Amazon S3 Integration Task
This page describes how to create an Amazon S3 integration task that imports files from an S3 bucket into TiDB Cloud Lake. CSV, Parquet, and NDJSON file formats are supported, and the task can be configured for one-time import or continuous ingestion.
If you need to create reusable AWS credentials first, see Amazon S3 - Credentials.
Supported File Formats
Prerequisites
- An Amazon S3 - Credentials data source has already been created
- The AWS credentials have read access to the target S3 bucket
- If you plan to enable Clean Up Original Files, the credentials also need write and delete permissions
Creating an S3 Integration Task
Step 1: Basic Info
Navigate to Data > Data Integration and click Create Task.
Select an S3 data source, then configure the basic settings:
CSV Options
When the file type is CSV, additional options are available:
File Path Patterns
The file path supports wildcard patterns for matching multiple files:
s3://mybucket/data/2025-*.csv # All CSV files starting with "2025-"
s3://mybucket/logs/*.parquet # All Parquet files in the logs directory
s3://mybucket/events/data.ndjson # A single specific file
Step 2: Preview Data
After configuring the basic settings, click Next to preview the source data.
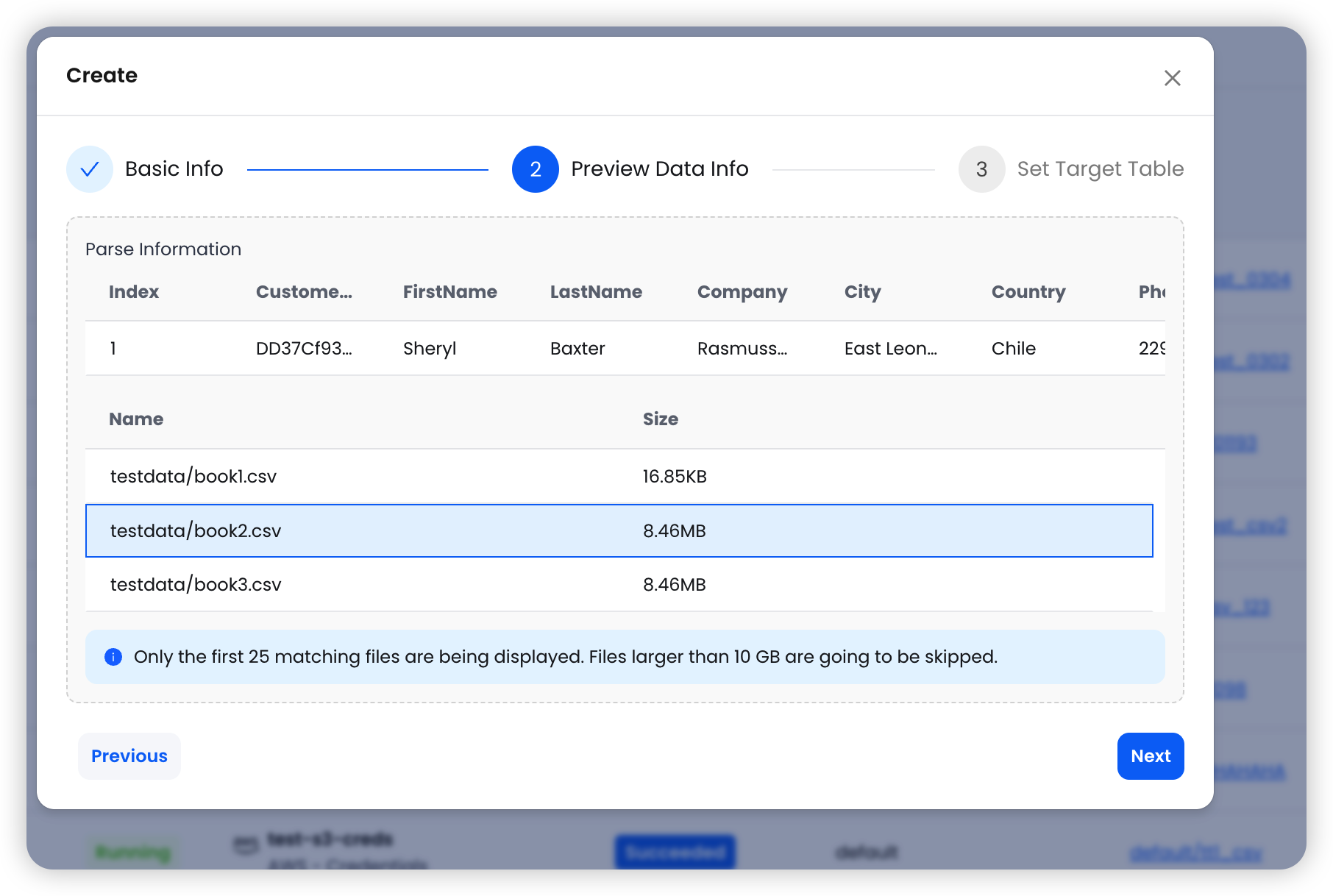
The system reads the first matching file and displays:
- Sample data with column names and types
- A list of matching files (up to 25 files) with their sizes
Step 3: Set Target Table
Configure the destination in TiDB Cloud Lake:
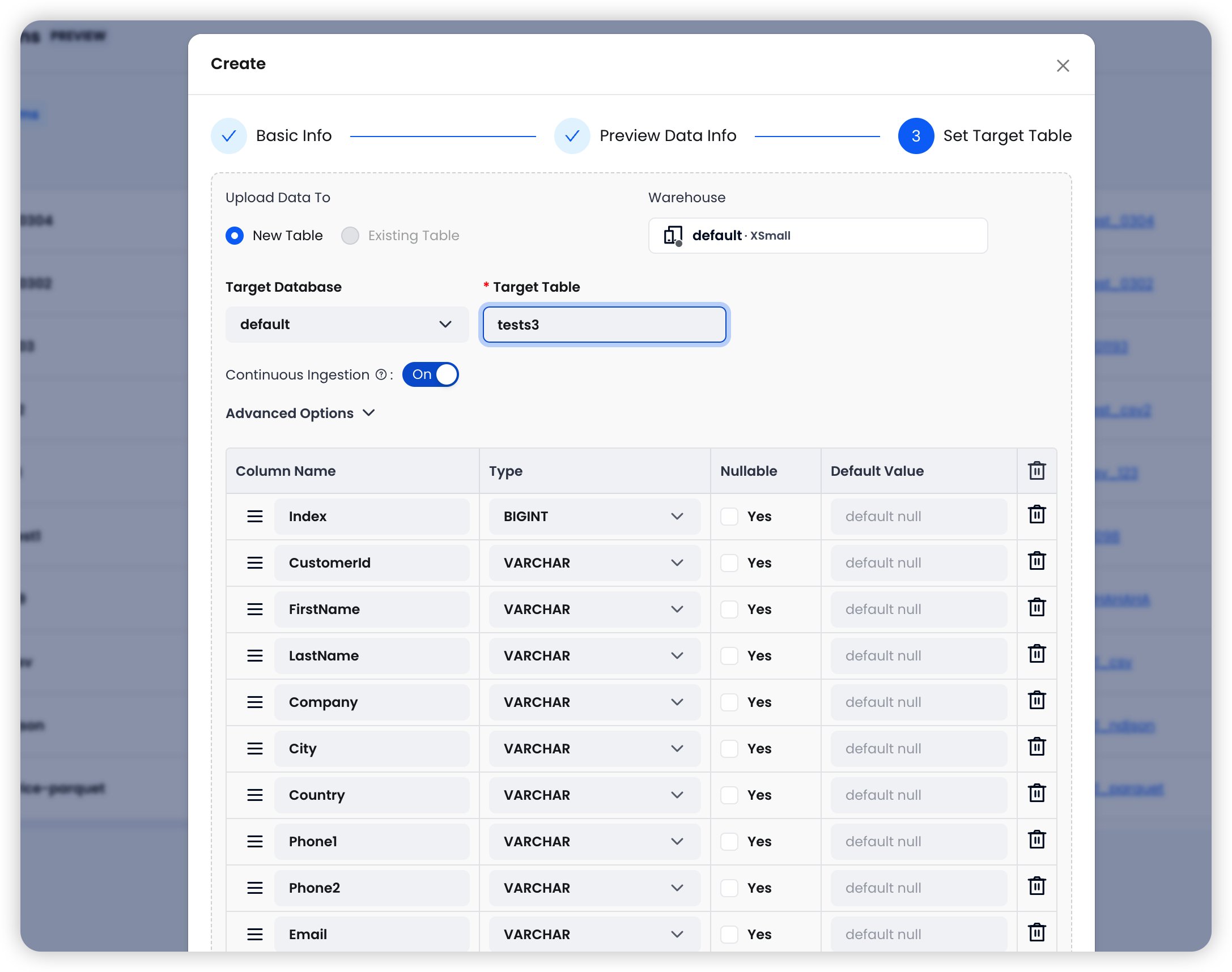
The system auto-detects columns from the source files. You can review and edit column names and types before proceeding.
Ingestion Options
Click Create to finalize the integration task.
Task Behavior
Advanced Configuration
Continuous Ingestion
When enabled, the task runs as a long-lived process that periodically scans the S3 path for new files. Each cycle:
- Lists objects matching the file path pattern
- Identifies new files not yet imported
- Imports new files into the target table using
COPY INTO - Records import results in the task history
This is useful for data pipelines where upstream systems continuously write new files to S3.
Error Handling
- Abort (default): The import stops at the first error encountered. Use this when data quality is critical and you want to investigate any issues before proceeding.
- Continue: Skips rows that cause errors and continues importing the remaining data. Use this when partial imports are acceptable and you want to maximize data throughput.
Clean Up Original Files (PURGE)
When enabled, source files are deleted from S3 after they are successfully imported into TiDB Cloud Lake. This helps manage storage costs and prevents reprocessing. Ensure your AWS credentials have s3:DeleteObject permission on the target bucket.
Allow Duplicate Imports (FORCE)
By default, the system tracks which files have been imported and skips them in subsequent runs. Enabling this option forces re-import of all matching files, regardless of whether they have been previously imported. This is useful when you need to reload data after schema changes or data corrections.