Integrate Data with Confluent Cloud, Snowflake, ksqlDB, and SQL Server
Confluent is an Apache Kafka-compatible streaming data platform that provides strong data integration capabilities. On this platform, you can access, store, and manage non-stop real-time streaming data.
Starting from TiDB v6.1.0, TiCDC supports replicating incremental data to Confluent in Avro format. This document introduces how to replicate TiDB incremental data to Confluent using TiCDC, and further replicate data to Snowflake, ksqlDB, and SQL Server via Confluent Cloud. The organization of this document is as follows:
- Quickly deploy a TiDB cluster with TiCDC included.
- Create a changefeed that replicates data from TiDB to Confluent Cloud.
- Create Connectors that replicate data from Confluent Cloud to Snowflake, ksqlDB, and SQL Server.
- Write data to TiDB using go-tpc, and observe data changes in Snowflake, ksqlDB, and SQL Server.
The preceding steps are performed in a lab environment. You can also deploy a cluster in a production environment by referring to these steps.
Replicate incremental data to Confluent Cloud
Step 1. Set up the environment
Deploy a TiDB cluster with TiCDC included.
In a lab or testing environment, you can deploy a TiDB cluster with TiCDC included quickly by using TiUP Playground.
tiup playground --host 0.0.0.0 --db 1 --pd 1 --kv 1 --tiflash 0 --ticdc 1 # View cluster status tiup statusIf TiUP is not installed yet, refer to Install TiUP. In a production environment, you can deploy a TiCDC as instructed in Deploy TiCDC.
Register Confluent Cloud and create a Confluent cluster.
Create a Basic cluster and make it accessible via Internet. For details, see Quick Start for Confluent Cloud.
Step 2. Create an access key pair
Create a cluster API key.
Sign in to Confluent Cloud. Choose Data integration > API keys > Create key. On the Select scope for API key page that is displayed, select Global access.
After creation, a key pair file is generated, as shown below.
=== Confluent Cloud API key: xxx-xxxxx === API key: L5WWA4GK4NAT2EQV API secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Bootstrap server: xxx-xxxxx.ap-east-1.aws.confluent.cloud:9092Record the Schema Registry Endpoints.
In the Confluent Cloud Console, choose Schema Registry > API endpoint. Record the Schema Registry Endpoints. The following is an example:
https://yyy-yyyyy.us-east-2.aws.confluent.cloudCreate a Schema Registry API key.
In the Confluent Cloud Console, choose Schema Registry > API credentials. Click Edit and then Create key.
After creation, a key pair file is generated, as shown below:
=== Confluent Cloud API key: yyy-yyyyy === API key: 7NBH2CAFM2LMGTH7 API secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxYou can also perform this step by using Confluent CLI. For details, see Connect Confluent CLI to Confluent Cloud Cluster.
Step 3. Create a Kafka changefeed
Create a changefeed configuration file.
As required by Avro and Confluent Connector, incremental data of each table must be sent to an independent topic, and a partition must be dispatched for each event based on the primary key value. Therefore, you need to create a changefeed configuration file
changefeed.confwith the following contents:[sink] dispatchers = [ {matcher = ['*.*'], topic = "tidb_{schema}_{table}", partition="index-value"}, ]For detailed description of
dispatchersin the configuration file, see Customize the rules for Topic and Partition dispatchers of Kafka Sink.Create a changefeed to replicate incremental data to Confluent Cloud:
tiup cdc:v<CLUSTER_VERSION> cli changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://<broker_endpoint>/ticdc-meta?protocol=avro&replication-factor=3&enable-tls=true&auto-create-topic=true&sasl-mechanism=plain&sasl-user=<broker_api_key>&sasl-password=<broker_api_secret>" --schema-registry="https://<schema_registry_api_key>:<schema_registry_api_secret>@<schema_registry_endpoint>" --changefeed-id="confluent-changefeed" --config changefeed.confYou need to replace the values of the following fields with those created or recorded in Step 2. Create an access key pair:
<broker_endpoint><broker_api_key><broker_api_secret><schema_registry_api_key><schema_registry_api_secret><schema_registry_endpoint>
Note that you should encode
<schema_registry_api_secret>based on HTML URL Encoding Reference before replacing its value. After you replace all the preceding fields, the configuration file is as follows:tiup cdc:v<CLUSTER_VERSION> cli changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://xxx-xxxxx.ap-east-1.aws.confluent.cloud:9092/ticdc-meta?protocol=avro&replication-factor=3&enable-tls=true&auto-create-topic=true&sasl-mechanism=plain&sasl-user=L5WWA4GK4NAT2EQV&sasl-password=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" --schema-registry="https://7NBH2CAFM2LMGTH7:xxxxxxxxxxxxxxxxxx@yyy-yyyyy.us-east-2.aws.confluent.cloud" --changefeed-id="confluent-changefeed" --config changefeed.confRun the command to create a changefeed.
If the changefeed is successfully created, changefeed information, such as changefeed ID, is displayed, as shown below:
Create changefeed successfully! ID: confluent-changefeed Info: {... changfeed info json struct ...}If no result is returned after you run the command, check the network connectivity between the server where you run the command and Confluent Cloud. For details, see Test connectivity to Confluent Cloud.
After creating the changefeed, run the following command to check the changefeed status:
tiup cdc:v<CLUSTER_VERSION> cli changefeed list --server="http://127.0.0.1:8300"You can refer to Manage TiCDC Changefeeds to manage the changefeed.
Step 4. Write data to generate change logs
After the preceding steps are done, TiCDC sends change logs of incremental data in the TiDB cluster to Confluent Cloud. This section describes how to write data into TiDB to generate change logs.
Simulate service workload.
To generate change logs in a lab environment, you can use go-tpc to write data to the TiDB cluster. Specifically, run the following command to create a database
tpccin the TiDB cluster. Then, use TiUP bench to write data to this new database.tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 prepare tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 run --time 300sFor more details about go-tpc, refer to How to Run TPC-C Test on TiDB.
Observe data in Confluent Cloud.
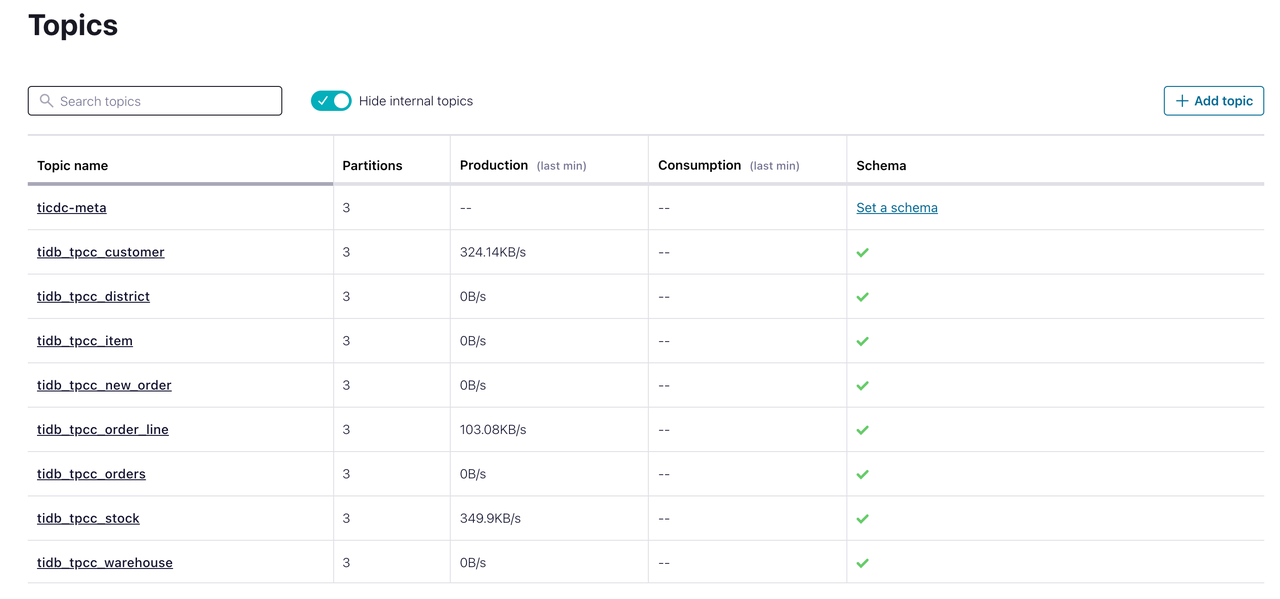
In the Confluent Cloud Console, click Topics. You can see that the target topics have been created and are receiving data. At this time, incremental data of the TiDB database is successfully replicated to Confluent Cloud.
Integrate data with Snowflake
Snowflake is a cloud native data warehouse. With Confluent, you can replicate TiDB incremental data to Snowflake by creating Snowflake Sink Connectors.
Prerequisites
- You have registered and created a Snowflake cluster. See Getting Started with Snowflake.
- Before connecting to the Snowflake cluster, you have generated a private key for it. See Key Pair Authentication & Key Pair Rotation.
Integration procedure
Create a database and a schema in Snowflake.
In the Snowflake control console, choose Data > Database. Create a database named
TPCCand a schema namedTiCDC.In the Confluent Cloud Console, choose Data integration > Connectors > Snowflake Sink. The page shown below is displayed.

Select the topic you want to replicate to Snowflake. Then go to the next page.
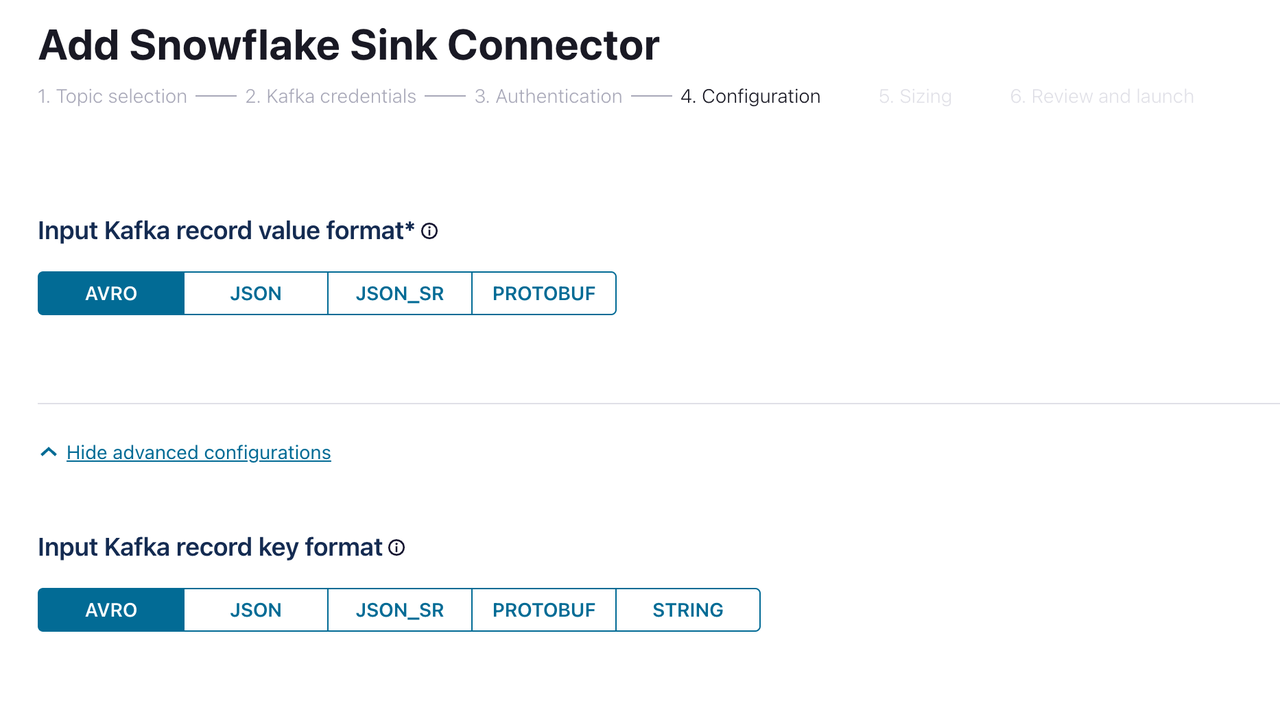
Specify the authentication information for connecting Snowflake. Fill in Database name and Schema name with the values you created in the previous step. Then go to the next page.
On the Configuration page, select
AVROfor both Input Kafka record value format and Input Kafka record key format. Then click Continue. Wait until the connector is created and the status becomes Running, which might take several minutes.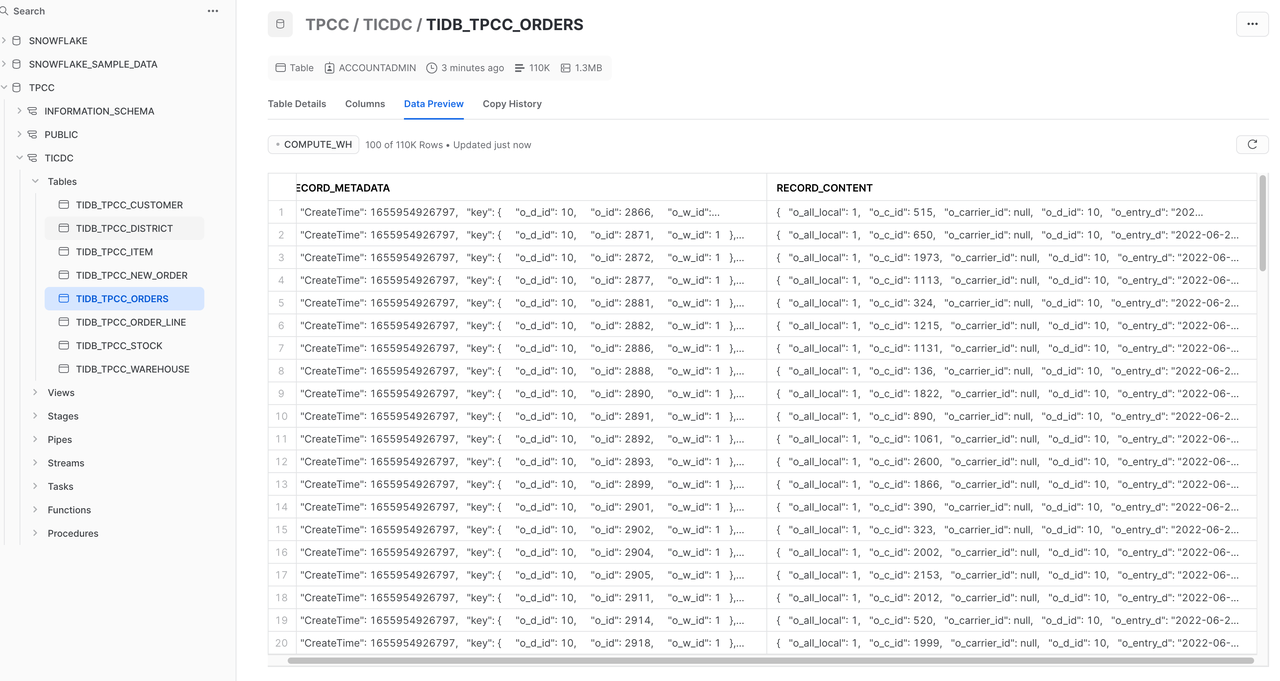
In the Snowflake console, choose Data > Database > TPCC > TiCDC. You can see that TiDB incremental data has been replicated to Snowflake. Data integration with Snowflake is done (see the preceding figure). However, the table structure in Snowflake is different from that in TiDB, and data is inserted into Snowflake incrementally. In most scenarios, you expect the data in Snowflake to be a replica of the data in TiDB, rather than storing TiDB change logs. This problem will be addressed in the next section.
Create data replicas of TiDB tables in Snowflake
In the previous section, the change logs of TiDB incremental data have been replicated to Snowflake. This section describes how to process these change logs using the TASK and STREAM features of Snowflake according to the event type of INSERT, UPDATE, and DELETE, and then write them to a table with the same structure as that in upstream, thereby creating a data replica of the TiDB table in Snowflake. The following takes the ITEM table as an example.
The structure of the ITEM table is as follows:
CREATE TABLE `item` (
`i_id` int NOT NULL,
`i_im_id` int DEFAULT NULL,
`i_name` varchar(24) DEFAULT NULL,
`i_price` decimal(5,2) DEFAULT NULL,
`i_data` varchar(50) DEFAULT NULL,
PRIMARY KEY (`i_id`)
);
In Snowflake, there is a table named TIDB_TEST_ITEM, which is automatically created by the Confluent Snowflake Sink Connector. The table structure is as follows:
create or replace TABLE TIDB_TEST_ITEM (
RECORD_METADATA VARIANT,
RECORD_CONTENT VARIANT
);
In Snowflake, create a table with the same structure as that in TiDB:
create or replace table TEST_ITEM ( i_id INTEGER primary key, i_im_id INTEGER, i_name VARCHAR, i_price DECIMAL(36,2), i_data VARCHAR );Create a stream for
TIDB_TEST_ITEMand setappend_onlytotrueas follows.create or replace stream TEST_ITEM_STREAM on table TIDB_TEST_ITEM append_only=true;In this way, the created stream captures only
INSERTevents in real time. Specifically, when a new change log is generated forITEMin TiDB, the change log will be inserted intoTIDB_TEST_ITEMand be captured by the stream.Process the data in the stream. According to the event type, insert, update, or delete the stream data in the
TEST_ITEMtable.--Merge data into the TEST_ITEM table merge into TEST_ITEM n using -- Query TEST_ITEM_STREAM (SELECT RECORD_METADATA:key as k, RECORD_CONTENT:val as v from TEST_ITEM_STREAM) stm -- Match the stream with table on the condition that i_id is equal on k:i_id = n.i_id -- If the TEST_ITEM table contains a record that matches i_id and v is empty, delete this record when matched and IS_NULL_VALUE(v) = true then delete -- If the TEST_ITEM table contains a record that matches i_id and v is not empty, update this record when matched and IS_NULL_VALUE(v) = false then update set n.i_data = v:i_data, n.i_im_id = v:i_im_id, n.i_name = v:i_name, n.i_price = v:i_price -- If the TEST_ITEM table does not contain a record that matches i_id, insert this record when not matched then insert (i_data, i_id, i_im_id, i_name, i_price) values (v:i_data, v:i_id, v:i_im_id, v:i_name, v:i_price) ;In the preceding example, the
MERGE INTOstatement of Snowflake is used to match the stream and the table on a specific condition, and then execute corresponding operations, such as deleting, updating, or inserting a record. In this example, threeWHEREclauses are used for the following three scenarios:- Delete the record in the table when the stream and the table match and the data in the stream is empty.
- Update the record in the table when the stream and the table match and the data in the stream is not empty.
- Insert the record in the table when the stream and the table do not match.
Periodically execute the statement in Step 3 to ensure that data is always up-to-date. You can also use the
SCHEDULED TASKfeature of Snowflake:-- Create a TASK to periodically execute the MERGE INTO statement create or replace task STREAM_TO_ITEM warehouse = test -- Execute the TASK every minute schedule = '1 minute' when -- Skip the TASK when there is no data in TEST_ITEM_STREAM system$stream_has_data('TEST_ITEM_STREAM') as -- Merge data into the TEST_ITEM table. The statement is the same as that in the preceding example merge into TEST_ITEM n using (select RECORD_METADATA:key as k, RECORD_CONTENT:val as v from TEST_ITEM_STREAM) stm on k:i_id = n.i_id when matched and IS_NULL_VALUE(v) = true then delete when matched and IS_NULL_VALUE(v) = false then update set n.i_data = v:i_data, n.i_im_id = v:i_im_id, n.i_name = v:i_name, n.i_price = v:i_price when not matched then insert (i_data, i_id, i_im_id, i_name, i_price) values (v:i_data, v:i_id, v:i_im_id, v:i_name, v:i_price) ;
At this time, you have established a data channel with certain ETL capabilities. Through this data channel, you can replicate TiDB's incremental data change logs to Snowflake, maintain a data replica of TiDB, and use the data in Snowflake.
The last step is to regularly clean up the useless data in the TIDB_TEST_ITEM table:
-- Clean up the TIDB_TEST_ITEM table every two hours
create or replace task TRUNCATE_TIDB_TEST_ITEM
warehouse = test
schedule = '120 minute'
when
system$stream_has_data('TIDB_TEST_ITEM')
as
TRUNCATE table TIDB_TEST_ITEM;
Integrate data with ksqlDB
ksqlDB is a database purpose-built for stream processing applications. You can create ksqlDB clusters on Confluent Cloud and access incremental data replicated by TiCDC.
Select ksqlDB in the Confluent Cloud Console and create a ksqlDB cluster as instructed.
Wait until the ksqlDB cluster status is Running. This process takes several minutes.
In the ksqlDB Editor, run the following command to create a stream to access the
tidb_tpcc_orderstopic:CREATE STREAM orders (o_id INTEGER, o_d_id INTEGER, o_w_id INTEGER, o_c_id INTEGER, o_entry_d STRING, o_carrier_id INTEGER, o_ol_cnt INTEGER, o_all_local INTEGER) WITH (kafka_topic='tidb_tpcc_orders', partitions=3, value_format='AVRO');Run the following command to check the orders STREAM data:
SELECT * FROM ORDERS EMIT CHANGES;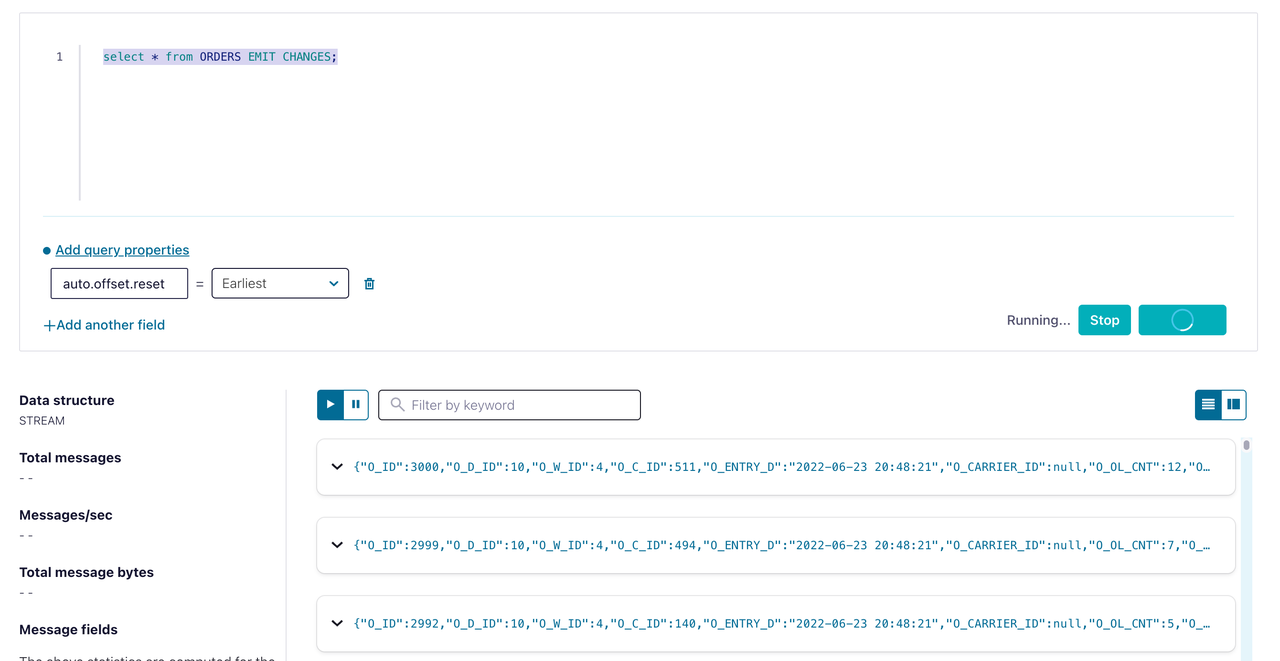
You can see that the incremental data has been replicated to ksqlDB, as shown in the preceding figure. Data integration with ksqlDB is done.
Integrate data with SQL Server
Microsoft SQL Server is a relational database management system (RDBMS) developed by Microsoft. With Confluent, you can replicate TiDB incremental data to SQL Server by creating SQL Server Sink Connectors.
Connect to SQL Server and create a database named
tpcc.[ec2-user@ip-172-1-1-1 bin]$ sqlcmd -S 10.61.43.14,1433 -U admin Password: 1> create database tpcc 2> go 1> select name from master.dbo.sysdatabases 2> go name ---------------------------------------------------------------------- master tempdb model msdb rdsadmin tpcc (6 rows affected)In the Confluent Cloud Console, choose Data integration > Connectors > Microsoft SQL Server Sink. The page shown below is displayed.
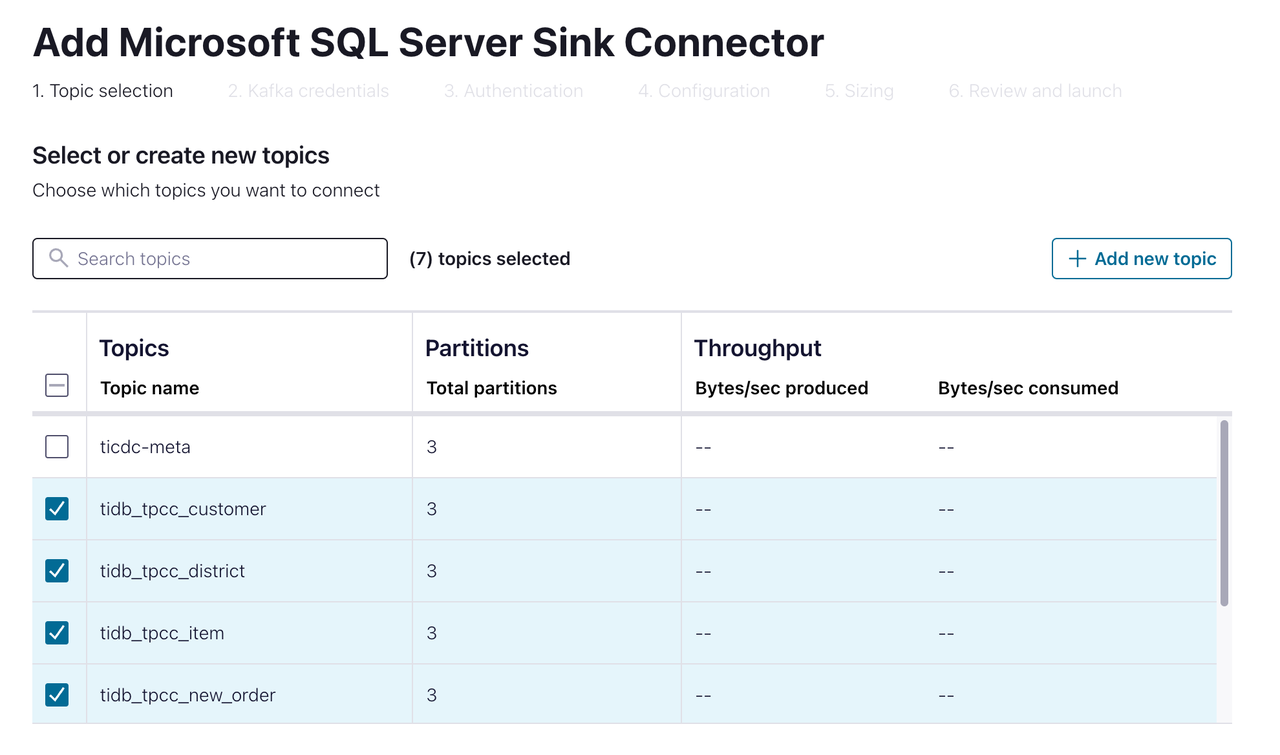
Select the topic you want to replicate to SQL Server. Then go to the next page.
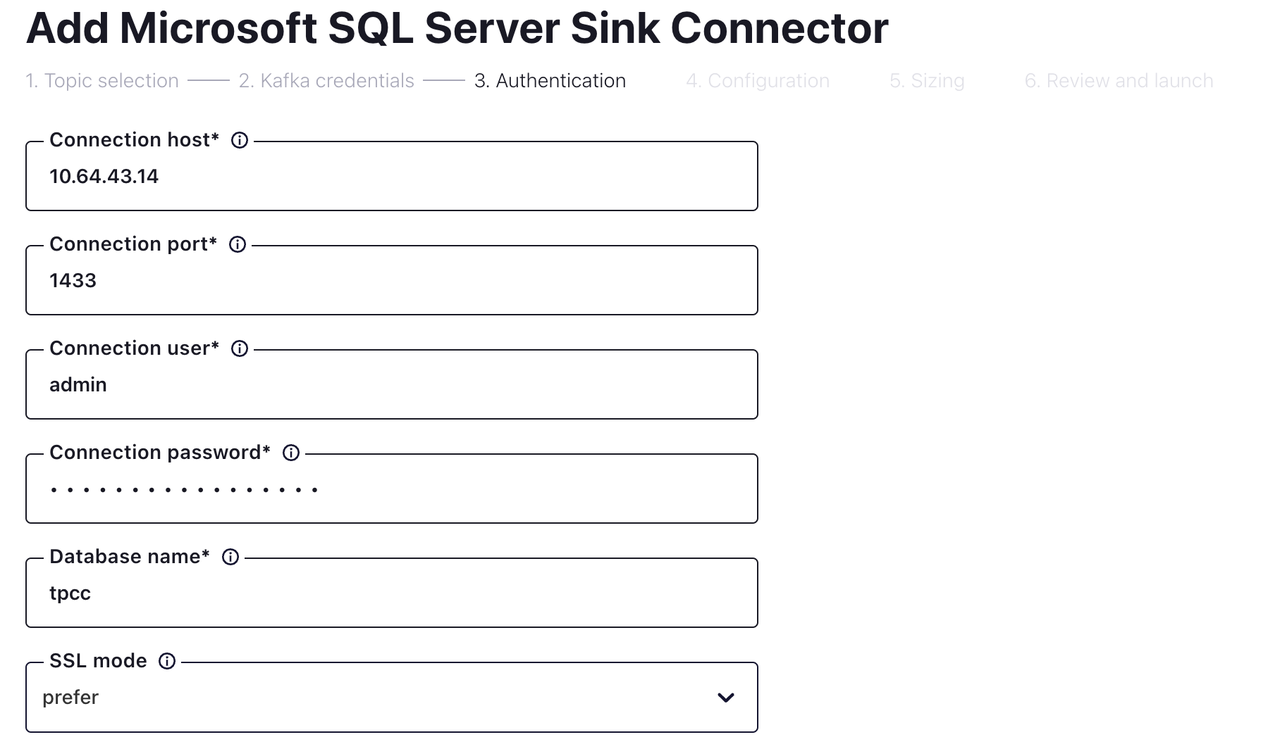
Fill in the connection and authentication information. Then go to the next page.
On the Configuration page, configure the following fields and click Continue.
After configuration, click Continue. Wait until the connector status becomes Running, which might take several minutes.
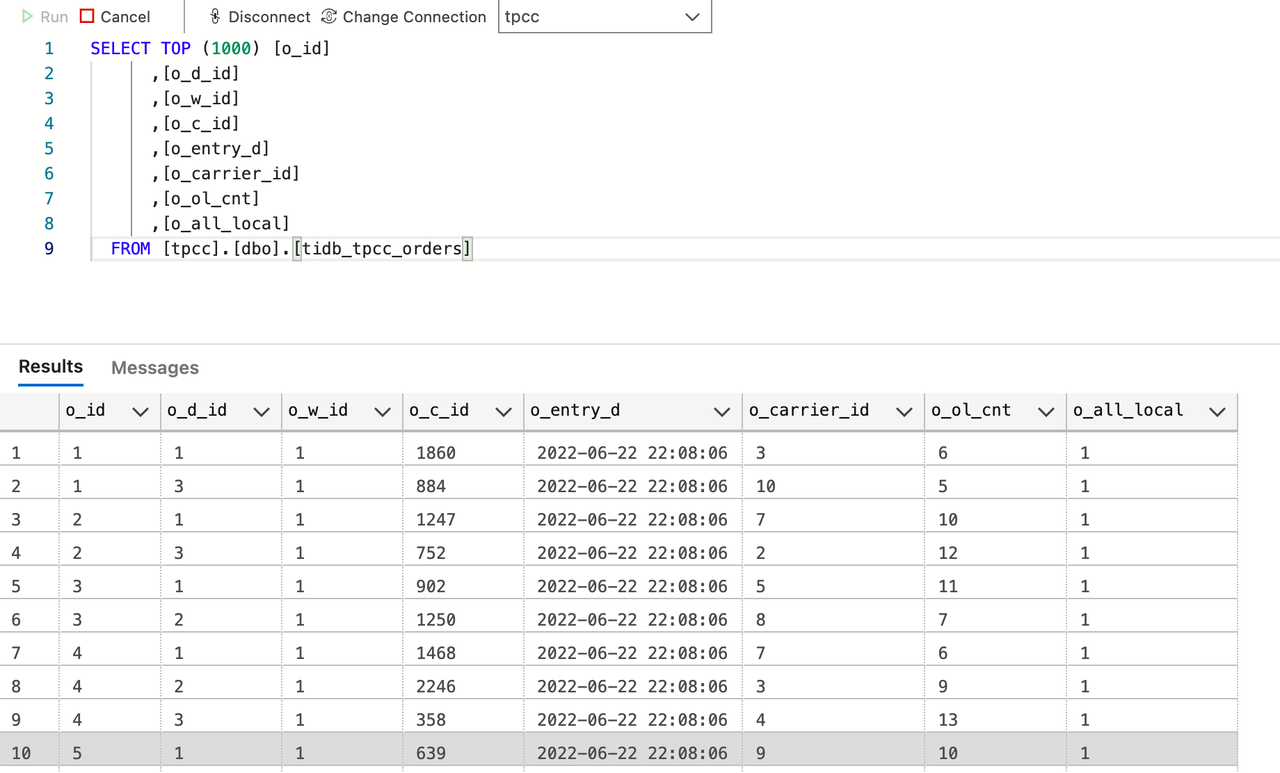
Connect SQL Server and observe the data. You can see that the incremental data has been replicated to SQL Server, as shown in the preceding figure. Data integration with SQL Server is done.