TiDB Scheduler 扩展调度器
TiDB Scheduler 是 Kubernetes 调度器扩展 的 TiDB 实现。TiDB Scheduler 用于向 Kubernetes 添加新的调度规则。本文介绍 TiDB Scheduler 扩展调度器的工作原理。
tidb-scheduler 与 default-scheduler
Kubernetes 集群中默认会部署一个 kube-scheduler,用于 Pod 调度,默认调度器名字为 default-scheduler。
在早期 Kubernetes 版本中 (< v1.16),默认调度器对于 Pod 均匀调度支持不够灵活,因此我们实现了 TiDB Scheduler 用于扩展 Kubernetes 默认调度器的调度规则,支持 TiDB 集群 Pod 的均匀调度,名字为 tidb-scheduler。
从 Kubernetes v1.16 开始,Kubernetes 默认调度器引入了 EvenPodsSpread 特性,控制 Pod 在集群内故障域之间的分布。该特性在 v1.18 进入 beta,在 v1.19 正式 GA。
因此,如果 Kubernetes 集群满足下面条件之一,就不需要使用 tidb-scheduler,直接使用 default-scheduler。你需要为组件配置 topologySpreadConstraints,即可实现 tidb-scheduler 的均匀调度功能。
- Kubernetes 版本为 v1.18.x 并且已开启
EvenPodsSpreadfeature gate。 - Kubernetes 版本 >= v1.19。
TiDB 集群调度需求
TiDB 集群包括 PD,TiKV 以及 TiDB 三个核心组件,每个组件又是由多个节点组成,PD 是一个 Raft 集群,TiKV 是一个多 Raft Group 集群,并且这两个组件都是有状态的。如果 Kubernetes 集群没有开启 EvenPodsSpread feature gate,Kubernetes 的默认调度器的调度规则无法满足 TiDB 集群的高可用调度需求,需要扩展 Kubernetes 的调度规则。
目前,可通过修改 TidbCluster 的 metadata.annotations 来按照特定的维度进行调度,比如:
metadata:
annotations:
pingcap.com/ha-topology-key: kubernetes.io/hostname
上述配置按照节点(默认值)维度进行调度,若要按照其他维度调度,比如: pingcap.com/ha-topology-key: zone,表示按照 zone 调度,还需给各节点打如下标签:
kubectl label nodes node1 zone=zone1
不同节点可有不同的标签,也可有相同的标签,如果某一个节点没有打该标签,则调度器不会调度 pod 到该节点。
目前,TiDB Scheduler 实现了如下几种自定义的调度规则(下述示例基于节点调度,基于其他维度的调度规则相同)。
PD 组件
调度规则一:确保每个节点上调度的 PD 实例个数小于 Replicas / 2。例如:
TiKV 组件
调度规则二:如果 Kubernetes 节点数小于 3 个(Kubernetes 集群节点数小于 3 个是无法实现 TiKV 高可用的),则可以任意调度;否则,每个节点上可调度的 TiKV 个数的计算公式为:ceil(Replicas/3) 。例如:
工作原理
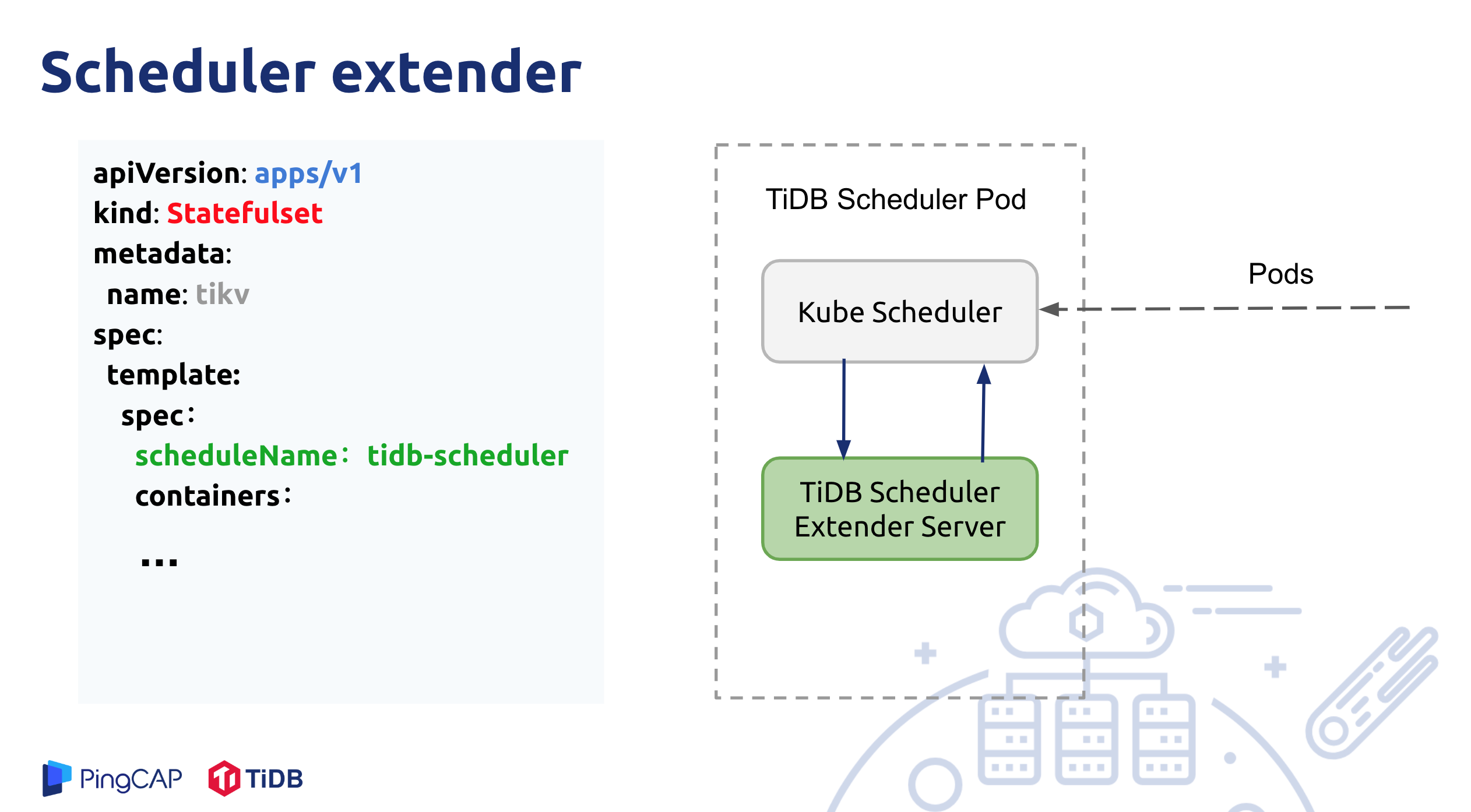
TiDB Scheduler 通过实现 Kubernetes 调度器扩展(Scheduler extender)来添加自定义调度规则。
TiDB Scheduler 组件部署为一个或者多个 Pod,但同时只有一个 Pod 在工作。Pod 内部有两个 Container,一个 Container 是原生的 kube-scheduler;另外一个 Container 是 tidb-scheduler,实现为一个 Kubernetes scheduler extender。
如果 TidbCluster 中配置组件使用 tidb-scheduler,TiDB Operator 创建的 PD、TiDB、TiKV Pod 的 .spec.schedulerName 属性会被设置为 tidb-scheduler,即都用 TiDB Scheduler 自定义调度器来调度。
此时,一个 Pod 的调度流程是这样的:
kube-scheduler拉取所有.spec.schedulerName为tidb-scheduler的 Pod,对于每个 Pod 会首先经过 Kubernetes 默认调度规则过滤;- 在这之后,
kube-scheduler会发请求到tidb-scheduler服务,tidb-scheduler会通过一些自定义的调度规则(见上述介绍)对发送过来的节点进行过滤,最终将剩余可调度的节点返回给kube-scheduler; - 最终由
kube-scheduler决定最终调度的节点。
如果出现 Pod 无法调度,请参考此文档诊断和解决。