TiFlash Pipeline Execution Model
本文介绍 TiFlash 的 pipeline 执行模型。
从 v7.2.0 版本开始,TiFlash 支持一种新的执行模型,即 pipeline 执行模型。
- 对于 v7.2.0 和 v7.3.0 版本:pipeline 执行模型处于实验阶段,由
tidb_enable_tiflash_pipeline_model控制。 - 对于 v7.4.0 及之后的版本:pipeline 执行模型正式发布。它是 TiFlash 的一个内部特性,与 TiFlash 资源控制紧密集成。当你启用 TiFlash 资源控制时,pipeline 执行模型会自动启用。关于如何使用 TiFlash 资源控制的详细信息,请参考 Use Resource Control to Achieve Resource Group Limitation and Flow Control。此外,从 v7.4.0 开始,系统变量
tidb_enable_tiflash_pipeline_model被废弃。
受到论文 Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age 的启发,TiFlash 的 pipeline 执行模型提供了一种细粒度的任务调度模型,这与传统的线程调度模型不同。它减少了操作系统线程的应用和调度开销,并提供了细粒度的调度机制。
设计与实现
原始的 TiFlash 流式模型是一种线程调度执行模型。每个查询会独立申请若干线程以协同执行。
该线程调度模型存在以下两个缺陷:
- 在高并发场景下,过多的线程导致大量的上下文切换,从而带来较高的线程调度成本。
- 线程调度模型无法准确衡量查询的资源使用情况,也无法实现细粒度的资源控制。
新的 pipeline 执行模型进行了以下优化:
- 将查询划分为多个 pipeline,依次执行。在每个 pipeline 中,尽可能将数据块保留在缓存中,以实现更好的时间局部性,提升整体执行效率。
- 为了摆脱操作系统原生的线程调度模型,采用更细粒度的调度机制,每个 pipeline 被实例化为多个任务,使用任务调度模型。同时,采用固定线程池以减少操作系统线程调度的开销。
pipeline 执行模型的架构如下:
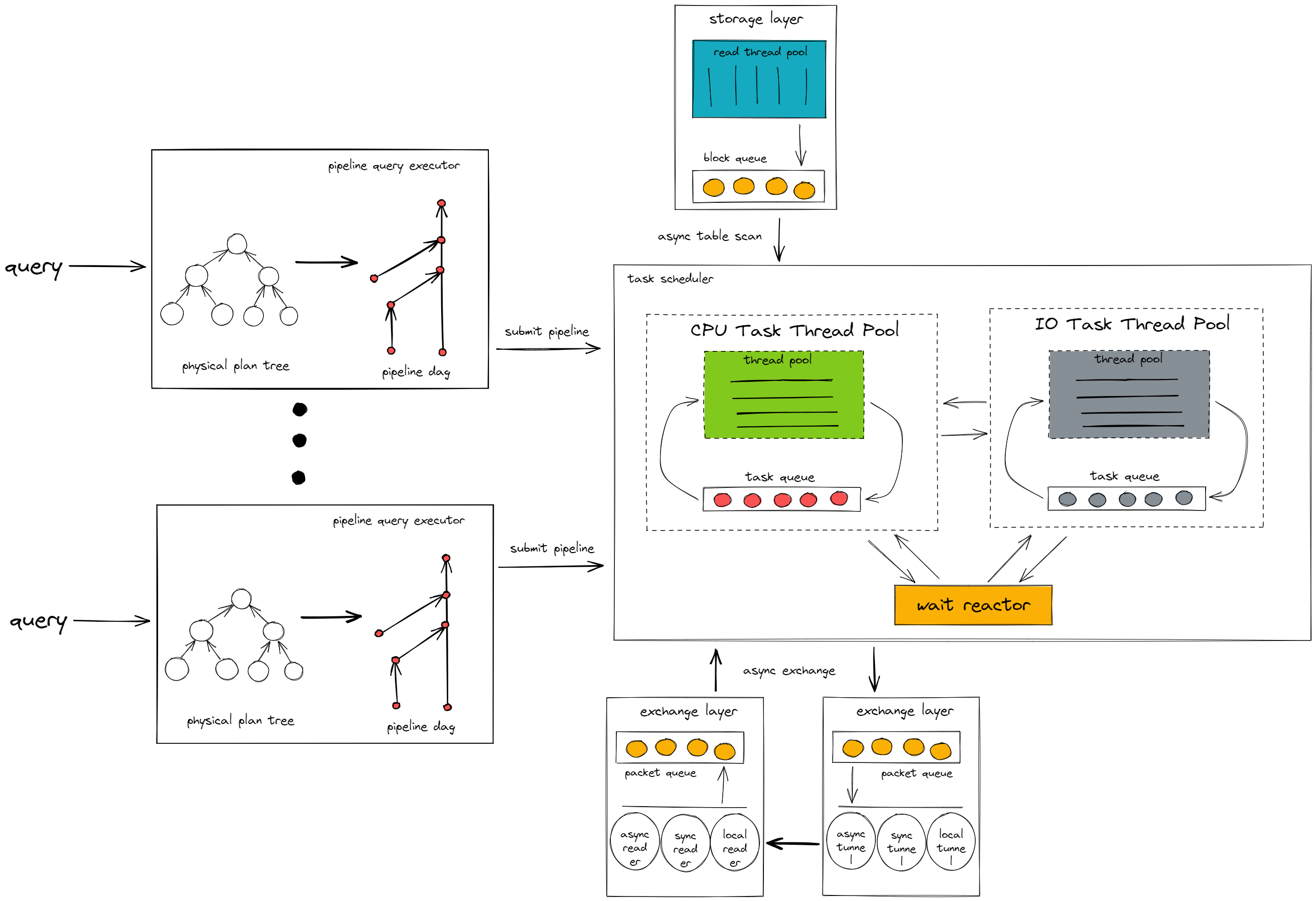
如上图所示,pipeline 执行模型由两个主要组件组成:pipeline 查询执行器和任务调度器。
pipeline 查询执行器
pipeline 查询执行器将来自 TiDB 节点的查询请求转换为一个 pipeline 有向无环图(DAG)。
它会在查询中找到 pipeline breaker 操作符,并根据 pipeline breaker 将查询拆分成多个 pipeline,然后根据 pipeline 之间的依赖关系,将它们组装成一个 DAG。
pipeline breaker 是具有暂停/阻塞逻辑的操作符。这类操作符会持续接收来自上游操作符的数据块,直到全部数据块接收完毕,然后将处理结果返回给下游操作符。这类操作符会中断数据处理管道,因此称为 pipeline breaker。其中一个 pipeline breaker 是 Aggregation 操作符,它会在计算哈希表中的数据之前,将上游操作符的所有数据写入哈希表,然后再进行数据计算并将结果返回给下游操作符。
查询转换为 pipeline DAG 后,pipeline 查询执行器会根据依赖关系依次执行每个 pipeline。每个 pipeline 会根据查询的并发度实例化为多个任务,并提交给任务调度器执行。
任务调度器
任务调度器负责执行由 pipeline 查询执行器提交的任务。任务在调度器中根据不同的执行逻辑在不同组件之间动态切换。
CPU task thread pool
执行任务中的 CPU 密集型计算逻辑,例如数据过滤和函数计算。
IO task thread pool
执行任务中的 IO 密集型计算逻辑,例如将中间结果写入磁盘。
Wait reactor
执行任务中的等待逻辑,例如等待网络层将数据包传输到计算层。