グローバルインデックス
グローバルインデックスを導入する前、TiDBはパーティションごとにローカルインデックスを作成していました。つまり、パーティションごとに制限のローカルインデックスが作成されていました。このインデックス作成アプローチでは、データのグローバルな一意性を保証するために、主キーと一意キーにすべてのパーティションキーを含める必要がありました。さらに、クエリが複数のパーティションにまたがるデータにアクセスする必要がある場合、TiDBは結果を返すために各パーティションのデータをスキャンする必要がありました。
これらの問題に対処するため、TiDBはバージョン8.3.0でグローバルインデックス機能を導入しました。単一のグローバルインデックスでテーブル全体のデータをカバーするため、パーティションキーが含まれていない場合でも、主キーと一意キーはグローバルに一意に保たれます。さらに、グローバルインデックスを使用すると、TiDBは各パーティションのローカルインデックスを参照することなく、複数のパーティションにまたがるインデックスデータに単一の操作でアクセスできます。これにより、パーティションキー以外のキーに対するクエリパフォーマンスが大幅に向上します。v8.5.4以降では、一意でないインデックスもグローバルインデックスとして作成できます。
利点
グローバル インデックスを使用すると、クエリのパフォーマンスが大幅に向上し、インデックスの柔軟性が高まり、データの移行とアプリケーションの変更にかかるコストが削減されます。
クエリパフォーマンスの向上
グローバルインデックスは、非パーティション列へのクエリの効率を効果的に向上させます。クエリに非パーティション列が含まれる場合、グローバルインデックスは関連データを迅速に特定できるため、すべてのパーティションにわたるフルテーブルスキャンを回避できます。これにより、コプロセッサー(COP)タスクの数が大幅に削減され、特にパーティション数が多いシナリオで大きな効果を発揮します。
ベンチマーク テストでは、テーブルに 100 個のパーティションが含まれている場合、sysbench select_random_pointsシナリオでのパフォーマンスが最大 53 倍向上することが示されています。
強化されたインデックスの柔軟性
グローバルインデックスにより、パーティションテーブルの一意のキーにはすべてのパーティション列が含まれていなければならないという制約がなくなります。これにより、インデックス設計の柔軟性が向上します。パーティションスキームに制約されることなく、実際のクエリパターンとビジネスロジックに基づいてインデックスを作成できるようになります。この柔軟性は、クエリパフォーマンスを向上させるだけでなく、より幅広いアプリケーション要件に対応できるようになります。
データ移行とアプリケーション変更にかかるコストの削減
データ移行やアプリケーションの変更時に、グローバルインデックスを使用することで、追加の調整作業を大幅に削減できます。グローバルインデックスがない場合、パーティションスキームを変更したり、インデックスの制限を回避するためにSQLクエリを書き直したりする必要があるかもしれません。グローバルインデックスを使用すれば、こうした変更を回避でき、開発コストと保守コストの両方を削減できます。
例えば、OracleデータベースからTiDBにテーブルを移行する場合、Oracleはグローバルインデックスをサポートしているため、パーティション列を含まない一意のインデックスが使用されることがあります。TiDBがグローバルインデックスを導入する前は、TiDBのパーティションルールに準拠するようにテーブルスキーマを変更する必要がありました。現在、TiDBはグローバルインデックスをサポートしています。データを移行する際には、これらのインデックスをグローバルとして定義するだけで済み、スキーマの動作をOracleと一貫性のあるものにすることができ、移行コストを大幅に削減できます。
グローバルインデックスの制限
- インデックス定義で
GLOBALキーワードが明示的に指定されていない場合、TiDB はデフォルトでローカル インデックスを作成します。 - キーワード
GLOBALとLOCALはパーティションテーブルにのみ適用され、非パーティションテーブルには影響しません。つまり、非パーティションテーブルでは、グローバルインデックスとローカルインデックスに違いはありません。 DROP PARTITIONREORGANIZE PARTITIONの DDL 操作も、グローバルインデックスの更新をトリガーします。これらの DDL 操作はTRUNCATE PARTITION結果を返す前にグローバルインデックスの更新が完了するのを待つ必要があるため、実行時間が長くなります。これは、DROP PARTITIONやTRUNCATE PARTITIONなどのデータアーカイブのシナリオで特に顕著です。グローバルインデックスがない場合、これらの操作は通常すぐに完了します。しかし、グローバルインデックスがある場合、更新が必要なインデックスの数が増えるにつれて実行時間が長くなります。- グローバル インデックスを含むテーブルは
EXCHANGE PARTITION操作をサポートしません。 - デフォルトでは、パーティションテーブルの主キーはクラスター化インデックスであり、パーティションキーを含める必要があります。主キーからパーティションキーを除外する必要がある場合は、テーブル作成時に主キーを非クラスター化グローバルインデックスとして明示的に指定できます(例:
PRIMARY KEY(col1, col2) NONCLUSTERED GLOBAL)。 - 式列にグローバル インデックスが追加された場合、またはグローバル インデックスがプレフィックス インデックスでもある場合 (たとえば
UNIQUE KEY idx_id_prefix (id(10)) GLOBAL)、このグローバル インデックスの統計を手動で収集する必要があります。
機能の進化
- v7.6.0より前:TiDBはパーティションテーブル上のローカルインデックスのみをサポートします。つまり、パーティションテーブルの一意キーには、パーティション式内のすべての列を含める必要があります。パーティションキーを使用しないクエリはすべてのパーティションをスキャンする必要があり、クエリパフォーマンスが低下します。
- v7.6.0 : グローバルインデックスを有効にするシステム変数
tidb_enable_global_indexが導入されました。ただし、この機能は現時点ではまだ開発中であり、本番での使用は推奨されません。 - v8.3.0 : グローバルインデックスが実験的機能としてリリースされました。インデックスを定義する際に
GLOBALキーワードを使用することで、明示的にグローバルインデックスを作成できます。 - v8.4.0 : グローバルインデックス機能が一般提供(GA)されました。システム変数
tidb_enable_global_indexを設定せずに、キーワードGLOBALを使って直接グローバルインデックスを作成できます。このバージョン以降、システム変数 4 は非推奨となり、値はONに固定されます。つまり、グローバルインデックスはデフォルトで有効になります。 - v8.5.0 : グローバル インデックスは、パーティション式のすべての列を含めることをサポートします。
グローバルインデックスとローカルインデックス
次の図は、グローバル インデックスとローカル インデックスの違いを示しています。
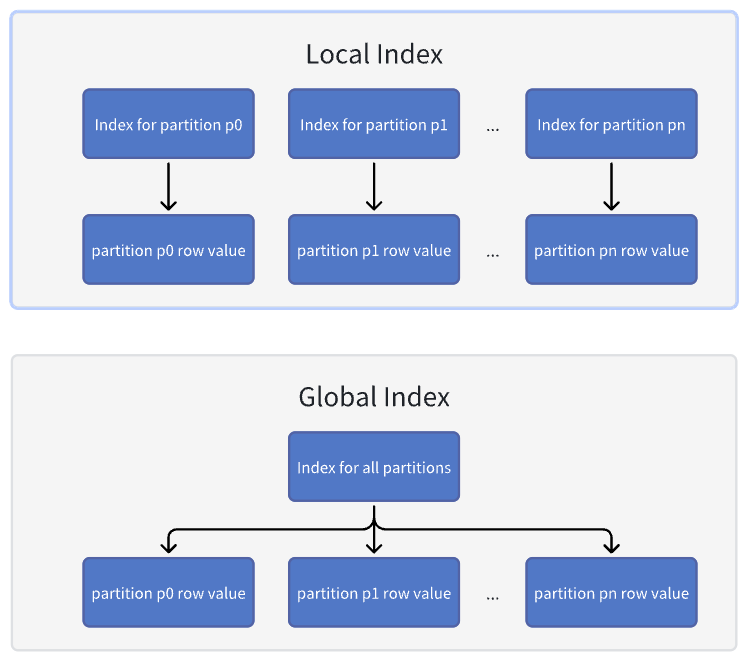
グローバルインデックスのシナリオ:
- 頻度の低いデータアーカイブ:例えば、医療業界では、一部のビジネスデータは最大30年間保持する必要があります。このようなデータは月ごとにパーティション分割されることが多く、一度に360個のパーティションが作成され、その後
DROP~TRUNCATE操作が発生することは非常にまれです。このようなシナリオでは、パーティション間の一貫性とクエリパフォーマンスの向上を実現するグローバルインデックスの方が適しています。 - 複数のパーティションにまたがるクエリ: クエリが複数のパーティションにわたるデータにアクセスする必要がある場合、グローバル インデックスを使用すると、すべてのパーティションにわたるフル スキャンを回避し、クエリの効率を高めることができます。
ローカルインデックスのシナリオ:
- 頻繁なデータ アーカイブ: データ アーカイブ操作が頻繁に発生し、ほとんどのクエリが単一のパーティションに制限されている場合は、ローカル インデックスの方がパフォーマンスが向上します。
- パーティション交換の使用:銀行などの業界では、処理済みのデータをまず通常のテーブルに書き込み、検証後にパーティションテーブルに交換することで、パーティションテーブルへのパフォーマンスへの影響を最小限に抑える場合があります。この場合、グローバルインデックスを使用するとパーティションテーブルはパーティション交換をサポートしなくなるため、ローカルインデックスが推奨されます。
グローバルインデックスとクラスター化インデックス
クラスター化インデックスとグローバルインデックスの根本的な制約により、1つのインデックスをクラスター化インデックスとグローバルインデックスの両方の機能を同時に使用することはできません。ただし、それぞれのインデックスは、クエリシナリオに応じて異なるパフォーマンス上のメリットをもたらします。両方のメリットを活用する必要がある場合は、パーティション列をクラスター化インデックスに含め、パーティション列を含まない別のグローバルインデックスを作成することができます。
次のようなテーブル スキーマがあるとします。
CREATE TABLE `t` (
`id` int DEFAULT NULL,
`ts` timestamp NULL DEFAULT NULL,
`data` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY RANGE (UNIX_TIMESTAMP(`ts`))
(PARTITION `p0` VALUES LESS THAN (1735660800)
PARTITION `p1` VALUES LESS THAN (1738339200)
...)
前述のテーブルtでは、列idに一意の値が含まれています。ポイントクエリと範囲クエリの両方を最適化するには、テーブル作成ステートメントでクラスター化インデックスPRIMARY KEY(id, ts)と、パーティション列を含まないグローバルインデックスUNIQUE KEY id(id)を定義します。これにより、 idに基づくポイントクエリはグローバルインデックスidを使用し、実行プランPointGetを選択します。範囲クエリではクラスター化インデックスが使用されます。これは、クラスター化インデックスはグローバルインデックスと比較して追加のテーブル参照を回避し、クエリ効率を向上させるためです。
変更されたテーブル スキーマは次のとおりです。
CREATE TABLE `t` (
`id` int NOT NULL,
`ts` timestamp NOT NULL,
`data` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`, `ts`) /*T![clustered_index] CLUSTERED */,
UNIQUE KEY `id` (`id`) /*T![global_index] GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY RANGE (UNIX_TIMESTAMP(`ts`))
(PARTITION `p0` VALUES LESS THAN (1735660800),
PARTITION `p1` VALUES LESS THAN (1738339200)
...)
このアプローチは、 idに基づいてポイント クエリを最適化すると同時に範囲クエリのパフォーマンスを向上させ、タイムスタンプ ベースのクエリでテーブルのパーティション列が効果的に利用されることを保証します。
使用法
グローバル インデックスを作成するには、インデックス定義にGLOBALキーワードを追加します。
注記:
グローバルインデックスはパーティション管理に影響します。1、3、または
REORGANIZE PARTITIONTRUNCATEを実行するとDROPテーブルレベルのグローバルインデックスの更新がトリガーされます。つまり、これらのDDL操作は、対応するグローバルインデックスの更新が完了した後にのみ返されるため、実行時間が長くなる可能性があります。
CREATE TABLE t1 (
col1 INT NOT NULL,
col2 DATE NOT NULL,
col3 INT NOT NULL,
col4 INT NOT NULL,
UNIQUE KEY uidx12(col1, col2) GLOBAL,
UNIQUE KEY uidx3(col3),
KEY idx1(col1) GLOBAL
)
PARTITION BY HASH(col3)
PARTITIONS 4;
前の例では、一意のインデックスuidx12と一意でないインデックスidx1はグローバル インデックスになりますが、 uidx3通常の一意のインデックスのままです。
クラスター化インデックスはグローバルインデックスにはなり得ないことに注意してください。例:
CREATE TABLE t2 (
col1 INT NOT NULL,
col2 DATE NOT NULL,
PRIMARY KEY (col2) CLUSTERED GLOBAL
) PARTITION BY HASH(col1) PARTITIONS 5;
ERROR 1503 (HY000): A CLUSTERED INDEX must include all columns in the table's partitioning function
クラスター化インデックスはグローバルインデックスとしても機能しません。これは、クラスター化インデックスをグローバルにすると、テーブルがパーティション化されなくなるためです。クラスター化インデックスのキーはパーティションレベルの行データのキーですが、グローバルインデックスはテーブルレベルで定義されるため、競合が発生します。主キーをグローバルインデックスにする必要がある場合は、明示的に非クラスター化インデックスとして定義する必要があります。例:
PRIMARY KEY(col1, col2) NONCLUSTERED GLOBAL
SHOW CREATE TABLEの出力でGLOBALインデックス オプションをチェックすることで、グローバル インデックスを識別できます。
SHOW CREATE TABLE t1\G
Table: t1
Create Table: CREATE TABLE `t1` (
`col1` int NOT NULL,
`col2` date NOT NULL,
`col3` int NOT NULL,
`col4` int NOT NULL,
UNIQUE KEY `uidx12` (`col1`,`col2`) /*T![global_index] GLOBAL */,
UNIQUE KEY `uidx3` (`col3`),
KEY `idx1` (`col1`) /*T![global_index] GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY HASH (`col3`) PARTITIONS 4
1 row in set (0.00 sec)
あるいは、 INFORMATION_SCHEMA.TIDB_INDEXESテーブルをクエリし、出力のIS_GLOBAL列をチェックしてグローバル インデックスを識別することもできます。
SELECT * FROM information_schema.tidb_indexes WHERE table_name='t1';
+--------------+------------+------------+----------+--------------+-------------+----------+---------------+------------+----------+------------+-----------+-----------+
| TABLE_SCHEMA | TABLE_NAME | NON_UNIQUE | KEY_NAME | SEQ_IN_INDEX | COLUMN_NAME | SUB_PART | INDEX_COMMENT | Expression | INDEX_ID | IS_VISIBLE | CLUSTERED | IS_GLOBAL |
+--------------+------------+------------+----------+--------------+-------------+----------+---------------+------------+----------+------------+-----------+-----------+
| test | t1 | 0 | uidx12 | 1 | col1 | NULL | | NULL | 1 | YES | NO | 1 |
| test | t1 | 0 | uidx12 | 2 | col2 | NULL | | NULL | 1 | YES | NO | 1 |
| test | t1 | 0 | uidx3 | 1 | col3 | NULL | | NULL | 2 | YES | NO | 0 |
| test | t1 | 1 | idx1 | 1 | col1 | NULL | | NULL | 3 | YES | NO | 1 |
+--------------+------------+------------+----------+--------------+-------------+----------+---------------+------------+----------+------------+-----------+-----------+
3 rows in set (0.00 sec)
通常のテーブルをパーティション分割する場合、またはパーティションテーブルを再パーティションする場合、必要に応じてインデックスをグローバル インデックスまたはローカル インデックスに更新できます。
例えば、次のSQL文は、列col1に基づいて表t1再パーティション化し、グローバルインデックスuidx12とidx1ローカルインデックスに更新し、ローカルインデックスuidx3グローバルインデックスに更新します。列uidx3は列col3の一意のインデックスです。すべてのパーティションにわたって列col3の一意性を確保するには、列uidx3グローバルインデックスにする必要があります。列uidx12とidx1は列col1のインデックスであり、グローバルインデックスまたはローカルインデックスのどちらでも構いません。
ALTER TABLE t1 PARTITION BY HASH (col1) PARTITIONS 3 UPDATE INDEXES (uidx12 LOCAL, uidx3 GLOBAL, idx1 LOCAL);
動作メカニズム
このセクションでは、グローバル インデックスの設計原則と実装を含む、グローバル インデックスの動作メカニズムについて説明します。
設計原則
TiDBのパーティションテーブルでは、ローカルインデックスのキープレフィックスはパーティションIDですが、グローバルインデックスのキープレフィックスはテーブルIDです。この設計により、グローバルインデックスデータがTiKV上で連続的に分散され、インデックス検索に必要なRPCリクエストの数が削減されます。
CREATE TABLE `sbtest` (
`id` int(11) NOT NULL,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
KEY idx(k),
KEY global_idx(k) GLOBAL
) partition by hash(id) partitions 5;
前述のテーブルスキーマを例に挙げましょう。1 idxローカルインデックス、 global_idxはグローバルインデックスです。5 のデータはPartitionID1_i_xxxやPartitionID2_i_xxxなどidxつの異なる範囲に分散されていますが、 global_idxのデータは単一の範囲 ( TableID_i_xxx ) に集中しています。
kに関連するクエリ(例えばSELECT * FROM sbtest WHERE k > 1を実行すると、ローカルインデックスidxは5つの個別の範囲を生成しますが、グローバルインデックスglobal_idxは1つの範囲のみを生成します。TiDBの各範囲は1つ以上のRPCリクエストに対応するため、グローバルインデックスを使用することでRPCリクエストの数を数倍削減でき、インデックスクエリのパフォーマンスが向上します。
次の図は、 idxとglobal_idxという 2 つの異なるインデックスを使用してSELECT * FROM sbtest WHERE k > 1ステートメントを実行した場合の RPC 要求とデータ フローの違いを示しています。
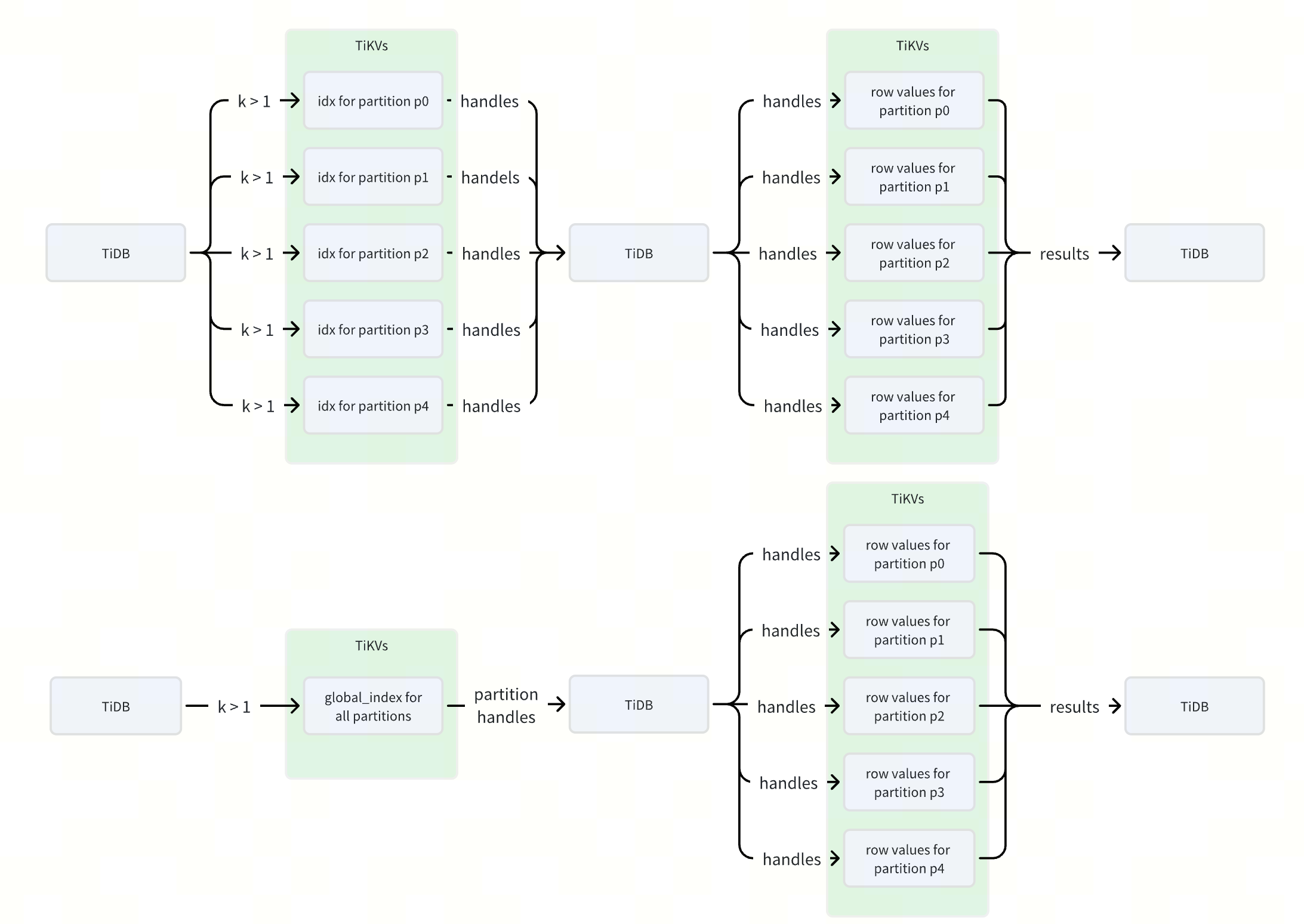
エンコード方法
TiDBでは、インデックスエントリはキーと値のペアとしてエンコードされます。パーティションテーブルの場合、各パーティションはTiKVレイヤーで独立した物理テーブルとして扱われ、それぞれにpartitionID設定されます。したがって、パーティションテーブルにおけるインデックスエントリのエンコードは次のようになります。
Unique key
Key:
- PartitionID_indexID_ColumnValues
Value:
- IntHandle
- TailLen_IntHandle
- CommonHandle
- TailLen_IndexVersion_CommonHandle
Non-unique key
Key:
- PartitionID_indexID_ColumnValues_Handle
Value:
- IntHandle
- TailLen_Padding
- CommonHandle
- TailLen_IndexVersion
グローバルインデックスの場合、インデックスエントリのエンコーディングは異なります。グローバルインデックスのキーレイアウトが現在のインデックスキーのエンコーディングと互換性を保つため、新しいインデックスエンコーディングレイアウトは次のように定義されます。
Unique key
Key:
- TableID_indexID_ColumnValues
Value:
- IntHandle
- TailLen_PartitionID_IntHandle
- CommonHandle
- TailLen_IndexVersion_CommonHandle_PartitionID
Non-unique key
Key:
- TableID_indexID_ColumnValues_Handle
Value:
- IntHandle
- TailLen_PartitionID
- CommonHandle
- TailLen_IndexVersion_PartitionID
このエンコーディング方式では、 TableIDグローバルインデックスキーの先頭に配置され、 PartitionIDが値に格納されます。この設計の利点は、既存のインデックスキーエンコーディングとの互換性が確保されることです。しかし、いくつかの課題も生じます。例えば、 DROP PARTITIONやTRUNCATE PARTITIONなどのDDL操作を実行する場合、インデックスエントリが連続して格納されないため、追加の処理が必要になります。
パフォーマンステスト結果
次のテストは、sysbench のselect_random_pointsシナリオに基づいており、主にさまざまなパーティション戦略とインデックス作成方法でのクエリ パフォーマンスを比較するために使用されます。
テストで使用されるテーブル スキーマは次のとおりです。
CREATE TABLE `sbtest` (
`id` int(11) NOT NULL,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,
KEY `k_1` (`k`)
/* Key `k_1` (`k`, `c`) GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
/* Partition by hash(`id`) partitions 100 */
/* Partition by range(`id`) xxxx */
ワークロード SQL は次のとおりです。
SELECT id, k, c, pad
FROM sbtest
WHERE k IN (xx, xx, xx)
範囲パーティション(100 パーティション):
ハッシュパーティション(100パーティション):
前述のテストでは、高同時実行環境において、グローバルインデックスによってパーティションテーブルのクエリパフォーマンスが大幅に向上し、最大50倍のパフォーマンス向上が実現できることが実証されています。さらに、グローバルインデックスはリクエストユニット(RU)の消費量を大幅に削減します。パーティション数が増えるにつれて、パフォーマンスのメリットはさらに顕著になります。