RocksDBの概要
RocksDBは、キーと値の保存と読み書き関数を提供するLSMツリーストレージエンジンです。Facebookによって開発され、LevelDBをベースにしています。ユーザーが書き込んだキーと値のペアは、まずWrite Ahead Log(WAL)に挿入され、次にメモリ内のSkipList( MemTableと呼ばれるデータ構造)に書き込まれます。LSMツリーエンジンは、ランダムな変更(挿入)をWALファイルへのシーケンシャルな書き込みに変換するため、Bツリーエンジンよりも優れた書き込みスループットを提供します。
メモリ内のデータが一定サイズに達すると、RocksDBはその内容をディスク上のソート文字列テーブル(SST)ファイルにフラッシュします。SSTファイルは複数のレベル(デフォルトでは最大6レベル)で構成されています。あるレベルの合計サイズがしきい値に達すると、RocksDBはSSTファイルの一部を選択し、次のレベルにマージします。後続の各レベルは前のレベルの10倍の大きさになるため、データの90%が最終レイヤーに保存されます。
RocksDBでは、複数のカラムファミリ(CF)を作成できます。各CFはそれぞれ独自のSkipListファイルとSSTファイルを持ち、同じWALファイルを共有します。これにより、アプリケーションの特性に応じて、異なるCFに異なる設定を適用できます。これにより、WALへの同時書き込み回数が増加することはありません。
TiKVアーキテクチャ
TiKV のアーキテクチャは次のようになります。
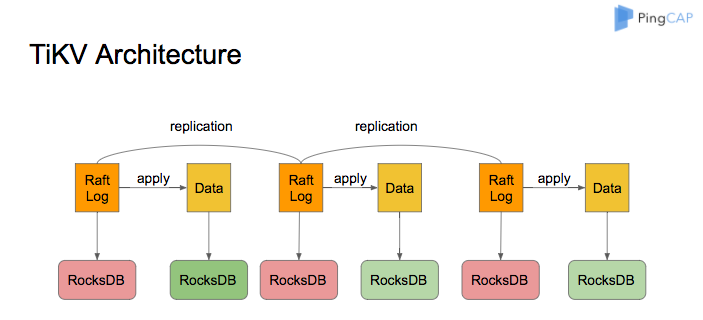
TiKVのストレージエンジンであるRocksDBは、 Raftログとユーザーデータの保存に使用されます。TiKVノード内のすべてのデータは、2つのRocksDBインスタンスを共有します。1つはRaftログ用(多くの場合raftdbと呼ばれます)、もう1つはユーザーデータとMVCCメタデータ用(多くの場合kvdbと呼ばれます)です。kvdbには、raft、lock、default、writeの4つのCFがあります。
- raft CF: 各リージョンのメタデータを保存します。非常に小さなスペースしか占有しないため、ユーザーは気にする必要はありません。
- ロックCF:悲観的トランザクションの悲観的ロックと、分散トランザクションの事前書き込みロックを保存します。トランザクションがコミットされると、ロックCF内の対応するデータは速やかに削除されます。そのため、ロックCFのデータサイズは通常非常に小さく(1GB未満)、増加した場合、大量のトランザクションがコミット待ち状態にあることを意味し、システムにバグや障害が発生している可能性があります。
- 書き込みCF: ユーザーが実際に書き込んだデータとMVCCメタデータ(データが属するトランザクションの開始タイムスタンプとコミットタイムスタンプ)を保存します。ユーザーがデータ行を書き込む際、データ長が255バイト以下の場合は書き込みCFに保存されます。それ以外の場合は、デフォルトCFに保存されます。TiDBでは、非一意インデックスに保存される値は空で、一意インデックスに保存される値は主キーインデックスであるため、セカンダリインデックスは書き込みCFの領域のみを占有します。
- デフォルト CF: 255 バイトを超えるデータを保存します。
RocksDB のメモリ使用量
読み取りパフォーマンスを向上させ、ディスクへの読み取り操作を削減するために、RocksDBはディスクに保存されているファイルを一定のサイズ(デフォルトは32 KiB)に基づいてブロックに分割します。ブロックを読み取る際、まずメモリ内のBlockCacheにデータが既に存在するかどうかを確認します。存在する場合、ディスクにアクセスすることなく、メモリから直接データを読み取ることができます。
BlockCacheは、LRUアルゴリズムに従って最も最近使用されていないデータを破棄します。デフォルトでは、TiKVはシステムメモリの45%をBlockCacheに割り当てます。ユーザーはstorage.block-cache.capacity設定を適切な値に変更することもできます。ただし、システムメモリ全体の60%を超えることは推奨されません。
RocksDBに書き込まれるデータは、まずMemTableに書き込まれます。MemTableのサイズが128MBを超えると、新しいMemTableに切り替わります。TiKVには2つのRocksDBインスタンスがあり、合計4つのCFがあります。各CFのMemTableのサイズ制限は128MBです。同時に存在できるMemTableは最大5つです。それ以上の場合、フォアグラウンド書き込みはブロックされます。この部分が占有するメモリは最大2.5GB(4 x 5 x 128MB)です。メモリ消費量が少なくなるため、この制限を変更することは推奨されません。
RocksDB のスペース使用量
- マルチバージョン:RocksDBはLSMツリー構造のキーバリューストレージエンジンであるため、 MemTableのデータはまずL0にフラッシュされます。ファイルは生成順に並べられるため、L0ではSSTの範囲が重複する可能性があります。その結果、同じキーがL0で複数のバージョンを持つ場合があります。ファイルがL0からL1にマージされると、一定サイズ(デフォルトは8MB)の複数のファイルに分割されます。同じレベルの各ファイルのキー範囲は互いに重複しないため、L1以降のレベルでは各キーに対して1つのバージョンのみとなります。
- スペース増幅:各レベルのファイルの合計サイズは前のレベルのx倍(デフォルトは10)であるため、データの90%が最終レベルに保存されます。これは、RocksDBのスペース増幅が1.11を超えないことを意味します(L0はデータ量が少ないため無視できます)。
- TiKVの領域拡張:TiKVは独自のMVCC戦略を採用しています。ユーザーがキーを書き込むと、RocksDBに書き込まれる実際のデータはキー + commit_tsです。つまり、更新と削除によって新しいキーもRocksDBに書き込まれます。TiKVは一定間隔で古いバージョンのデータを削除します(RocksDBのDeleteインターフェース経由)。そのため、ユーザーがTiKVに保存するデータの実際の領域は、1.11に過去10分間に書き込まれたデータを加えたものと考えられます(TiKVが古いデータを速やかに削除すると仮定)。
RocksDB のバックグラウンド スレッドと圧縮
RocksDBでは、 MemTableをSSTファイルに変換したり、様々なレベルでSSTファイルをマージしたりする操作は、バックグラウンドスレッドプールで実行されます。バックグラウンドスレッドプールのデフォルトサイズは8です。マシンのCPU数が8以下の場合、バックグラウンドスレッドプールのデフォルトサイズはCPU数から1を引いたサイズになります。
通常、この設定を変更する必要はありません。マシンに複数のTiKVインスタンスを展開している場合、またはマシンの読み取り負荷が比較的高く書き込み負荷が低い場合は、必要に応じてrocksdb/max-background-jobs ~3または4を調整してください。
書き込み停止
RocksDBのL0は他のレベルとは異なります。L0のSSTは生成順に並べられます。SST間のキー範囲は重複する可能性があります。そのため、クエリを実行する際には、L0内の各SSTを順番にクエリする必要があります。クエリのパフォーマンスに影響を与えないように、L0にファイル数が多すぎる場合はWriteStallがトリガーされ、書き込みがブロックされます。
書き込み遅延が急激に増加した場合は、まずGrafana RocksDB KVパネルのWriteStall Reasonメトリックを確認してください。L0ファイルの数が多すぎることがWriteStallの原因である場合は、以下の設定を64に調整してください。
rocksdb.defaultcf.level0-slowdown-writes-trigger
rocksdb.writecf.level0-slowdown-writes-trigger
rocksdb.lockcf.level0-slowdown-writes-trigger
rocksdb.defaultcf.level0-stop-writes-trigger
rocksdb.writecf.level0-stop-writes-trigger
rocksdb.lockcf.level0-stop-writes-trigger