TiDB Optimistic Transaction Model
With optimistic transactions, conflicting changes are detected as part of a transaction commit. This helps improve the performance when concurrent transactions are infrequently modifying the same rows, because the process of acquiring row locks can be skipped. In the case that concurrent transactions frequently modify the same rows (a conflict), optimistic transactions might perform worse than pessimistic transactions.
Before enabling optimistic transactions, make sure that your application correctly handles that a COMMIT statement could return errors. If you are unsure of how your application handles this, it is recommended to instead use Pessimistic Transactions.
Principles of optimistic transactions
To support distributed transactions, TiDB adopts two-phase commit (2PC) in optimistic transactions. The procedure is as follows:
The client begins a transaction.
TiDB gets a timestamp (monotonically increasing in time and globally unique) from PD as the unique transaction ID of the current transaction, which is called
start_ts. TiDB implements multi-version concurrency control, sostart_tsalso serves as the version of the database snapshot obtained by this transaction. This means that the transaction can only read the data from the database atstart_ts.The client issues a read request.
- TiDB receives routing information (how data is distributed among TiKV nodes) from PD.
- TiDB receives the data of the
start_tsversion from TiKV.
The client issues a write request.
TiDB checks whether the written data satisfies constraints (to ensure the data types are correct, the NOT NULL constraint is met). Valid data is stored in the private memory of this transaction in TiDB.
The client issues a commit request.
TiDB begins 2PC, and persists data in store while guaranteeing the atomicity of transactions.
- TiDB selects a Primary Key from the data to be written.
- TiDB receives the information of Region distribution from PD, and groups all keys by Region accordingly.
- TiDB sends prewrite requests to all TiKV nodes involved. Then, TiKV checks whether there are conflict or expired versions. Valid data is locked.
- TiDB receives all responses in the prewrite phase and the prewrite is successful.
- TiDB receives a commit version number from PD and marks it as
commit_ts. - TiDB initiates the second commit to the TiKV node where Primary Key is located. TiKV checks the data, and cleans the locks left in the prewrite phase.
- TiDB receives the message that reports the second phase is successfully finished.
TiDB returns a message to inform the client that the transaction is successfully committed.
TiDB asynchronously cleans the locks left in this transaction.
Advantages and disadvantages
From the process of transactions in TiDB above, it is clear that TiDB transactions have the following advantages:
- Simple to understand
- Implement cross-node transaction based on single-row transaction
- Decentralized lock management
However, TiDB transactions also have the following disadvantages:
- Transaction latency due to 2PC
- In need of a centralized timestamp allocation service
- OOM (out of memory) when extensive data is written in the memory
Transaction retries
In the optimistic transaction model, transactions might fail to be committed because of write–write conflict in heavy contention scenarios. Starting from v3.0.8, TiDB uses the pessimistic transaction mode by default, the same as MySQL. This means that TiDB and MySQL add locks during the execution of write-type SQL statements, and its Repeatable Read isolation level allows for current reads, so commits generally do not encounter exceptions.
Automatic retry
If a write-write conflict occurs during the transaction commit, TiDB automatically retries the SQL statement that includes write operations. You can enable the automatic retry by setting tidb_disable_txn_auto_retry to OFF and set the retry limit by configuring tidb_retry_limit:
# Whether to disable automatic retry. ("on" by default)
tidb_disable_txn_auto_retry = OFF
# Set the maximum number of the retires. ("10" by default)
# When "tidb_retry_limit = 0", automatic retry is completely disabled.
tidb_retry_limit = 10
You can enable the automatic retry in either session level or global level:
Session level:
SET tidb_disable_txn_auto_retry = OFF;SET tidb_retry_limit = 10;Global level:
SET GLOBAL tidb_disable_txn_auto_retry = OFF;SET GLOBAL tidb_retry_limit = 10;
Limits of retry
By default, TiDB will not retry transactions because this might lead to lost updates and damaged REPEATABLE READ isolation.
The reason can be observed from the procedures of retry:
- Allocate a new timestamp and mark it as
start_ts. - Retry the SQL statements that contain write operations.
- Implement the two-phase commit.
In Step 2, TiDB only retries SQL statements that contain write operations. However, during retrying, TiDB receives a new version number to mark the beginning of the transaction. This means that TiDB retries SQL statements with the data in the new start_ts version. In this case, if the transaction updates data using other query results, the results might be inconsistent because the REPEATABLE READ isolation is violated.
If your application can tolerate lost updates, and does not require REPEATABLE READ isolation consistency, you can enable this feature by setting tidb_disable_txn_auto_retry = OFF.
Conflict detection
As a distributed database, TiDB performs in-memory conflict detection in the TiKV layer, mainly in the prewrite phase. TiDB instances are stateless and unaware of each other, which means they cannot know whether their writes result in conflicts across the cluster. Therefore, conflict detection is performed in the TiKV layer.
The configuration is as follows:
# Controls the number of slots. ("2048000" by default)
scheduler-concurrency = 2048000
In addition, TiKV supports monitoring the time spent on waiting latches in the scheduler.
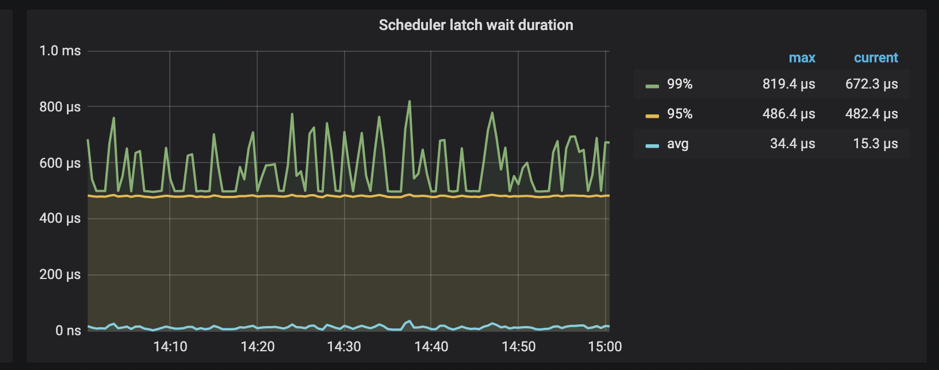
When Scheduler latch wait duration is high and there are no slow writes, it can be safely concluded that there are many write conflicts at this time.