Storage sink 消费程序设计
本文介绍如何设计和实现一个 TiDB 数据变更的消费程序。
TiCDC 不提供消费存储服务的数据的标准实现。本文介绍一个基于 Golang 的消费示例程序,该示例程序能够读取存储服务中的数据并写入到兼容 MySQL 的下游数据库。你可以参考本文提供的数据格式和以下示例代码实现消费端。
Consumer 设计
下图是 Consumer 的整体消费流程:
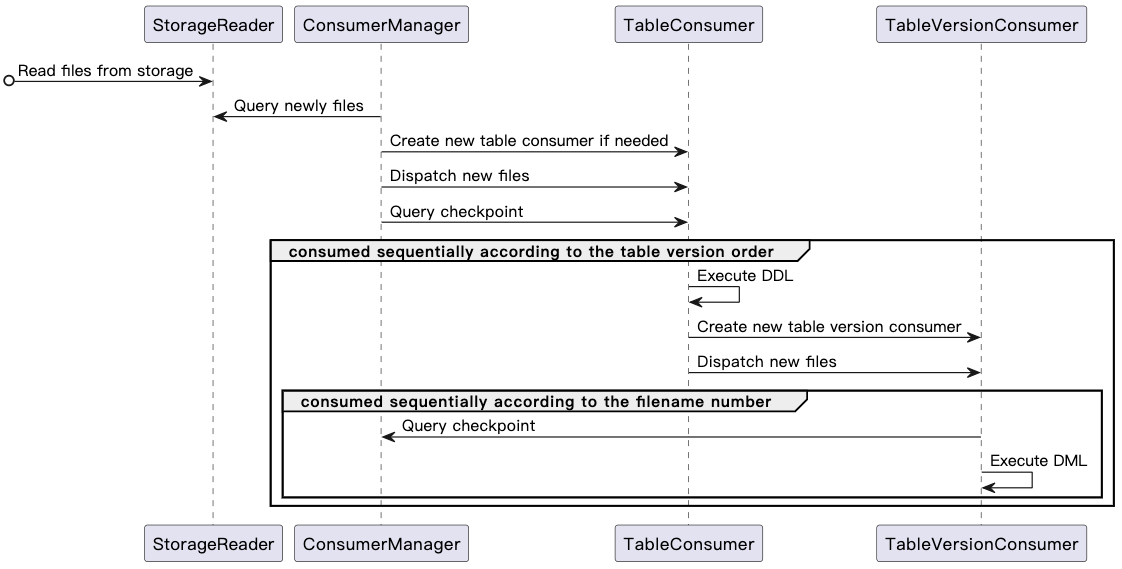
以下是 Consumer 消费流程中的组件和功能定义,及其功能注释:
type StorageReader struct {
}
// Read the files from storage
// Add newly added files and delete files that not exist in storage
func (c *StorageReader) ReadFiles() {}
// Query newly added files and the latest checkpoint from storage,one file can only be returned once
func (c *StorageReader) ExposeNewFiles() (int64, []string) {}
// ConsumerManager is responsible for assigning tasks to TableConsumer.
// Different consumers can consume data concurrently,
// but data of one table must be processed by the same TableConsumer.
type ConsumerManager struct {
// StorageCheckpoint is recorded in metadata file and it can be fetched by calling `StorageReader.ExposeNewFiles()`.
// It indicates that the data whose transaction commit time is less than this checkpoint has been stored in storage
StorageCheckpoint int64
// it indicates where the consumer has consumed
// ConsumerManager periodically collects TableConsumer.Checkpoint,
// then Checkpoint is updated to the minimum value of all TableConsumer.Checkpoint
Checkpoint int64
tableFiles[schema][table]*TableConsumer
}
// Query newly files from StorageReader
// For new created table, create a TableConsumer for the new table
// If any, send new files to the corresponding TableConsumer
func (c *ConsumerManager) Dispatch() {}
type TableConsumer struct {
// it indicates where this TableConsumer has consumed
// Its initial value is ConsumerManager.Checkpoint
// TableConsumer.Checkpoint is equal to TableVersionConsumer.Checkpoint
Checkpoint int64
schema,table string
// Must be consumed sequentially according to the table version order
verConsumers map[version int64]*TableVersionConsumer
currentVer, previousVer int64
}
// Send newly files to the corresponding TableVersionConsumer
// For any DDL, assign a TableVersionConsumer for the new table version
func (tc *TableConsumer) Dispatch() {}
// If DDL query is empty or its tableVersion is less than TableConsumer.Checkpoint,
// - ignore this DDL, and consume the data under the table version
// Otherwise,
// - execute DDL first, and then consume the data under the table version
// - But for dropped table, self recycling after drop table DDL is executed
func (tc *TableConsumer) ExecuteDDL() {}
type TableVersionConsumer struct {
// it indicates where the TableVersionConsumer has consumed
// Its initial value is TableConsumer.Checkpoint
Checkpoint int64
schema,table,version string
// For same table version, data in different partitions can be consumed concurrently
# partitionNum int64
// Must be consumed sequentially according to the data file number
fileSet map[filename string]*TableVersionConsumer
currentVersion
}
// If data commit ts is less than TableConsumer.Checkpoint
// or bigger than ConsumerManager.StorageCheckpoint,
// - ignore this data
// Otherwise,
// - process this data and write it to MySQL
func (tc *TableVersionConsumer) ExecuteDML() {}
DDL 事件的处理
举例来说,第一次遍历目录时目录内容如下:
├── metadata
└── test
├── tbl_1
│ └── 437752935075545091
│ ├── CDC000001.json
│ └── schema.json
此时,首先需要解析 schema.json 文件中的表结构信息,从中获取 DDL Query 语句,并将其分为两种情况处理:
- 如果 DDL Query 为空或者 TableVersion 小于 consumer checkpoint 则跳过该语句。
- 否则,在下游 MySQL 数据库中执行获取到的 DDL 语句。
接着再开始同步数据文件 CDC000001.json。
例如,以下的 test/tbl_1/437752935075545091/schema.json 文件中 DDL Query 不为空:
{
"Table":"test",
"Schema":"tbl_1",
"Version": 1,
"TableVersion":437752935075545091,
"Query": "create table tbl_1 (Id int primary key, LastName char(20), FirstName varchar(30), HireDate datetime, OfficeLocation Blob(20))",
"TableColumns":[
{
"ColumnName":"Id",
"ColumnType":"INT",
"ColumnNullable":"false",
"ColumnIsPk":"true"
},
{
"ColumnName":"LastName",
"ColumnType":"CHAR",
"ColumnLength":"20"
},
{
"ColumnName":"FirstName",
"ColumnType":"VARCHAR",
"ColumnLength":"30"
},
{
"ColumnName":"HireDate",
"ColumnType":"DATETIME"
},
{
"ColumnName":"OfficeLocation",
"ColumnType":"BLOB",
"ColumnLength":"20"
}
],
"TableColumnsTotal":"5"
}
当程序再次遍历目录,发现该表新增了一个版本目录。程序先消费完 test/tbl_1/437752935075545091 目录下的所有文件,然后再消费新目录下的数据。
├── metadata
└── test
├── tbl_1
│ ├── 437752935075545091
│ │ ├── CDC000001.json
│ │ └── schema.json
│ └── 437752935075546092
│ │ └── CDC000001.json
│ │ └── schema.json
消费逻辑跟上述一致,先解析 schema.json 文件中的表结构信息,从中获取 DDL Query 语句并按不同情况处理,然后同步数据文件 CDC000001.json。
DML 事件的处理
在处理完 DDL 事件后,可以在 {schema}/{table}/{table-version-separator}/ 目录下,根据具体的文件格式(CSV 或 Canal-JSON)并按照文件序号依次处理 DML 事件。
因为 TiCDC 提供 At Least Once 语义,可能出现重复发送数据的情况,所以需要在消费程序中比较数据事件的 commit ts 和 consumer checkpoint,并在 commit ts 小于 consumer checkpoint 的情况下进行去重处理。