TiDB Lightning 简介
TiDB Lightning 是用于从静态文件导入 TB 级数据到 TiDB 集群的工具,常用于 TiDB 集群的初始化数据导入。
TiDB Lightning 支持以下文件类型:
- Dumpling 生成的文件
- CSV 文件
- Amazon Aurora 生成的 Apache Parquet 文件
TiDB Lightning 支持从以下位置读取:
TiDB Lightning 整体架构
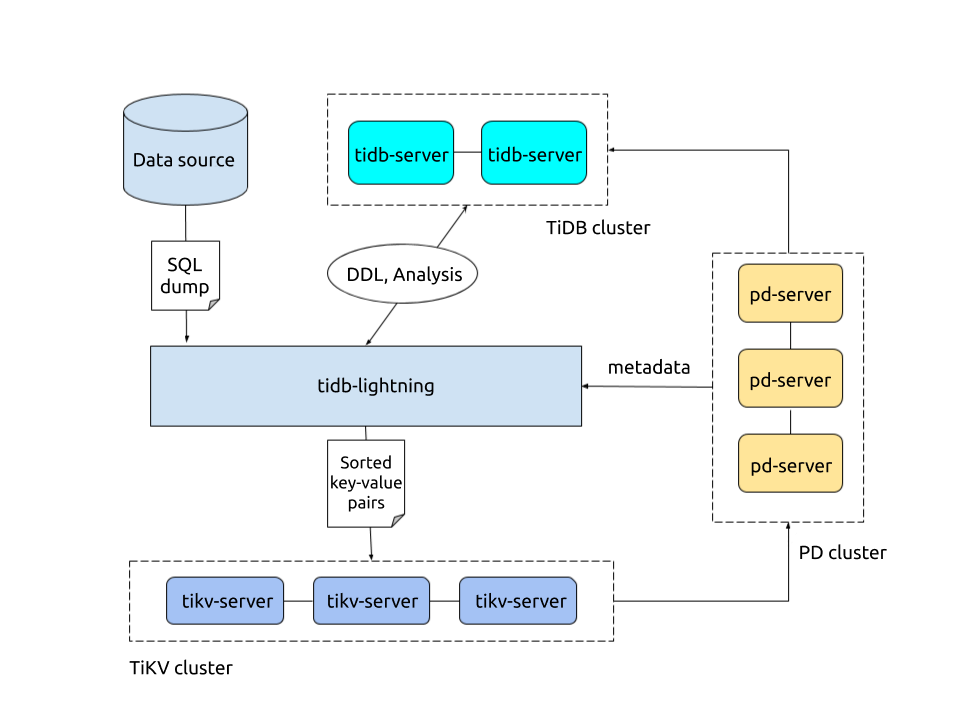
TiDB Lightning 目前支持两种导入方式,通过 backend 配置区分。不同的模式决定 TiDB Lightning 如何将数据导入到目标 TiDB 集群。
Physical Import Mode:TiDB Lightning 首先将数据编码成键值对并排序存储在本地临时目录,然后将这些键值对上传到各个 TiKV 节点,最后调用 TiKV Ingest 接口将数据插入到 TiKV 的 RocksDB 中。如果用于初始化导入,请优先考虑使用 Physical Import Mode,其拥有较高的导入速度。Physical Import Mode 对应的后端模式为
local。Logical Import Mode:TiDB Lightning 先将数据编码成 SQL,然后直接运行这些 SQL 语句进行数据导入。如果需要导入的集群为生产环境线上集群,或需要导入的目标表中已包含有数据,则应使用 Logical Import Mode。Logical Import Mode 对应的后端模式为
tidb。