Titan 介绍
Titan 是基于 RocksDB 的高性能单机 key-value 存储引擎插件。
当 value 较大(1 KB 以上或 512 B 以上)的时候,Titan 在写、更新和点读等场景下性能都优于 RocksDB。但与此同时,Titan 会占用更多硬盘空间和部分舍弃范围查询。随着 SSD 价格的降低,Titan 的优势会更加突出,让用户更容易做出选择。
核心特性
- 支持将 value 从 LSM-tree 中分离出来单独存储,以降低写放大。
- 已有 RocksDB 实例可以平滑地升级到 Titan,这意味着升级过程不需要人工干预,并且不会影响线上服务。
- 100% 兼容目前 TiKV 所使用的所有 RocksDB 的特性。
适用场景
Titan 适合在以下场景中使用:
- 前台写入量较大,RocksDB 大量触发 compaction 消耗大量 I/O 带宽或者 CPU 资源,造成 TiKV 前台读写性能较差。
- 前台写入量较大,由于 I/O 带宽瓶颈或 CPU 瓶颈的限制,RocksDB compaction 进度落后较多频繁造成 write stall。
- 前台写入量较大,RocksDB 大量触发 compaction 造成 I/O 写入量较大,影响 SSD 盘的寿命。
开启 Titan 需要考虑以下前提条件:
- Value 较大。即 value 平均大小比较大,或者数据中大 value 的数据总大小占比比较大。目前 Titan 默认 1KB 以上大小的 value 是大 value,根据实际情况 512B 以上大小的 value 也可以看作是大 value。注:由于 TiKV Raft 层的限制,写入 TiKV 的 value 大小还是无法超过 8MB 的限制,可通过
raft-entry-max-size配置项调整该限制。 - 没有范围查询或者对范围查询性能不敏感。Titan 存储数据的顺序性较差,所以相比 RocksDB 范围查询的性能较差,尤其是大范围查询。在测试中 Titan 范围查询性能相比 RocksDB 下降 40% 到数倍不等。
- 磁盘剩余空间足够,推荐为相同数据量下 RocksDB 磁盘占用的两倍。Titan 降低写放大是通过牺牲空间放大达到的。另外由于 Titan 逐个压缩 value,压缩率比 RocksDB(逐个压缩 block)要差。这两个因素一起造成 Titan 占用磁盘空间比 RocksDB 要多,这是正常现象。根据实际情况和不同的配置,Titan 磁盘空间占用可能会比 RocksDB 多一倍。
从 v7.6.0 开始,TiDB 对 Titan 性能进行了优化,并将 Titan 作为默认的存储引擎。由于 TiKV 在 Value 较小时会直接存在 RocksDB 中,因此即便是小 Value 也可以打开 Titan。
性能提升请参考 Titan 的设计与实现。
架构与实现
Titan 的基本架构如下图所示:
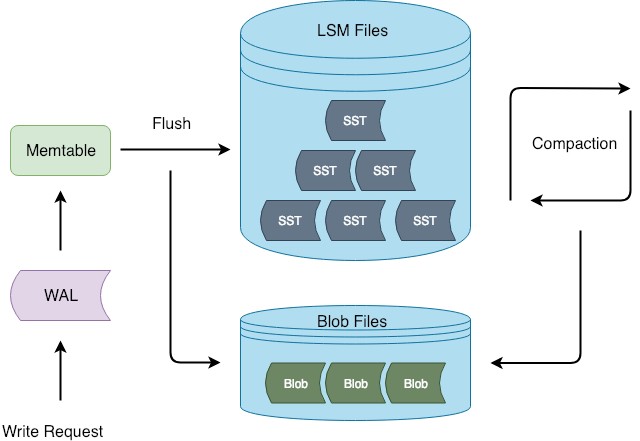
Titan 在 Flush 和 Compaction 的时候将 value 分离出 LSM-tree,这样写入流程可以和 RocksDB 保持一致,减少对 RocksDB 的侵入性改动。
BlobFile
BlobFile 是用来存放从 LSM-tree 中分离出来的 value 的文件,其格式如下图所示:
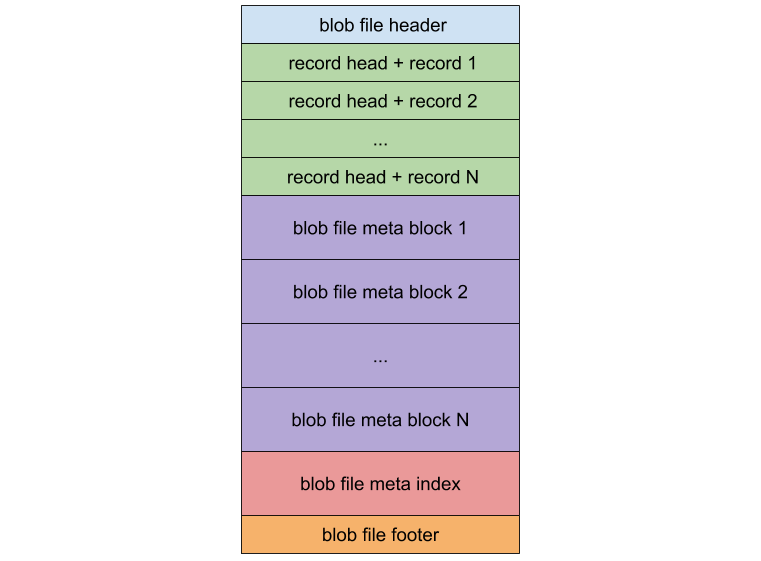
BlobFile 由 blob record 、meta block、meta index block 和 footer 组成。其中每个 blob record 用于存放一个 key-value 对;meta block 支持可扩展性,可以用来存放和 BlobFile 相关的一些属性;meta index block 用于检索 meta block。
BlobFile 的实现上有几点值得关注的地方:
- BlobFile 中的 key-value 是有序存放的,目的是在实现 iterator 的时候可以通过 prefetch 的方式提高顺序读取的性能。
- 每个 blob record 都保留了 value 对应的 user key 的拷贝,这样做的目的是在进行 GC 的时候,可以通过查询 user key 是否更新来确定对应 value 是否已经过期,但同时也带来了一定的写放大。
- BlobFile 支持 blob record 粒度的压缩,并且支持多种压缩算法,包括 Snappy、
lz4和zstd。在 v7.6.0 之前的版本,Titan 默认使用的压缩算法是lz4。v7.6.0 之后,默认使用zstd。
TitanTableBuilder
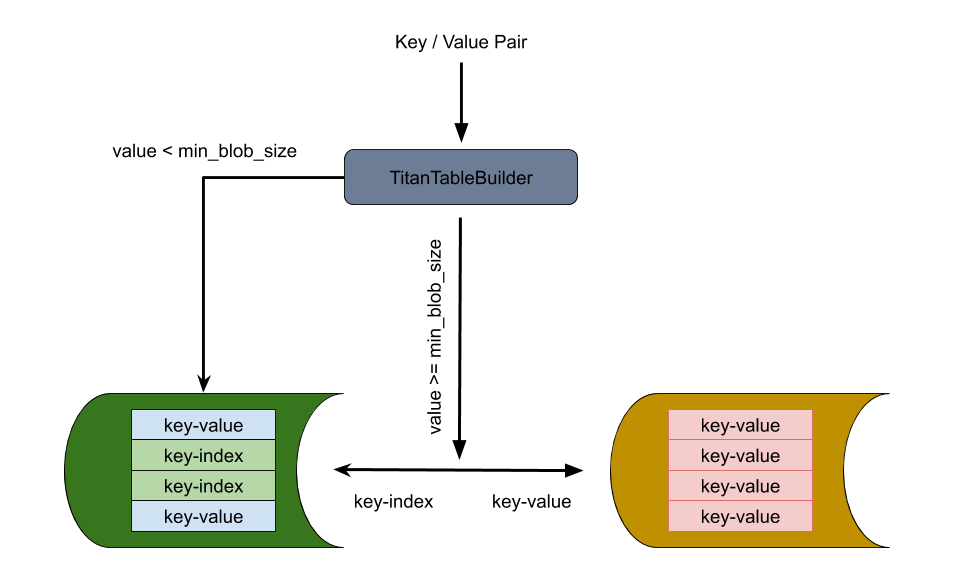
TitanTableBuilder 是实现分离 key-value 的关键,它通过判断 value size 的大小来决定是否将 value 分离到 BlobFile 中去。如果 value size 大于等于 min_blob_size 则将 value 分离到 BlobFile,并生成 index 写入 SST;如果 value size 小于 min_blob_size 则将 value 直接写入 SST。
该流程还支持将 Titan 降级回 RocksDB。在 RocksDB 做 compaction 的时候,将分离出来的 value 重新写回新生成的 SST 文件中。
Garbage Collection
Garbage Collection (GC) 的目的是回收空间。由于在 LSM-tree compaction 进行回收 key 时,储存在 blob 文件中的 value 并不会一同被删除,因此需要 GC 定期来将已经作废的 value 删除掉。在 Titan 中有两种 GC 方式可供选择:
- 定期整合重写 Blob 文件将作废的 value 剔除(传统 GC)
- 在 LSM-tree compaction 的时候同时进行 blob 文件的重写 (Level-Merge)
传统 GC
Titan 使用 RocksDB 的 TablePropertiesCollector 和 EventListener 来收集 GC 所需的统计信息。
TablePropertiesCollector
RocksDB 允许使用自定义的 TablePropertiesCollector 来搜集 SST 上的 properties 并写入到对应文件中去。Titan 通过一个自定义的 TablePropertiesCollector —— BlobFileSizeCollector 来搜集每个 SST 中有多少数据是存放在哪些 BlobFile 上的,将它收集到的 properties 命名为 BlobFileSizeProperties,它的工作流程和数据格式如下图所示:
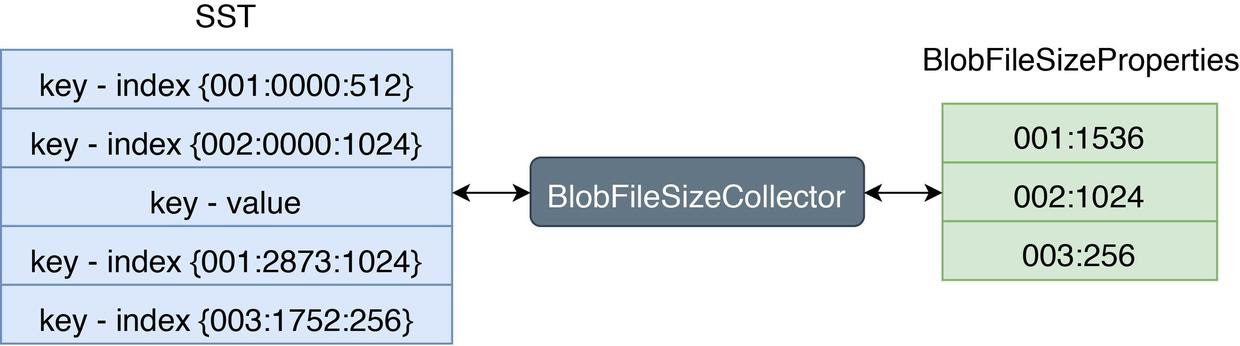
左边 SST 中 Index 的格式为:第一列代表 BlobFile 的文件 ID,第二列代表 blob record 在 BlobFile 中的 offset,第三列代表 blob record 的 size。右边 BlobFileSizeProperties 中的每一行代表一个 BlobFile 以及 SST 中有多少数据保存在这个 BlobFile 中,第一列代表 BlobFile 的文件 ID,第二列代表数据大小。
EventListener
RocksDB 是通过 Compaction 来丢弃旧版本数据以回收空间的,因此每次 Compaction 完成后 Titan 中的某些 BlobFile 中便可能有部分或全部数据过期。因此便可以通过监听 Compaction 事件来触发 GC,搜集比对 Compaction 中输入输出 SST 的 BlobFileSizeProperties 来决定挑选哪些 BlobFile 进行 GC。其流程大概如下图所示:
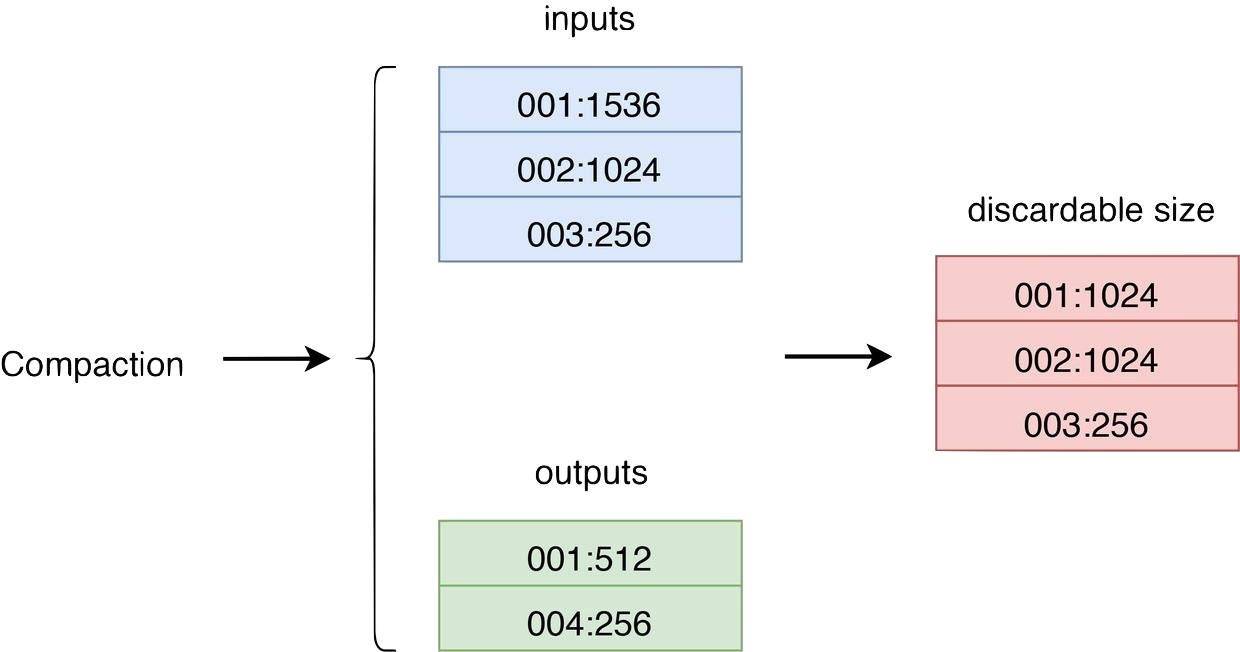
inputs 代表参与 Compaction 的所有 SST 的 BlobFileSizeProperties,outputs 代表 Compaction 生成的所有 SST 的 BlobFileSizeProperties,discardable size 是通过计算 inputs 和 outputs 得出的每个 BlobFile 被丢弃的数据大小,第一列代表 BlobFile 的文件 ID,第二列代表被丢弃的数据大小。
Titan 会为每个有效的 BlobFile 在内存中维护一个 discardable size 变量,每次 Compaction 结束之后都对相应的 BlobFile 的 discardable size 变量进行累加。注意,在每次重启后会扫描一遍所有的 SST 的 BlobFileSizeProperties 重新构建每个有效 BlobFile 的 discardable size 变量。每次 GC 开始时就可以通过挑选 discardable size 最大的几个 BlobFile 来作为候选的文件。为了减小写放大,我们可以容忍一定的空间放大,所以 Titan 只有在 BlobFile 可丢弃的数据达到一定比例之后才会对其进行 GC。
GC 的方式就是对于这些选中的 BlobFile 文件,依次通过查询其中每个 value 相应的 key 的 blob index 是否存在或者更新来确定该 value 是否作废,最终将未作废的 value 归并排序生成新的 BlobFile,并将这些 value 更新后的 blob index 通过 WriteCallback 或者 MergeOperator 的方式写回到 SST 中。在完成 GC 后,这些原来的 BlobFile 文件并不会立即被删除,Titan 会在写回 blob index 后记录 RocksDB 最新的 sequence number,等到最旧 snapshot 的 sequence 超过这个记录的 sequence number 时 BlobFile 才能被删除。这个是因为在写回 blob index 后,还是可能通过之前的 snapshot 访问到老的 blob index,因此需要确保没有 snapshot 会访问到这个老的 blob index 后才能安全删除相应 BlobFile。
Level Merge
Level Merge 是 Titan 新加入的一种策略,它的核心思想是 LSM-tree 在进行 Compaction 的同时,对 SST 文件对应的 BlobFile 进行归并重写产生新的 BlobFile。其流程大概如下图所示:
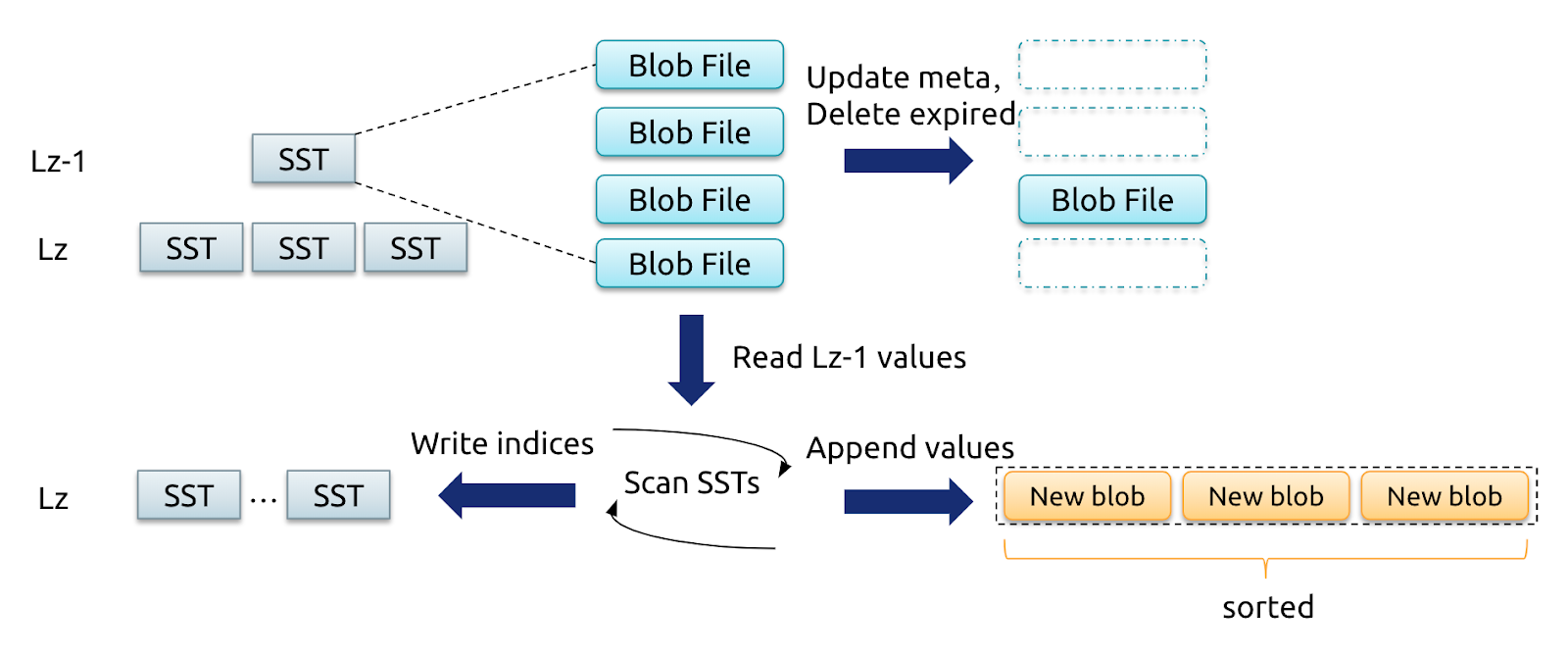
Level z-1 和 Level z 的 SST 进行 Compaction 时会对 KV 对有序读写一遍,这时就可以对这些 SST 中所涉及的 BlobFile 的 value 有序写到新的 BlobFile 中,并在生成新的 SST 时将 key 的 blob index 进行更新。对于 Compaction 中被删除的 key,相应的 value 也不会写到新的 BlobFile 中,相当于完成了 GC。
相比于传统 GC,Level Merge 这种方式在 LSM-tree 进行 Compaction 的同时就完成了 Blob GC,不再需要查询 LSM-tree 的 blob index 情况和写回新 blob index 到 LSM-tree 中,减小了 GC 对前台操作影响。同时通过不断的重写 BlobFile,减小了 BlobFile 之间的相互重叠,提高系统整体有序性,也就是提高了 Scan 性能。当然将 BlobFile 以类似 tiering compaction 的方式分层会带来写放大,考虑到 LSM-tree 中 99% 的数据都落在最后两层,因此 Titan 仅对 LSM-tree 中 Compaction 到最后两层数据对应的 BlobFile 进行 Level Merge。
Range Merge
Range Merge 是基于 Level Merge 的一个优化。考虑如下两种情况,会导致最底层的有序性越来越差:
开启
level_compaction_dynamic_level_bytes,此时 LSM-tree 各层动态增长,随数据量增大最后一层的 sorted run 会越来越多。某个 range 被频繁 Compaction 导致该 range 的 sorted runs 较多。

因此需要通过 Range Merge 操作维持 sorted run 在一定水平,即在 OnCompactionComplete 时统计该 range 的 sorted run 数量,若数量过多则将涉及的 BlobFile 标记为 ToMerge,在下一次的 Compaction 中进行重写。
扩容与缩容
基于向后兼容的考虑,TiKV 在扩缩容时的 Snapshot 仍然是 RocksDB 的格式。因此扩容后的节点由于一开始全部来自 RocksDB,因此会显示 RocksDB 的特征,比如压缩率会高于老的 TiKV 节点、Store Size 会较小、同时 Compaction 的写放大会相对较大。后续这些 RocksDB 格式的 SST 参与 Compaction 之后逐步转换为 Titan 格式。
min-blob-size 对性能的影响
min-blob-size 是决定一个 Value 是否用 Titan 存储的依据。如果 Value 大于或等于 min-blob-size,会用 Titan 存储,反之则用 RocksDB 的原生格式存储。min-blob-size 太小或太大都会导致性能下降。
下表格列举了 YCSB 这个负载在不同 min-blob-size 值时的 QPS 对比。每一轮测试中测试数据的行宽和 min-blob-size 相等,从而确保 Titan 启用时数据保存在 Titan 中。
| 行宽 (Bytes) | Point_Get | Point_Get (Titan) | scan100 | scan100 (Titan) | scan10000 | scan10000 (Titan) | UPDATE | UPDATE (Titan) |
|---|---|---|---|---|---|---|---|---|
| 1KB | 139255 | 140486 | 25171 | 21854 | 533 | 175 | 17913 | 30767 |
| 2KB | 114201 | 124075 | 12466 | 11552 | 249 | 131 | 10369 | 27188 |
| 4KB | 92385 | 103811 | 7918 | 5937 | 131 | 87 | 5327 | 22653 |
| 8KB | 104380 | 130647 | 7365 | 5402 | 86.6 | 68 | 3180 | 16745 |
| 16KB | 54234 | 54600 | 4937 | 5174 | 55.4 | 58.9 | 1753 | 10120 |
| 32KB | 31035 | 31052 | 2705 | 3422 | 38 | 45.3 | 984 | 5844 |
以上可见,当行宽是 16KB 时,Titan 在所有 YCSB 细分负载下上都超过了 RocksDB。然而在一些极端重度扫描场景下,如运行 Dumpling,16KB 行宽下 Titan 的性能会有约 10% 的回退。因此,如果负载是以写和点查为主,建议将 min-blob-size 调整为 1KB;如果负载有大量扫描,建议将 min-blob-size 调整为至少 16KB。