タイタンの概要
タイタンは、キーと値の分離を実現する高性能なロックスDBプラグインです。Titanは、大きな値が使用される際のRocksDBでの書き込み増幅を軽減できます。
キーと値のペアの値のサイズが大きい場合(1KBまたは512Bを超える場合)、Titanは書き込み、更新、ポイント読み取りのシナリオにおいてRocksDBよりも優れたパフォーマンスを発揮します。ただし、Titanはstorage容量と範囲クエリのパフォーマンスを犠牲にすることで、より高い書き込みパフォーマンスを実現しています。SSDの価格が下がり続けるにつれて、このトレードオフはますます重要になるでしょう。
主な特徴
- ログ構造化マージツリー (LSM ツリー) から値を分離し、個別に保存することで書き込み増幅を削減します。
- RocksDBインスタンスをTitanにシームレスにアップグレードします。アップグレードには人的介入は必要なく、オンラインサービスにも影響はありません。
- 現在の TiKV で使用されているすべての RocksDB 機能との 100% の互換性を実現します。
使用シナリオ
Titan は、大量のデータが TiKV フォアグラウンドに書き込まれるシナリオに適しています。
- RocksDBは大量のコンパクションをトリガーするため、I/O帯域幅やCPUリソースを大量に消費します。これにより、フォアグラウンドでの読み取りおよび書き込みパフォーマンスが低下します。
- RocksDB の圧縮は (I/O 帯域幅の制限または CPU ボトルネックにより) 大幅に遅れ、書き込み停止が頻繁に発生します。
- RocksDB は大量の圧縮をトリガーし、多くの I/O 書き込みを引き起こし、SSD ディスクの寿命に影響を与えます。
前提条件
Titan を有効にするための前提条件は次のとおりです。
- 値の平均サイズが大きい、またはすべての大きな値のサイズが値の合計サイズの大部分を占めています。現在、1KBを超える値のサイズは大きな値とみなされます。状況によっては、この数値(1KB)が512Bになる場合があります。TiKV Raftレイヤーの制限により、TiKVに書き込まれる単一の値は8MBを超えることはできません。1
raft-entry-max-size設定値を調整することで、この制限を緩和できます。 - 範囲クエリは実行されないか、高い範囲クエリのパフォーマンスを必要としません。Titan に格納されるデータは整列されていないため、範囲クエリのパフォーマンスは RocksDB よりも低く、特に広い範囲のクエリではその傾向が顕著です。PingCAP の内部テストによると、Titan の範囲クエリのパフォーマンスは RocksDB よりも 40% から数倍低いことが示されています。
- 十分なディスク容量(同じデータ量でRocksDBのディスク消費量の2倍の容量を確保することを検討してください)。これは、Titanがディスク容量を犠牲にして書き込み増幅を削減するためです。また、Titanは値を1つずつ圧縮するため、圧縮率はRocksDBよりも低くなります。RocksDBはブロックを1つずつ圧縮するため、TitanはRocksDBよりも多くのstorage容量を消費しますが、これは想定内の正常な動作です。状況によっては、Titanのstorage消費量がRocksDBの2倍になる場合があります。
バージョン7.6.0以降、新規作成されたクラスターではTitanがデフォルトで有効になっています。小さなTiKV値はRocksDBに保存されたままなので、このシナリオでもTitanを有効にすることができます。
Titan のパフォーマンスを向上させたい場合は、ブログ投稿Titan: 書き込み増幅を減らす RocksDB プラグイン参照してください。
アーキテクチャと実装
次の図は Titan のアーキテクチャを示しています。
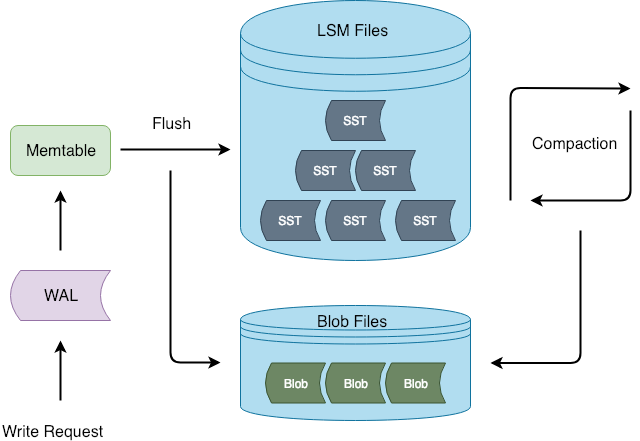
フラッシュおよびコンパクション操作中、TitanはLSMツリーから値を分離します。このアプローチの利点は、書き込みプロセスがRocksDBと一貫性を保つため、RocksDBへの侵入的な変更の可能性が低減されることです。
ブロブファイル
TitanはLSMツリーから値ファイルを分離し、BlobFileに保存します。次の図はBlobFileの形式を示しています。
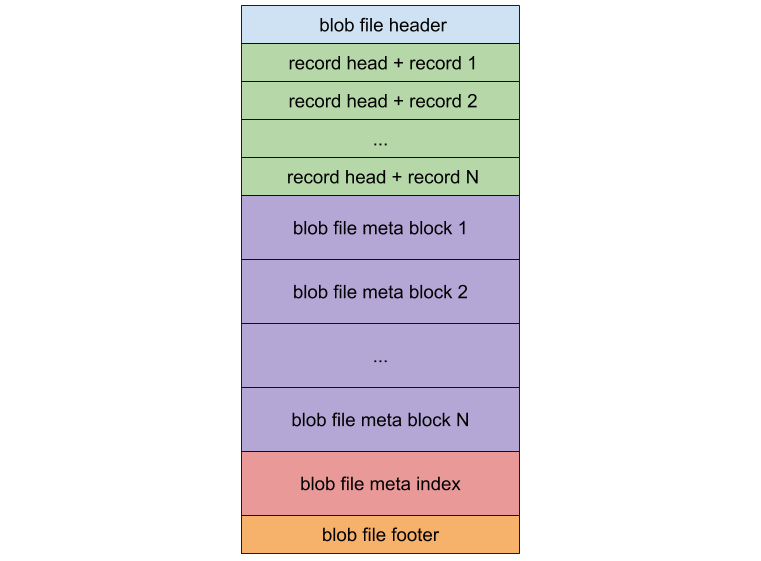
BLOBファイルは主にBLOBレコード、メタブロック、メタインデックスブロック、フッターで構成されます。各ブロックレコードにはキーと値のペアが格納されます。メタブロックはスケーラビリティのために使用され、BLOBファイルに関連するプロパティが格納されます。メタインデックスブロックはメタブロックの検索に使用されます。
注記:
- BLOB ファイル内のキーと値のペアは順番に格納されるため、Iterator を実装すると、プリフェッチによって順次読み取りのパフォーマンスが向上します。
- 各BLOBレコードは、値に対応するユーザーキーのコピーを保持します。これにより、Titanがガベージコレクション(GC)を実行する際に、ユーザーキーを照会し、対応する値が古くなっているかどうかを識別できます。ただし、このプロセスによって書き込み増幅が発生します。
- BlobFile は BLOB レコードレベルでの圧縮をサポートします。Titan はスナッピー 、
lz4、zstdなどの複数の圧縮アルゴリズムをサポートします。v7.6.0 より前のバージョンでは、デフォルトの圧縮アルゴリズムはlz4でした。v7.6.0 以降では、デフォルトの圧縮アルゴリズムはzstdです。- Snappy 圧縮ファイルは公式Snappyフォーマットである必要があります。他のバリアントはサポートされていません。
Titanテーブルビルダー
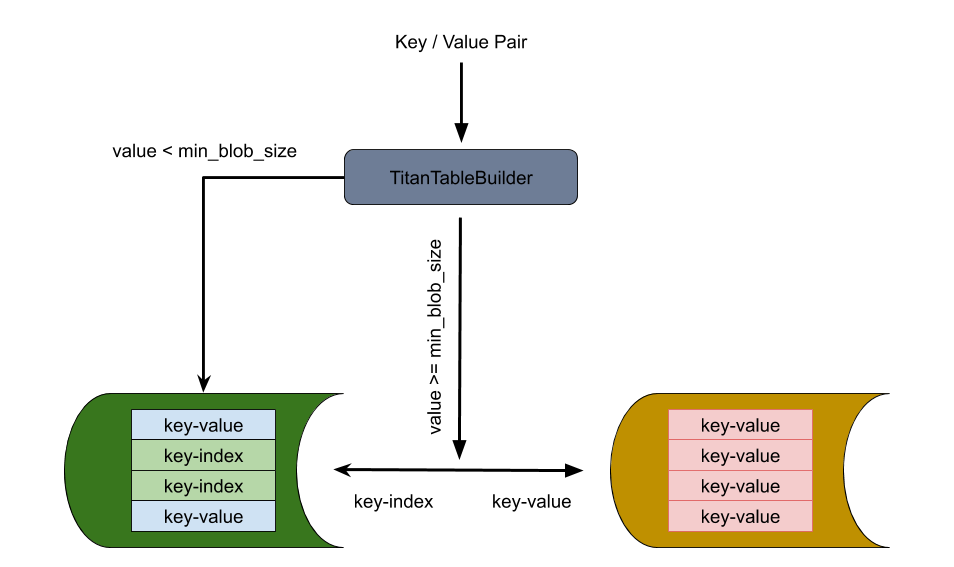
TitanTableBuilderは、キーと値の分離を実現するための鍵です。TitanTableBuilderはキーペアの値のサイズを決定し、それに基づいてキーと値のペアから値を分離してBLOBファイルに保存するかどうかを決定します。
- 値のサイズが
min_blob_size以上の場合、TitanTableBuilder は値を分割して BLOB ファイルに保存します。また、TitanTableBuilder はインデックスを生成して SST に書き込みます。 - 値のサイズが
min_blob_sizeより小さい場合、TitanTableBuilder は値を SST に直接書き込みます。
上記のプロセスで、TitanをRocksDBにダウングレードすることも可能です。RocksDBが圧縮を実行している間、分離された値は新しく生成されたSSTファイルに書き戻されます。
ガベージコレクション
Titanはガベージコレクション(GC)を使用してスペースを再利用します。LSMツリーのコンパクションでキーが再利用される際、BLOBファイルに格納されている一部の値は同時に削除されません。そのため、Titanは定期的にGCを実行し、古くなった値を削除する必要があります。Titanは以下の2種類のGCを提供します。
- BLOBファイルは定期的に統合され、古い値を削除するために書き換えられます。これはGCの通常の実行方法です。
- LSMツリーのコンパクションと同時にBLOBファイルの書き換えが行われます。これがレベルマージの機能です。
通常のGC
Titan は、RocksDB の TablePropertiesCollector および EventListener コンポーネントを使用して、GC の情報を収集します。
テーブルプロパティコレクター
RocksDBは、カスタムテーブルプロパティコレクターであるBlobFileSizeCollectorを使用して、SSTからプロパティを収集し、対応するSSTファイルに書き込むことができます。収集されたプロパティはBlobFileSizePropertiesという名前になります。次の図は、BlobFileSizeCollectorのワークフローとデータ形式を示しています。
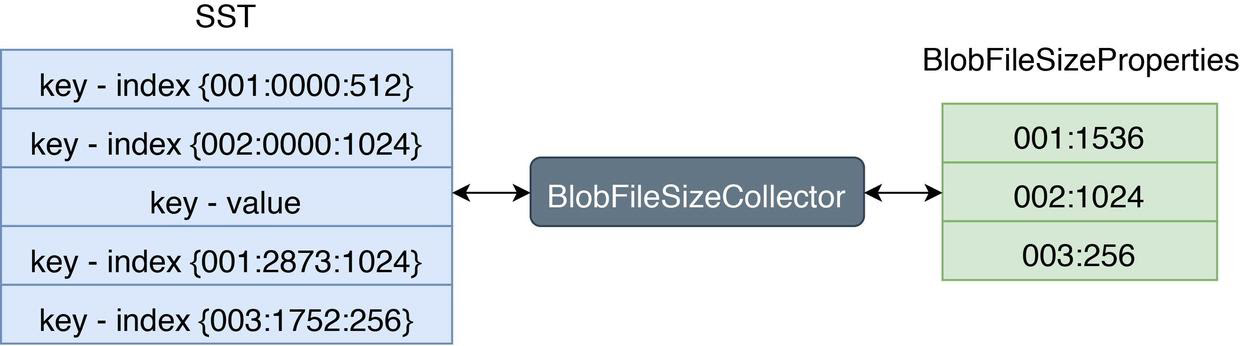
左側はSSTインデックスのフォーマットです。最初の列はBLOBファイルID、2番目の列はBLOBファイル内のBLOBレコードのオフセット、3番目の列はBLOBレコードのサイズです。
右側はBlobFileSizePropertiesのフォーマットです。各行はBLOBファイルと、そのBLOBファイルに保存されているデータの量を表します。最初の列はBLOBファイルのID、2番目の列はデータのサイズです。
イベントリスナー
RocksDBは、古いデータを破棄してスペースを再利用するためにコンパクションを使用します。コンパクションのたびに、Titan内の一部のBLOBファイルに一部または全部が古くなったデータが含まれる可能性があります。そのため、コンパクションイベントをリッスンすることでGCをトリガーできます。コンパクション中に、SSTの入出力BLOBファイルサイズプロパティを収集して比較することで、どのBLOBファイルがGCを必要とするかを特定できます。次の図は、一般的なプロセスを示しています。
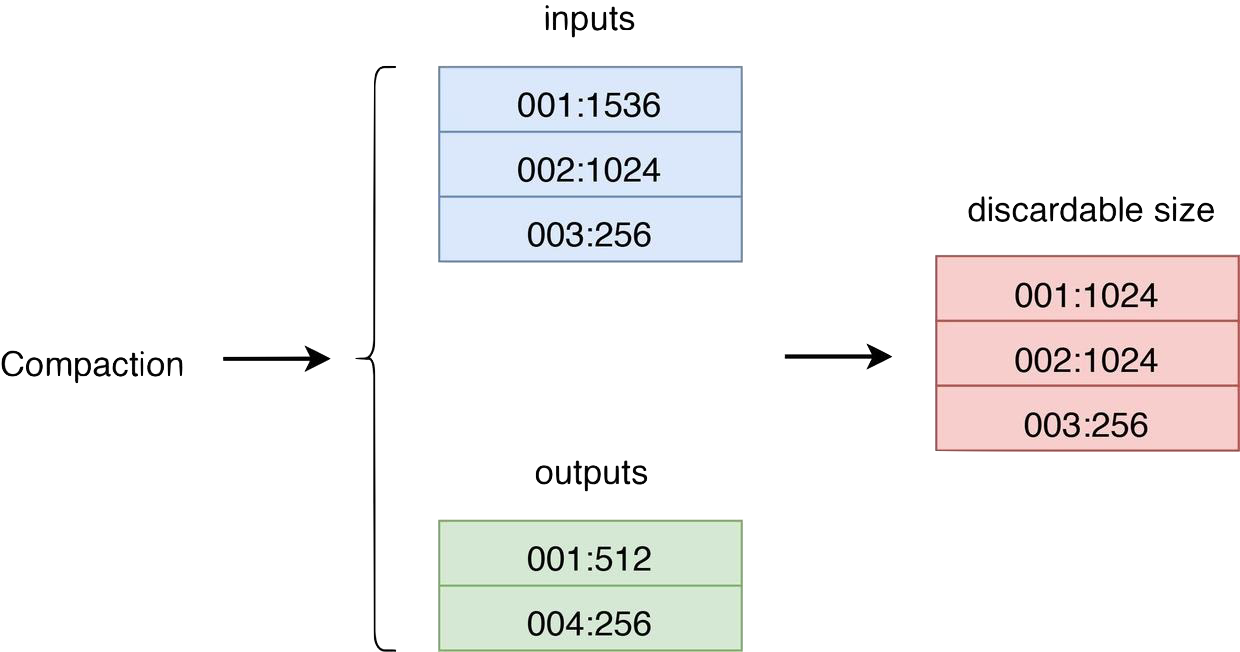
- inputs は、圧縮に参加するすべての SST の BLOB ファイル サイズのプロパティを表します。
- 出力は、圧縮で生成されたすべての SST の BLOB ファイル サイズのプロパティを表します。
- 破棄可能サイズは、入力と出力に基づいて計算された、各BLOBファイルごとに破棄されるファイルのサイズです。最初の列はBLOBファイルのIDです。2番目の列は破棄されるファイルのサイズです。
Titanは、有効なBLOBファイルごとに、破棄可能サイズ変数をメモリ内に保持します。圧縮が行われるたびに、対応するBLOBファイルについてこの変数が累積されます。GCが開始されるたびに、破棄可能サイズが最も大きいBLOBファイルがGCの候補ファイルとして選択されます。書き込み増幅を抑えるため、一定レベルのスペース増幅が許容されます。つまり、破棄可能ファイルのサイズが特定の割合に達した場合にのみ、BLOBファイルでGCが開始されます。
Titan は、選択された BLOB ファイルについて、各値に対応するキーの BLOB インデックスが存在するか、更新されているかを確認し、その値が古くなっているかどうかを判断します。値が古くない場合、Titan は値を新しい BLOB ファイルにマージしてソートし、WriteCallback または MergeOperator を使用して更新された BLOB インデックスを SST に書き込みます。次に、Titan は RocksDB の最新のシーケンス番号を記録し、最も古いスナップショットのシーケンスが記録されたシーケンス番号を超えるまで、古い BLOB ファイルを削除しません。これは、BLOB インデックスが SST に書き戻された後も、以前のスナップショットを介して古い BLOB インデックスにアクセスできるためです。したがって、GC が対応する BLOB ファイルを安全に削除する前に、スナップショットが古い BLOB インデックスにアクセスしないようにする必要があります。
レベルマージ
レベルマージはTitanに新たに導入されたアルゴリズムです。レベルマージの実装原理に基づき、TitanはSSTファイルに対応するBLOBファイルをマージして書き換え、LSMツリーで圧縮処理を実行しながら新しいBLOBファイルを生成します。以下の図は、その一般的なプロセスを示しています。
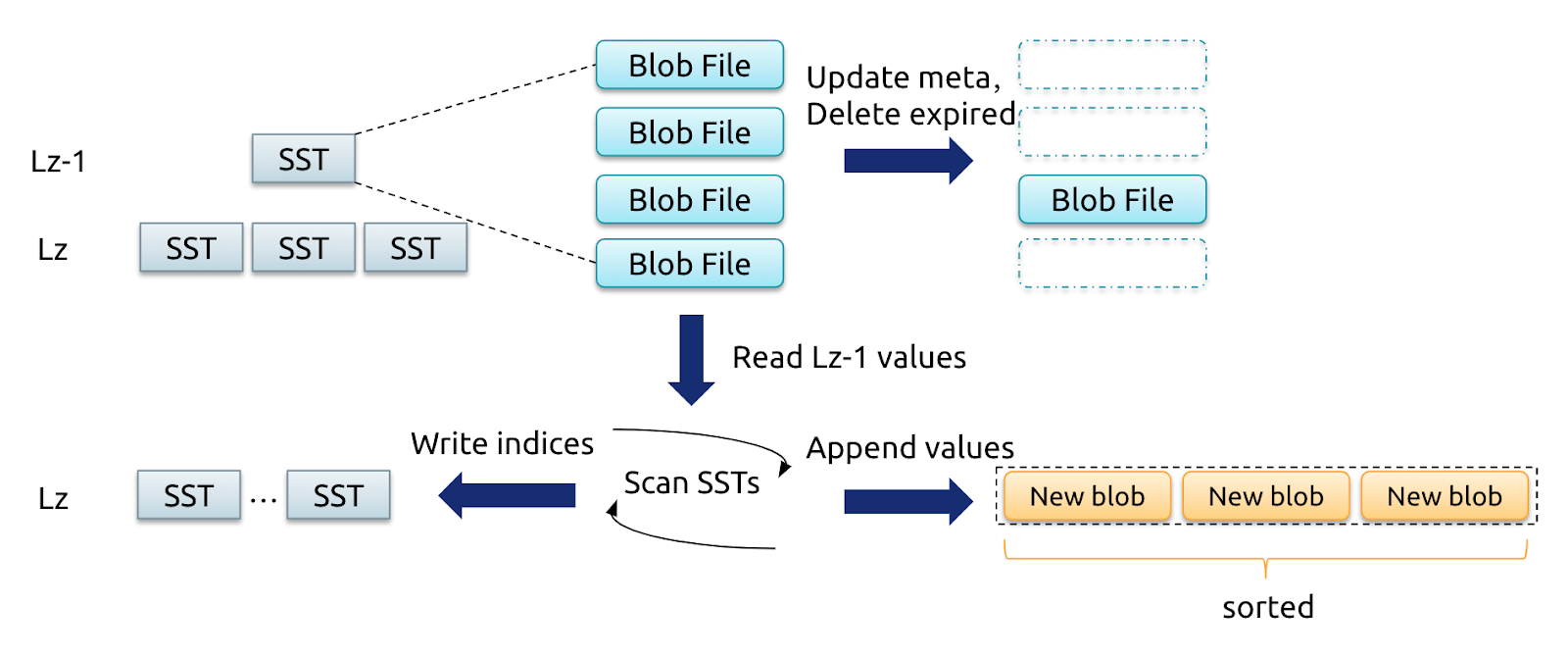
レベルz-1およびレベルzのSSTに対してコンパクションを実行すると、Titanはキーと値のペアを順番に読み書きします。次に、選択されたBLOBファイルの値を新しいBLOBファイルに順番に書き込み、新しいSSTが生成されるとキーのBLOBインデックスを更新します。コンパクションで削除されたキーについては、対応する値は新しいBLOBファイルに書き込まれません。これはGCと同様に機能します。
通常のGCと比較して、レベルマージアプローチは、LSMツリーで圧縮が行われている間にBLOB GCを完了します。これにより、TitanはLSMツリー内のBLOBインデックスの状態を確認したり、新しいBLOBインデックスをLSMツリーに書き込んだりする必要がなくなります。これにより、GCがフォアグラウンド操作に与える影響が軽減されます。BLOBファイルが繰り返し書き換えられるため、ファイル間の重複が少なくなり、システム全体の秩序が向上し、スキャンのパフォーマンスが向上します。
ただし、階層化コンパクションと同様にBLOBファイルを階層化すると、書き込み増幅が発生します。LSMツリー内のデータの99%は最下位2レベルに格納されているため、TitanはLSMツリーの最下位2レベルにのみコンパクションされたデータに対応するBLOBファイルに対してレベルマージ操作を実行します。
範囲結合
レンジマージは、レベルマージに基づくGCの最適化されたアプローチです。ただし、以下の状況では、LSMツリーの最下位レベルの順序が悪くなる可能性があります。
level_compaction_dynamic_level_bytes有効にすると、LSM ツリーの各レベルのデータ量が動的に増加し、最下位レベルのソートされた実行が増加し続けます。- 特定の範囲のデータが頻繁に圧縮され、その範囲内でソートされた実行が多数発生します。

そのため、ソートされた実行回数を一定レベル以下に抑えるには、Range Merge操作が必要です。OnCompactionCompleteの実行時に、Titanは範囲内のソートされた実行回数をカウントします。回数が多い場合、Titanは対応するBLOBファイルをToMergeとしてマークし、次回のコンパクションで書き換えます。
スケールアウトとスケールイン
後方互換性のため、スケーリング中もTiKVスナップショットはRocksDB形式のままです。スケーリングされたノードはすべてRocksDBから取得されるため、従来のTiKVノードよりも高い圧縮率、より小さいストアサイズ、コンパクション時の比較的大きな書き込み増幅など、RocksDBの特性を引き継いでいます。これらのRocksDB形式のSSTファイルは、コンパクション後に徐々にTitan形式に変換されます。
min-blob-sizeがパフォーマンスに与える影響
min-blob-size 、値が Titan に格納されるかどうかを決定します。値がmin-blob-size以上の場合、Titan に格納されます。それ以外の場合は、ネイティブの RocksDB 形式で格納されます。4 min-blob-size小さすぎたり大きすぎたりすると、パフォーマンスに影響します。
以下の表は、YCSBワークロードのQPSを異なるmin-blob-size値に基づいて比較したものです。各テストラウンドでは、テストデータの行幅はmin-blob-sizeに設定されており、Titanが有効な場合はデータがTitanに保存されます。
| 行幅(バイト) | Point_Get | Point_Get (タイタン) | スキャン100 | scan100(タイタン) | スキャン10000 | scan10000(タイタン) | UPDATE | UPDATE (タイタン) |
|---|---|---|---|---|---|---|---|---|
| 1KB | 139255 | 140486 | 25171 | 21854 | 533 | 175 | 17913 | 30767 |
| 2KB | 114201 | 124075 | 12466 | 11552 | 249 | 131 | 10369 | 27188 |
| 4KB | 92385 | 103811 | 7918 | 5937 | 131 | 87 | 5327 | 22653 |
| 8KB | 104380 | 130647 | 7365 | 5402 | 86.6 | 68 | 3180 | 16745 |
| 16KB | 54234 | 54600 | 4937 | 5174 | 55.4 | 58.9 | 1753 | 10120 |
| 32KB | 31035 | 31052 | 2705 | 3422 | 38 | 45.3 | 984 | 5844 |
注記:
scan100100 件のレコードをスキャンすることを意味し、scan1000010000 件のレコードをスキャンすることを意味します。
表から、行幅が16KBの場合、すべてのYCSBワークロードにおいて、TitanがRocksDBよりも優れたパフォーマンスを発揮することがわかります。ただし、 Dumplingの実行など、スキャン負荷が高い極端なシナリオでは、行幅が16KBの場合のTitanのパフォーマンスは10%低下します。したがって、ワークロードが主に書き込みとポイント読み取りである場合は、 min-blob-sizeから1KBに設定することをお勧めします。ワークロードに大量のスキャンが含まれる場合は、 min-blob-sizeから少なくとも16KBに設定することをお勧めします。