TiSpark ユーザーガイド
TiSpark 対TiFlash
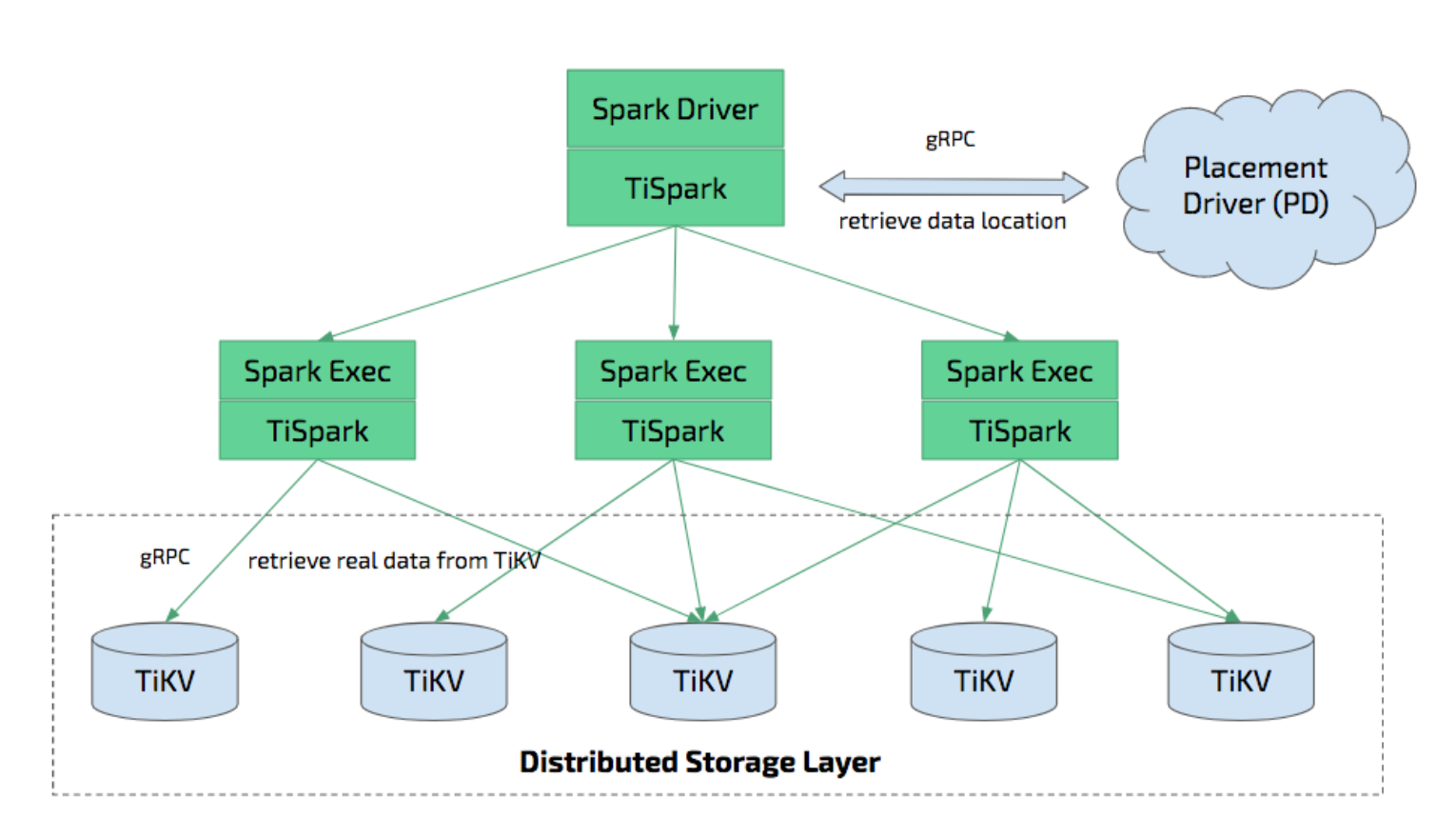
ティスパーク 、TiDB/TiKV 上で Apache Spark を実行し、複雑な OLAP クエリに応答するために構築された薄いレイヤーです。Spark プラットフォームと分散 TiKV クラスターの両方の利点を活用し、分散 OLTP データベースである TiDB にシームレスに接着して、オンライン トランザクションと分析の両方のワンストップ ソリューションとして機能するハイブリッド トランザクション/分析処理 (HTAP) ソリューションを提供します。
TiFlashは、HTAP を有効にする別のツールです。TiFlash と TiSpark はどちらも、複数のホストを使用して OLTP データに対して OLAP クエリを実行できます。TiFlashはデータを列形式で保存するため、より効率的な分析クエリが可能になります。TiFlash と TiSparkは一緒に使用できます。
TiSparkとは
TiSpark は、TiKV クラスターと PD クラスターに依存します。また、Spark クラスターを設定する必要があります。このドキュメントでは、TiSpark の設定方法と使用方法について簡単に説明します。Apache Spark に関する基本的な知識が必要です。詳細については、 Apache Spark ウェブサイト参照してください。
TiSpark は Spark Catalyst Engine と緊密に統合されており、コンピューティングを正確に制御できます。これにより、Spark は TiKV からデータを効率的に読み取ることができます。TiSpark はインデックス シークもサポートしており、高速ポイント クエリを可能にします。TiSpark はコンピューティングを TiKV にプッシュすることでデータ クエリを高速化し、Spark SQL で処理されるデータの量を削減します。同時に、TiSpark は TiDB 組み込み統計を使用して最適なクエリ プランを選択できます。
TiSpark と TiDB を使用すると、ETL を構築および保守することなく、トランザクション タスクと分析タスクの両方を同じプラットフォームで実行できます。これにより、システムアーキテクチャが簡素化され、保守コストが削減されます。
TiDB でのデータ処理には、Spark エコシステムのツールを使用できます。
- TiSpark: データ分析とETL
- TiKV: データ取得
- スケジュールシステム: レポート生成
また、TiSpark は TiKV への分散書き込みをサポートしています。Spark と JDBC を使用した TiDB への書き込みと比較すると、TiKV への分散書き込みではトランザクション (すべてのデータが正常に書き込まれるか、すべての書き込みが失敗するかのいずれか) を実装でき、書き込みが高速になります。
要件
- TiSpark は Spark 2.3 以上をサポートします。
- TiSpark には JDK 1.8 と Scala 2.11/2.12 が必要です。
- TiSpark は、
YARN、Mesos、Standaloneなどの任意の Spark モードで実行されます。
Sparkの推奨デプロイメント構成
TiSpark は Spark の TiDB コネクタであるため、使用するには実行中の Spark クラスターが必要です。
このドキュメントでは、Spark の導入に関する基本的なアドバイスを提供します。詳細なハードウェア推奨事項については、 スパーク公式サイトを参照してください。
Spark クラスターの独立したデプロイメントの場合:
- Spark には 32 GB のメモリを割り当てることをお勧めします。オペレーティング システムとバッファ キャッシュ用にメモリの少なくとも 25% を予約してください。
- Spark には、マシンごとに少なくとも 8 ~ 16 個のコアをプロビジョニングすることをお勧めします。まず、すべての CPU コアを Spark に割り当てる必要があります。
以下はspark-env.sh構成に基づく例です。
SPARK_EXECUTOR_MEMORY = 32g
SPARK_WORKER_MEMORY = 32g
SPARK_WORKER_CORES = 8
TiSparkを入手
TiSpark は、TiKV の読み取りと書き込みの機能を提供する Spark 用のサードパーティ jar パッケージです。
mysql-connector-j を入手する
GPL ライセンスの制限により、 mysql-connector-java依存関係は提供されなくなりました。
TiSpark の jar の次のバージョンにはmysql-connector-java含まれなくなります。
- TiSpark > 3.0.1
- TiSpark > 2.5.1 (TiSpark 2.5.x の場合)
- TiSpark > 2.4.3 (TiSpark 2.4.x 用)
ただし、TiSpark では書き込みと認証にmysql-connector-java必要です。このような場合は、次のいずれかの方法でmysql-connector-java手動でインポートする必要があります。
mysql-connector-javaSpark jar ファイルに入力します。Spark ジョブを送信するときに
mysql-connector-javaインポートします。次の例を参照してください。
spark-submit --jars tispark-assembly-3.0_2.12-3.1.0-SNAPSHOT.jar,mysql-connector-java-8.0.29.jar
TiSparkのバージョンを選択
TiDB と Spark のバージョンに応じて、TiSpark のバージョンを選択できます。
TiSpark 2.4.4、2.5.2、3.0.2、3.1.1、および 3.2.3 は最新の安定バージョンであり、強く推奨されます。
注記:
TiSpark は、TiDB v7.0.0 以降のバージョンとの互換性を保証しません。
TiSpark jarを入手する
次のいずれかの方法で TiSpark jar を取得できます。
- メイヴンセントラルから取得して
pingcapを検索 - TiSparkリリースから取得
- 以下の手順でソースからビルドします
注記:
現在、TiSpark をビルドするには java8 のみが選択肢となります。確認するには mvn -version を実行してください。
git clone https://github.com/pingcap/tispark.git
TiSpark ルート ディレクトリで次のコマンドを実行します。
// add -Dmaven.test.skip=true to skip the tests
mvn clean install -Dmaven.test.skip=true
// or you can add properties to specify spark version
mvn clean install -Dmaven.test.skip=true -Pspark3.2.1
TiSpark jar のアーティファクト ID
TiSpark のアーティファクト ID は TiSpark のバージョンによって異なります。
はじめる
このドキュメントでは、spark-shell で TiSpark を使用する方法について説明します。
spark-shellを起動する
spark-shell で TiSpark を使用するには:
spark-defaults.confに次の設定を追加します。
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.pd.addresses ${your_pd_address}
spark.sql.catalog.tidb_catalog org.apache.spark.sql.catalyst.catalog.TiCatalog
spark.sql.catalog.tidb_catalog.pd.addresses ${your_pd_address}
--jarsオプションで spark-shell を起動します。
spark-shell --jars tispark-assembly-{version}.jar
TiSparkバージョンを入手
spark-shell で次のコマンドを実行すると、TiSpark のバージョン情報を取得できます。
spark.sql("select ti_version()").collect
TiSparkを使用してデータを読み取る
Spark SQL を使用して TiKV からデータを読み取ることができます。
spark.sql("use tidb_catalog")
spark.sql("select count(*) from ${database}.${table}").show
TiSparkを使用してデータを書き込む
Spark DataSource API を使用して、 ACIDが保証される TiKV にデータを書き込むことができます。
val tidbOptions: Map[String, String] = Map(
"tidb.addr" -> "127.0.0.1",
"tidb.password" -> "",
"tidb.port" -> "4000",
"tidb.user" -> "root"
)
val customerDF = spark.sql("select * from customer limit 100000")
customerDF.write
.format("tidb")
.option("database", "tpch_test")
.option("table", "cust_test_select")
.options(tidbOptions)
.mode("append")
.save()
詳細はデータ ソース API ユーザー ガイド参照してください。
TiSpark 3.1 以降では、Spark SQL を使用して TiKV にデータを書き込むことができます。詳細については、 挿入SQL参照してください。
JDBC データソースを使用してデータを書き込む
TiSpark を使用せずに、Spark JDBC を使用して TiDB に書き込むこともできます。
これは TiSpark の範囲外です。このドキュメントでは例のみを示します。詳細については、 JDBC から他のデータベースへを参照してください。
import org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions
val customer = spark.sql("select * from customer limit 100000")
// you might need to repartition the source to make it balanced across nodes
// and increase concurrency
val df = customer.repartition(32)
df.write
.mode(saveMode = "append")
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
// replace the host and port with yours and be sure to use rewrite batch
.option("url", "jdbc:mysql://127.0.0.1:4000/test?rewriteBatchedStatements=true")
.option("useSSL", "false")
// as tested, setting to `150` is a good practice
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE, 150)
.option("dbtable", s"cust_test_select") // database name and table name here
.option("isolationLevel", "NONE") // set isolationLevel to NONE
.option("user", "root") // TiDB user here
.save()
TiDB OOM につながる可能性のある大規模な単一トランザクションを回避し、 ISOLATION LEVEL does not supportエラーも回避するには、 isolationLevel NONEに設定します (TiDB は現在REPEATABLE-READのみをサポートしています)。
TiSparkを使用してデータを削除する
Spark SQL を使用して TiKV からデータを削除できます。
spark.sql("use tidb_catalog")
spark.sql("delete from ${database}.${table} where xxx")
詳細は機能を削除参照してください。
他のデータソースを操作する
次のように複数のカタログを使用して、異なるデータ ソースからデータを読み取ることができます。
// Read from Hive
spark.sql("select * from spark_catalog.default.t").show
// Join Hive tables and TiDB tables
spark.sql("select t1.id,t2.id from spark_catalog.default.t t1 left join tidb_catalog.test.t t2").show
TiSpark 構成
次の表の構成は、 spark-defaults.confと一緒に使用することも、他の Spark 構成プロパティと同じ方法で渡すこともできます。
TLS 構成
TiSpark TLS には、TiKV クライアント TLS と JDBC コネクタ TLS の 2 つの部分があります。TiSpark で TLS を有効にするには、両方を構成する必要があります。1 spark.tispark.tikv.xxx 、PD および TiKVサーバーとの TLS 接続を作成するために TiKV クライアントに使用されます。3 spark.tispark.jdbc.xxx 、TLS 接続で TiDBサーバーに接続するために JDBC に使用されます。
TiSpark TLS が有効になっている場合は、 tikv.trust_cert_collection 、 tikv.key_cert_chain 、 tikv.key_fileの構成で X.509 証明書を構成するか、 tikv.jks_enable 、 tikv.jks_trust_path 、 tikv.jks_key_pathで JKS 証明書を構成する必要があります。 jdbc.server_cert_storeとjdbc.client_cert_storeオプションです。
TiSpark は TLSv1.2 と TLSv1.3 のみをサポートします。
- 以下は、TiKV クライアントで X.509 証明書を使用して TLS 構成を開く例です。
spark.tispark.tikv.tls_enable true
spark.tispark.tikv.trust_cert_collection /home/tispark/root.pem
spark.tispark.tikv.key_cert_chain /home/tispark/client.pem
spark.tispark.tikv.key_file /home/tispark/client.key
- 以下は、TiKV クライアントで JKS 構成を使用して TLS を有効にする例です。
spark.tispark.tikv.tls_enable true
spark.tispark.tikv.jks_enable true
spark.tispark.tikv.jks_key_path /home/tispark/config/tikv-truststore
spark.tispark.tikv.jks_key_password tikv_trustore_password
spark.tispark.tikv.jks_trust_path /home/tispark/config/tikv-clientstore
spark.tispark.tikv.jks_trust_password tikv_clientstore_password
JKS 証明書と X.509 証明書の両方が設定されている場合、JKS の優先順位が高くなります。つまり、TLS ビルダーは JKS 証明書を最初に使用します。したがって、共通の PEM 証明書だけを使用する場合は、 spark.tispark.tikv.jks_enable=true設定しないでください。
- 以下は、JDBC コネクタで TLS を有効にする例です。
spark.tispark.jdbc.tls_enable true
spark.tispark.jdbc.server_cert_store /home/tispark/jdbc-truststore
spark.tispark.jdbc.server_cert_password jdbc_truststore_password
spark.tispark.jdbc.client_cert_store /home/tispark/jdbc-clientstore
spark.tispark.jdbc.client_cert_password jdbc_clientstore_password
- TiDB TLSを開く方法の詳細については、 TiDBクライアントとサーバー間のTLSを有効にする参照してください。
- JAVA キーストアの生成方法の詳細については、 SSL を使用した安全な接続参照してください。
Log4j 構成
spark-shellまたはspark-sqlを起動してクエリを実行すると、次の警告が表示される場合があります。
Failed to get database ****, returning NoSuchObjectException
Failed to get database ****, returning NoSuchObjectException
ここで、 ****データベース名です。
この警告は無害であり、Spark が独自のカタログで****を見つけられないために発生します。これらの警告は無視してかまいません。
ミュートするには、次のテキストを${SPARK_HOME}/conf/log4j.propertiesに追加します。
# tispark disable "WARN ObjectStore:568 - Failed to get database"
log4j.logger.org.apache.hadoop.hive.metastore.ObjectStore=ERROR
タイムゾーンの設定
-Duser.timezoneシステム プロパティ (たとえば、 -Duser.timezone=GMT-7 ) を使用してタイム ゾーンを設定します。これはTimestampタイプに影響します。
spark.sql.session.timeZone使用しないでください。
特徴
TiSpark の主な機能は次のとおりです。
式インデックスのサポート
TiDB v5.0 は表現インデックスサポートします。
TiSpark は現在、 expression indexテーブルからのデータの取得をサポートしていますが、 expression index TiSpark のプランナーでは使用されません。
TiFlashの操作
TiSpark は、構成spark.tispark.isolation_read_enginesを介してTiFlashからデータを読み取ることができます。
パーティションテーブルのサポート
TiDBからパーティションテーブルを読み取る
TiSpark は、TiDB から範囲パーティション テーブルとハッシュ パーティション テーブルを読み取ることができます。
現在、TiSpark は MySQL/TiDB パーティション テーブル構文select col_name from table_name partition(partition_name)をサポートしていません。ただし、 where条件を使用してパーティションをフィルターすることは可能です。
TiSpark は、テーブルに関連付けられたパーティション タイプとパーティション式に応じて、パーティション プルーニングを適用するかどうかを決定します。
TiSpark は、パーティション式が次のいずれかの場合にのみ、範囲パーティション分割にパーティション プルーニングを適用します。
- 列式
YEAR($argument)引数は列であり、その型は datetime または datetime として解析できる文字列リテラルです。
パーティション プルーニングが適用できない場合、TiSpark の読み取りはすべてのパーティションに対してテーブル スキャンを実行することと同じです。
パーティションテーブルに書き込む
現在、TiSpark は、次の条件下でのみ、範囲パーティション テーブルとハッシュ パーティション テーブルへのデータの書き込みをサポートしています。
- パーティション式は列式です。
- パーティション式は
YEAR($argument)で、引数は列であり、その型は datetime または datetime として解析できる文字列リテラルです。
パーティション化されたテーブルに書き込むには、次の 2 つの方法があります。
- データソース API を使用して、置換および追加のセマンティクスをサポートするパーティション テーブルに書き込みます。
- Spark SQL で delete ステートメントを使用します。
注記:
現在、TiSpark は、utf8mb4_bin照合順序が有効になっているパーティション テーブルへの書き込みのみをサポートしています。
Security
TiSpark v2.5.0 以降のバージョンを使用している場合は、TiDB を使用して TiSpark ユーザーを認証および承認できます。
認証と承認機能はデフォルトでは無効になっています。有効にするには、Spark 構成ファイルspark-defaults.confに次の構成を追加します。
// Enable authentication and authorization
spark.sql.auth.enable true
// Configure TiDB information
spark.sql.tidb.addr $your_tidb_server_address
spark.sql.tidb.port $your_tidb_server_port
spark.sql.tidb.user $your_tidb_server_user
spark.sql.tidb.password $your_tidb_server_password
詳細についてはTiDBサーバーを介した認可と認証参照してください。
その他の機能
統計情報
TiSpark は統計情報を次の目的で使用します。
- 最小の推定コストでクエリ プランで使用するインデックスを決定します。
- 効率的なブロードキャスト参加を可能にする小さなテーブル ブロードキャスト。
TiSpark が統計情報にアクセスできるようにするには、関連するテーブルが分析されていることを確認してください。
テーブルを分析する方法の詳細については、 統計入門参照してください。
TiSpark 2.0 以降では、統計情報はデフォルトで自動的に読み込まれます。
FAQ
TiSparkFAQ参照。