TiCDC 基本监控指标
从 v7.0.0 版本开始,使用 TiUP 一键部署 Grafana 时,会自动在 Grafana 监控页面新增 TiCDC Summary Dashboard。通过该监控面板,你可以快速地了解 TiCDC 服务器运行状态和同步任务的基本情况。
下图显示了 TiCDC Dashboard 的监控栏:

各监控栏说明如下:
- Server:集群中 TiCDC 节点的概要信息
- Changefeed:TiCDC 同步任务延迟和状态信息
- Dataflow:TiCDC 内部各个模块处理数据改变的各种统计信息
- Transaction Sink:下游为 MySQL 或者 TiDB 时的写延迟信息
- MQ Sink: 下游为 MQ 系统时的写延迟信息
- Cloud Storage Sink:下游为 Cloud Storage 时的写速率信息
- Redo:开启 Redo 功能时的写延迟信息
Server 监控栏
Server 监控栏示例如下:
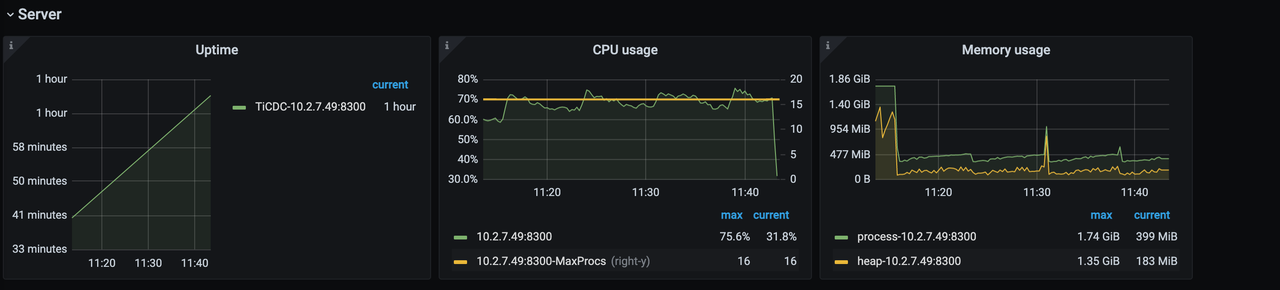
- Uptime:TiCDC 节点已经运行的时间。
- CPU usage:TiCDC 节点的 CPU 使用量。
- Memory usage:TiCDC 节点的内存使用量。
Changefeed 监控栏
Changefeed 监控栏示例如下:
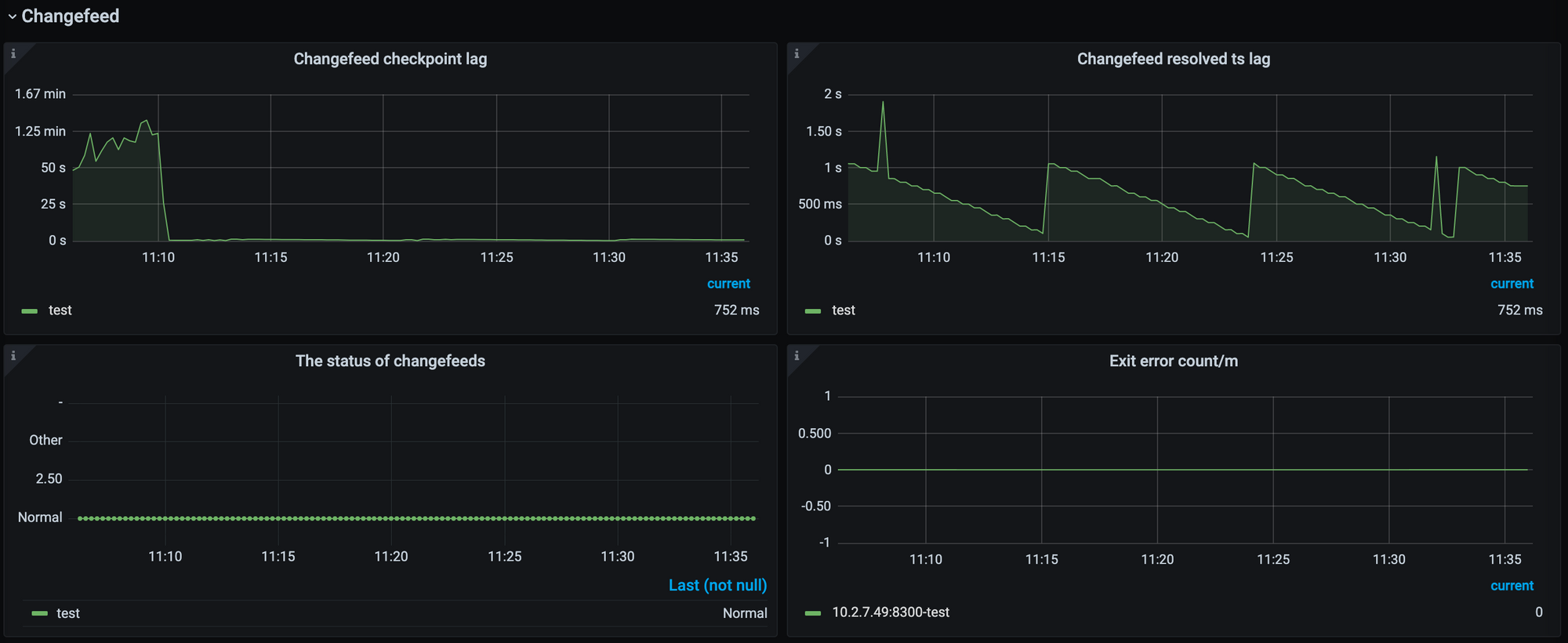
- Changefeed checkpoint lag:这个指标代表上游 TiDB 集群和下游系统之间的数据复制延迟,延迟以时间为单位。该指标反映了 Changefeed 整体的数据同步状况是否健康,通常情况下,lag 越小,说明同步任务状态越好。而当 lag 上升时,通常说明 Changefeed 的同步能力或者下游系统的消费能力无法匹配上游的写入速度。
- Changefeed resolved ts lag:这个指标代表了上游 TiDB 集群与 TiCDC 节点之间的数据延迟,延迟以时间为单位。该指标能够反映 Changefeed 拉取上游数据变更的能力,当 lag 上升时,说明 Changefeed 无法及时地拉取上游产生的数据变更。
Dataflow 监控栏

- Puller output events/s:TiCDC 节点中 Puller 模块每秒输出到 Sorter 模块的数据变更个数。该指标能够反映 TiCDC 拉取上游变更事件的速度。
- Puller output events:TiCDC 节点中 Puller 模块输出到 Sorter 模块的数据变更总数。

- Sorter output events/s:TiCDC 节点中 Sorter 模块每秒输出到 Sink 模块的数据变更个数。值得注意的是,Sorter 的数据输出速率会受到 Sink 模块的影响,因此在发现 Sorter 模块输出速率比 Puller 模块低时,不一定是因为 Sorter 模块排序速度过慢;而应该先观察 Sink 模块的相关指标,确认是否是因为 Sink 模块 Flush 数据的耗时较长,导致 Sorter 模块输出降低。
- Sorter output event:TiCDC 节点中 Sorter 模块输出到 Sink 模块的数据变更总个数。

- Mounter output events/s:TiCDC 节点中 Mounter 模块每秒解码的数据变更的个数。当上游发生的数据变更包含较多字段时,Mounter 的解码速度可能会受到影响。
- Mounter output event:TiCDC 节点中 Mounter 模块解码的数据变更的总个数。

- Sink flush rows/s:TiCDC 节点中 Sink 模块每秒往下游输出的数据变更个数。该指标反映的是同步任务向下游进行同步的速率,当 Sink flush rows/s 小于 Puller output events/s 时,同步延迟可能会上升。
- Sink flush rows:TiCDC 节点中 Sink 模块输出的数据变更的总个数。
Transaction Sink 监控栏
Transaction Sink 监控栏示意如下,该监控栏只有下游为 MySQL 或者 TiDB 时才有数据。
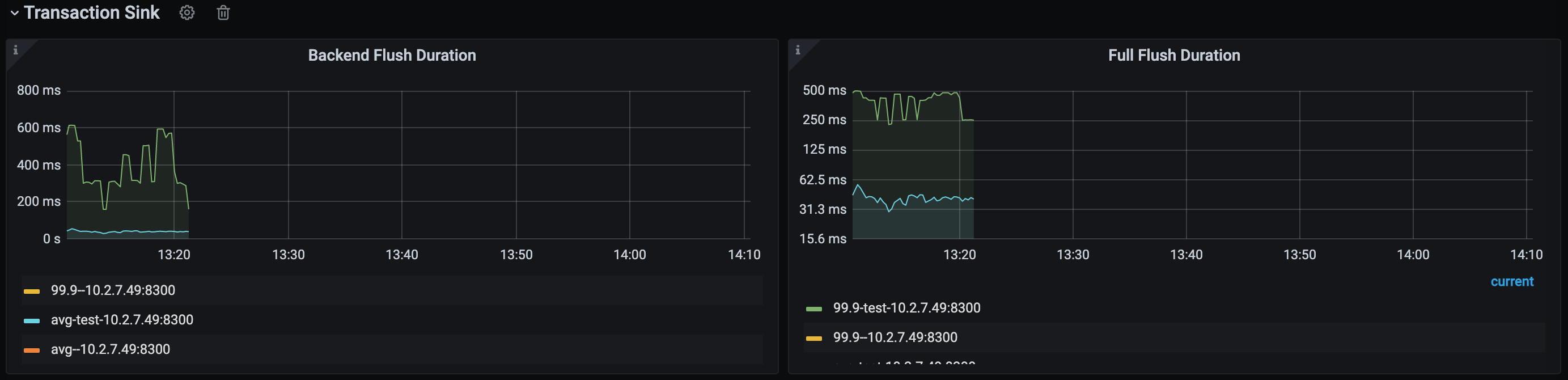
- Backend Flush Duration:TiCDC Transaction Sink 模块在向下游执行一条 SQL 语句的耗时。通过观察该指标,能够判断下游的性能是否为同步速度的瓶颈。一般来说,p999 应该维持在 500 ms 内为佳,超过该值时,同步速度可能就会受到影响,引起 Changefeed checkpoint lag 上升。
- Full Flush Duration:TiCDC 中每个事务从 Sorter 排序完成直到发送到下游之间的总耗时。用该值减去 Backend Flush Duration 的值,即可得出一个事务在被执行到下游之前的总排队时长。如果排队时长较高,可以考虑给同步任务分配更多的内存 Quota。
MQ Sink 监控栏
MQ Sink 监控栏示意如下,该监控栏只有下游为 Kafka 时才有数据。
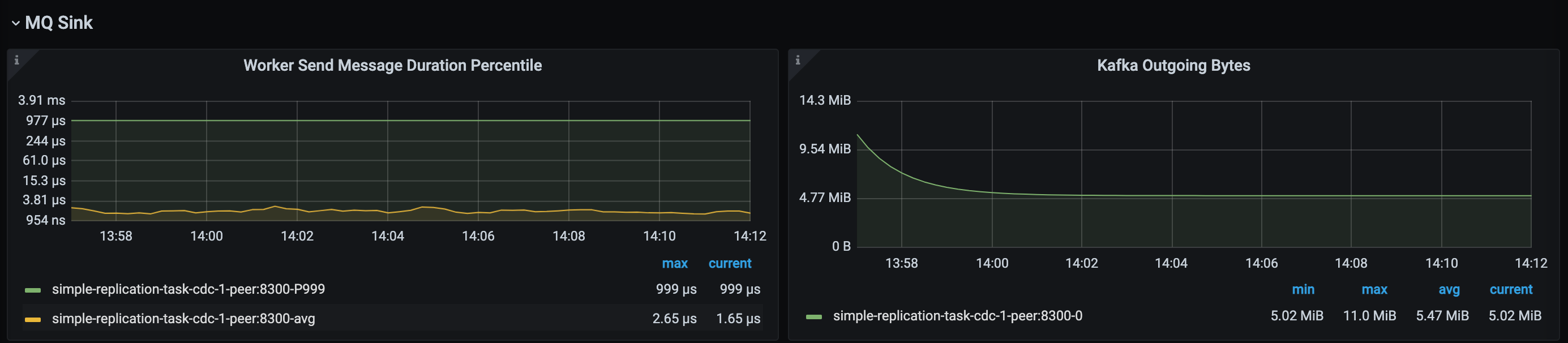
- Worker Send Message Duration Percentile:TiCDC MQ Sink 的 Worker 往下游发送数据的延迟。
- Kafka Ongoing Bytes:TiCDC MQ Sink 往下游发送数据的速率。
Cloud Storage Sink 监控栏
Cloud Storage Sink 监控栏示意如下,该监控栏只有下游为 Cloud Storage 时才有数据。
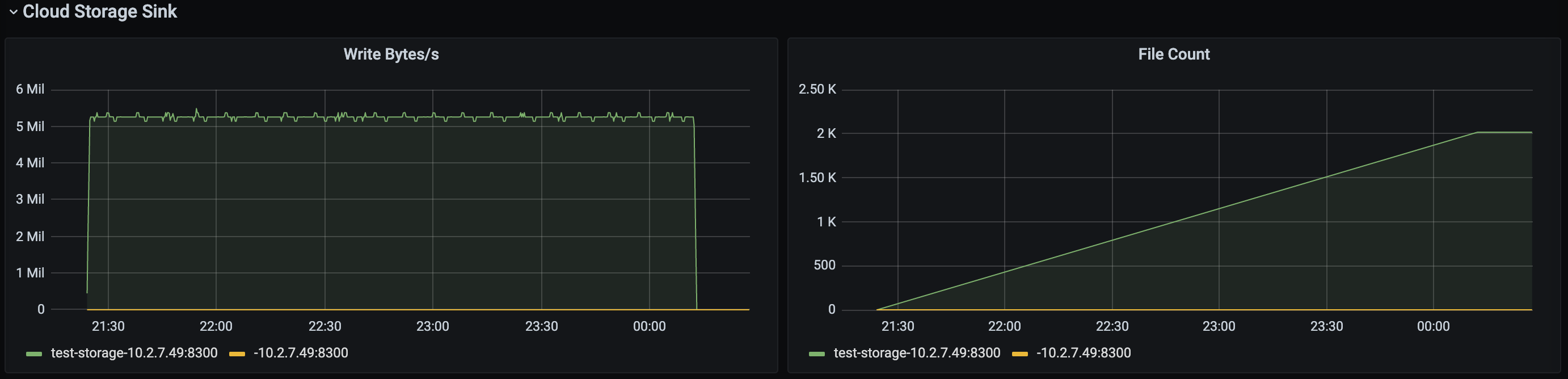
- Write Bytes/s:Cloud Storage Sink 模块往下游写数据的速率。
- File Count:Cloud Storage Sink 模块写文件的总数量。
Redo 监控栏
Redo 监控栏示意如下,该监控栏只有在开启了 Redo Log 功能时才有数据。
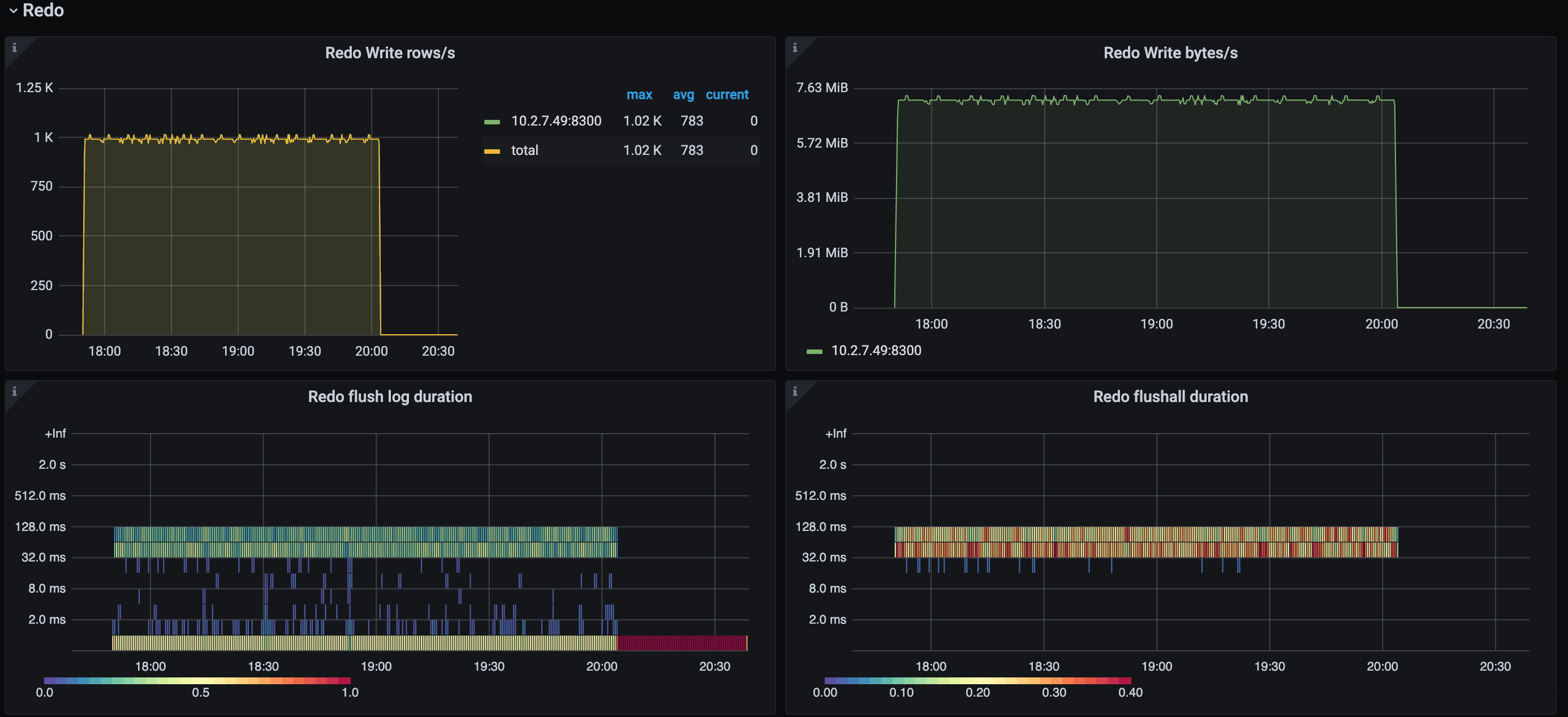
- Redo Write rows/s:Redo 模块每秒写数据的行数。当开启 Redo 功能时,如果发现同步任务的延迟上升,那么可以观察该指标是否和 Puller Output event/s 的值有较大差距。如果是,那么可能是由于 Redo 模块的写入能力不足造成延迟上升。
- Redo Write Byte/s:Redo 模块每秒写数据的速率。
- Redo flush log duration:Redo 模块往下游刷写数据的耗时。若该指标值较高,则可能是它影响了同步的速度。
- Redo flushall duration:数据变更停留在 Redo 模块中的总时长。