TiDB 分散実行フレームワーク (DXF)
注記:
この機能は、クラスターTiDB CloudスターターおよびTiDB Cloudエッセンシャルでは利用できません。
TiDBは、優れたスケーラビリティと弾力性を備えたコンピューティングとストレージの分離アーキテクチャを採用しています。v7.1.0以降、TiDBは分散アーキテクチャのリソースの利点をさらに活用するために、分散実行フレームワーク(DXF)を導入しました。DXFの目標は、タスクの統一されたスケジューリングと分散実行を実装し、全体タスクと個別タスクの両方に対して統一されたリソース管理機能を提供することで、ユーザーのリソース利用に対する期待をより適切に満たすことです。
このドキュメントでは、DXF の使用例、制限事項、使用方法、実装原則について説明します。
ユースケース
データベース管理システムでは、コアとなるトランザクション処理(TP)と分析処理(AP)のワークロードに加えて、DDL操作、 IMPORT INTO ANALYZEバックアップ/リストアといった重要なタスクが存在します。これらのタスクは、データベースオブジェクト(テーブル)内の大量のデータを処理する必要があるため、通常TTL次のような特性を持ちます。
- スキーマまたはデータベース オブジェクト (テーブル) 内のすべてのデータを処理する必要があります。
- 定期的に実行する必要があるかもしれませんが、頻度は低くなります。
- リソースが適切に制御されていない場合、TP および AP タスクに影響を与え、データベース サービスの品質が低下する可能性があります。
DXF を有効にすると上記の問題が解決され、次の 3 つの利点があります。
- このフレームワークは、高いスケーラビリティ、高い可用性、および高いパフォーマンスを実現する統合された機能を提供します。
- DXF はタスクの分散実行をサポートしており、TiDB クラスター全体の利用可能なコンピューティング リソースを柔軟にスケジュールできるため、TiDB クラスター内のコンピューティング リソースをより有効に活用できます。
- DXF は、全体的タスクと個々のタスクの両方に対して、統合されたリソースの使用および管理機能を提供します。
現在、DXF はADD INDEXとIMPORT INTOステートメントの分散実行をサポートしています。
ADD INDEXはインデックスを作成するために使用されるDDL文です。例:ALTER TABLE t1 ADD INDEX idx1(c1); CREATE INDEX idx1 ON table t1(c1);IMPORT INTOは、CSV、SQL、Parquet などの形式のデータを空のテーブルにインポートするために使用されます。
制限
DXF では、同時にスケジュールできるのは最大 16 個のタスク ( ADD INDEXタスクとIMPORT INTOタスクを含む) のみです。
前提条件
DXF を使用してADD INDEXタスクを実行する前に、 高速オンラインDDLモードを有効にする必要があります。
高速オンライン DDL に関連する次のシステム変数を調整します。
tidb_ddl_enable_fast_reorg: 高速オンラインDDLモードを有効にするために使用されます。TiDB v6.5.0以降ではデフォルトで有効になっています。tidb_ddl_disk_quota: 高速オンライン DDL モードで使用できるローカル ディスクの最大クォータを制御するために使用されます。
高速オンライン DDL に関連する次の構成項目を調整します。
temp-dir: 高速オンライン DDL モードで使用できるローカル ディスク パスを指定します。
注記:
TiDB
temp-dirディレクトリ用に少なくとも 100 GiB の空き領域を用意することをお勧めします。
使用法
DXFを有効にするには、
tidb_enable_dist_taskの値をONに設定します。v8.1.0以降では、この変数はデフォルトで有効になっています。v8.1.0以降のバージョンで新しく作成されたクラスターでは、この手順をスキップできます。SET GLOBAL tidb_enable_dist_task = ON;DXFタスクの実行中、フレームワークでサポートされているステートメント(
ADD INDEXやIMPORT INTOなど)が分散的に実行されます。すべてのTiDBノードはデフォルトでDXFタスクを実行します。一般に、DDL タスクの分散実行に影響を与える可能性のある次のシステム変数については、デフォルト値を使用することをお勧めします。
tidb_ddl_reorg_worker_cnt: デフォルト値4を使用します。推奨される最大値は16です。tidb_ddl_reorg_prioritytidb_ddl_error_count_limittidb_ddl_reorg_batch_size: デフォルト値を使用します。推奨される最大値は1024です。
タスクのスケジュール
デフォルトでは、DXFはすべてのTiDBノードを分散タスクの実行対象としてスケジュールします。v7.4.0以降、TiDBセルフマネージドクラスターでは、 tidb_service_scope設定することで、DXFが分散タスクの実行対象としてスケジュールするTiDBノードを制御できます。
バージョンv7.4.0からv8.0.0までの場合、
tidb_service_scopeのオプション値は''またはbackgroundです。現在のクラスターにtidb_service_scope = 'background'のTiDBノードがある場合、DXFはこれらのノードにタスクの実行をスケジュールします。障害または通常のスケールインにより、現在のクラスターにtidb_service_scope = 'background'TiDBノードがない場合、DXFはtidb_service_scope = ''のノードにタスクの実行をスケジュールします。v8.1.0以降では、
tidb_service_scope任意の有効な値に設定できます。分散タスクが送信されると、タスクは現在接続されているTiDBノードのtidb_service_scope値にバインドされ、DXFは同じtidb_service_scope値を持つTiDBノードにのみタスクの実行をスケジュールします。ただし、以前のバージョンとの設定互換性を保つため、分散タスクがtidb_service_scope = ''ノードに送信され、現在のクラスターにtidb_service_scope = 'background'のTiDBノードがある場合、DXFはtidb_service_scope = 'background'のTiDBノードにタスクの実行をスケジュールします。
v8.1.0以降、タスク実行中に新しいノードが追加された場合、DXFは前述のルールに基づいて、新しいノードにタスクを実行するかどうかをスケジュールするかどうかを決定します。新しく追加されたノードにタスクを実行させたくない場合は、事前にそれらのノードに異なるtidb_service_scope設定することをお勧めします。
注記:
- バージョンv7.4.0からv8.0.0まで、複数のTiDBノードを持つクラスターでは、2つ以上のTiDBノードで
tidb_service_scopeからbackground設定することを強くお勧めします。この変数を1つのTiDBノードにのみ設定した場合、そのノードが再起動または障害を起こした場合、タスクはtidb_service_scope = ''が設定されているTiDBノードに再スケジュールされ、これらのTiDBノードで実行されているアプリケーションに影響を及ぼします。- 分散タスクの実行中、
tidb_service_scope構成への変更は現在のタスクには適用されませんが、次のタスクからは適用されます。
実施原則
DXF のアーキテクチャは次のとおりです。
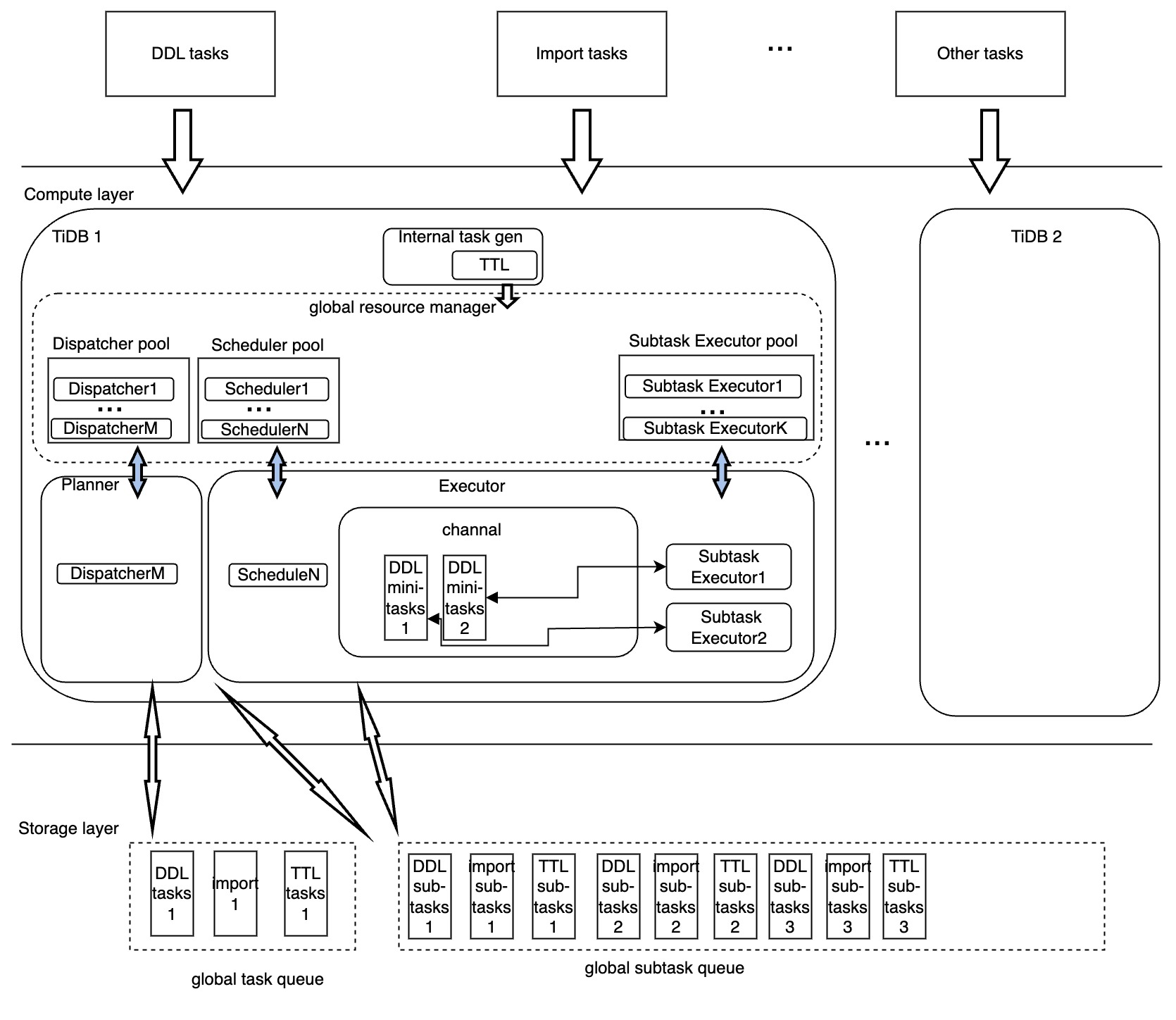
上の図に示すように、DXF でのタスクの実行は主に次のモジュールによって処理されます。
- ディスパッチャ: 各タスクの分散実行プランを生成し、実行プロセスを管理し、タスクの状態を変換し、実行時のタスク情報を収集してフィードバックします。
- スケジューラ: TiDB ノード間で分散タスクの実行を複製し、タスク実行の効率を向上させます。
- サブタスクエグゼキュータ:分散サブタスクの実際の実行者。また、サブタスクエグゼキュータはサブタスクの実行状況をスケジューラに返し、スケジューラはサブタスクの実行状況を一元的に更新します。
- リソース プール: 上記のモジュールのコンピューティング リソースをプールすることにより、リソースの使用状況と管理を定量化する基礎を提供します。