して、以前に記録された永続的な構成を上書きします。
統計が収集されたPREDICATE COLUMNSおよび列を見つけるには、次の構文を使用します。
SHOW COLUMN_STATS_USAGE [ShowLikeOrWhere];
SHOW COLUMN_STATS_USAGEステートメントは、次の 6 つの列を返します。
次の例では、 ANALYZE TABLE t PREDICATE COLUMNS;実行した後、TiDB は列b 、 c 、およびdの統計を収集します。ここで、列bはPREDICATE COLUMNであり、列cおよびdはインデックス列です。
SET GLOBAL tidb_enable_column_tracking = ON;
Query OK, 0 rows affected (0.00 sec)
CREATE TABLE t (a INT, b INT, c INT, d INT, INDEX idx_c_d(c, d));
Query OK, 0 rows affected (0.00 sec)
-- The optimizer uses the statistics on column b in this query.
SELECT * FROM t WHERE b > 1;
Empty set (0.00 sec)
-- After waiting for a period of time (100 * stats-lease), TiDB writes the collected `PREDICATE COLUMNS` to mysql.column_stats_usage.
-- Specify `last_used_at IS NOT NULL` to show the `PREDICATE COLUMNS` collected by TiDB.
SHOW COLUMN_STATS_USAGE WHERE db_name = 'test' AND table_name = 't' AND last_used_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+------------------+
| test | t | | b | 2022-01-05 17:21:33 | NULL |
+---------+------------+----------------+-------------+---------------------+------------------+
1 row in set (0.00 sec)
ANALYZE TABLE t PREDICATE COLUMNS;
Query OK, 0 rows affected, 1 warning (0.03 sec)
-- Specify `last_analyzed_at IS NOT NULL` to show the columns for which statistics have been collected.
SHOW COLUMN_STATS_USAGE WHERE db_name = 'test' AND table_name = 't' AND last_analyzed_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+---------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+---------------------+
| test | t | | b | 2022-01-05 17:21:33 | 2022-01-05 17:23:06 |
| test | t | | c | NULL | 2022-01-05 17:23:06 |
| test | t | | d | NULL | 2022-01-05 17:23:06 |
+---------+------------+----------------+-------------+---------------------+---------------------+
3 rows in set (0.00 sec)
インデックスに関する統計を収集する
IndexNameList in TableNameのすべてのインデックスに関する統計を収集するには、次の構文を使用します。
ANALYZE TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
IndexNameListが空の場合、この構文はTableNameのすべてのインデックスの統計を収集します。
ノート:
収集の前後の統計情報の一貫性を確保するために、
tidb_analyze_versionが2の場合、この構文はインデックスのみではなく、テーブル全体 (すべての列とインデックスを含む) の統計を収集します。
パーティションに関する統計を収集する
PartitionNameListinTableNameのすべてのパーティションに関する統計を収集するには、次の構文を使用します。
```sql
ANALYZE TABLE TableName PARTITION PartitionNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
PartitionNameListinTableNameのすべてのパーティションのインデックス統計を収集するには、次の構文を使用します。
```sql
ANALYZE TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
テーブル内の一部のパーティションの一部の列の統計を収集するだけが必要な場合は、次の構文を使用します。
```sql
ANALYZE TABLE TableName PARTITION PartitionNameList [COLUMNS ColumnNameList|PREDICATE COLUMNS|ALL COLUMNS] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
動的プルーニング モードで分割されたテーブルの統計を収集する
動的プルーニング モードで分割されたテーブルにアクセスすると、TiDB は GlobalStats と呼ばれるテーブルレベルの統計を収集します。現在、GlobalStats はすべてのパーティションの統計から集計されています。動的プルーニング モードでは、パーティションテーブルの統計の更新により、GlobalStats の更新がトリガーされる可能性があります。
ノート:
GlobalStats の更新がトリガーされると、次のようになります。
- 一部のパーティションに統計がない場合 (分析されたことのない新しいパーティションなど)、GlobalStats の生成が中断され、パーティションで使用できる統計がないことを示す警告メッセージが表示されます。
- 一部の列の統計が特定のパーティションに存在しない場合 (これらのパーティションで分析するために別の列が指定されている場合)、これらの列の統計が集計されると GlobalStats の生成が中断され、特定のパーティションに一部の列の統計が存在しないことを示す警告メッセージが表示されます。パーティション。
動的プルーニング モードでは、パーティションとテーブルの Analyze 構成は同じである必要があります。したがって、
ANALYZE TABLE TableName PARTITION PartitionNameListステートメントに続いてCOLUMNS構成を指定したり、WITHに続いてOPTIONS構成を指定したりすると、TiDB はそれらを無視して警告を返します。
増分収集
完全な収集後の分析速度を向上させるために、増分収集を使用して、時間列などの単調に減少しない列で新しく追加されたセクションを分析できます。
ノート:
- 現在、増分コレクションはインデックスに対してのみ提供されています。
- 増分コレクションを使用する場合、テーブルに存在する操作が
INSERTだけであること、およびインデックス列に新しく挿入された値が単調に減少しないことを確認する必要があります。そうしないと、統計情報が不正確になり、適切な実行計画を選択する TiDB オプティマイザに影響を与える可能性があります。
次の構文を使用して増分コレクションを実行できます。
- all
IndexNameListsinTableNameの索引列に関する統計を増分的に収集するには、次のようにします。
```sql
ANALYZE INCREMENTAL TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
- all
PartitionNameListsinTableNameのパーティションの索引列に関する統計を増分的に収集するには、次のようにします。
```sql
ANALYZE INCREMENTAL TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
自動更新
INSERT 、 DELETE 、またはUPDATEステートメントの場合、TiDB は行数と更新された行を自動的に更新します。 TiDB はこの情報を定期的に保持し、更新サイクルは 20 * stats-leaseです。デフォルト値のstats-leaseは3sです。値を0として指定すると、自動的に更新されません。
統計の自動更新に関連する 3 つのシステム変数は次のとおりです。
テーブル内のtblの行の総数に対する変更された行の数の比率がtidb_auto_analyze_ratioよりも大きく、現在の時刻がtidb_auto_analyze_start_timeからtidb_auto_analyze_end_timeの間にある場合、TiDB はバックグラウンドでANALYZE TABLE tblステートメントを実行して、この統計を自動的に更新します。テーブル。
小さなテーブルで少量のデータを変更すると自動更新が頻繁にトリガーされるという状況を回避するために、テーブルの行数が 1000 未満の場合、そのようなデータ変更は TiDB で自動更新をトリガーしません。 SHOW STATS_METAステートメントを使用して、テーブル内の行数を表示できます。
ノート:
現在、自動更新では、手動
ANALYZEで入力された設定項目は記録されません。したがって、WITH構文を使用してANALYZEの収集動作を制御する場合は、スケジュールされたタスクを手動で設定して統計を収集する必要があります。
TiDB v6.0 以降、TiDB はKILLステートメントを使用して、バックグラウンドで実行されているANALYZEタスクを終了することをサポートしています。バックグラウンドで実行されているANALYZEタスクが多くのリソースを消費し、アプリケーションに影響を与えることがわかった場合は、次の手順に従ってANALYZEタスクを終了できます。
- 次の SQL ステートメントを実行します。
```sql
SHOW ANALYZE STATUS
```
結果の`instance`列目と`process_id`列目を確認すると、TiDBインスタンスのアドレスとバックグラウンド`ANALYZE`タスクのタスク`ID`取得できます。
バックグラウンドで実行されている
ANALYZEタスクを終了します。enable-global-killがtrue(デフォルトではtrue) の場合、KILL TIDB ${id};ステートメントを直接実行できます。ここで、${id}は、前の手順で取得したバックグラウンドANALYZEタスクのIDです。enable-global-killがfalseの場合、クライアントを使用して、バックエンドANALYZEタスクを実行している TiDB インスタンスに接続し、KILL TIDB ${id};ステートメントを実行する必要があります。クライアントを使用して別の TiDB インスタンスに接続する場合、またはクライアントと TiDB クラスターの間にプロキシがある場合、KILLステートメントはバックグラウンドのANALYZEタスクを終了できません。
KILLステートメントの詳細については、 KILLを参照してください。
ANALYZE同時実行の制御
ANALYZEステートメントを実行すると、次のパラメーターを使用して同時実行性を調整し、システムへの影響を制御できます。
tidb_build_stats_concurrency
現在、 ANALYZEステートメントを実行すると、タスクは複数の小さなタスクに分割されます。各タスクは、1 つの列またはインデックスに対してのみ機能します。 tidb_build_stats_concurrencyパラメータを使用して、同時タスクの数を制御できます。デフォルト値は4です。
tidb_distsql_scan_concurrency
通常の列を分析する場合、 tidb_distsql_scan_concurrencyパラメータを使用して、一度に読み取るリージョンの数を制御できます。デフォルト値は15です。
tidb_index_serial_scan_concurrency
インデックス列を分析する場合、 tidb_index_serial_scan_concurrencyパラメータを使用して、一度に読み取るリージョンの数を制御できます。デフォルト値は1です。
ANALYZE 構成を保持する
v5.4.0 以降、TiDB はANALYZEの構成の永続化をサポートしています。この機能を使用すると、既存の構成を将来の統計収集に簡単に再利用できます。
以下は、永続性をサポートするANALYZE構成です。
ANALYZE 構成の永続性を有効にする
ANALYZE構成永続化機能は、デフォルトで有効になっています (システム変数tidb_analyze_versionデフォルトで2で、 tidb_persist_analyze_optionsはONです)。
この機能を使用して、ステートメントを手動で実行するときにANALYZEステートメントで指定された永続化構成を記録できます。記録されると、次に TiDB が自動的に統計を更新するか、これらの構成を指定せずに手動で統計を収集するときに、TiDB は記録された構成に従って統計を収集します。
永続構成を指定してANALYZEステートメントを複数回手動で実行すると、TiDB は、最新のANALYZEステートメントで指定された新しい構成を使用して、以前に記録された永続構成を上書きします。
ANALYZE 構成の永続性を無効にする
ANALYZE構成永続化機能を無効にするには、 tidb_persist_analyze_optionsシステム変数をOFFに設定します。 ANALYZE構成永続化機能はtidb_analyze_version = 1には適用されないため、設定tidb_analyze_version = 1でこの機能を無効にすることもできます。
ANALYZE構成永続化機能を無効にした後、TiDB は永続化された構成レコードをクリアしません。したがって、この機能を再度有効にすると、TiDB は以前に記録された永続的な構成を使用して統計を収集し続けます。
ノート:
ANALYZE構成の永続化機能を再度有効にしたときに、以前に記録された永続化構成が最新のデータに適用できなくなった場合は、ANALYZEステートメントを手動で実行し、新しい永続化構成を指定する必要があります。
統計を収集するためのメモリクォータ
TiDB v6.1.0 以降、システム変数tidb_mem_quota_analyzeを使用して、TiDB で統計を収集するためのメモリクォータを制御できます。
適切な値tidb_mem_quota_analyze設定するには、クラスターのデータ サイズを考慮してください。デフォルトのサンプリング レートを使用する場合、主な考慮事項は、列の数、列の値のサイズ、および TiDB のメモリ構成です。最大値と最小値を構成するときは、次の提案を考慮してください。
ノート:
以下の提案は参考用です。実際のシナリオに基づいて値を構成する必要があります。
- 最小値: TiDB が最も列の多いテーブルから統計を収集するときの最大メモリ使用量よりも大きくする必要があります。おおよその参考値: TiDB がデフォルト構成を使用して 20 列のテーブルから統計を収集する場合、最大メモリ使用量は約 800 MiB です。 TiDB がデフォルト構成を使用して 160 列のテーブルから統計を収集する場合、最大メモリ使用量は約 5 GiB です。
- 最大値: TiDB が統計を収集していない場合は、使用可能なメモリよりも小さくする必要があります。
ANALYZE状態をビュー
ANALYZEステートメントを実行すると、次の SQL ステートメントを使用してANALYZEの現在の状態を表示できます。
SHOW ANALYZE STATUS [ShowLikeOrWhere]
このステートメントはANALYZEの状態を返します。 ShowLikeOrWhere使用して、必要な情報をフィルタリングできます。
現在、 SHOW ANALYZE STATUSステートメントは次の 11 列を返します。
TiDB v6.1.0 以降、 SHOW ANALYZE STATUSステートメントはクラスターレベルのタスクの表示をサポートしています。 TiDB の再起動後でも、このステートメントを使用して再起動前のタスク レコードを表示できます。 TiDB v6.1.0 より前では、 SHOW ANALYZE STATUSステートメントはインスタンス レベルのタスクのみを表示でき、タスク レコードは TiDB の再起動後にクリアされます。
SHOW ANALYZE STATUS最新のタスク レコードのみを表示します。 TiDB v6.1.0 から、システム テーブルを介して過去 7 日間の履歴タスクを表示できますmysql.analyze_jobs 。
tidb_mem_quota_analyzeが設定され、TiDB バックグラウンドで実行されている自動ANALYZEタスクがこのしきい値よりも多くのメモリを使用すると、タスクが再試行されます。 SHOW ANALYZE STATUSステートメントの出力で、失敗したタスクと再試行されたタスクを確認できます。
tidb_max_auto_analyze_timeが 0 よりも大きく、TiDB バックグラウンドで実行されている自動ANALYZEタスクがこのしきい値よりも時間がかかる場合、タスクは終了します。
mysql> SHOW ANALYZE STATUS [ShowLikeOrWhere];
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| Table_schema | Table_name | Partition_name | Job_info | Processed_rows | Start_time | End_time | State | Fail_reason |
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| test | sbtest1 | | retry auto analyze table all columns with 100 topn, 0.055 samplerate | 2000000 | 2022-05-07 16:41:09 | 2022-05-07 16:41:20 | finished | NULL |
| test | sbtest1 | | auto analyze table all columns with 100 topn, 0.5 samplerate | 0 | 2022-05-07 16:40:50 | 2022-05-07 16:41:09 | failed | analyze panic due to memory quota exceeds, please try with smaller samplerate |
統計をビュー
次のステートメントを使用して、統計ステータスを表示できます。
テーブルのメタデータ
SHOW STATS_METAステートメントを使用して、行の総数と更新された行の数を表示できます。
SHOW STATS_META [ShowLikeOrWhere];
ShowLikeOrWhereOptの構文は次のとおりです。

現在、 SHOW STATS_METAステートメントは次の 6 つの列を返します。
ノート:
TiDB が DML ステートメントに従って総行数と変更された行数を自動的に更新すると、
update_timeも更新されます。したがって、update_time、ANALYZEステートメントが最後に実行された時刻を示すとは限りません。
テーブルのヘルス状態
SHOW STATS_HEALTHYステートメントを使用して、テーブルの正常性状態をチェックし、統計の精度を大まかに見積もることができます。 modify_count >= row_countの場合、ヘルス状態は 0 です。 modify_count < row_countの場合、ヘルス状態は (1 - modify_count / row_count ) * 100 です。
構文は次のとおりです。
SHOW STATS_HEALTHY [ShowLikeOrWhere];
SHOW STATS_HEALTHYのあらすじは次のとおりです。

現在、 SHOW STATS_HEALTHYステートメントは次の 4 つの列を返します。
列のメタデータ
SHOW STATS_HISTOGRAMSステートメントを使用して、すべての列の異なる値の数とNULLの数を表示できます。
構文は次のとおりです。
SHOW STATS_HISTOGRAMS [ShowLikeOrWhere]
このステートメントは、異なる値の数と、すべての列のNULLの数を返します。 ShowLikeOrWhere使用して、必要な情報をフィルタリングできます。
現在、 SHOW STATS_HISTOGRAMSステートメントは次の 10 列を返します。
ヒストグラムのバケット
SHOW STATS_BUCKETSステートメントを使用して、ヒストグラムの各バケットを表示できます。
構文は次のとおりです。
SHOW STATS_BUCKETS [ShowLikeOrWhere]
回路図は以下の通りです:

このステートメントは、すべてのバケットに関する情報を返します。 ShowLikeOrWhere使用して、必要な情報をフィルタリングできます。
現在、 SHOW STATS_BUCKETSステートメントは次の 11 列を返します。
トップN情報
SHOW STATS_TOPNステートメントを使用して、TiDB によって現在収集されている上位 N 情報を表示できます。
構文は次のとおりです。
SHOW STATS_TOPN [ShowLikeOrWhere];
現在、 SHOW STATS_TOPNステートメントは次の 7 列を返します。
統計の削除
DROP STATSステートメントを実行して、統計を削除できます。
DROP STATS TableName
上記のステートメントは、 TableNameのすべての統計を削除します。パーティションテーブルが指定されている場合、このステートメントは、このテーブル内のすべてのパーティションの統計と、動的プルーニング モードで生成された GlobalStats を削除します。
DROP STATS TableName PARTITION PartitionNameList;
この前のステートメントは、 PartitionNameListで指定されたパーティションの統計のみを削除します。
DROP STATS TableName GLOBAL;
上記のステートメントは、指定されたテーブルの動的プルーニング モードで生成された GlobalStats のみを削除します。
負荷統計
デフォルトでは、列統計のサイズに応じて、TiDB は次のように異なる方法で統計をロードします。
- 少量のメモリを消費する統計 (count、distinctCount、nullCount など) の場合、列データが更新されている限り、TiDB は対応する統計を自動的にメモリにロードして、SQL 最適化段階で使用します。
- 大量のメモリを消費する統計 (ヒストグラム、TopN、Count-Min Sketch など) の場合、SQL 実行のパフォーマンスを確保するために、TiDB は必要に応じて統計を非同期にロードします。ヒストグラムを例に取ります。 TiDB は、オプティマイザがその列のヒストグラム統計を使用する場合にのみ、列のヒストグラム統計をメモリにロードします。オンデマンドの非同期統計ロードは、SQL 実行のパフォーマンスには影響しませんが、SQL 最適化の不完全な統計を提供する場合があります。
v5.4.0 以降、TiDB は同期読み込み統計機能を導入しています。この機能により、TiDB は、SQL ステートメントの実行時に大規模な統計 (ヒストグラム、TopN、Count-Min Sketch 統計など) をメモリに同期的にロードできるようになり、SQL 最適化のための統計の完全性が向上します。
この機能を有効にするには、システム変数tidb_stats_load_sync_waitの値をタイムアウト (ミリ秒単位) に設定します。これは、SQL 最適化が完全な列統計を同期的にロードするまで最大で待機できる時間です。この変数のデフォルト値は100で、機能が有効であることを示します。
統計の同期読み込み機能を有効にした後、次のように機能をさらに構成できます。
- SQL 最適化の待機時間がタイムアウトに達したときの TiDB の動作を制御するには、
tidb_stats_load_pseudo_timeoutシステム変数の値を変更します。この変数のデフォルト値はONです。これは、タイムアウト後、SQL 最適化プロセスがどの列でもヒストグラム、TopN、または CMSketch 統計を使用しないことを示します。この変数がOFFに設定されている場合、タイムアウト後、SQL の実行は失敗します。 - 同期ロード統計機能が同時に処理できる列の最大数を指定するには、TiDB 構成ファイルの
stats-load-concurrencyオプションの値を変更します。デフォルト値は5です。 - 同期ロード統計機能がキャッシュできる列要求の最大数を指定するには、TiDB 構成ファイルの
stats-load-queue-sizeオプションの値を変更します。デフォルト値は1000です。
統計のインポートとエクスポート
統計のエクスポート
統計をエクスポートするためのインターフェイスは次のとおりです。
${db_name}データベースの${table_name}テーブルの JSON 形式の統計を取得するには、次のようにします。
```
http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}
```
例えば:
```
curl -s http://127.0.0.1:10080/stats/dump/test/t1 -o /tmp/t1.json
```
- 特定の時間に
${db_name}データベースの${table_name}テーブルの JSON 形式の統計を取得するには:
```
http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyyMMddHHmmss}
```
統計のインポート
ノート:
MySQL クライアントを起動するときは、
--local-infile=1オプションを使用します。
通常、インポートされた統計は、エクスポート インターフェイスを使用して取得された JSON ファイルを参照します。
構文:
LOAD STATS 'file_name'
file_nameは、インポートする統計のファイル名です。
ロック統計
v6.5.0 以降、TiDB はロック統計をサポートしています。テーブルの統計がロックされると、テーブルの統計は変更できず、テーブルでANALYZEステートメントを実行できません。例えば:
テーブルtを作成し、そこにデータを挿入します。テーブルtの統計がロックされていない場合、 ANALYZEステートメントを正常に実行できます。
mysql> create table t(a int, b int);
Query OK, 0 rows affected (0.03 sec)
mysql> insert into t values (1,2), (3,4), (5,6), (7,8);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> analyze table t;
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> show warnings;
+-------+------+-----------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t |
+-------+------+-----------------------------------------------------------------+
1 row in set (0.00 sec)
テーブルtの統計をロックし、 ANALYZEを実行します。 SHOW STATS_LOCKEDの出力から、表tの統計がロックされていることがわかります。警告メッセージは、 ANALYZEステートメントがテーブルtをスキップしたことを示しています。
mysql> lock stats t;
Query OK, 0 rows affected (0.00 sec)
mysql> show stats_locked;
+---------+------------+----------------+--------+
| Db_name | Table_name | Partition_name | Status |
+---------+------------+----------------+--------+
| test | t | | locked |
+---------+------------+----------------+--------+
1 row in set (0.01 sec)
mysql> analyze table t;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> show warnings;
+---------+------+-----------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t |
| Warning | 1105 | skip analyze locked table: t |
+---------+------+-----------------------------------------------------------------+
2 rows in set (0.00 sec)
テーブルtとANALYZEの統計のロックを解除すると、再び正常に実行できます。
mysql> unlock stats t;
Query OK, 0 rows affected (0.01 sec)
mysql> analyze table t;
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> show warnings;
+-------+------+-----------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t |
+-------+------+-----------------------------------------------------------------+
1 row in set (0.00 sec)