データのインポートのためのCSV構成
このドキュメントでは、 TiDB Cloudの Import Data サービスの CSV 構成について説明します。
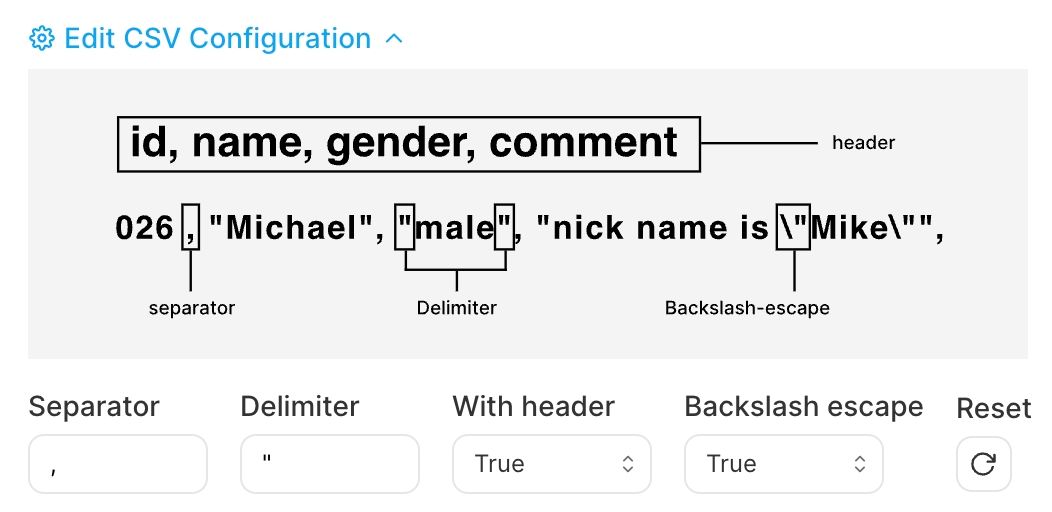
以下は、 TiDB Cloudのデータインポートサービスを使用してCSVファイルをインポートする際のCSVコンフィグレーションウィンドウです。詳細については、 クラウドストレージからTiDB Cloud DedicatedにCSVファイルをインポートする参照してください。
セパレーター
定義: フィールドセパレーターを定義します。1文字または複数文字を指定できますが、空にすることはできません。
共通の値:
- CSV(カンマ区切り値)の場合は
,上記のスクリーンショットに示すように、「1」、「Michael」、「male」は3つのフィールドを表します。 - TSV (タブ区切り値)の場合は
"\t"。
- CSV(カンマ区切り値)の場合は
デフォルト:
,
デリミタ
定義: 引用符で囲む際に使用する区切り文字を定義します。区切り文字が空の場合、すべてのフィールドは引用符で囲まれません。
共通の値:
'"'フィールドを二重引用符で囲みます。上のスクリーンショットに示すように、"Michael","male"2つのフィールドを表します。2つのフィールドの間には必ず,必要です。データが"Michael""male"(,なし)の場合、インポートタスクは解析に失敗します。データが"Michael,male"(二重引用符が1つだけ)の場合、1つのフィールドとして解析されます。''引用を無効にします。
デフォルト:
"
NULL値
定義: CSV ファイル内の
NULL値を表す文字列を定義します。デフォルト:
\N
バックスラッシュエスケープ
定義: フィールド内のバックスラッシュをエスケープ文字として解析するかどうかを制御します。バックスラッシュエスケープが有効になっている場合、以下のシーケンスが認識され、変換されます。
その他の場合(例えば
\")には、バックスラッシュは削除され、次の文字(")がフィールドに残ります。残った文字には特別な役割(例えば区切り文字)はなく、通常の文字として扱われます。引用符で囲んでも、バックスラッシュがエスケープ文字として解析されるかどうかは影響を受けません。次のフィールドを例に挙げます。
- 値が
Trueの場合、"nick name is \"Mike\""nick name is "Mike"として解析され、ターゲット テーブルに書き込まれます。 - 値が
Falseの場合、"nick name is \"、Mike\、""の3つのフィールドとして解析されます。しかし、フィールドが互いに分離されていないため、正しく解析できません。
標準CSVファイルの場合、記録するフィールドに二重引用符で囲まれた文字が含まれている場合は、エスケープ処理のために二重引用符を2つ使用する必要があります。この場合、二重引用符を
Backslash escape = True使用すると解析エラーが発生しますが、Backslash escape = False使用すると正しく解析されます。典型的なシナリオは、インポートされたフィールドにJSONコンテンツが含まれている場合です。標準CSVのJSONフィールドは通常、次のように保存されます。"{""key1"":""val1"", ""key2"": ""val2""}"この場合、
Backslash escape = False設定すると、フィールドは次のようにデータベースに正しくエスケープされます。{"key1": "val1", "key2": "val2"}CSVソースファイルの内容が以下のようにJSON形式で保存されている場合は、
Backslash escape = True以下のように設定することを検討してください。ただし、これはCSVの標準形式ではありません。"{\"key1\": \"val1\", \"key2\":\"val2\" }"- 値が
デフォルト: 有効
ヘッダーをスキップ
定義: CSVファイルのヘッダー行をスキップするかどうかを制御します。 「ヘッダーをスキップ」が有効になっている場合、インポート時にCSVファイルの最初の行がスキップされます。
デフォルト: 無効