Configure TiDB for Optimal Performance
This guide describes how to optimize the performance of TiDB, including:
- Best practices for common workloads.
- Strategies for handling challenging performance scenarios.
Overview
Optimizing TiDB for peak performance requires careful tuning of various settings. In many cases, achieving optimal performance involves adjusting configurations beyond their default values.
The default settings prioritize stability over performance. To maximize performance, you might need to use more aggressive configurations and, in some cases, experimental features. These recommendations are based on production deployment experience and performance optimization research.
This guide describes the non-default settings, including their benefits and potential trade-offs. Use this information to optimize TiDB settings for your workload requirements.
Key settings for common workloads
The following settings are commonly used to optimize TiDB performance:
- Enhance execution plan cache, such as SQL Prepared Execution Plan Cache, Non-prepared plan cache, and Instance-level execution plan cache.
- Optimize the behavior of the TiDB optimizer by using Optimizer Fix Controls.
- Use the Titan storage engine more aggressively.
- Fine-tune TiKV's compaction and flow control configurations, to ensure optimal and stable performance under write-intensive workloads.
These settings can significantly improve performance for many workloads. However, as with any optimization, thoroughly test them in your environment before deploying to production.
System variables
Execute the following SQL commands to apply the recommended settings:
SET GLOBAL tidb_enable_instance_plan_cache=on;
SET GLOBAL tidb_instance_plan_cache_max_size=2GiB;
SET GLOBAL tidb_enable_non_prepared_plan_cache=on;
SET GLOBAL tidb_ignore_prepared_cache_close_stmt=on;
SET GLOBAL tidb_analyze_column_options='ALL';
SET GLOBAL tidb_stats_load_sync_wait=2000;
SET GLOBAL tidb_opt_limit_push_down_threshold=10000;
SET GLOBAL tidb_opt_derive_topn=on;
SET GLOBAL tidb_runtime_filter_mode=LOCAL;
SET GLOBAL tidb_opt_enable_mpp_shared_cte_execution=on;
SET GLOBAL tidb_rc_read_check_ts=on;
SET GLOBAL tidb_guarantee_linearizability=off;
SET GLOBAL pd_enable_follower_handle_region=on;
SET GLOBAL tidb_opt_fix_control = '44262:ON,44389:ON,44823:10000,44830:ON,44855:ON,52869:ON';
The following table outlines the impact of specific system variable configurations:
| System variable | Description | Note |
|---|---|---|
tidb_enable_instance_plan_cache and tidb_instance_plan_cache_max_size | Use instance-level plan cache instead of session-level caching. This significantly improves performance for workloads with high connection counts or frequent prepared statement usage. | This is an experimental feature. Test in non-production environments first and monitor memory usage as the plan cache size increases. |
tidb_enable_non_prepared_plan_cache | Enable the Non-prepared plan cache feature to reduce compile costs for applications that do not use prepared statements. | N/A |
tidb_ignore_prepared_cache_close_stmt | Cache plans for applications that use prepared statements but close the plan after each execution. | N/A |
tidb_analyze_column_options | Collect statistics for all columns to avoid suboptimal execution plans due to missing column statistics. By default, TiDB only collects statistics for predicate columns. | Setting this variable to 'ALL' can cause more resource usage for the ANALYZE TABLE operation compared with the default value 'PREDICATE'. |
tidb_stats_load_sync_wait | Increase the timeout for synchronously loading statistics from the default 100 milliseconds to 2 seconds. This ensures TiDB loads the necessary statistics before query compilation. | Increasing this value leads to a longer synchronization wait time before query compilation. |
tidb_opt_limit_push_down_threshold | Increase the threshold that determines whether to push the Limit or TopN operator down to TiKV. | When multiple index options exist, increasing this variable makes the optimizer favor indexes that can optimize the ORDER BY and Limit operators. |
tidb_opt_derive_topn | Enable the optimization rule of Deriving TopN or Limit from window functions. | This is limited to the ROW_NUMBER() window function. |
tidb_runtime_filter_mode | Enable Runtime Filter in the local mode to improve hash join efficiency. | The variable is introduced in v7.2.0 and is disabled by default for safety. |
tidb_opt_enable_mpp_shared_cte_execution | Enable non-recursive Common Table Expressions (CTE) pushdown to TiFlash. | This is an experimental feature. |
tidb_rc_read_check_ts | For the read-committed isolation level, enabling this variable avoids the latency and cost of getting the global timestamp and optimizes transaction-level read latency. | This feature is incompatible with the Repeatable Read isolation level. |
tidb_guarantee_linearizability | Improve performance by skipping the commit timestamp fetch from the PD server. | This sacrifices linearizability in favor of performance. Only causal consistency is guaranteed. It is not suitable for scenarios requiring strict linearizability. |
pd_enable_follower_handle_region | Activate the PD Follower feature, allowing PD followers to process Region requests. This helps distribute load evenly across all PD servers and reduces CPU pressure on the PD leader. | This is an experimental feature. Test in non-production environments. |
tidb_opt_fix_control | Enable advanced query optimization strategies to improve performance through additional optimization rules and heuristics. | Test thoroughly in your environment, as performance improvements vary by workload. |
The following describes the optimizer control configurations that enable additional optimizations:
44262:ON: Use Dynamic pruning mode to access the partitioned table when the GlobalStats are missing.44389:ON: For filters such asc = 10 and (a = 'xx' or (a = 'kk' and b = 1)), build more comprehensive scan ranges forIndexRangeScan.44823:10000: To save memory, plan cache does not cache queries with parameters exceeding the specified number of this variable. Increase plan cache parameter limit from200to10000to make plan cache available for query with long in-lists.44830:ON: Plan cache is allowed to cache execution plans with thePointGetoperator generated during physical optimization.44855:ON: The optimizer selectsIndexJoinwhen theProbeside of anIndexJoinoperator contains aSelectionoperator.52869:ON: The optimizer chooses index merge automatically if the optimizer can choose the single index scan method (other than full table scan) for a query plan.
TiKV configurations
Add the following configuration items to the TiKV configuration file:
[server]
concurrent-send-snap-limit = 64
concurrent-recv-snap-limit = 64
snap-io-max-bytes-per-sec = "400MiB"
[pessimistic-txn]
in-memory-peer-size-limit = "32MiB"
in-memory-instance-size-limit = "512MiB"
[rocksdb]
max-manifest-file-size = "256MiB"
[rocksdb.titan]
enabled = true
[rocksdb.defaultcf.titan]
min-blob-size = "1KB"
blob-file-compression = "zstd"
[storage]
scheduler-pending-write-threshold = "512MiB"
[storage.flow-control]
l0-files-threshold = 50
soft-pending-compaction-bytes-limit = "512GiB"
[rocksdb.writecf]
level0-slowdown-writes-trigger = 20
soft-pending-compaction-bytes-limit = "192GiB"
[rocksdb.defaultcf]
level0-slowdown-writes-trigger = 20
soft-pending-compaction-bytes-limit = "192GiB"
[rocksdb.lockcf]
level0-slowdown-writes-trigger = 20
soft-pending-compaction-bytes-limit = "192GiB"
| Configuration item | Description | Note |
|---|---|---|
concurrent-send-snap-limit, concurrent-recv-snap-limit, and snap-io-max-bytes-per-sec | Set limits for concurrent snapshot transfer and I/O bandwidth during TiKV scaling operations. Higher limits reduce scaling time by allowing faster data migration. | Adjusting these limits affects the trade-off between scaling speed and online transaction performance. |
in-memory-peer-size-limit and in-memory-instance-size-limit | Control the memory allocation for pessimistic lock caching at the Region and TiKV instance levels. Storing locks in memory reduces disk I/O and improves transaction performance. | Monitor memory usage carefully. Higher limits improve performance but increase memory consumption. |
rocksdb.max-manifest-file-size | Set the maximum size of the RocksDB Manifest file, which logs the metadata about SST files and database state changes. Increasing this size reduces the frequency of Manifest file rewrites, thereby minimizing their impact on foreground write performance. | The default value is 128MiB. In environments with a large number of SST files (for example, hundreds of thousands), frequent Manifest rewrites can degrade write performance. Adjusting this parameter to a higher value, such as 256MiB or larger, can help maintain optimal performance. |
rocksdb.titan, rocksdb.defaultcf.titan, min-blob-size, and blob-file-compression | Enable the Titan storage engine to reduce write amplification and alleviate disk I/O bottlenecks. Particularly useful when RocksDB compaction cannot keep up with write workloads, resulting in accumulated pending compaction bytes. | Enable it when write amplification is the primary bottleneck. Trade-offs include:
|
storage.scheduler-pending-write-threshold | Set the maximum size of the write queue in the TiKV scheduler. When the total size of pending write tasks exceeds this threshold, TiKV returns a Server Is Busy error for new write requests. | The default value is 100MiB. In scenarios with high write concurrency or temporary write spikes, increasing this threshold (for example, to 512MiB) can help accommodate the load. However, if the write queue continues to accumulate and exceeds this threshold persistently, it might indicate underlying performance issues that require further investigation. |
storage.flow-control.l0-files-threshold | Control when write flow control is triggered based on the number of kvDB L0 files. Increasing the threshold reduces write stalls during high write workloads. | Higher thresholds might lead to more aggressive compactions when many L0 files exist. |
storage.flow-control.soft-pending-compaction-bytes-limit | Control the threshold for pending compaction bytes to manage write flow control. The soft limit triggers partial write rejections. | The default soft limit is 192GiB. In write-intensive scenarios, if compaction processes cannot keep up, pending compaction bytes accumulate, potentially triggering flow control. Adjusting the limit can provide more buffer space, but persistent accumulation indicates underlying issues that require further investigation. |
rocksdb.(defaultcf\|writecf\|lockcf).level0-slowdown-writes-trigger rocksdb.(defaultcf\|writecf\|lockcf).soft-pending-compaction-bytes-limit | You need to manually set level0-slowdown-writes-trigger and soft-pending-compaction-bytes-limit back to their default values. This way they will not be affected by flow control parameters. In addition, set the Rocksdb parameters to maintain the same compaction efficiency as the default parameters. | For more information, see Issue 18708. |
Note that the compaction and flow control configuration adjustments outlined in the preceding table are tailored for TiKV deployments on instances with the following specifications:
- CPU: 32 cores
- Memory: 128 GiB
- Storage: 5 TiB EBS
- Disk Throughput: 1 GiB/s
Recommended configuration adjustments for write-intensive workloads
To optimize TiKV performance and stability under write-intensive workloads, it is recommended that you adjust certain compaction and flow control parameters based on the hardware specifications of the instance. For example:
rocksdb.rate-bytes-per-sec: usually use the default value. If you notice that compaction I/O is consuming a significant share of the disk bandwidth, consider capping the rate to about 60% of your disk’s maximum throughput. This helps balance compaction work and ensures the disk is not saturated. For example, on a disk rated at 1 GiB/s, set this to roughly600MiB.storage.flow-control.soft-pending-compaction-bytes-limitandstorage.flow-control.hard-pending-compaction-bytes-limit: increase these limits proportionally to the available disk space (for example, 1 TiB and 2 TiB, respectively) to provide more buffer for compaction processes.
These settings help ensure efficient resource utilization and minimize potential bottlenecks during peak write loads.
TiFlash-learner configurations
Add the following configuration items to the TiFlash-learner configuration file:
[server]
snap-io-max-bytes-per-sec = "300MiB"
| Configuration item | Description | Note |
|---|---|---|
snap-io-max-bytes-per-sec | Control the maximum allowable disk bandwidth for data replication from TiKV to TiFlash. Higher limits accelerate initial data loading and catch-up replication. | Higher bandwidth consumption might impact online transaction performance. Balance between replication speed and system stability. |
Benchmark
This section compares performance between default settings (baseline) and optimized settings based on the preceding key settings for common loads.
Sysbench workloads on 1000 tables
Test environment
The test environment is as follows:
- 3 TiDB servers (16 cores, 64 GiB)
- 3 TiKV servers (16 cores, 64 GiB)
- TiDB version: v8.4.0
- Workload: sysbench oltp_read_only
Performance comparison
The following table compares throughput, latency, and plan cache hit ratio between baseline and optimized settings.
| Metric | Baseline | Optimized | Improvement |
|---|---|---|---|
| QPS | 89,100 | 100,128 | +12.38% |
| Average latency (ms) | 35.87 | 31.92 | -11.01% |
| P95 latency (ms) | 58.92 | 51.02 | -13.41% |
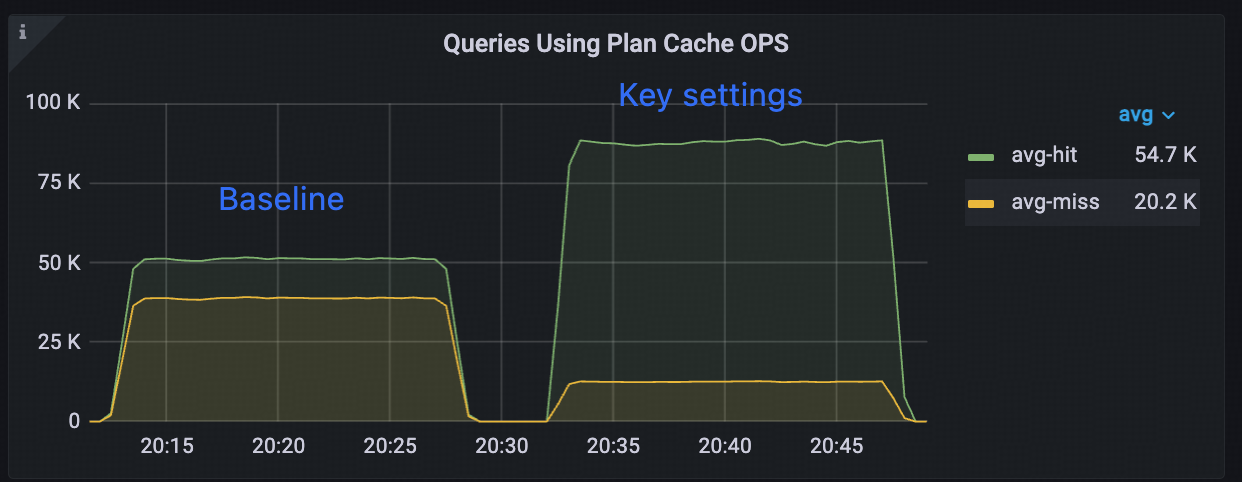
| Plan cache hit ratio (%) | 56.89% | 87.51% | +53.82% |
| Plan cache memory usage (MiB) | 95.3 | 70.2 | -26.34% |
Key benefits
The instance plan cache demonstrates significant performance improvements over the baseline configuration:
Higher hit ratio: increases by 53.82% (from 56.89% to 87.51%).
Lower memory usage: decreases by 26.34% (from 95.3 MiB to 70.2 MiB).
Better performance:
- QPS increases by 12.38%.
- Average latency decreases by 11.01%.
- P95 latency decreases by 13.41%.
How it works
Instance plan cache improves performance through these mechanisms:
- Cache execution plans for
SELECTstatements in memory. - Share cached plans across all connections (up to 200) on the same TiDB instance.
- Can effectively store plans for up to 5,000
SELECTstatements across 1,000 tables. - Cache misses primarily occur only for
BEGINandCOMMITstatements.
Real-world benefits
Although the benchmark using simple sysbench oltp_read_only queries (14 KB per plan) shows modest improvements, you can expect greater benefits in real-word applications:
- Complex queries can run up to 20 times faster.
- Memory usage is more efficient compared to session-level plan cache.
Instance plan cache is particularly effective for systems with:
- Large tables with many columns.
- Complex SQL queries.
- High concurrent connections.
- Diverse query patterns.
Memory efficiency
Instance plan cache provides better memory efficiency than session-level plan cache because:
- Plans are shared across all connections
- No need to duplicate plans for each session
- More efficient memory utilization while maintaining higher hit ratios
In scenarios with multiple connections and complex queries, session-level plan cache would require significantly more memory to achieve similar hit ratios, making instance plan cache the more efficient choice.
Test workload
The following sysbench oltp_read_only prepare command loads data:
sysbench oltp_read_only prepare --mysql-host={host} --mysql-port={port} --mysql-user=root --db-driver=mysql --mysql-db=test --threads=100 --time=900 --report-interval=10 --tables=1000 --table-size=10000
The following sysbench oltp_read_only run command runs workload:
sysbench oltp_read_only run --mysql-host={host} --mysql-port={port} --mysql-user=root --db-driver=mysql --mysql-db=test --threads=200 --time=900 --report-interval=10 --tables=1000 --table-size=10000
For more information, see How to Test TiDB Using Sysbench.
YCSB workloads on large record value
Test environment
The test environment is as follows:
- 3 TiDB servers (16 cores, 64 GiB)
- 3 TiKV servers (16 cores, 64 GiB)
- TiDB version: v8.4.0
- Workload: go-ycsb workloada
Performance comparison
The following table compares throughput (operations per second) between the baseline and optimized settings.
| Item | Baseline (OPS) | Optimized (OPS) | Improvement |
|---|---|---|---|
| Load data | 2858.5 | 5074.3 | +77.59% |
| Workloada | 2243.0 | 12804.3 | +470.86% |
Performance analysis
Titan is enabled by default starting from v7.6.0 and the default min-blob-size of Titan in TiDB v8.4.0 is 32KiB. The baseline configuration uses a record size of 31KiB to ensure data is stored in RocksDB. In contrast, for the key settings configuration, set min-blob-size to 1KiB, causing data to be stored in Titan.
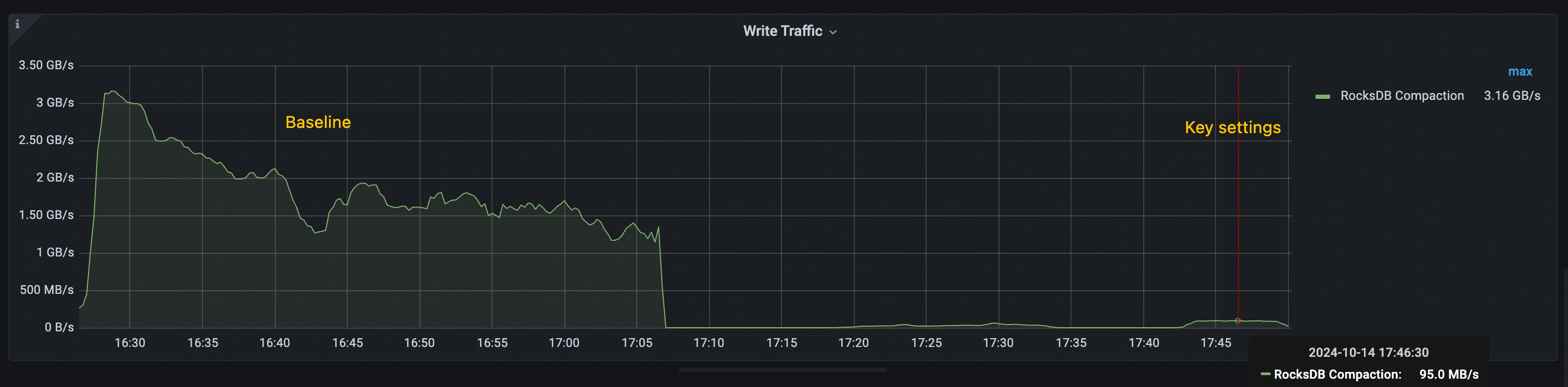
The performance improvement observed in the key settings is primarily attributed to Titan's ability to reduce RocksDB compactions. As shown in the following figures:
- Baseline: The total throughput of RocksDB compaction exceeds 1 GiB/s, with peaks over 3 GiB/s.
- Key settings: The peak throughput of RocksDB compaction remains below 100 MiB/s.
This significant reduction in compaction overhead contributes to the overall throughput improvement seen in the key settings configuration.
Test workload
The following go-ycsb load command loads data:
go-ycsb load mysql -P /ycsb/workloads/workloada -p {host} -p mysql.port={port} -p threadcount=100 -p recordcount=5000000 -p operationcount=5000000 -p workload=core -p requestdistribution=uniform -pfieldcount=31 -p fieldlength=1024
The following go-ycsb run command runs workload:
go-ycsb run mysql -P /ycsb/workloads/workloada -p {host} -p mysql.port={port} -p mysql.db=test -p threadcount=100 -p recordcount=5000000 -p operationcount=5000000 -p workload=core -prequestdistribution=uniform -p fieldcount=31 -p fieldlength=1024
Edge cases and optimizations
This section shows you how to optimize TiDB for specific scenarios that need targeted adjustments beyond basic optimizations. You will learn how to tune TiDB for your particular use cases.
Identify edge cases
To identify edge cases, perform the following steps:
- Analyze query patterns and workload characteristics.
- Monitor system metrics to identify performance bottlenecks.
- Gather feedback from application teams about specific issues.
Common edge cases
The following lists some common edge cases:
- High TSO wait for high-frequency small queries
- Choose the proper max chunk size for different workloads
- Tune coprocessor cache for read-heavy workloads
- Optimize chunk size for workload characteristics
- Optimize transaction mode and DML type for different workloads
- Optimize
GROUP BYandDISTINCToperations with TiKV pushdown - Mitigate MVCC version accumulation using in-memory engine
- Optimize statistics collection during batch operations
- Optimize thread pool settings for different instance types
The following sections explain how to handle each of these cases. You need to adjust different parameters or use specific TiDB features for each scenario.
High TSO wait for high-frequency small queries
Troubleshooting
If your workload involves frequent small transactions or queries that frequently request timestamps, TSO (Timestamp Oracle) can become a performance bottleneck. To check if TSO wait time is impacting your system, check the Performance Overview > SQL Execute Time Overview panel. If TSO wait time constitutes a large portion of your SQL execution time, consider the following optimizations:
- Use low-precision TSO (enable
tidb_low_resolution_tso) for read operations that do not need strict consistency. For more information, see Solution 1: use low-precision TSO. - Combine small transactions into larger ones where possible. For more information, see Solution 2: parallel mode for TSO requests.
Solution 1: low-precision TSO
You can reduce TSO wait time by enabling the low-precision TSO feature (tidb_low_resolution_tso). After this feature is enabled, TiDB uses the cached timestamp to read data, reducing TSO wait time at the expense of potentially stale reads.
This optimization is particularly effective in the following scenarios:
- Read-heavy workloads where slight staleness is acceptable.
- Scenarios where reducing query latency is more important than absolute consistency.
- Applications that can tolerate reads that are a few seconds behind the latest committed state.
Benefits and trade-offs:
- Reduce query latency by enabling stale reads with a cached TSO, eliminating the need to request new timestamps.
- Balance performance against data consistency: this feature is only suitable for scenarios where stale reads are acceptable. It is not recommended to use it when strict data consistency is required.
To enable this optimization:
SET GLOBAL tidb_low_resolution_tso=ON;
Solution 2: parallel mode for TSO requests
The tidb_tso_client_rpc_mode system variable switches the mode in which TiDB sends TSO RPC requests to PD. The default value is DEFAULT. When the following conditions are met, you can consider switching this variable to PARALLEL or PARALLEL-FAST for potential performance improvements:
- TSO waiting time constitutes a significant portion of the total execution time of SQL queries.
- The TSO allocation in PD has not reached its bottleneck.
- PD and TiDB nodes have sufficient CPU resources.
- The network latency between TiDB and PD is significantly higher than the time PD takes to allocate TSO (that is, network latency accounts for the majority of TSO RPC duration).
- To get the duration of TSO RPC requests, check the PD TSO RPC Duration panel in the PD Client section of the Grafana TiDB dashboard.
- To get the duration of PD TSO allocation, check the PD server TSO handle duration panel in the TiDB section of the Grafana PD dashboard.
- The additional network traffic resulting from more TSO RPC requests between TiDB and PD (twice for
PARALLELor four times forPARALLEL-FAST) is acceptable.
To switch the parallel mode, execute the following command:
-- Use the PARALLEL mode
SET GLOBAL tidb_tso_client_rpc_mode=PARALLEL;
-- Use the PARALLEL-FAST mode
SET GLOBAL tidb_tso_client_rpc_mode=PARALLEL-FAST;
Tune coprocessor cache for read-heavy workloads
You can improve query performance for read-heavy workloads by optimizing the coprocessor cache. This cache stores the results of coprocessor requests, reducing repeated computations of frequently accessed data. To optimize cache performance, perform the following steps:
- Monitor the cache hit ratio using the metrics described in Coprocessor Cache.
- Increase the cache size to improve hit rates for larger working sets.
- Adjust the admission threshold based on query patterns.
The following lists some recommended settings for a read-heavy workload:
[tikv-client.copr-cache]
capacity-mb = 4096
admission-max-ranges = 5000
admission-max-result-mb = 10
admission-min-process-ms = 0
Optimize chunk size for workload characteristics
The tidb_max_chunk_size system variable sets the maximum number of rows in a chunk during the execution process. Adjusting this value based on your workload can improve performance.
For OLTP workloads with large concurrency and small transactions:
Set the value between
128and256rows (the default value is1024).This reduces memory usage and makes limit queries faster.
Use case: point queries, small range scans.
SET GLOBAL tidb_max_chunk_size = 128;
For OLAP or analytical workloads with complex queries and large result sets:
Set the value between
1024and4096rows.This increases throughput when scanning large amounts of data.
Use case: aggregations, large table scans.
SET GLOBAL tidb_max_chunk_size = 4096;
Optimize transaction mode and DML type for different workloads
TiDB provides different transaction modes and DML execution types to optimize performance for various workload patterns.
Transaction modes
You can set the transaction mode using the tidb_txn_mode system variable.
Pessimistic transaction mode (default):
- Suitable for general workloads with potential write conflicts.
- Provides stronger consistency guarantees.
SET SESSION tidb_txn_mode = "pessimistic";- Suitable for workloads with minimal write conflicts.
- Better performance for multi-statement transactions.
- Example:
BEGIN; INSERT...; INSERT...; COMMIT;.
SET SESSION tidb_txn_mode = "optimistic";
DML types
You can control the execution mode of DML statements using the tidb_dml_type system variable, which is introduced in v8.0.0.
To use the bulk DML execution mode, set tidb_dml_type to "bulk". This mode optimizes bulk data loading without conflicts and reduces memory usage during large write operations. Before using this mode, ensure that:
autocommitis enabled.- The
pessimistic-auto-commitconfiguration item is set tofalse.
SET SESSION tidb_dml_type = "bulk";
Optimize GROUP BY and DISTINCT operations with TiKV pushdown
TiDB pushes down aggregation operations to TiKV to reduce data transfer and processing overhead. The performance improvement varies based on your data characteristics.
Usage scenarios
Ideal scenarios (high performance gain):
- Columns containing few distinct values (low NDV).
- Data containing frequent duplicate values.
- Example: status columns, category codes, date parts.
Non-ideal scenarios (potential performance loss):
- Columns containing mostly unique values (high NDV).
- Unique identifiers or timestamps.
- Example: User IDs, transaction IDs.
Configuration
Enable pushdown optimizations at the session or global level:
-- Enable regular aggregation pushdown
SET GLOBAL tidb_opt_agg_push_down = ON;
-- Enable distinct aggregation pushdown
SET GLOBAL tidb_opt_distinct_agg_push_down = ON;
Mitigate MVCC version accumulation using in-memory engine
Excessive MVCC versions can cause performance bottlenecks, particularly in high read/write areas or due to issues with garbage collection and compaction. You can use the TiKV MVCC In-Memory Engine (IME) introduced in v8.5.0 to mitigate this issue. To enable it, add the following configuration to your TiKV configuration file.
[in-memory-engine]
enable = true
Optimize statistics collection during batch operations
You can optimize performance during batch operations while maintaining query optimization by managing statistics collection. This section describes how to manage this process effectively.
When to disable auto analyze
You can disable auto analyze by setting the tidb_enable_auto_analyze system variable to OFF in the following scenarios:
- During large data imports.
- During bulk update operations.
- For time-sensitive batch processing.
- When you need full control over the timing of statistics collection.
Best practices
Before the batch operation:
-- Disable auto analyze SET GLOBAL tidb_enable_auto_analyze = OFF;After the batch operation:
-- Manually collect statistics ANALYZE TABLE your_table; -- Re-enable auto analyze SET GLOBAL tidb_enable_auto_analyze = ON;
Optimize thread pool settings for different instance types
To improve TiKV performance, configure the thread pools based on your instance's CPU resources. The following guidelines help you optimize these settings:
For instances with 8 to 16 cores, the default settings are typically sufficient.
For instances with 32 or more cores, increase the pool sizes for better resource utilization. Adjust the settings as follows:
[server] # Increase gRPC thread pool grpc-concurrency = 10 [raftstore] # Optimize for write-intensive workloads apply-pool-size = 4 store-pool-size = 4 store-io-pool-size = 2