Troubleshoot Hotspot Issues
This document describes how to locate and resolve the problem of read and write hotspots.
As a distributed database, TiDB has a load balancing mechanism to distribute the application loads as evenly as possible to different computing or storage nodes, to make better use of server resources. However, in certain scenarios, some application loads cannot be well distributed, which can affect the performance and form a single point of high load, also known as a hotspot.
TiDB provides a complete solution to troubleshooting, resolving or avoiding hotspots. By balancing load hotspots, overall performance can be improved, including improving QPS and reducing latency.
Common hotspots
This section describes TiDB encoding rules, table hotspots, and index hotspots.
TiDB encoding rules
TiDB assigns a TableID to each table, an IndexID to each index, and a RowID to each row. By default, if the table uses an integer primary key, the value of the primary key is treated as the RowID. Among these IDs, TableID is unique in the entire cluster, while IndexID and RowID are unique in the table. The type of all these IDs is int64.
Each row of data is encoded as a key-value pair according to the following rule:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
The tablePrefix and recordPrefixSep of the key are specific string constants, used to distinguish from other data in the KV space.
For Index data, the key-value pair is encoded according to the following rule:
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue
Value: rowID
Index data has two types: the unique index and the non-unique index.
For unique indexes, you can follow the coding rules above.
For non-unique indexes, a unique key cannot be constructed through this encoding, because the
tablePrefix{TableID}_indexPrefixSep{IndexID}of the same index is the same and theColumnsValueof multiple rows might be the same. The encoding rule for non-unique indexes is as follows:Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_rowID Value: null
Table hotspots
According to TiDB coding rules, the data of the same table is in a range prefixed by the beginning of the TableID, and the data is arranged in the order of RowID values. When RowID values are incremented during table inserting, the inserted line can only be appended to the end. The Region will split after it reaches a certain size, and then it still can only be appended to the end of the range. The INSERT operation can only be executed on one Region, forming a hotspot.
The common auto-increment primary key is sequentially increasing. When the primary key is of the integer type, the value of the primary key is used as the RowID by default. At this time, the RowID is sequentially increasing, and a write hotspot of the table forms when a large number of INSERT operations exist.
Meanwhile, the RowID in TiDB is also sequentially auto-incremental by default. When the primary key is not an integer type, you might also encounter the problem of write hotspots.
In addition, when hotspots occur during the process of data writes (on a newly created table or partition) or data reads (periodic read hotspots in read-only scenarios), you can control the Region merge behavior using table attributes. For details, see Control the Region merge behavior using table attributes.
Index hotspots
Index hotspots are similar to table hotspots. Common index hotspots appear in fields that are monotonously increasing in time order, or INSERT scenarios with a large number of repeated values.
Identify hotspot issues
Performance problems are not necessarily caused by hotspots and might be caused by multiple factors. Before troubleshooting issues, confirm whether it is related to hotspots.
To judge write hotspots, open Hot Write in the TiKV-Trouble-Shooting monitoring panel to check whether the Raftstore CPU metric value of any TiKV node is significantly higher than that of other nodes.
To judge read hotspots, open Thread_CPU in the TiKV-Details monitoring panel to check whether the coprocessor CPU metric value of any TiKV node is particularly high.
Use TiDB Dashboard to locate hotspot tables
The Key Visualizer feature in TiDB Dashboard helps users narrow down hotspot troubleshooting scope to the table level. The following is an example of the thermal diagram shown by Key Visualizer. The horizontal axis of the graph is time, and the vertical axis are various tables and indexes. The brighter the color, the greater the load. You can switch the read or write flow in the toolbar.
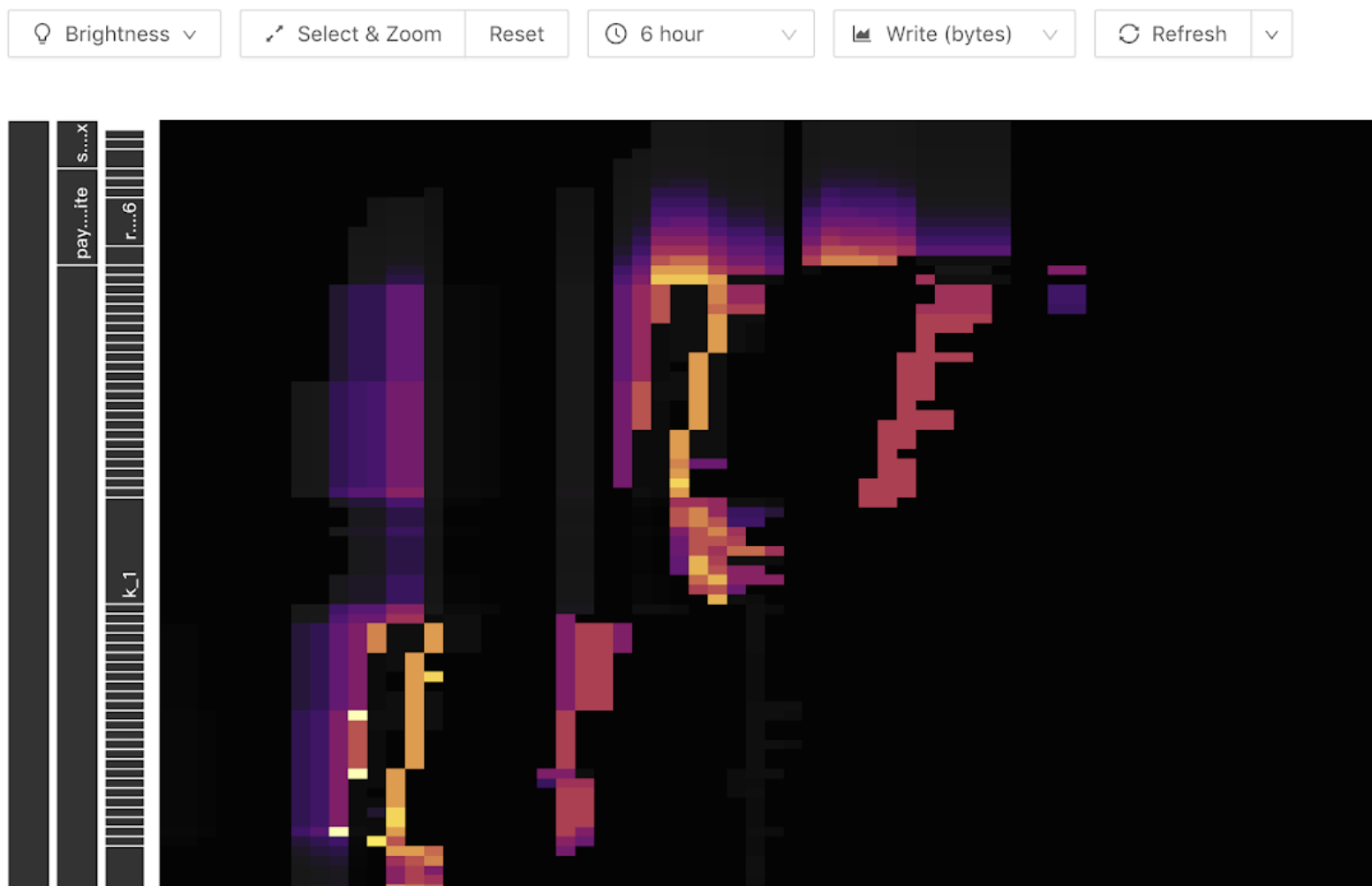
The following bright diagonal lines (oblique upward or downward) can appear in the write flow graph. Because the write only appears at the end, as the number of table Regions becomes larger, it appears as a ladder. This indicates that a write hotspot shows in this table:

For read hotspots, a bright horizontal line is generally shown in the thermal diagram. Usually these are caused by small tables with a large number of accesses, shown as follows:

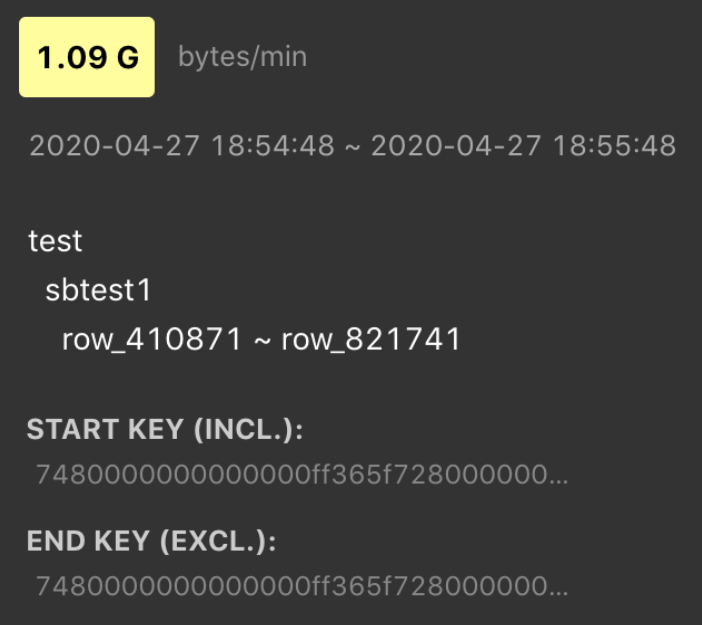
Hover over the bright block, you can see what table or index has a heavy load. For example:
Use SHARD_ROW_ID_BITS to process hotspots
For a non-clustered primary key or a table without a primary key, TiDB uses an implicit auto-increment RowID. When a large number of INSERT operations exist, the data is written into a single Region, resulting in a write hotspot.
By setting SHARD_ROW_ID_BITS, row IDs are scattered and written into multiple Regions, which can alleviate the write hotspot issue.
SHARD_ROW_ID_BITS = 4 # Represents 16 shards.
SHARD_ROW_ID_BITS = 6 # Represents 64 shards.
SHARD_ROW_ID_BITS = 0 # Represents the default 1 shard.
Statement example:
CREATE TABLE: CREATE TABLE t (c int) SHARD_ROW_ID_BITS = 4;
ALTER TABLE: ALTER TABLE t SHARD_ROW_ID_BITS = 4;
The value of SHARD_ROW_ID_BITS can be dynamically modified. The modified value only takes effect for newly written data.
For the table with a primary key of the CLUSTERED type, TiDB uses the primary key of the table as the RowID. At this time, the SHARD_ROW_ID_BITS option cannot be used because it changes the RowID generation rules. For the table with the primary key of the NONCLUSTERED type, TiDB uses an automatically allocated 64-bit integer as the RowID. In this case, you can use the SHARD_ROW_ID_BITS feature. For more details about the primary key of the CLUSTERED type, refer to clustered index.
The following two load diagrams shows the case where two tables without primary keys use SHARD_ROW_ID_BITS to scatter hotspots. The first diagram shows the situation before scattering hotspots, while the second one shows the situation after scattering hotspots.
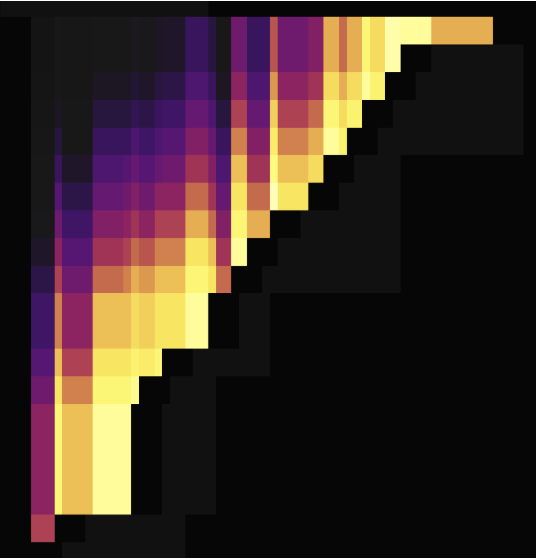
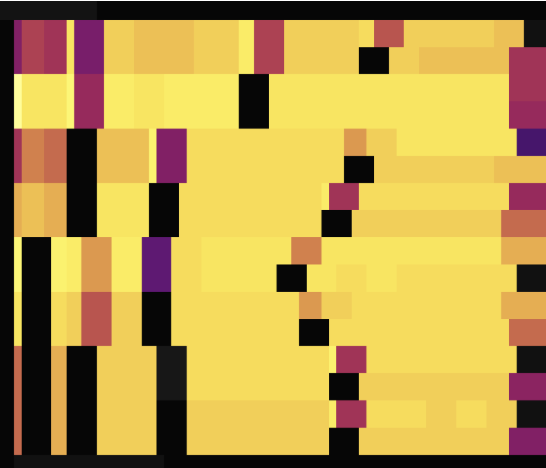
As shown in the load diagrams above, before setting SHARD_ROW_ID_BITS, load hotspots are concentrated on a single Region. After setting SHARD_ROW_ID_BITS, load hotspots become scattered.
Handle auto-increment primary key hotspot tables using AUTO_RANDOM
To resolve the write hotspots brought by auto-increment primary keys, use AUTO_RANDOM to handle hotspot tables that have auto-increment primary keys.
If this feature is enabled, TiDB generates randomly distributed and non-repeated (before the space is used up) primary keys to achieve the purpose of scattering write hotspots.
Note that the primary keys generated by TiDB are no longer auto-increment primary keys and you can use LAST_INSERT_ID() to obtain the primary key value assigned last time.
To use this feature, modify AUTO_INCREMENT to AUTO_RANDOM in the CREATE TABLE statement. This feature is suitable for non-application scenarios where the primary keys only need to guarantee uniqueness.
For example:
CREATE TABLE t (a BIGINT PRIMARY KEY AUTO_RANDOM, b varchar(255));
INSERT INTO t (b) VALUES ("foo");
SELECT * FROM t;
+------------+---+
| a | b |
+------------+---+
| 1073741825 | b |
+------------+---+
SELECT LAST_INSERT_ID();
+------------------+
| LAST_INSERT_ID() |
+------------------+
| 1073741825 |
+------------------+
The following two load diagrams shows the situations both before and after modifying AUTO_INCREMENT to AUTO_RANDOM to scatter hotspots. The first one uses AUTO_INCREMENT, while the second one uses AUTO_RANDOM.
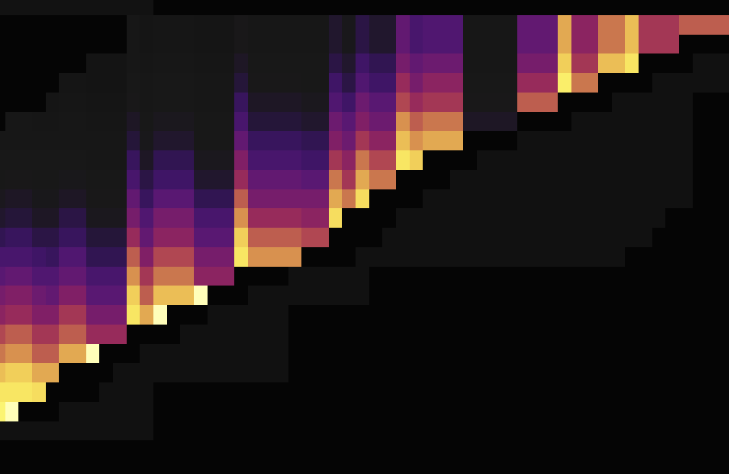

As shown in the load diagrams above, using AUTO_RANDOM to replace AUTO_INCREMENT can well scatter hotspots.
For more details, see AUTO_RANDOM.
Optimization of small table hotspots
The Coprocessor Cache feature of TiDB supports pushing down computing result caches. After this feature is enabled, TiDB caches the computing results that will be pushed down to TiKV. This feature works well for read hotspots of small tables.
For more details, see Coprocessor Cache.
See also:
Scatter read hotspots
In a read hotspot scenario, the hotspot TiKV node cannot process read requests in time, resulting in the read requests queuing. However, not all TiKV resources are exhausted at this time. To reduce latency, TiDB v7.1.0 introduces the load-based replica read feature, which allows TiDB to read data from other TiKV nodes without queuing on the hotspot TiKV node. You can control the queue length of read requests using the tidb_load_based_replica_read_threshold system variable. When the estimated queue time of the leader node exceeds this threshold, TiDB prioritizes reading data from follower nodes. This feature can improve read throughput by 70% to 200% in a read hotspot scenario compared to not scattering read hotspots.
CPU-aware hot Region scheduling for read hotspots
Starting from v8.5.7, PD supports CPU-aware hot Region scheduling for read hotspots. TiKV reports hot Region read CPU usage in store heartbeats, and PD can use CPU usage as a scheduling dimension. This mechanism helps PD identify read hotspots whose QPS or byte throughput appears balanced but whose TiKV CPU usage remains uneven, such as workloads with queries that have different CPU costs or clusters where TiKV nodes handle different workload patterns.
- For clusters that support read CPU reporting, the default
read-prioritiesvalue ofbalance-hot-region-scheduleriscpu,byte. - For clusters that do not support read CPU reporting, PD automatically falls back to
query,byte, or tobyte,keyif the cluster does not support thequerydimension either.
To view or adjust the scheduling dimensions, use pd-ctl scheduler config balance-hot-region-scheduler.
Use TiKV MVCC in-memory engine to mitigate read hotspots caused by high MVCC read amplification
When the retention time of historical MVCC data for GC is too long, or when the records are frequently updated or deleted, read hotspots might occur due to scanning a large number of MVCC versions. To alleviate this type of hotspot, you can enable the TiKV MVCC In-Memory Engine feature.